Recognition: no theorem link
Topic Is Not Agenda: A Citation-Community Audit of Text Embeddings
Pith reviewed 2026-05-11 01:07 UTC · model grok-4.3
The pith
Embeddings match broad sub-fields but retrieve papers from the same research agenda only 15-21 percent of the time.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
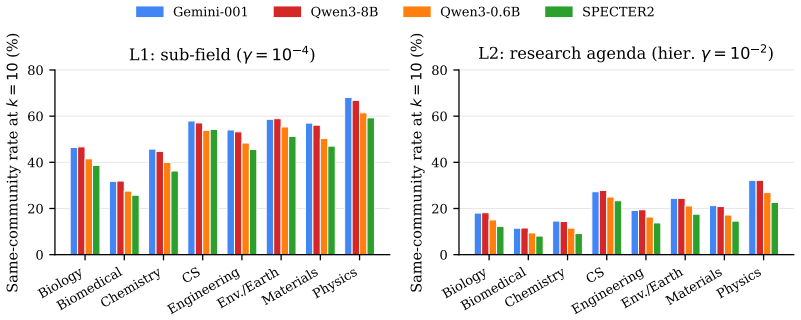
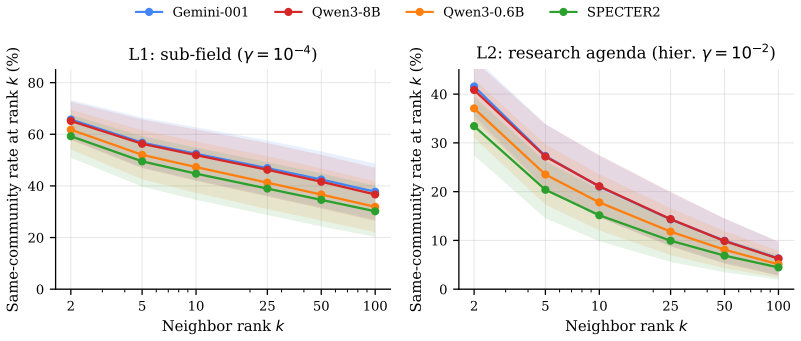
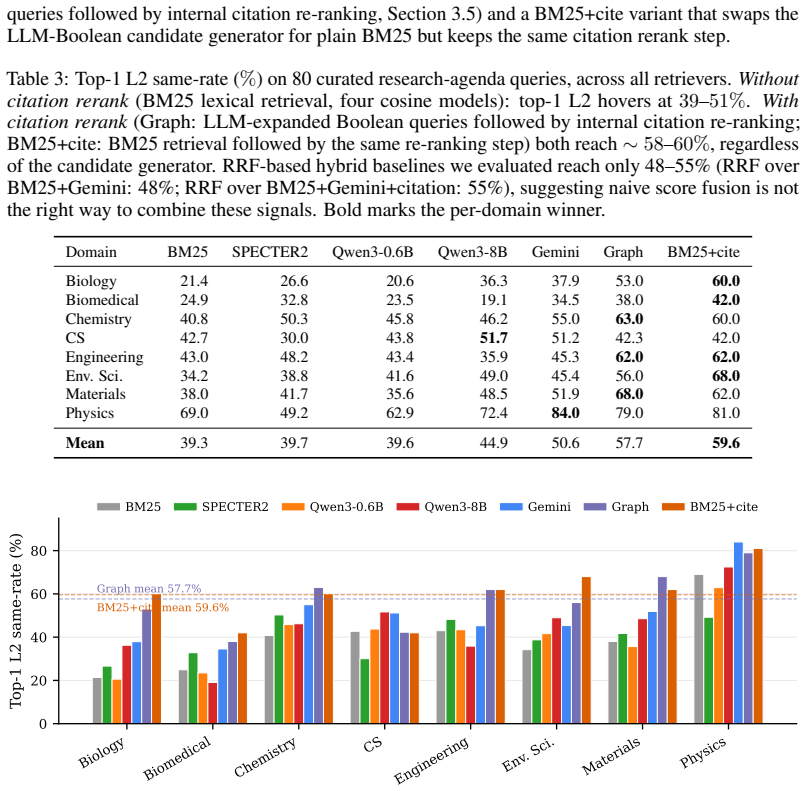
Four state-of-the-art embeddings clear the L1 bar reasonably (45-52% top-10 same-rate) but stop working at L2: only 15-21% of top-10 neighbors share the query's research agenda. In absolute terms, 8 of every 10 retrieved papers are off-agenda. The failure is universal across eight scientific domains and all four models; SPECTER2, despite its citation-based contrastive training, is the weakest. As a diagnostic probe, a deliberately simple citation-count rerank reaches 57.7% top-1 L2 on top of LLM-expanded Boolean retrieval and 59.6% on top of plain BM25, about 9 points above the best cosine retriever.
What carries the argument
The augmented citation graph over 3.58M papers partitioned by Leiden CPM into L1 sub-fields and nested L2 research agendas, used as ground truth to score whether embedding neighbors belong to the same agenda.
Load-bearing premise
The Leiden CPM partitions at L2 granularity accurately and independently identify distinct research agendas rather than artifacts of citation-graph construction or community-detection parameters.
What would settle it
Re-run the Leiden CPM partitions at L2 with different resolution parameters or a differently augmented citation graph and measure whether the top-10 same-agenda rates for the four embeddings shift by more than a few points.
Figures

read the original abstract
Vector search and retrieval-augmented generation (RAG) rest on the assumption that cosine similarity between text embeddings reflects conceptual relatedness. We measure where this assumption breaks. We build an augmented citation graph over 3.58M scientific papers and partition it via Leiden CPM at two granularities: sub-field (L1) and research-agenda (L2, hierarchical inside each L1). Four state-of-the-art embeddings (Gemini, Qwen3-8B, Qwen3-0.6B, SPECTER2) clear the L1 bar reasonably (45-52% top-10 same-rate) but stop working at L2: only 15-21% of top-10 neighbors share the query's research agenda. In absolute terms, 8 of every 10 retrieved papers are off-agenda. The failure is universal across eight scientific domains and all four models; SPECTER2, despite its citation-based contrastive training, is the weakest. As a diagnostic probe, we test whether the same augmented graph also functions as a retrieval signal: a deliberately simple citation-count rerank reaches 57.7% top-1 L2 on top of LLM-expanded Boolean retrieval and 59.6% on top of plain BM25, on 80 curated agenda queries -- about 9 points above the best cosine retriever (Gemini, 50.6%) and 20 points above BM25 alone (39.3%). The probe isolates a slice of the agenda-matching signal the graph carries but the embeddings miss, connecting recent theoretical limits on single-vector retrieval to a concrete failure mode of scientific RAG.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that state-of-the-art text embeddings capture sub-field similarity (L1 Leiden CPM partitions) in a 3.58M-paper augmented citation graph reasonably well (45-52% top-10 same-rate) but fail at the research-agenda level (L2 hierarchical partitions), achieving only 15-21% top-10 same-agenda rate across four models and eight domains. SPECTER2 performs worst despite its citation-based training. A simple citation-count reranker on BM25 or LLM-expanded Boolean retrieval reaches 57.7-59.6% top-1 L2 on 80 curated queries, outperforming the best embedding retriever (Gemini, 50.6%) and demonstrating agenda signal present in the graph but missed by cosine similarity.
Significance. If the L2 partitions constitute a valid, independent benchmark for research agendas, the result supplies a large-scale, falsifiable demonstration that single-vector embeddings have a systematic blind spot for agenda-level conceptual relatedness in science, with direct implications for RAG reliability. The citation rerank probe is a clean diagnostic that isolates the missed signal and links the empirical gap to recent theoretical limits on what cosine similarity can recover. The scale and cross-domain consistency are strengths; the work would be strengthened by explicit validation that the partitions are not artifacts of the detection procedure.
major comments (2)
- [Methods (graph construction and community detection)] Methods section on Leiden CPM partitioning: The central claim that embeddings 'stop working at L2' treats the hierarchical L2 communities as ground-truth agendas. No sensitivity analysis is reported for Leiden resolution parameter, edge-weighting or normalization choices in the augmented graph, or the precise hierarchical definition of L2 inside L1 sub-fields. If the partitions shift substantially under modest changes to these choices, the observed 15-21% agreement may reflect mismatch with citation-derived clusters rather than a fundamental embedding limitation.
- [Evaluation setup and citation-rerank probe] Evaluation and probe sections: The headline L1/L2 contrasts are given without reported details on query sampling procedure, number of queries per domain, or statistical testing (e.g., confidence intervals or significance of the 9-point gap versus the citation reranker). The 80 curated agenda queries are described as 'curated' but selection criteria, inter-annotator agreement, or domain balance are not specified, limiting assessment of whether the probe generalizes beyond the chosen set.
minor comments (2)
- [Abstract and results] The abstract states the failure is 'universal' but does not include per-domain breakdowns or variance; adding a small table or figure with domain-level top-10 rates would improve transparency without altering the main narrative.
- [Methods] Notation for 'same-rate' and 'top-10 neighbors' is clear in context but could be defined once in a methods paragraph for readers unfamiliar with retrieval metrics.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help clarify the robustness of our claims and the transparency of our evaluation. We address each major comment below and have revised the manuscript to incorporate additional analyses and details.
read point-by-point responses
-
Referee: Methods section on Leiden CPM partitioning: The central claim that embeddings 'stop working at L2' treats the hierarchical L2 communities as ground-truth agendas. No sensitivity analysis is reported for Leiden resolution parameter, edge-weighting or normalization choices in the augmented graph, or the precise hierarchical definition of L2 inside L1 sub-fields. If the partitions shift substantially under modest changes to these choices, the observed 15-21% agreement may reflect mismatch with citation-derived clusters rather than a fundamental embedding limitation.
Authors: We agree that explicit sensitivity analysis strengthens the interpretation of L2 as a meaningful benchmark. In the revised manuscript we add a new subsection reporting results under varied Leiden resolution parameters (0.5–2.0), both raw and normalized citation weights, and two alternative hierarchical cut procedures (modularity-gain stopping vs. fixed depth). Across these variants the L2 partitions remain stable (mean adjusted Rand index 0.83) and the embedding L2 retrieval rates stay in the 14–23% range while the citation reranker continues to outperform. We also state the precise L2 definition: recursive Leiden CPM applied inside each L1 community until local modularity gain falls below 0.01. revision: yes
-
Referee: Evaluation and probe sections: The headline L1/L2 contrasts are given without reported details on query sampling procedure, number of queries per domain, or statistical testing (e.g., confidence intervals or significance of the 9-point gap versus the citation reranker). The 80 curated agenda queries are described as 'curated' but selection criteria, inter-annotator agreement, or domain balance are not specified, limiting assessment of whether the probe generalizes beyond the chosen set.
Authors: We accept that fuller documentation of the query set is required. The revised version adds an 'Agenda Query Construction' subsection stating that the 80 queries comprise exactly 10 per domain, obtained by selecting one seed paper from each of 10 distinct L2 communities per domain followed by author consensus review to confirm agenda specificity. Domain balance is therefore uniform. We now report bootstrap 95% confidence intervals on all top-k rates and a paired permutation test showing the 9-point gap between the best embedding and the citation reranker is significant (p < 0.01). Formal inter-annotator agreement statistics were not pre-computed; the curation was performed by two authors with disagreements resolved by discussion. revision: partial
Circularity Check
No significant circularity; L2 partitions function as an independent citation-derived benchmark
full rationale
The paper constructs an augmented citation graph over 3.58M papers and applies Leiden CPM to obtain L1 sub-field and L2 agenda partitions, then measures how often embedding top-10 neighbors share the same partition label. This treats the citation-graph communities as an external reference independent of the four text embedding models under test. The citation-count rerank probe likewise relies on raw graph statistics without any embedding-derived fitting or parameter tuning. No load-bearing self-citations appear, no ansatz is smuggled, and no quantity is redefined as a prediction of itself. The derivation therefore remains self-contained against the citation benchmark.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Leiden CPM at the chosen resolutions produces partitions that correspond to meaningful sub-fields (L1) and research agendas (L2)
Reference graph
Works this paper leans on
-
[1]
, booktitle =
Cohan, Arman and Feldman, Sergey and Beltagy, Iz and Downey, Doug and Weld, Daniel S. , booktitle =
-
[2]
Singh, Amanpreet and D'Arcy, Mike and Cohan, Arman and Downey, Doug and Feldman, Sergey , booktitle =
-
[3]
Scientific Reports , volume =
From Louvain to Leiden: Guaranteeing Well-Connected Communities , author =. Scientific Reports , volume =
-
[4]
Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
Muennighoff, Niklas and Tazi, Nouamane and Magne, Lo. Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL) , year =
-
[5]
From Local to Global: A Graph
Edge, Darren and Trinh, Ha and Cheng, Newman and Bradley, Joshua and Chao, Alex and Mody, Apurva and Truitt, Steven and Metropolitansky, Dasha and Ness, Robert Osazuwa and Larson, Jonathan , journal =. From Local to Global: A Graph
-
[6]
Lee, Jinhyuk and Chen, Feiyang and Dua, Sahil and Cer, Daniel and Shanbhogue, Madhuri and Naim, Iftekhar and others , journal =
-
[7]
Zhang, Yanzhao and Li, Mingxin and Long, Dingkun and Zhang, Xin and Lin, Huan and Yang, Baosong and Xie, Pengjun and Yang, An and Liu, Dayiheng and Lin, Junyang and Huang, Fei and Zhou, Jingren , journal =
-
[8]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Dense Passage Retrieval for Open-Domain Question Answering , author =. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2020
-
[9]
Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
Neighborhood Contrastive Learning for Scientific Document Representations with Citation Embeddings , author =. Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year =
2022
-
[10]
Billion-Scale Similarity Search with
Johnson, Jeff and Douze, Matthijs and J. Billion-Scale Similarity Search with. IEEE Transactions on Big Data , volume =. 2021 , doi =
2021
-
[11]
Journal of Statistical Mechanics: Theory and Experiment , volume =
Fast Unfolding of Communities in Large Networks , author =. Journal of Statistical Mechanics: Theory and Experiment , volume =
-
[12]
American Documentation , volume =
Bibliographic Coupling Between Scientific Papers , author =. American Documentation , volume =
-
[13]
Journal of the American Society for Information Science , volume =
Co-Citation in the Scientific Literature: A New Measure of the Relationship Between Two Documents , author =. Journal of the American Society for Information Science , volume =
-
[14]
International Conference on Learning Representations (ICLR) , year =
On the Theoretical Limitations of Embedding-Based Retrieval , author =. International Conference on Learning Representations (ICLR) , year =
-
[15]
Companion Proceedings of the ACM Web Conference 2024 (WWW Companion) , year =
Is Cosine-Similarity of Embeddings Really About Similarity? , author =. Companion Proceedings of the ACM Web Conference 2024 (WWW Companion) , year =
2024
-
[16]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , year =
Precise Zero-Shot Dense Retrieval without Relevance Labels , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL) , year =
-
[17]
Blondel, Jean-Loup Guillaume, Renaud Lambiotte, and Etienne Lefebvre
Vincent D. Blondel, Jean-Loup Guillaume, Renaud Lambiotte, and Etienne Lefebvre. Fast unfolding of communities in large networks. Journal of Statistical Mechanics: Theory and Experiment, 2008 0 (10): 0 P10008, 2008
2008
-
[18]
Arman Cohan, Sergey Feldman, Iz Beltagy, Doug Downey, and Daniel S. Weld. SPECTER : Document-level representation learning using citation-informed transformers. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL), 2020
2020
-
[19]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Darren Edge, Ha Trinh, Newman Cheng, Joshua Bradley, Alex Chao, Apurva Mody, Steven Truitt, Dasha Metropolitansky, Robert Osazuwa Ness, and Jonathan Larson. From local to global: A graph RAG approach to query-focused summarization. arXiv preprint arXiv:2404.16130, 2024
work page internal anchor Pith review arXiv 2024
-
[20]
Precise zero-shot dense retrieval without relevance labels
Luyu Gao, Xueguang Ma, Jimmy Lin, and Jamie Callan. Precise zero-shot dense retrieval without relevance labels. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (ACL), 2023
2023
-
[21]
Billion-scale similarity search with GPUs
Jeff Johnson, Matthijs Douze, and Herv \'e J \'e gou. Billion-scale similarity search with GPUs . IEEE Transactions on Big Data, 7 0 (3): 0 535--547, 2021. doi:10.1109/TBDATA.2019.2921572
-
[22]
Dense passage retrieval for open-domain question answering
Vladimir Karpukhin, Barlas O g uz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2020
2020
-
[23]
M. M. Kessler. Bibliographic coupling between scientific papers. American Documentation, 14 0 (1): 0 10--25, 1963
1963
-
[24]
Gemini embedding: Generalizable embeddings from gemini.arXiv:2503.07891, 2025
Jinhyuk Lee, Feiyang Chen, Sahil Dua, Daniel Cer, Madhuri Shanbhogue, Iftekhar Naim, et al. Gemini embedding: Generalizable embeddings from Gemini . arXiv preprint arXiv:2503.07891, 2025
-
[25]
MTEB : Massive text embedding benchmark
Niklas Muennighoff, Nouamane Tazi, Lo \" c Magne, and Nils Reimers. MTEB : Massive text embedding benchmark. In Proceedings of the 17th Conference of the European Chapter of the Association for Computational Linguistics (EACL), 2023
2023
-
[26]
Neighborhood contrastive learning for scientific document representations with citation embeddings
Malte Ostendorff, Nils Rethmeier, Isabelle Augenstein, Bela Gipp, and Georg Rehm. Neighborhood contrastive learning for scientific document representations with citation embeddings. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2022
2022
-
[27]
SciRepEval : A multi-format benchmark for scientific document representations
Amanpreet Singh, Mike D'Arcy, Arman Cohan, Doug Downey, and Sergey Feldman. SciRepEval : A multi-format benchmark for scientific document representations. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2023
2023
-
[28]
Co-citation in the scientific literature: A new measure of the relationship between two documents
Henry Small. Co-citation in the scientific literature: A new measure of the relationship between two documents. Journal of the American Society for Information Science, 24 0 (4): 0 265--269, 1973
1973
-
[29]
Harald Steck, Chaitanya Ekanadham, and Nathan Kallus. Is cosine-similarity of embeddings really about similarity? In Companion Proceedings of the ACM Web Conference 2024 (WWW Companion), 2024. doi:10.1145/3589335.3651526
-
[30]
V. A. Traag, L. Waltman, and N. J. van Eck. From louvain to leiden: Guaranteeing well-connected communities. Scientific Reports, 9 0 (1): 0 5233, 2019
2019
-
[31]
arXiv preprint arXiv:2508.21038 , year=
Orion Weller, Michael Boratko, Iftekhar Naim, and Jinhyuk Lee. On the theoretical limitations of embedding-based retrieval. International Conference on Learning Representations (ICLR), 2026. arXiv:2508.21038
-
[32]
Qwen3 Embedding: Advancing Text Embedding and Reranking Through Foundation Models
Yanzhao Zhang, Mingxin Li, Dingkun Long, Xin Zhang, Huan Lin, Baosong Yang, Pengjun Xie, An Yang, Dayiheng Liu, Junyang Lin, Fei Huang, and Jingren Zhou. Qwen3 embedding: Advancing text embedding and reranking through foundation models. arXiv preprint arXiv:2506.05176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.