Recognition: 2 theorem links
· Lean TheoremQwen3-VL-Seg: Unlocking Open-World Referring Segmentation with Vision-Language Grounding
Pith reviewed 2026-05-11 02:31 UTC · model grok-4.3
The pith
A lightweight decoder turns MLLM bounding boxes into precise pixel masks for open-world referring segmentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
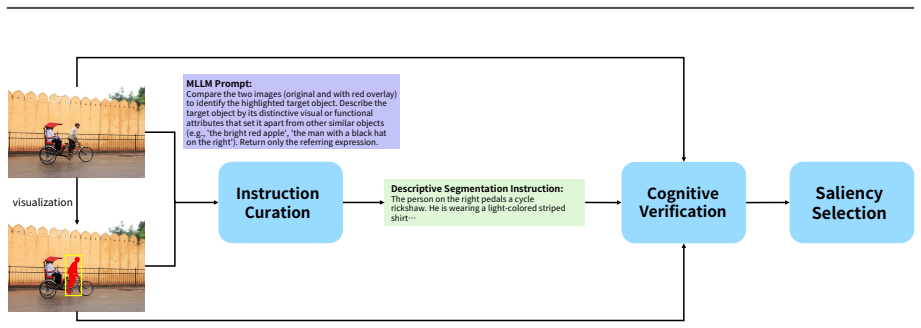
Qwen3-VL-Seg treats the bounding box output from a base multimodal large language model as a semantically grounded structural prior and decodes it into pixel-level referring segmentation masks using a lightweight box-guided mask decoder. The decoder employs multi-scale spatial feature injection, spatial-semantic query construction, box-guided high-resolution pixel fusion, and iterative mask-aware query refinement, adding only about 0.4 percent parameters. Training relies on the constructed SA1B-ORS dataset containing category-oriented and descriptive instance samples. Evaluation on the ORS-Bench benchmark shows strong performance across closed-set and open-world referring segmentation, clear
What carries the argument
The box-guided mask decoder that combines multi-scale spatial feature injection, spatial-semantic query construction, box-guided high-resolution pixel fusion, and iterative mask-aware query refinement to convert MLLM boxes into masks.
If this is right
- The model performs strongly on referring expression segmentation and visual grounding in both closed-set and open-world conditions.
- Clear advantages appear on language-intensive instructions and out-of-distribution cases in ORS-Bench.
- General multimodal competence is broadly preserved after the segmentation adaptation.
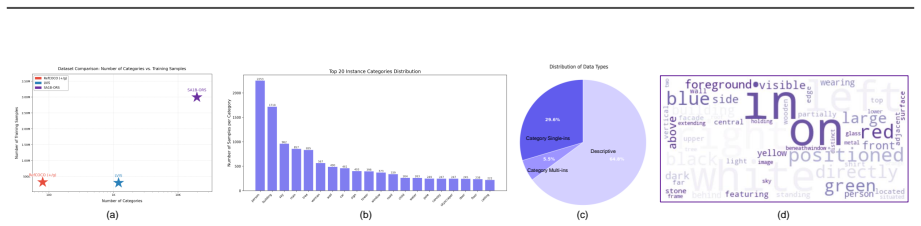
- Scalable open-world training is supported by the SA1B-ORS dataset with its category and descriptive subsets.
Where Pith is reading between the lines
- This prior-based approach could reduce reliance on separate heavy segmentation models in vision-language pipelines.
- The same decoder pattern may extend to other dense tasks such as referring depth or video segmentation with minimal changes.
- Carefully screened benchmarks like ORS-Bench could become standard for measuring genuine open-world language grounding.
Load-bearing premise
The bounding box predicted by the base MLLM provides a sufficiently accurate and semantically grounded structural prior that the lightweight decoder can turn into precise pixel masks even for unconstrained open-world referring expressions.
What would settle it
Direct pixel-overlap measurements on out-of-distribution referring expressions where the base MLLM produces inaccurate or semantically misaligned boxes would show masks with low agreement to human ground truth.
Figures









read the original abstract
Open-world referring segmentation requires grounding unconstrained language expressions to precise pixel-level regions. Existing multimodal large language models (MLLMs) exhibit strong open-world visual grounding, but their outputs remain limited to sparse bounding-box coordinates and are insufficient for dense visual prediction. Recent MLLM-based segmentation methods either directly predict sparse contour coordinates, struggling to reconstruct continuous object boundaries, or rely on external segmentation foundation models such as the Segment Anything Model (SAM), introducing substantial architectural and deployment overhead. We present Qwen3-VL-Seg, a parameter-efficient framework that treats the MLLM-predicted box as a semantically grounded structural prior and decodes it into pixel-level referring segmentation. At its core, a lightweight box-guided mask decoder combines multi-scale spatial feature injection, spatial-semantic query construction, box-guided high-resolution pixel fusion, and iterative mask-aware query refinement, introducing only 17M parameters (about 0.4\% of the base model). For scalable open-world training, we construct SA1B-ORS, an SA-1B-derived dataset with two subsets: SA1B-CoRS (category-oriented samples) and SA1B-DeRS (descriptive, instance-specific samples). For evaluation, we curate ORS-Bench, a manually screened benchmark with in-distribution and out-of-distribution subsets covering diverse referring expression types. Extensive experiments on referring expression segmentation, visual grounding, and ORS-Bench show that Qwen3-VL-Seg performs strongly across closed-set and open-world settings, with clear advantages on language-intensive instructions and strong out-of-distribution generalization. Evaluations on general multimodal benchmarks further show that the model broadly preserves general-purpose multimodal competence after segmentation-oriented adaptation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Qwen3-VL-Seg, a parameter-efficient framework (adding only 17M parameters, ~0.4% of the base model) that treats bounding-box outputs from the Qwen3-VL MLLM as a semantically grounded structural prior and decodes them into pixel-level masks via a lightweight box-guided mask decoder. The decoder incorporates multi-scale spatial feature injection, spatial-semantic query construction, box-guided high-resolution pixel fusion, and iterative mask-aware query refinement. To enable scalable training, the authors construct SA1B-ORS (with SA1B-CoRS and SA1B-DeRS subsets) from SA-1B; for evaluation they curate ORS-Bench with in-distribution and out-of-distribution subsets. Experiments claim strong results on referring expression segmentation and visual grounding tasks, advantages on language-intensive instructions, robust out-of-distribution generalization on ORS-Bench, and preservation of general multimodal competence.
Significance. If the central performance claims hold, the work offers a practical, low-overhead route to dense open-world referring segmentation from existing MLLMs without external foundation models such as SAM. The creation of SA1B-ORS and ORS-Bench constitutes a reusable resource for the community, and the explicit focus on parameter efficiency plus retention of general capabilities is a clear strength.
major comments (2)
- [§3] §3 (Framework): The central claim that the 17M-parameter decoder can reliably convert MLLM-predicted boxes into precise masks for unconstrained open-world expressions rests on the untested assumption that those boxes supply a sufficiently tight and semantically complete prior. No quantitative analysis (e.g., correlation between box IoU and final mask mIoU, or failure cases on ambiguous/deictic expressions) is provided on ORS-Bench to substantiate this load-bearing assumption.
- [§4.3] §4.3 (ORS-Bench experiments): The reported strong out-of-distribution generalization and advantages on language-intensive instructions are presented without error bars, multiple random seeds, or explicit criteria for the ID/OOD split and data exclusion. This makes it impossible to determine whether the gains are robust or sensitive to post-hoc dataset choices.
minor comments (2)
- [Abstract] Abstract and §1: The phrase 'extensive experiments' is used without enumerating the exact baselines, metrics, or number of runs, reducing immediate clarity for readers.
- [§3.2] Notation in the decoder description could be made more precise by adding a single equation or pseudocode block for the iterative refinement step.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the framework assumptions and experimental reporting. We address each major comment point by point below.
read point-by-point responses
-
Referee: [§3] §3 (Framework): The central claim that the 17M-parameter decoder can reliably convert MLLM-predicted boxes into precise masks for unconstrained open-world expressions rests on the untested assumption that those boxes supply a sufficiently tight and semantically complete prior. No quantitative analysis (e.g., correlation between box IoU and final mask mIoU, or failure cases on ambiguous/deictic expressions) is provided on ORS-Bench to substantiate this load-bearing assumption.
Authors: We agree that direct quantitative evidence for the sufficiency of the MLLM box prior is important to support the central claim. While end-to-end performance on ORS-Bench provides supporting evidence, we have added a new analysis subsection (Section 3.4) in the revised manuscript. This includes a correlation study between box IoU (w.r.t. ground truth) and final mask mIoU across ORS-Bench samples, plus a qualitative breakdown of failure cases on ambiguous and deictic expressions. These additions directly test and substantiate the assumption. revision: yes
-
Referee: [§4.3] §4.3 (ORS-Bench experiments): The reported strong out-of-distribution generalization and advantages on language-intensive instructions are presented without error bars, multiple random seeds, or explicit criteria for the ID/OOD split and data exclusion. This makes it impossible to determine whether the gains are robust or sensitive to post-hoc dataset choices.
Authors: We thank the referee for highlighting the need for greater statistical rigor and transparency. In the revised manuscript we have re-run the ORS-Bench experiments with three independent random seeds and now report mean ± standard deviation (error bars) for all key metrics. We have also expanded Section 4.1 with explicit, reproducible criteria for the ID/OOD split, including the manual screening protocol, exclusion rules to prevent data leakage, and the rationale for sample selection. These revisions address concerns about robustness and post-hoc choices. revision: yes
Circularity Check
No significant circularity; empirical claims rest on independent decoder and new benchmarks
full rationale
The paper proposes a lightweight 17M-parameter box-guided mask decoder that processes MLLM-predicted bounding boxes into pixel masks using multi-scale feature injection, spatial-semantic queries, box-guided fusion, and iterative refinement. It constructs new training data (SA1B-ORS with CoRS/DeRS subsets) and a new evaluation benchmark (ORS-Bench with in/out-of-distribution splits). All performance claims are supported by experimental results on referring expression segmentation, visual grounding, and general multimodal tasks. No equations, derivations, or predictions are presented that reduce claimed outputs to fitted parameters or self-cited results by construction. The decoder parameters are trained independently; the central results are empirical evaluations against external benchmarks rather than self-referential definitions or renamings.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Multimodal LLM bounding-box predictions serve as semantically grounded structural priors sufficient for mask decoding in open-world settings
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe present Qwen3-VL-Seg, a parameter-efficient framework that treats the MLLM-predicted box as a semantically grounded structural prior and decodes it into pixel-level referring segmentation. At its core, a lightweight box-guided mask decoder combines multi-scale spatial feature injection, spatial-semantic query construction, box-guided high-resolution pixel fusion, and iterative mask-aware query refinement, introducing only 17M parameters
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearOur key insight is that the bounding box predicted by the MLLM is not merely a terminal output, but a semantically grounded and spatially informative anchor for mask decoding.
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, Wenbin Ge, Zhifang Guo, Qidong Huang, Jie Huang, Fei Huang, Binyuan Hui, Shutong Jiang, Zhaohai Li, Mingsheng Li, Mei Li, Kaixin Li, Zicheng Lin, Junyang Lin, Xuejing Liu, Jiawei Liu, Chenglong Liu, Yang Liu, Dayiheng Liu, Shixuan ...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
SAM 3: Segment Anything with Concepts
URL https://lf3-static.bytednsdoc.com/obj/eden-cn/lapzild-tss/ljhwZthlaukjlkulzlp/seed2/ 0214/Seed2.0%20Model%20Card.pdf. Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chai- tanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719,
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Shikra: Unleashing Multimodal LLM's Referential Dialogue Magic
Keqin Chen, Zhao Zhang, Weili Zeng, Richong Zhang, Feng Zhu, and Rui Zhao. Shikra: Unleashing multimodal llm’s referential dialogue magic.arXiv preprint arXiv:2306.15195,
work page internal anchor Pith review arXiv
-
[4]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261,
work page internal anchor Pith review Pith/arXiv arXiv
-
[5]
Google DeepMind. Gemini 3 flash model card. https://storage.googleapis.com/deepmind-media/ Model-Cards/Gemini-3-Flash-Model-Card.pdf, 2025a. Accessed: 2025-02-14. Google DeepMind. Gemini 3 pro model card. Model card, Google DeepMind, 2025b. URL https: //storage.googleapis.com/deepmind-media/Model-Cards/Gemini-3-Pro-Model-Card.pdf. Agrim Gupta, Piotr Dolla...
work page 2025
-
[6]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29,
work page 2022
-
[7]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Donggon Jang, Yucheol Cho, Suin Lee, Taehyeon Kim, and Dae-Shik Kim. Mmr: A large-scale benchmark dataset for multi-target and multi-granularity reasoning segmentation.arXiv preprint arXiv:2503.13881,
-
[9]
Referitgame: Referring to objects in photographs of natural sceneteam2023geminis
Sahar Kazemzadeh, Vicente Ordonez, Mark Matten, and Tamara Berg. Referitgame: Referring to objects in photographs of natural sceneteam2023geminis. InProceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pp. 787–798,
work page 2014
-
[10]
Alexander Kirillov, Eric Mintun, Nikhila Ravi, Hanzi Mao, Chloe Rolland, Laura Gustafson, Tete Xiao, Spencer Whitehead, Alexander C. Berg, Wan-Yen Lo, Piotr Dollár, and Ross Girshick. Segment anything. arXiv:2304.02643,
work page internal anchor Pith review arXiv
-
[11]
Text4seg: Reimagining image segmentation as text generation.arXiv preprint arXiv:2410.09855, 2024
20 Mengcheng Lan, Chaofeng Chen, Yue Zhou, Jiaxing Xu, Yiping Ke, Xinjiang Wang, Litong Feng, and Wayne Zhang. Text4seg: Reimagining image segmentation as text generation.arXiv preprint arXiv:2410.09855,
-
[12]
Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
Chang Liu, Henghui Ding, and Xudong Jiang. Gres: Generalized referring expression segmentation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp. 23592–23601, 2023a. Shilong Liu, Zhaoyang Zeng, Tianhe Ren, Feng Li, Hao Zhang, Jie Yang, Chunyuan Li, Jianwei Yang, Hang Su, Jun Zhu, et al. Grounding dino: Marrying dino...
-
[14]
SAM 2: Segment Anything in Images and Videos
URL https: //arxiv.org/abs/2408.00714. Zhongwei Ren, Zhicheng Huang, Yunchao Wei, Yao Zhao, Dongmei Fu, Jiashi Feng, and Xiaojie Jin. Pixellm: Pixel reasoning with large multimodal model. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 26374–26383,
work page internal anchor Pith review Pith/arXiv arXiv
-
[15]
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaugh- lin, Aiden Low, AJ Ostrow, Akhila Ananthram, et al. Openai gpt-5 system card.arXiv preprint arXiv:2601.03267,
work page internal anchor Pith review Pith/arXiv arXiv
-
[16]
Hao Tang, Chenwei Xie, Haiyang Wang, Xiaoyi Bao, Tingyu Weng, Pandeng Li, Yun Zheng, and Liwei Wang. Ufo: A unified approach to fine-grained visual perception via open-ended language interface. arXiv preprint arXiv:2503.01342,
-
[17]
Gemini: A Family of Highly Capable Multimodal Models
Gemini Team, Rohan Anil, Sebastian Borgeaud, Jean-Baptiste Alayrac, Jiahui Yu, Radu Soricut, Johan Schalkwyk, Andrew M Dai, Anja Hauth, Katie Millican, et al. Gemini: a family of highly capable multimodal models.arXiv preprint arXiv:2312.11805,
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Jingchao Wang, Zhijian Wu, Dingjiang Huang, Yefeng Zheng, and Hong Wang. Unlocking the poten- tial of mllms in referring expression segmentation via a light-weight mask decoder.arXiv preprint arXiv:2508.04107, 2025a. Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Yang Fan, Kai Dang, Me...
-
[19]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025b. Zhixiang Wei, Yi Li, Zhehan Kan, Xinghua Jiang, Zuwei Long, Shifeng Liu, Hongze Shen, We...
work page internal anchor Pith review Pith/arXiv arXiv
-
[20]
Ferret: Refer and ground anything anywhere at any granularity,
Haoxuan You, Haotian Zhang, Zhe Gan, Xianzhi Du, Bowen Zhang, Zirui Wang, Liangliang Cao, Shih-Fu Chang, and Yinfei Yang. Ferret: Refer and ground anything anywhere at any granularity.arXiv preprint arXiv:2310.07704,
-
[21]
Recognize anything: A strong image tagging model
Youcai Zhang, Xinyu Huang, Jinyu Ma, Zhaoyang Li, Zhaochuan Luo, Yanchun Xie, Yuzhuo Qin, Tong Luo, Yaqian Li, Shilong Liu, et al. Recognize anything: A strong image tagging model.arXiv preprint arXiv:2306.03514,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.