Recognition: no theorem link
The Text Uncanny Valley: Non-Monotonic Performance Degradation in LLM Information Retrieval
Pith reviewed 2026-05-11 02:49 UTC · model grok-4.3
The pith
LLMs show a U-shaped drop in accuracy when detecting information in text that has been partially fragmented by inserted spaces inside words.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
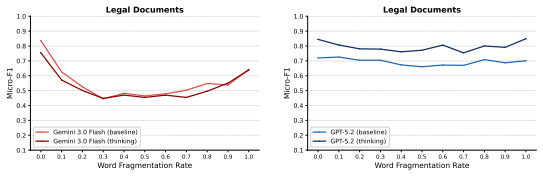
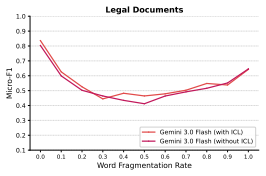
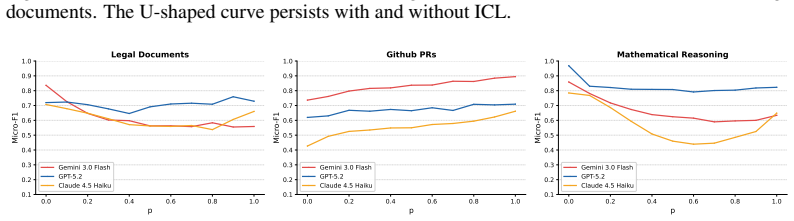
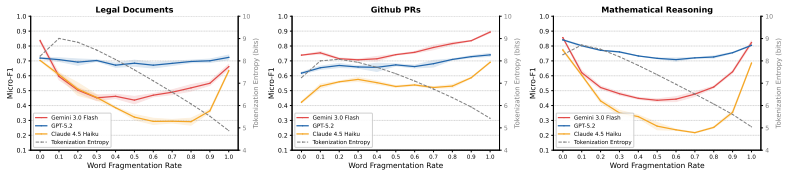
By inserting whitespace characters inside words at increasing rates, LLMs' detection accuracy follows a U-shaped curve. The authors call this the Text Uncanny Valley and attribute it to a mode transition: models rely on word-level processing for near-normal text and shift to character-level processing for heavily fragmented text, leaving an ineffective intermediate regime where neither mode works well. Four experiments support the account: in-context learning does not lift valley-bottom performance, regularizing the inserted spaces flattens the U-shape, a math reasoning task shows the same pattern for one model but not stronger ones, and tokenization entropy peaks before the accuracy minimum
What carries the argument
The mode transition hypothesis: LLMs toggle between word-level processing for intact text and character-level processing for broken text, with the valley marking the disordered middle ground.
If this is right
- Clean-text benchmarks miss a failure mode that appears as soon as real-world inputs contain moderate word-boundary noise.
- In-context examples do not close the performance gap at the bottom of the valley.
- Tasks that depend less on exact lexical matching show a shallower or absent valley, especially in stronger models.
- Tokenization statistics already signal the conflicting regime before accuracy reaches its lowest point.
Where Pith is reading between the lines
- The same non-monotonic pattern may appear in other retrieval or classification tasks when inputs contain partial word corruption.
- Training or fine-tuning on a continuous range of fragmentation levels could reduce or remove the valley.
- Different corruption methods, such as character deletions or substitutions, could be tested to check whether the valley is tied to whitespace insertion specifically.
Load-bearing premise
That the performance dip is caused specifically by a disordered switch between word-level and character-level reading modes rather than by tokenization side effects or other task features.
What would settle it
Measuring whether the U-shaped curve disappears when the same fragmentation is applied but token boundaries are held constant, or when models are explicitly prompted to stay in one processing mode throughout.
Figures





read the original abstract
Existing Large Language Model (LLM) benchmarks primarily focus on syntactically correct inputs, leaving a significant gap in evaluation on imperfect text. In this work, we study how word-boundary corruption affects how LLMs detect targeted information. By inserting whitespace characters within words to break them into fragments, LLMs' detection accuracy follows a U-shaped curve with the increase in insertion rate. We refer to this curve as the Text Uncanny Valley. To explain such observation, we propose a mode transition hypothesis: LLMs operate in a word-level mode for near-normal text and a character-level mode for heavily fragmented text, with the valley marking the disordered transition where neither mode is effective. Four experiments and one analysis are consistent with this account: in-context learning fails to rescue valley-bottom performance; regularizing the perturbation substantially reduces the U-shape; a math reasoning task replicates the U-shape for Gemini 3.0 Flash but not for stronger models, suggesting the effect is attenuated when tasks rely less on exact lexical alignment; and tokenization entropy peaks before the F1 minimum, consistent with a regime-conflict interpretation. These findings reveal a failure mode invisible to clean-text benchmarks yet directly relevant to any deployment scenario involving noisy or uncurated text inputs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript reports that inserting whitespace characters within words to corrupt word boundaries causes LLMs' detection accuracy on targeted information retrieval tasks to follow a U-shaped curve as insertion rate increases, termed the 'Text Uncanny Valley'. The authors propose a mode transition hypothesis in which LLMs operate in a word-level mode for near-normal text and shift to a character-level mode for heavily fragmented text, with the valley bottom marking a disordered transitional regime where neither mode is effective. This is supported by four experiments (in-context learning fails to rescue valley performance; regularization of the perturbation reduces the U-shape; a math reasoning task replicates the U-shape for Gemini 3.0 Flash but not stronger models; tokenization entropy peaks before the F1 minimum) and one analysis presented as consistent with the hypothesis.
Significance. If the reported U-shaped degradation and its interpretation hold after addressing alternative explanations, the work identifies a robustness failure mode in LLMs for noisy or uncurated text that is invisible to standard clean-text benchmarks. This has direct implications for real-world deployments involving imperfect inputs and could motivate new evaluation protocols and training strategies focused on handling fragmentation.
major comments (2)
- [tokenization entropy analysis] The tokenization entropy analysis (described in the abstract and supporting the mode transition hypothesis) shows entropy peaking before the F1 minimum and is presented as consistent with regime conflict. However, this pattern is equally predicted by subword tokenizer fragmentation artifacts alone, which increase tokenization entropy and induce input distribution shift without any internal mode transition. The manuscript provides no controls (e.g., comparison across tokenizers with differing subword granularity, measurement of token-level vs. character-level accuracy, or ablation holding token count fixed) to isolate the hypothesized internal processing modes from these surface effects. This is load-bearing for the central explanatory claim.
- [regularization experiment] The regularization experiment (abstract) is reported to substantially reduce the U-shape and is taken to support the mode transition account. Yet regularizing the perturbation also directly reduces the degree of BPE boundary disruption; without a matched control that preserves fragmentation while altering other factors, the result does not discriminate between the mode-transition hypothesis and a simpler distribution-shift account.
minor comments (2)
- [Abstract] The abstract states that four experiments and one analysis are 'consistent with this account' but does not report effect sizes, confidence intervals, or exact insertion-rate values at which the valley minimum occurs; including these quantitative details would strengthen verifiability.
- The manuscript would benefit from a table summarizing F1 scores or accuracy across insertion rates for each experiment, along with the precise definition of 'insertion rate' and the method of whitespace placement (e.g., uniform random vs. fixed positions).
Simulated Author's Rebuttal
Thank you for the constructive review. We address the two major comments below on the tokenization entropy analysis and regularization experiment. We propose revisions to clarify the evidential weight of these results while preserving the reported findings and overall hypothesis.
read point-by-point responses
-
Referee: The tokenization entropy analysis (described in the abstract and supporting the mode transition hypothesis) shows entropy peaking before the F1 minimum and is presented as consistent with regime conflict. However, this pattern is equally predicted by subword tokenizer fragmentation artifacts alone, which increase tokenization entropy and induce input distribution shift without any internal mode transition. The manuscript provides no controls (e.g., comparison across tokenizers with differing subword granularity, measurement of token-level vs. character-level accuracy, or ablation holding token count fixed) to isolate the hypothesized internal processing modes from these surface effects. This is load-bearing for the central explanatory claim.
Authors: We agree that the entropy analysis alone cannot isolate hypothesized internal mode transitions from surface-level tokenizer fragmentation and distribution shift effects. The manuscript presents the entropy peak as consistent with regime conflict rather than as definitive evidence. The mode transition hypothesis rests on the joint pattern across all four experiments and the analysis. In revision we will add explicit discussion noting that the observed entropy pattern is also predicted by tokenizer artifacts, weaken the interpretive language around this specific result, and include a limitations paragraph on the absence of the suggested controls (tokenizer comparisons, token vs. character accuracy, fixed-token ablations). This addresses the concern directly. revision: yes
-
Referee: The regularization experiment (abstract) is reported to substantially reduce the U-shape and is taken to support the mode transition account. Yet regularizing the perturbation also directly reduces the degree of BPE boundary disruption; without a matched control that preserves fragmentation while altering other factors, the result does not discriminate between the mode-transition hypothesis and a simpler distribution-shift account.
Authors: We acknowledge that uniform regularization of insertions necessarily reduces both disorder and the degree of BPE boundary disruption, so the experiment does not furnish a fully matched control separating fragmentation level from transition disorder. The design aimed to show that lowering the disordered character of the perturbation attenuates the valley. We will revise the manuscript to describe the regularization procedure in more detail, present the result as consistent with but not conclusive for the mode-transition account, and note the alternative distribution-shift interpretation explicitly. revision: yes
Circularity Check
No significant circularity; empirical observation and hypothesis supported by independent tests.
full rationale
The paper reports an observed U-shaped performance curve under increasing word-fragmentation insertions and proposes a mode-transition hypothesis (word-level to character-level processing) as an interpretive account. The hypothesis is not derived from first principles or equations that reduce to the inputs; instead, it is evaluated through four distinct experiments (in-context learning rescue failure, regularization of perturbations, math-task replication across model strengths, and tokenization-entropy timing) plus one analysis. These tests are described as providing consistent external evidence rather than tautological fits or self-referential definitions. No load-bearing self-citations, ansatzes smuggled via prior work, or renamed known results appear in the derivation chain. The central claim remains self-contained against the reported benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLMs process text via distinct word-level and character-level modes depending on input fragmentation level
invented entities (1)
-
mode transition hypothesis
no independent evidence
Reference graph
Works this paper leans on
-
[2]
URL https://arxiv. org/abs/2504.02733. S. Alqahtani, M. T. Nayeem, M. T. R. Laskar, T. Mohiuddin, and M. S. Bari. Stop taking tokenizers for granted: They are core design decisions in large language models. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8410–8432,
-
[3]
URL https://aclanthology.org/2026.eacl-long. 394/. Anthropic. System card: Claude Haiku 4.5. https://anthropic.com/ claude-haiku-4-5-system-card,
work page 2026
-
[4]
Y . Chai, Y . Fang, Q. Peng, and X. Li. Tokenization falling short: On subword robustness in large language models. InFindings of the Association for Computational Linguistics: EMNLP 2024, pages 1582–1599,
work page 2024
-
[6]
Training Verifiers to Solve Math Word Problems
URLhttps://arxiv.org/abs/2110.14168. DeepSeek-AI. DeepSeek-V3 technical report.arXiv preprint arXiv:2412.19437,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
URL https://arxiv.org/abs/2412.19437. H. Y . Fu, A. Shrivastava, J. Moore, P. West, C. Tan, and A. Holtzman. Absence Bench: Language models can’t see what’s missing. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track,
work page internal anchor Pith review Pith/arXiv arXiv
- [8]
-
[10]
URLhttps://arxiv.org/abs/2404.06654. A. Jain and A. Garimella. Knowing what’s missing: Assessing information sufficiency in question answering. InFindings of the Association for Computational Linguistics: EACL 2026, pages 4163–4174,
work page internal anchor Pith review arXiv 2026
- [11]
-
[13]
URLhttps://arxiv.org/abs/2502.16781. M. Sclar, Y . Choi, Y . Tsvetkov, and A. Suhr. Quantifying language models’ sensitivity to spurious features in prompt design or: How I learned to start worrying about prompt formatting. In Proceedings of the International Conference on Learning Representations (ICLR),
- [14]
- [16]
-
[18]
URL https://arxiv.org/abs/2505.09388. Z. Yang, S. Yang, L. Hu, and D. Wang. Word recovery in large language models enables character- level tokenization robustness.arXiv preprint arXiv:2603.10771,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
URL https://arxiv. org/abs/2603.10771. A. Zhuo, X. Ning, N. Li, Y . Wang, and P. Lu. On the ability of LLMs to handle character-level perturbations: How well and how?arXiv preprint arXiv:2510.14365,
-
[20]
URL https: //arxiv.org/abs/2510.14365. 11 A Limitations Indirect mechanism evidence.Our two-modes hypothesis rests on behavioral observations and tokenization statistics rather than internal model states. A direct mechanistic account would require access to attention patterns or layer-wise activations, none of which are available through black-box APIs. T...
-
[21]
and evalu- ate each model on each problem independently at eleven word_fragmentation_rate levels (0.0,0.1, . . . ,1.0 ). Each API call consists of a single fragmented problem; thinking mode is disabled for all models to isolate tokenization level effects. Accuracy is measured by exact numerical match, with tolerance for minor formatting differences (e.g.,...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.