Recognition: no theorem link
PersonaGest: Personalized Co-Speech Gesture Generation with Semantic-Guided Hierarchical Motion Representation
Pith reviewed 2026-05-11 02:25 UTC · model grok-4.3
The pith
A two-stage framework with semantic-aware motion codes generates co-speech gestures that match both speech meaning and a user reference style.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
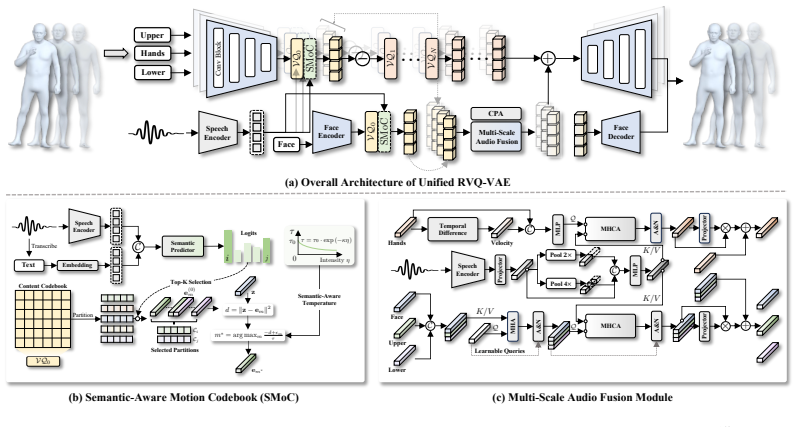
PersonaGest is a two-stage framework for co-speech gesture generation. In the first stage a semantic-guided RVQ-VAE incorporates a Semantic-Aware Motion Codebook (SMoC) that organizes the content codebook by gesture semantics and applies contrastive learning to enforce separation of content from gestural style. In the second stage a Masked Generative Transformer produces content tokens via semantic-aware re-masking, after which a cascade of Style Residual Transformers conditions the output on a reference motion prompt to control style. This design overcomes the inability of earlier VQ-VAE methods to encode semantic structure or explicitly disentangle content from style.
What carries the argument
Semantic-Aware Motion Codebook (SMoC) inside the residual vector-quantized VAE, which structures codes by gesture semantics and pairs with contrastive learning to separate motion content from style.
If this is right
- Generated gestures exhibit higher semantic alignment with the input speech than earlier VQ-VAE baselines.
- Style is transferred more faithfully when a reference motion prompt is supplied.
- Objective metrics and perceptual user studies both report state-of-the-art results.
- The hierarchical representation supports independent manipulation of semantic content and stylistic execution.
Where Pith is reading between the lines
- The same semantic-guided codebook construction could be applied to other motion domains such as dance or sign-language synthesis where meaning and expression must remain separable.
- The two-stage pipeline might combine with large language models to produce gestures directly from conversational text without manual reference prompts.
- If the disentanglement generalizes, the method could support real-time style switching in virtual-reality avatars or accessibility tools.
Load-bearing premise
The Semantic-Aware Motion Codebook together with contrastive learning in the RVQ-VAE stage can disentangle semantic content from gestural style without losing motion fidelity or introducing artifacts.
What would settle it
If ablation experiments that remove the semantic guidance or the contrastive loss show no measurable drop in semantic coherence scores, style consistency to the reference prompt, or human preference ratings on the same test set, the claimed benefit of the disentanglement mechanism would be refuted.
Figures







read the original abstract
Co-speech gesture generation aims to synthesize realistic body movements that are semantically coherent with speech and faithful to a user-specified gestural style. Existing VQ-VAE based co-speech gesture generation methods improve generation quality but fail to encode semantic structure into the motion representation or explicitly disentangle content from style, limiting both semantic coherence and personalization fidelity. We present PersonaGest, a two-stage framework addressing both limitations. In the first stage, a semantic-guided RVQ-VAE disentangles motion content and gestural style within the residual quantization structure, where a Semantic-Aware Motion Codebook (SMoC) organizes the content codebook by gesture semantics and contrastive learning further enforces content-style separation. In the second stage, a Masked Generative Transformer generates content tokens via a semantic-aware re-masking strategy, followed by a cascade of Style Residual Transformers conditioned on a reference motion prompt for style control. Extensive experiments demonstrate state-of-the-art performance on objective metrics and perceptual user studies, with strong style consistency to the reference prompt. Our project page with demo videos is available at https://danny-nus.github.io/PersonaGest/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents PersonaGest, a two-stage framework for personalized co-speech gesture generation. The first stage uses a semantic-guided RVQ-VAE with a Semantic-Aware Motion Codebook (SMoC) that organizes content codebooks by gesture semantics, combined with contrastive learning to disentangle motion content from gestural style. The second stage consists of a Masked Generative Transformer that generates content tokens via semantic-aware re-masking, followed by a cascade of Style Residual Transformers conditioned on a reference motion prompt for style control. The authors claim this yields state-of-the-art performance on objective metrics and perceptual user studies, with strong style consistency to the reference prompt.
Significance. If the disentanglement and performance claims hold, the work would advance co-speech gesture synthesis by explicitly separating semantic content from style in hierarchical motion representations, enabling more coherent and personalized outputs for applications in virtual avatars and animation. The two-stage transformer cascade and project page with demo videos provide a concrete, inspectable contribution that could serve as a baseline for future motion generation research.
major comments (2)
- [§3.2] §3.2 (Semantic-Guided RVQ-VAE): The claim that SMoC combined with contrastive learning successfully disentangles content from style without losing motion fidelity is load-bearing for the central contribution, yet the manuscript provides insufficient detail on how semantic labels are assigned to codebook entries or how the contrastive loss is formulated to enforce separation (e.g., positive/negative pair construction); this risks the separation being post-hoc rather than structurally enforced.
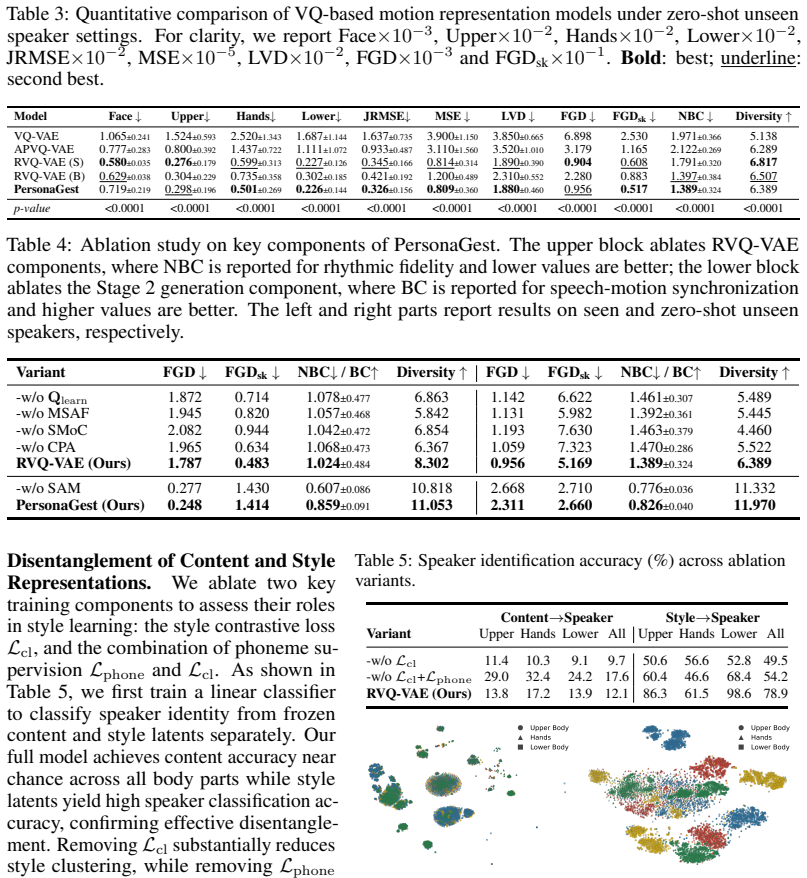
- [§4.2] §4.2 (Ablation Studies): The reported gains from the full model over the RVQ-VAE baseline on semantic coherence metrics are not accompanied by quantitative diagnostics (such as mutual information between content codes and style attributes or reconstruction error under style swaps); without these, it is difficult to confirm that the disentanglement is effective rather than an artifact of the evaluation protocol.
minor comments (2)
- [Abstract] The abstract and §1 should explicitly name the datasets (e.g., BEAT, Trinity) and list the exact baselines used for the SOTA claim to allow immediate comparison.
- [§3.3] Notation for the residual quantization levels and the re-masking strategy in §3.3 could be clarified with a small diagram or pseudocode to improve readability for readers unfamiliar with RVQ-VAE variants.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments on our manuscript. We address each major comment point-by-point below. Where the feedback identifies areas needing greater clarity or additional evidence, we will revise the manuscript accordingly to strengthen the presentation of our contributions.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Semantic-Guided RVQ-VAE): The claim that SMoC combined with contrastive learning successfully disentangles content from style without losing motion fidelity is load-bearing for the central contribution, yet the manuscript provides insufficient detail on how semantic labels are assigned to codebook entries or how the contrastive loss is formulated to enforce separation (e.g., positive/negative pair construction); this risks the separation being post-hoc rather than structurally enforced.
Authors: We agree that Section 3.2 would benefit from expanded implementation details to ensure the disentanglement mechanism is fully transparent. In the revised manuscript, we will add: (i) a precise description of the semantic label assignment process for SMoC entries, including how gesture semantics are derived from a pre-trained classifier on the training data and used to organize the codebook hierarchically; and (ii) the full mathematical formulation of the contrastive loss, with explicit construction of positive pairs (same semantic content, varying style) and negative pairs (different semantics). These additions will demonstrate that separation is enforced structurally via the codebook design and loss, rather than emerging post-hoc from evaluation. We will also include a small diagram illustrating the label-to-codebook mapping. revision: yes
-
Referee: [§4.2] §4.2 (Ablation Studies): The reported gains from the full model over the RVQ-VAE baseline on semantic coherence metrics are not accompanied by quantitative diagnostics (such as mutual information between content codes and style attributes or reconstruction error under style swaps); without these, it is difficult to confirm that the disentanglement is effective rather than an artifact of the evaluation protocol.
Authors: We acknowledge that the current ablation results in Section 4.2 rely primarily on downstream semantic coherence and style consistency metrics, which could be strengthened by direct diagnostics of disentanglement. In the revision, we will augment the ablation study with two new quantitative measures: (1) mutual information between the content code indices and style attributes (computed via a style classifier) to quantify independence, and (2) reconstruction error when swapping style codes across different content sequences. These will be reported alongside the existing metrics to provide direct evidence that content remains stable under style variation. We have already computed these diagnostics on our trained models and will include the results and analysis in the updated Section 4.2. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper introduces a new two-stage neural architecture (semantic-guided RVQ-VAE with SMoC codebook plus contrastive loss, followed by masked transformer cascade) for co-speech gesture generation. No equations, fitted parameters renamed as predictions, or self-citation chains are present in the text that would reduce any claimed result to its own inputs by construction. Performance claims rest on external experimental metrics and user studies rather than internal re-derivation. This is a standard empirical ML contribution with independent content.
Axiom & Free-Parameter Ledger
free parameters (2)
- RVQ-VAE codebook sizes and residual quantization levels
- Contrastive learning temperature and loss weights
axioms (2)
- domain assumption Body motion sequences can be effectively tokenized and disentangled into semantic content and gestural style using residual vector quantization augmented with semantic awareness.
- domain assumption Speech input provides sufficient semantic cues to guide content token generation via masked prediction.
invented entities (1)
-
Semantic-Aware Motion Codebook (SMoC)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Nakano, and Louis-Philippe Morency
Chaitanya Ahuja, Dong Won Lee, Yukiko I. Nakano, and Louis-Philippe Morency. Style transfer for co-speech gesture animation: A multi-speaker conditional-mixture approach. In Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part XVIII, pages 248–265, 2020
work page 2020
-
[2]
Low-resource adaptation for personalized co-speech gesture generation
Chaitanya Ahuja, Dong Won Lee, and Louis-Philippe Morency. Low-resource adaptation for personalized co-speech gesture generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 20534– 20544, 2022
work page 2022
-
[3]
Continual learning for personalized co-speech gesture generation
Chaitanya Ahuja, Pratik Joshi, Ryo Ishii, and Louis-Philippe Morency. Continual learning for personalized co-speech gesture generation. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 20836–20846, 2023
work page 2023
-
[4]
Ghazanfar Ali, Woojoo Kim, Muhammad Shahid Anwar, Jae-In Hwang, and Ahyoung Choi. Expanding multilingual co-speech interaction: The impact of enhanced gesture units in text-to- gesture synthesis for digital humans.IEEE Access, 13:145144–145157, 2025
work page 2025
-
[5]
Text2gestures: A transformer-based network for generating emotive body gestures for virtual agents
Uttaran Bhattacharya, Nicholas Rewkowski, Abhishek Banerjee, Pooja Guhan, Aniket Bera, and Dinesh Manocha. Text2gestures: A transformer-based network for generating emotive body gestures for virtual agents. InIEEE Virtual Reality and 3D User Interfaces, VR 2021, Lisbon, Portugal, March 27 - April 1, 2021, pages 160–169, 2021
work page 2021
-
[6]
Badler, Mark Steedman, Brett Achorn, Tripp Becket, Brett Douville, Scott Prevost, and Matthew Stone
Justine Cassell, Catherine Pelachaud, Norman I. Badler, Mark Steedman, Brett Achorn, Tripp Becket, Brett Douville, Scott Prevost, and Matthew Stone. Animated conversation: rule- based generation of facial expression, gesture & spoken intonation for multiple conversational agents. InProceedings of the 21th Annual Conference on Computer Graphics and Interac...
work page 1994
-
[7]
Huiwen Chang, Han Zhang, Lu Jiang, Ce Liu, and William T. Freeman. Maskgit: Masked generative image transformer. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 11305–11315, 2022
work page 2022
-
[8]
Enabling synergistic full-body control in prompt-based co-speech motion generation
Bohong Chen, Yumeng Li, Yao-Xiang Ding, Tianjia Shao, and Kun Zhou. Enabling synergistic full-body control in prompt-based co-speech motion generation. InProceedings of the 32nd ACM International Conference on Multimedia, pages 6774–6783, 2024
work page 2024
-
[9]
Lakshmikanth, Yusu Fang, Ruizhi Shao, Gordon Wetzstein, Li Fei-Fei, and Ehsan Adeli
Changan Chen, Juze Zhang, Shrinidhi K. Lakshmikanth, Yusu Fang, Ruizhi Shao, Gordon Wetzstein, Li Fei-Fei, and Ehsan Adeli. The language of motion: Unifying verbal and non- verbal language of 3d human motion. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2025, Nashville, TN, USA, June 11-15, 2025, pages 6200–6211, 2025
work page 2025
-
[10]
Junming Chen, Yunfei Liu, Jianan Wang, Ailing Zeng, Yu Li, and Qifeng Chen. Diffsheg: A diffusion-based approach for real-time speech-driven holistic 3d expression and gesture generation. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 7352–7361, 2024
work page 2024
-
[11]
A weighted overlap-add method of short-time fourier analysis/synthesis
Ronald Crochiere. A weighted overlap-add method of short-time fourier analysis/synthesis. IEEE Transactions on Acoustics, Speech, and Signal Processing, 28(1):99–102, 1980
work page 1980
-
[12]
Minh Duc Dang, Samira Pulatova, and Lawrence H. Kim. User-defined co-speech gesture design with swarm robots. InProceedings of the 2025 CHI Conference on Human Factors in Computing Systems, CHI 2025, YokohamaJapan, 26 April 2025- 1 May 2025, pages 787:1–787:15, 2025
work page 2025
-
[13]
Chenjing Ding, Chiyu Wang, Boshi Liu, Xi Guo, Weixuan Tang, and Wei Wu. Sgc-vqgan: Towards complex scene representation via semantic guided clustering codebook.arXiv preprint arXiv:2409.06105, 2024
-
[14]
Troje, and Marc-André Carbonneau
Saeed Ghorbani, Ylva Ferstl, Daniel Holden, Nikolaus F. Troje, and Marc-André Carbonneau. Zeroeggs: Zero-shot example-based gesture generation from speech.Comput. Graph. Forum, 42(1):206–216, 2023. 10
work page 2023
-
[15]
Learning individual styles of conversational gesture
Shiry Ginosar, Amir Bar, Gefen Kohavi, Caroline Chan, Andrew Owens, and Jitendra Malik. Learning individual styles of conversational gesture. InIEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019, pages 3497– 3506, 2019
work page 2019
-
[16]
Generating diverse and natural 3d human motions from text
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2022, New Orleans, LA, USA, June 18-24, 2022, pages 5142–5151, 2022
work page 2022
-
[17]
Momask: Generative masked modeling of 3d human motions
Chuan Guo, Yuxuan Mu, Muhammad Gohar Javed, Sen Wang, and Li Cheng. Momask: Generative masked modeling of 3d human motions. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 1900–1910, 2024
work page 2024
-
[18]
A motion matching-based framework for controllable gesture synthesis from speech
Ikhsanul Habibie, Mohamed Elgharib, Kripasindhu Sarkar, Ahsan Abdullah, Simbarashe Nyatsanga, Michael Neff, and Christian Theobalt. A motion matching-based framework for controllable gesture synthesis from speech. InACM SIGGRAPH 2022 conference proceedings, pages 1–9, 2022
work page 2022
-
[19]
Longbin Ji, Pengfei Wei, Yi Ren, Jinglin Liu, Chen Zhang, and Xiang Yin. C2g2: Controllable co-speech gesture generation with latent diffusion model.arXiv preprint arXiv:2308.15016, 2023
-
[20]
Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models
Zeqian Ju, Yuancheng Wang, Kai Shen, Xu Tan, Detai Xin, Dongchao Yang, Eric Liu, Yichong Leng, Kaitao Song, Siliang Tang, et al. Naturalspeech 3: Zero-shot speech synthesis with factorized codec and diffusion models. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024, pages 22605–22623, 2024
work page 2024
-
[21]
Priority- centric human motion generation in discrete latent space
Hanyang Kong, Kehong Gong, Dongze Lian, Michael Bi Mi, and Xinchao Wang. Priority- centric human motion generation in discrete latent space. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 14760–14770, 2023
work page 2023
-
[22]
Marshall, Catherine Pelachaud, Hannes Pirker, Kristinn R
Stefan Kopp, Brigitte Krenn, Stacy Marsella, Andrew N. Marshall, Catherine Pelachaud, Hannes Pirker, Kristinn R. Thórisson, and Hannes Högni Vilhjálmsson. Towards a common framework for multimodal generation: The behavior markup language. InIntelligent Virtual Agents, 6th International Conference, IVA 2006, Marina Del Rey, CA, USA, August 21-23, 2006, Pro...
work page 2006
-
[23]
Lik-Hang Lee, Tristan Braud, Peng Yuan Zhou, Lin Wang, Dianlei Xu, Zijun Lin, Abhishek Kumar, Carlos Bermejo, and Pan Hui. All one needs to know about metaverse: A complete survey on technological singularity, virtual ecosystem, and research agenda.Found. Trends Hum. Comput. Interact., 18(2-3):100–337, 2024
work page 2024
-
[24]
Bigvgan: A universal neural vocoder with large-scale training
Sang-gil Lee, Wei Ping, Boris Ginsburg, Bryan Catanzaro, and Sungroh Yoon. Bigvgan: A universal neural vocoder with large-scale training. InThe Eleventh International Conference on Learning Representations, ICLR 2023, Kigali, Rwanda, May 1-5, 2023, 2023
work page 2023
-
[25]
Jing Li, Di Kang, Wenjie Pei, Xuefei Zhe, Ying Zhang, Zhenyu He, and Linchao Bao. Au- dio2gestures: Generating diverse gestures from speech audio with conditional variational autoencoders. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, pages 11273–11282, 2021
work page 2021
-
[26]
Ruilong Li, Shan Yang, David A. Ross, and Angjoo Kanazawa. AI choreographer: Music conditioned 3d dance generation with AIST++. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, pages 13381– 13392, 2021
work page 2021
-
[27]
Prosodytalker: 3d visual speech animation via prosody decomposition
Zonglin Li, Xiaoqian Lv, Qinglin Liu, Quanling Meng, Xin Sun, and Shengping Zhang. Prosodytalker: 3d visual speech animation via prosody decomposition. InThirty-Ninth AAAI Conference on Artificial Intelligence, Thirty-Seventh Conference on Innovative Applications of Artificial Intelligence, Fifteenth Symposium on Educational Advances in Artificial Intelli...
work page 2025
-
[28]
Girshick, Kaiming He, and Piotr Dollár
Tsung-Yi Lin, Priya Goyal, Ross B. Girshick, Kaiming He, and Piotr Dollár. Focal loss for dense object detection. InIEEE International Conference on Computer Vision, ICCV 2017, Venice, Italy, October 22-29, 2017, pages 2999–3007, 2017
work page 2017
-
[29]
Haiyang Liu, Zihao Zhu, Naoya Iwamoto, Yichen Peng, Zhengqing Li, You Zhou, Elif Bozkurt, and Bo Zheng. BEAT: A large-scale semantic and emotional multi-modal dataset for conversa- tional gestures synthesis. InComputer Vision - ECCV 2022 - 17th European Conference, Tel Aviv, Israel, October 23-27, 2022, Proceedings, Part VII, pages 612–630, 2022
work page 2022
-
[30]
Haiyang Liu, Zihao Zhu, Giorgio Becherini, Yichen Peng, Mingyang Su, You Zhou, Xuefei Zhe, Naoya Iwamoto, Bo Zheng, and Michael J. Black. EMAGE: towards unified holistic co-speech gesture generation via expressive masked audio gesture modeling. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024,...
work page 2024
-
[31]
Semges: Semantics-aware co-speech gesture generation using semantic coherence and relevance learning
Lanmiao Liu, Esam Ghaleb, Asli Ozyurek, and Zerrin Yumak. Semges: Semantics-aware co-speech gesture generation using semantic coherence and relevance learning. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 13963–13973, October 2025
work page 2025
-
[32]
Lanmiao Liu, Esam Ghaleb, Aslı Özyürek, and Zerrin Yumak. Holisticsemges: Semantic grounding of holistic co-speech gesture generation with contrastive flow-matching.arXiv preprint arXiv:2603.26553, 2026
-
[33]
Lianlian Liu, YongKang He, Zhaojie Chu, Xiaofen Xing, and Xiangmin Xu. Mimicparts: Part- aware style injection for speech-driven 3d motion generation.arXiv preprint arXiv:2510.13208, 2025
-
[34]
Gesturelsm: Latent shortcut based co-speech gesture generation with spatial-temporal modeling
Pinxin Liu, Luchuan Song, Junhua Huang, Haiyang Liu, and Chenliang Xu. Gesturelsm: Latent shortcut based co-speech gesture generation with spatial-temporal modeling. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 10929–10939, October 2025
work page 2025
-
[35]
Audio- driven co-speech gesture video generation
Xian Liu, Qianyi Wu, Hang Zhou, Yuanqi Du, Wayne Wu, Dahua Lin, and Ziwei Liu. Audio- driven co-speech gesture video generation. InAdvances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - December 9, 2022, 2022
work page 2022
-
[36]
Ksdiff: Keyframe-augmented speech-aware dual- path diffusion for facial animation
Tianle Lyu, Junchuan Zhao, and Ye Wang. Ksdiff: Keyframe-augmented speech-aware dual- path diffusion for facial animation. InICASSP 2026-2026 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 13132–13136. IEEE, 2026
work page 2026
-
[37]
MDT-A2G: exploring masked diffusion transformers for co-speech gesture generation
Xiaofeng Mao, Zhengkai Jiang, Qilin Wang, Chencan Fu, Jiangning Zhang, Jiafu Wu, Yabiao Wang, Chengjie Wang, Wei Li, and Mingmin Chi. MDT-A2G: exploring masked diffusion transformers for co-speech gesture generation. InProceedings of the 32nd ACM Interna- tional Conference on Multimedia, MM 2024, Melbourne, VIC, Australia, 28 October 2024 - 1 November 202...
work page 2024
-
[38]
Convofusion: Multi-modal conversational diffusion for co-speech gesture synthesis
Muhammad Hamza Mughal, Rishabh Dabral, Ikhsanul Habibie, Lucia Donatelli, Marc Haber- mann, and Christian Theobalt. Convofusion: Multi-modal conversational diffusion for co-speech gesture synthesis. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024, pages 1388–1398, 2024
work page 2024
-
[39]
A comprehensive review of data-driven co-speech gesture generation.Comput
Simbarashe Nyatsanga, Taras Kucherenko, Chaitanya Ahuja, Gustav Eje Henter, and Michael Neff. A comprehensive review of data-driven co-speech gesture generation.Comput. Graph. Forum, 42(2):569–596, 2023
work page 2023
-
[40]
Mathis Petrovich, Michael J. Black, and Gül Varol. Action-conditioned 3d human motion synthesis with transformer V AE. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, pages 10965–10975, 2021
work page 2021
-
[41]
Emotiongesture: Audio-driven diverse emotional co-speech 3d gesture generation.IEEE Trans
Xingqun Qi, Chen Liu, Lincheng Li, Jie Hou, Haoran Xin, and Xin Yu. Emotiongesture: Audio-driven diverse emotional co-speech 3d gesture generation.IEEE Trans. Multim., 26: 10420–10430, 2024. 12
work page 2024
-
[42]
Speech drives templates: Co- speech gesture synthesis with learned templates
Shenhan Qian, Zhi Tu, Yihao Zhi, Wen Liu, and Shenghua Gao. Speech drives templates: Co- speech gesture synthesis with learned templates. In2021 IEEE/CVF International Conference on Computer Vision, ICCV 2021, Montreal, QC, Canada, October 10-17, 2021, pages 11057– 11066, 2021
work page 2021
-
[43]
Robust speech recognition via large-scale weak supervision
Alec Radford, Jong Wook Kim, Tao Xu, Greg Brockman, Christine McLeavey, and Ilya Sutskever. Robust speech recognition via large-scale weak supervision. InInternational Conference on Machine Learning, ICML 2023, 23-29 July 2023, Honolulu, Hawaii, USA, pages 28492–28518, 2023
work page 2023
-
[44]
Outrageously large neural networks: The sparsely-gated mixture-of-experts layer
Noam Shazeer, Azalia Mirhoseini, Krzysztof Maziarz, Andy Davis, Quoc Le, Geoffrey Hinton, and Jeff Dean. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. InInternational Conference on Learning Representations, 2017
work page 2017
-
[45]
Hand and mind: What gestures reveal about thought.Language and Speech, 37(2):203–209, 1994
Michael Studdert-Kennedy. Hand and mind: What gestures reveal about thought.Language and Speech, 37(2):203–209, 1994
work page 1994
-
[46]
Christine Marie Tipper, Giulia Signorini, and Scott T Grafton. Body language in the brain: constructing meaning from expressive movement.Frontiers in human neuroscience, 9:145501, 2015
work page 2015
-
[47]
Tommi Tykkala, Cédric Audras, and Andrew I. Comport. Direct iterative closest point for real-time visual odometry. InIEEE International Conference on Computer Vision Workshops, ICCV 2011 Workshops, Barcelona, Spain, November 6-13, 2011, pages 2050–2056, 2011
work page 2011
-
[48]
Susanne van Mulken, Elisabeth André, and Jochen Müller. The persona effect: How substantial is it? InPeople and Computers XIII, Proceedings of HCI ’98, pages 53–66, 1998
work page 1998
-
[49]
AQ-GT: a temporally aligned and quantized gru-transformer for co-speech gesture synthesis
Hendric V oß and Stefan Kopp. AQ-GT: a temporally aligned and quantized gru-transformer for co-speech gesture synthesis. InProceedings of the 25th International Conference on Multimodal Interaction, ICMI 2023, Paris, France, October 9-13, 2023, pages 60–69, 2023
work page 2023
-
[50]
Individual comparisons by ranking methods
Frank Wilcoxon. Individual comparisons by ranking methods. InBreakthroughs in statistics: Methodology and distribution, pages 196–202. 1992
work page 1992
-
[51]
Bowen Wu, Chaoran Liu, Carlos Toshinori Ishi, and Hiroshi Ishiguro. Modeling the conditional distribution of co-speech upper body gesture jointly using conditional-gan and unrolled-gan. Electronics, 10(3):228, 2021
work page 2021
-
[52]
Eggesture: Entropy-guided vector quantized variational autoencoder for co-speech gesture generation
Yiyong Xiao, Kai Shu, Haoyi Zhang, Baohua Yin, Wai Seng Cheang, Haoyang Wang, and Jiechao Gao. Eggesture: Entropy-guided vector quantized variational autoencoder for co-speech gesture generation. InProceedings of the 32nd ACM International Conference on Multimedia, MM 2024, Melbourne, VIC, Australia, 28 October 2024 - 1 November 2024, pages 6113–6122, 2024
work page 2024
-
[53]
Codetalker: Speech-driven 3d facial animation with discrete motion prior
Jinbo Xing, Menghan Xia, Yuechen Zhang, Xiaodong Cun, Jue Wang, and Tien-Tsin Wong. Codetalker: Speech-driven 3d facial animation with discrete motion prior. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 12780–12790, 2023
work page 2023
-
[54]
Mambatalk: Efficient holistic gesture synthesis with selective state space models
Zunnan Xu, Yukang Lin, Haonan Han, Sicheng Yang, Ronghui Li, Yachao Zhang, and Xiu Li. Mambatalk: Efficient holistic gesture synthesis with selective state space models. InAdvances in Neural Information Processing Systems 38: Annual Conference on Neural Information Processing Systems 2024, NeurIPS 2024, Vancouver, BC, Canada, December 10 - 15, 2024, 2024
work page 2024
-
[55]
Diffusestylegesture: Stylized audio-driven co-speech gesture generation with diffusion models
Sicheng Yang, Zhiyong Wu, Minglei Li, Zhensong Zhang, Lei Hao, Weihong Bao, Ming Cheng, and Long Xiao. Diffusestylegesture: Stylized audio-driven co-speech gesture generation with diffusion models. InProceedings of the Thirty-Second International Joint Conference on Artificial Intelligence, IJCAI 2023, 19th-25th August 2023, Macao, SAR, China, pages 5860–...
work page 2023
-
[56]
Payam Jome Yazdian, Mo Chen, and Angelica Lim. Gesture2vec: Clustering gestures using representation learning methods for co-speech gesture generation. InIEEE/RSJ International Conference on Intelligent Robots and Systems, IROS 2022, Kyoto, Japan, October 23-27, 2022, pages 3100–3107, 2022
work page 2022
-
[57]
Hongwei Yi, Hualin Liang, Yifei Liu, Qiong Cao, Yandong Wen, Timo Bolkart, Dacheng Tao, and Michael J. Black. Generating holistic 3d human motion from speech. InIEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2023, Vancouver, BC, Canada, June 17-24, 2023, pages 469–480, 2023
work page 2023
-
[58]
Pyramotion: Attentional pyramid-structured motion integration for co-speech 3d gesture synthesis
Zhizhuo Yin, Yuk Hang Tsui, and Pan Hui. Pyramotion: Attentional pyramid-structured motion integration for co-speech 3d gesture synthesis. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026
work page 2026
-
[59]
Speech gesture generation from the trimodal context of text, audio, and speaker identity.ACM Trans
Youngwoo Yoon, Bok Cha, Joo-Haeng Lee, Minsu Jang, Jaeyeon Lee, Jaehong Kim, and Geehyuk Lee. Speech gesture generation from the trimodal context of text, audio, and speaker identity.ACM Trans. Graph., 39(6):222:1–222:16, 2020
work page 2020
-
[60]
Fatemeh Zargarbashi, Dhruv Agrawal, Jakob Buhmann, Martin Guay, Stelian Coros, and Robert W. Sumner. Vq-style: Disentangling style and content in motion with residual quantized representations.Computer Graphics Forum, page e70377, 2026
work page 2026
-
[61]
Jian Zhang and Osamu Yoshie. Learning hierarchical discrete prior for co-speech gesture generation.Neurocomputing, 595:127831, 2024
work page 2024
-
[62]
Semtalk: Holistic co-speech motion generation with frame-level semantic emphasis
Xiangyue Zhang, Jianfang Li, Jiaxu Zhang, Ziqiang Dang, Jianqiang Ren, Liefeng Bo, and Zhigang Tu. Semtalk: Holistic co-speech motion generation with frame-level semantic emphasis. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 13761–13771, October 2025
work page 2025
-
[63]
Echomask: Speech-queried attention-based mask modeling for holistic co-speech motion generation
Xiangyue Zhang, Jianfang Li, Jiaxu Zhang, Jianqiang Ren, Liefeng Bo, and Zhigang Tu. Echomask: Speech-queried attention-based mask modeling for holistic co-speech motion generation. InProceedings of the 33rd ACM International Conference on Multimedia, MM 2025, Dublin, Ireland, October 27-31, 2025, pages 10827–10836, 2025
work page 2025
-
[64]
Xiangyue Zhang, Jianfang Li, Jianqiang Ren, and Jiaxu Zhang. Mitigating error accumulation in co-speech motion generation via global rotation diffusion and multi-level constraints. In Fortieth AAAI Conference on Artificial Intelligence, AAAI 2026, Singapore, January 20-27, 2026, pages 12834–12842, 2026
work page 2026
-
[65]
Semantic gesticulator: Semantics-aware co-speech gesture synthesis.ACM Trans
Zeyi Zhang, Tenglong Ao, Yuyao Zhang, Qingzhe Gao, Chuan Lin, Baoquan Chen, and Libin Liu. Semantic gesticulator: Semantics-aware co-speech gesture synthesis.ACM Trans. Graph., 43(4):136:1–136:17, 2024
work page 2024
-
[66]
Prosody-adaptable audio codecs for zero-shot voice conversion via in-context learning
Junchuan Zhao, Xintong Wang, and Ye Wang. Prosody-adaptable audio codecs for zero-shot voice conversion via in-context learning. In26th Annual Conference of the International Speech Communication Association, Interspeech 2025, Rotterdam, The Netherlands, 17-21 August 2025, 2025
work page 2025
-
[67]
Livelyspeaker: Towards semantic-aware co-speech gesture generation
Yihao Zhi, Xiaodong Cun, Xuelin Chen, Xi Shen, Wen Guo, Shaoli Huang, and Shenghua Gao. Livelyspeaker: Towards semantic-aware co-speech gesture generation. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 20750–20760, 2023
work page 2023
-
[68]
Chongyang Zhong, Lei Hu, Zihao Zhang, and Shihong Xia. Attt2m: Text-driven human motion generation with multi-perspective attention mechanism. InIEEE/CVF International Conference on Computer Vision, ICCV 2023, Paris, France, October 1-6, 2023, pages 509–519, 2023. 14 PersonaGest: Personalized Co-Speech Gesture Generation with Semantic-Guided Hierarchical ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.