Recognition: no theorem link
Cost-Ordered Feasibility for Multi-Armed Bandits with Cost Subsidy
Pith reviewed 2026-05-11 01:16 UTC · model grok-4.3
The pith
Any policy for multi-armed bandits with cost subsidies must pull a certain number of suboptimal arms, and a new algorithm matches this with upper bounds on cost and quality regret.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper proves instance-dependent lower bounds on the expected number of suboptimal samples required by any policy in the MAB-CS setting; these bounds are a strict generalization of prior bounds. It then presents the Cost-Ordered Feasibility (COF) algorithm that orders arms by increasing cost and combines samples from all arms to determine the feasibility of cheaper arms relative to the unknown optimal reward, and establishes instance-dependent upper bounds on COF's expected cumulative cost and quality regret.
What carries the argument
Cost-Ordered Feasibility (COF) algorithm, which orders arms by known cost and pools samples across arms to test whether each cheap arm satisfies the quality constraint defined relative to the unknown best reward.
If this is right
- Any policy must incur at least a minimum number of suboptimal pulls that depends on the specific cost gaps and reward gaps of the instance.
- COF achieves instance-dependent upper bounds on both cumulative cost and quality regret that are qualitatively tighter than earlier results.
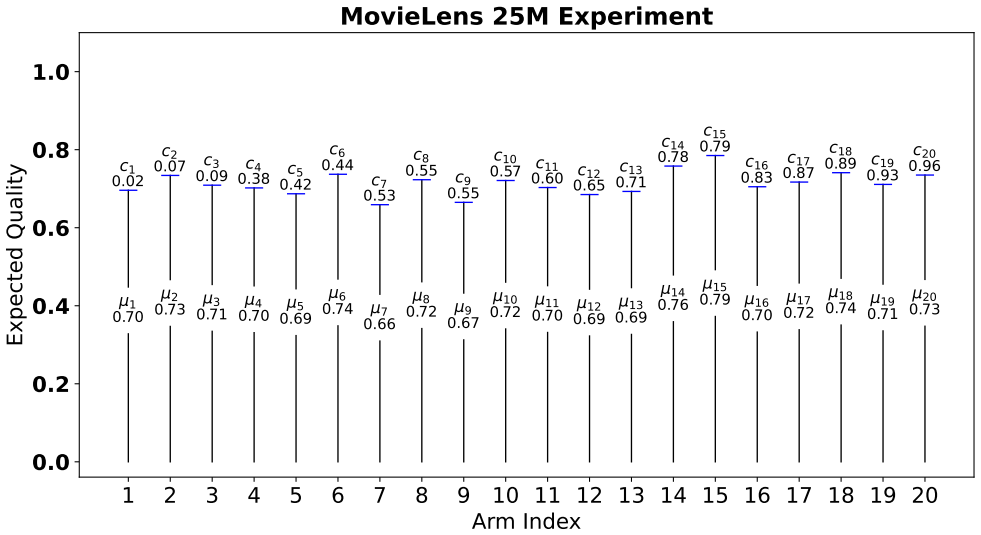
- The algorithm can be run directly on recommendation datasets such as MovieLens and Goodreads and yields lower cost and regret than standard baselines.
- The lower bounds provide structural insight into how the feasibility test interacts with the cost ordering.
Where Pith is reading between the lines
- The same ordering-plus-pooling idea could be adapted to cases where costs are also uncertain, provided cost estimates are obtained alongside reward samples.
- The feasibility-gauging step may apply to other constrained bandit problems in which one must verify that a low-cost option meets a threshold defined by an unknown optimum.
- Empirical gains on real datasets suggest the method scales to large discrete action spaces where exhaustive sampling is expensive.
Load-bearing premise
The cost of every arm is known beforehand and the quality constraint is defined relative to the unknown best reward.
What would settle it
Running COF on a concrete instance whose cost and reward gaps are known exactly and finding that its total cost or quality regret exceeds the derived upper bound by more than a constant factor would falsify the upper-bound claim.
Figures






read the original abstract
The classic multi-armed bandit (MAB) problem tackles the challenge of accruing maximum reward while making decisions under uncertainty. However, in applications, often the goal is to minimize cost subject to a constraint on the minimum permissible reward, an objective captured by multi-armed bandits with cost-subsidy (MAB-CS). Of interest to this paper is the setting where the quality (reward) constraint is specified relative to the unknown best reward and the cost of each arm is known. We characterize the expected sub-optimal samples required by any policy by proving instance-dependent lower bounds that offer new insight into the problem and are a strict generalization of prior bounds. Then, we propose an algorithm called Cost-Ordered Feasibility (COF) that leverages our insight and intelligently combine samples from all arms to gauge the feasibility of a cheap arm. Thereafter, we analyze COF to establish instance-dependent upper bounds on its expected cumulative cost and quality regret, i.e., relative to the cheapest feasible arm. Finally, we empirically validate the merits of COF, comparing it to baselines from the literature through extensive simulation experiments on the MovieLens and Goodreads datasets as well as representative synthetic instances. Not only does our paper develop qualitatively better theoretical regret upper bounds, but COF also convincingly demonstrates improved empirical performance.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper addresses multi-armed bandits with cost subsidy (MAB-CS) where arm costs are known and the quality constraint is defined relative to the unknown best reward. It derives instance-dependent lower bounds on the expected number of sub-optimal samples required by any policy, presented as a strict generalization of prior MAB bounds. The Cost-Ordered Feasibility (COF) algorithm is proposed to combine samples across arms for gauging the feasibility of low-cost arms. Instance-dependent upper bounds are established for COF on expected cumulative cost and quality regret relative to the cheapest feasible arm. The approach is validated through simulations on MovieLens, Goodreads, and synthetic instances, with claims of improved empirical performance over baselines.
Significance. If the lower and upper bounds hold as stated, the work provides meaningful new insight into the sample complexity of constrained MAB problems by extending existing lower-bound techniques to the cost-ordered setting and pairing them with an algorithm whose regret scales instance-dependently. The empirical results on recommendation datasets add practical value. The instance-dependent nature of both the bounds and the algorithm is a clear strength relative to worst-case analyses common in the literature.
minor comments (3)
- Abstract: the term 'quality regret' is introduced without a one-sentence definition; a brief parenthetical explanation would improve readability for readers unfamiliar with the exact regret definition used later.
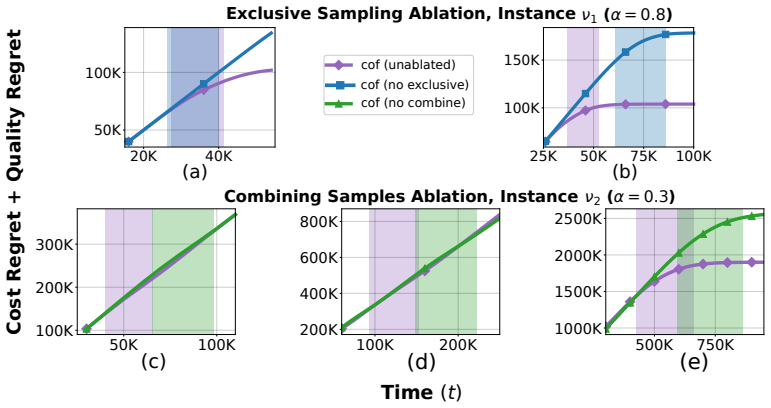
- Experiments section: details on data exclusion rules for MovieLens and Goodreads, the precise definition of the quality threshold, and how error bars are computed (e.g., number of runs, confidence intervals) are not provided; these omissions hinder reproducibility.
- COF algorithm description: while the high-level idea of combining samples to gauge feasibility is clear, a short pseudocode listing or explicit step-by-step procedure in the main text would clarify the sampling order and stopping condition.
Simulated Author's Rebuttal
We thank the referee for the positive review, accurate summary of our contributions, and recommendation for minor revision. The referee correctly identifies the value of our instance-dependent lower bounds as a generalization of prior MAB results and the practical utility of the COF algorithm paired with matching upper bounds. Since the report lists no specific major comments, we have no points requiring rebuttal or revision at this time.
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper first states the MAB-CS setting with known costs and relative quality threshold, then derives instance-dependent lower bounds on sub-optimal samples as a strict generalization of prior MAB results. It next defines the COF algorithm that uses these insights to gauge feasibility and finally proves instance-dependent upper bounds on cumulative cost and quality regret directly from the algorithm's behavior. No equation or claim reduces by construction to a fitted parameter, self-citation chain, or renamed input; the lower and upper bounds are obtained via independent analysis steps that remain falsifiable outside the fitted values.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Costs of each arm are known a priori
- standard math Rewards are drawn from unknown but fixed distributions
Reference graph
Works this paper leans on
-
[1]
Platform power struggle: Spotify and the major record labels
Luis Aguiar, Joel Waldfogel, and Axel Zeijen. Platform power struggle: Spotify and the major record labels. Technical report, National Bureau of Economic Research, 2024
work page 2024
-
[2]
On the complexity of all ε-best arms identification
Aymen Al Marjani, Tomas Kocak, and Aurélien Garivier. On the complexity of all ε-best arms identification. InJoint European Conference on Machine Learning and Knowledge Discovery in Databases, pages 317–332. Springer, 2022
work page 2022
-
[3]
Peter Auer and Ronald Ortner. Ucb revisited: Improved regret bounds for the stochastic multi-armed bandit problem.Periodica Mathematica Hungarica, 61(1-2):55–65, 2010
work page 2010
-
[4]
Finite-time analysis of the multiarmed bandit problem.Machine learning, 47(2):235–256, 2002
Peter Auer, Nicolo Cesa-Bianchi, and Paul Fischer. Finite-time analysis of the multiarmed bandit problem.Machine learning, 47(2):235–256, 2002
work page 2002
-
[5]
Ashwinkumar Badanidiyuru, Robert Kleinberg, and Aleksandrs Slivkins. Bandits with knapsacks.J. ACM, 65(3), mar 2018. ISSN 0004-5411. doi: 10.1145/3164539. URL https://doi.org/10.1145/3164539
-
[6]
Multiple identifications in multi- armed bandits
Séebastian Bubeck, Tengyao Wang, and Nitin Viswanathan. Multiple identifications in multi- armed bandits. InInternational Conference on Machine Learning, pages 258–265. PMLR, 2013
work page 2013
-
[7]
Semih Cayci, Atilla Eryilmaz, and R. Srikant. Budget-constrained bandits over general cost and reward distributions. In Silvia Chiappa and Roberto Calandra, editors,Proceedings of the Twenty Third International Conference on Artificial Intelligence and Statistics, volume 108 ofProceedings of Machine Learning Research, pages 4388–4398. PMLR, 2020. URL http...
work page 2020
-
[8]
Multi-armed bandit with budget constraint and variable costs
Wenkui Ding, Tao Qin, Xu-Dong Zhang, and Tie-Yan Liu. Multi-armed bandit with budget constraint and variable costs. InProceedings of the AAAI Conference on Artificial Intelligence, volume 27, pages 232–238, 2013. doi: 10.1609/aaai.v27i1.8637
-
[9]
Designing multi-objective multi-armed bandits algorithms: A study
Madalina M Drugan and Ann Nowe. Designing multi-objective multi-armed bandits algorithms: A study. InThe 2013 international joint conference on neural networks (IJCNN), pages 1–8. IEEE, 2013
work page 2013
-
[10]
A one-size-fits-all solution to conservative bandit problems
Yihan Du, Siwei Wang, and Longbo Huang. A one-size-fits-all solution to conservative bandit problems. InProceedings of the AAAI Conference on Artificial Intelligence, volume 35, pages 7254–7261, 2021
work page 2021
-
[11]
Multi-armed bandits with costly probes.IEEE Transactions on Information Theory, 71(1):618–643, 2025
Eray Can Elumar, Cem Tekin, and Osman Ya˘gan. Multi-armed bandits with costly probes.IEEE Transactions on Information Theory, 71(1):618–643, 2025. doi: 10.1109/TIT.2024.3506866
-
[12]
Victor Gabillon, Mohammad Ghavamzadeh, and Alessandro Lazaric. Best arm identification: A unified approach to fixed budget and fixed confidence.Advances in neural information processing systems, 25, 2012
work page 2012
-
[13]
Aurélien Garivier, Emilie Kaufmann, and Tor Lattimore. Explore first, exploit next: The true shape of regret in bandit problems.Mathematics of Operations Research, 44(2):377–408, 2019
work page 2019
-
[14]
F. Maxwell Harper and Joseph A. Konstan. The movielens datasets: History and context.ACM Trans. Interact. Intell. Syst., 5(4), dec 2015. ISSN 2160-6455. doi: 10.1145/2827872. URL https://doi.org/10.1145/2827872
-
[15]
Hooshang Tadrisi Javan, Amir Khanlari, Omid Motamedi, and Hadi Mokhtari. A hybrid advertising media selection model using ahp and fuzzy-based ga decision making.Neural Computing and Applications, 29(4):1153–1167, 2018
work page 2018
-
[16]
Universal Model Routing for Efficient LLM Inference.arXiv preprint arXiv:2502.08773, 2025
Wittawat Jitkrittum, Harikrishna Narasimhan, Ankit Singh Rawat, Jeevesh Juneja, Congchao Wang, Zifeng Wang, Alec Go, Chen-Yu Lee, Pradeep Shenoy, Rina Panigrahy, et al. Universal model routing for efficient llm inference.arXiv preprint arXiv:2502.08773, 2025. 10
-
[17]
Pairwise elimination with instance- dependent guarantees for bandits with cost subsidy
Ishank Juneja, Carlee Joe-Wong, and Osman Ya ˘gan. Pairwise elimination with instance- dependent guarantees for bandits with cost subsidy. InInternational Conference on Learning Representations (ICLR), 2025. URLhttps://openreview.net/forum?id=eB7T1bqthA
work page 2025
-
[18]
Efficient selection of multiple bandit arms: theory and practice
Shivaram Kalyanakrishnan and Peter Stone. Efficient selection of multiple bandit arms: theory and practice. InProceedings of the 27th International Conference on International Conference on Machine Learning, pages 511–518, 2010
work page 2010
-
[19]
Cost aware best arm identification.arXiv preprint arXiv:2402.16710, 2024
Kellen Kanarios, Qining Zhang, and Lei Ying. Cost aware best arm identification.arXiv preprint arXiv:2402.16710, 2024
-
[20]
Cambridge University Press, 2020
Tor Lattimore and Csaba Szepesvári.Bandit Algorithms. Cambridge University Press, 2020
work page 2020
-
[21]
Anatomy of a machine learning ecosystem: 2 million models on hugging face, 2025
Benjamin Laufer, Hamidah Oderinwale, and Jon Kleinberg. Anatomy of a machine learning ecosystem: 2 million models on hugging face, 2025. URL https://arxiv.org/abs/2508. 06811
work page 2025
-
[22]
Blake Mason, Lalit Jain, Ardhendu Tripathy, and Robert Nowak. Finding all ϵ-good arms in stochastic bandits.Advances in Neural Information Processing Systems, 33:20707–20718, 2020
work page 2020
-
[23]
Jordan W Moffett, Judith Anne Garretson Folse, and Robert W Palmatier. A theory of mul- tiformat communication: mechanisms, dynamics, and strategies.Journal of the Academy of Marketing Science, 49(3):441–461, 2021
work page 2021
-
[24]
Multi-armed bandits with cost subsidy
Abhishek Sinha, Aditya Gopalan, and Shie Mannor. Multi-armed bandits with cost subsidy. InProceedings of the 38th International Conference on Machine Learning, volume 130 of Proceedings of Machine Learning Research, pages 9734–9744. PMLR, 2021
work page 2021
-
[25]
How royalties work on spotify, 2026
Spotify for Artists. How royalties work on spotify, 2026. URLhttps://artists.spotify. com/royalties-guide. Accessed: 2026-04-27
work page 2026
-
[26]
Epsilon–first policies for budget–limited multi-armed bandits
Long Tran-Thanh, Archie Chapman, Enrique Munoz De Cote, Alex Rogers, and Nicholas R Jennings. Epsilon–first policies for budget–limited multi-armed bandits. InProceedings of the AAAI Conference on Artificial Intelligence, volume 24, pages 1211–1216, 2010
work page 2010
-
[27]
Knapsack based optimal policies for budget–limited multi–armed bandits
Long Tran-Thanh, Archie Chapman, Alex Rogers, and Nicholas Jennings. Knapsack based optimal policies for budget–limited multi–armed bandits. InProceedings of the AAAI Conference on Artificial Intelligence, volume 26, pages 1134–1140, 2012
work page 2012
-
[28]
Asterios Tsiourvas, Wei Sun, and Georgia Perakis. Causal llm routing: End-to-end regret minimization from observational data.arXiv preprint arXiv:2505.16037, 2025
-
[29]
Item recommendation on monotonic behavior chains
Mengting Wan and Julian McAuley. Item recommendation on monotonic behavior chains. In Proceedings of the 12th ACM conference on recommender systems, pages 86–94, 2018
work page 2018
-
[30]
Fine-grained spoiler detection from large-scale review corpora
Mengting Wan, Rishabh Misra, Ndapa Nakashole, and Julian McAuley. Fine-grained spoiler detection from large-scale review corpora. In Anna Korhonen, David Traum, and Lluís Màrquez, editors,Proceedings of the 57th Annual Meeting of the Association for Computational Linguis- tics, pages 2605–2610, Florence, Italy, July 2019. Association for Computational Lin...
-
[31]
Learning to route llms from bandit feedback,
Wang Wei, Tiankai Yang, Hongjie Chen, Yue Zhao, Franck Dernoncourt, Ryan A Rossi, and Hoda Eldardiry. Learning to route llms from bandit feedback: One policy, many trade-offs. arXiv preprint arXiv:2510.07429, 2025
-
[32]
Efficient training-free online routing for high-volume multi-llm serving
Fangzhou Wu and Sandeep Silwal. Efficient training-free online routing for high-volume multi-llm serving. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025
work page 2025
-
[33]
Yifan Wu, Roshan Shariff, Tor Lattimore, and Csaba Szepesvari. Conservative bandits. In Maria Florina Balcan and Kilian Q. Weinberger, editors,Proceedings of The 33rd International Conference on Machine Learning, volume 48 ofProceedings of Machine Learning Research, pages 1254–1262, New York, New York, USA, 20–22 Jun 2016. PMLR. URL https:// proceedings.m...
work page 2016
-
[34]
Thompson sampling for bud- geted multi-armed bandits
Yingce Xia, Haifang Li, Tao Qin, Nenghai Yu, and Tie-Yan Liu. Thompson sampling for bud- geted multi-armed bandits. InProceedings of the Twenty-Fourth International Joint Conference on Artificial Intelligence, pages 3960–3966. AAAI Press, 2015
work page 2015
-
[35]
Budgeted bandit problems with continuous random costs
Yingce Xia, Wenkui Ding, Xu-Dong Zhang, Nenghai Yu, and Tao Qin. Budgeted bandit problems with continuous random costs. In Geoffrey Holmes and Tie-Yan Liu, editors,Asian Conference on Machine Learning, volume 45 ofProceedings of Machine Learning Research, pages 317–332. PMLR, 2016. URL https://proceedings.mlr.press/v45/Xia15.html
work page 2016
-
[36]
The value of personalized recommendations: Evidence from netflix
Kevin Zielnicki, Guy Aridor, Aurelien Bibaut, Allen Tran, Winston Chou, and Nathan Kallus. The value of personalized recommendations: Evidence from netflix. Technical Report 12257, CESifo Working Paper Series, 2025. 12 A Additional Experiments and Details In this section we include all the empirical results and documentation supporting the experiments for...
work page 2025
-
[38]
3(b) perform the following sequence of steps:
Run ./scripts/plot_regret_vs_time.sh after making sure the correct destination of log files is hard coded into the bash file • To generate Fig. 3(b) perform the following sequence of steps:
-
[39]
All resource path based commands from here on out will be relative to the parent directory
Run ./scripts/run_good_reads.sh from the project parent directory. All resource path based commands from here on out will be relative to the parent directory. This will save the log file intoresults/run_logs
-
[40]
3(c) perform the following sequence of steps:
Run ./scripts/plot_only.sh after making sure the correct destination of log files is hard coded into the bash file 13 • To generate Fig. 3(c) perform the following sequence of steps:
-
[42]
3(d) perform the following sequence of steps:
Run ./scripts/plot_regret_vs_time.sh after making sure the correct destination of log files is hard coded into the bash file • To generate Fig. 3(d) perform the following sequence of steps:
-
[43]
All resource path based commands from here on out will be relative to the parent directory
Run ./scripts/run_movie_lens.sh from the project parent directory. All resource path based commands from here on out will be relative to the parent directory. This will save the log file intoresults/run_logs
-
[44]
Run ./scripts/plot_only.sh after making sure the correct destination of log files is hard coded into the bash file The other bash scripts in./scriptsare used to generate the plots available here in this supplemental experiments section. Computational resources and wall-clock execution time To run our bandit experiments we used a machine with the below con...
-
[45]
That is, any arm included inA † is also a part of otherA ℓ for any cheapa ℓ
As remarked in D.6,A † ⊆ A ℓ. That is, any arm included inA † is also a part of otherA ℓ for any cheapa ℓ
-
[46]
Since(∆ k,ℓ −3β) + = max{∆k,ℓ −3β,0}, and∆ k,ℓ = (1−α)µ k −µ ℓ, we have∆ k,† ≤∆ k,ℓ ∀ℓ < a ∗. Starting with the general feasibility condition forτ ℓ and applying our two observations, X ak∈Aℓ I n≤ 8 log(1/δ) ∆2 k (∆k,ℓ −3β) + 2 ≥ X ak∈A† I n≤ 8 log(1/δ) ∆2 k (∆k,† −3β) + 2 . Which in turn means thatτ ℓ(δ)as defined in Equation 42 is not more thanτ †(δ). L...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.