Recognition: no theorem link
Adaptive Subspace Projection for Generative Personalization
Pith reviewed 2026-05-11 01:25 UTC · model grok-4.3
The pith
Semantic drift in generative personalization concentrates in a low-dimensional subspace, enabling a training-free projection method to restore prompt fidelity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Analysis of the personalization process reveals that the semantic drift causing SCP is concentrated within a specific low-dimensional subspace and that the embedding of the original base concept becomes perturbed and unstable as a reference. AdaptSP addresses this by using the pre-trained embedding as a stable anchor, isolating the drift component, and projecting it onto the identified subspace to perform a precise adjustment that mitigates semantic collapsing while preserving subject identity.
What carries the argument
Adaptive Subspace Projection (AdaptSP): the test-time mechanism that identifies the low-dimensional subspace containing semantic drift and projects the perturbation vector onto it using the pre-trained embedding as anchor.
If this is right
- Personalized models achieve higher adherence to full text prompts without retraining.
- Contextual details in prompts are respected while the learned subject remains recognizable.
- The adjustment operates at test time on any already-personalized embedding.
- Prompt fidelity improves across varied text instructions that combine the subject with other elements.
Where Pith is reading between the lines
- If subspace identification proves consistent across different personalization techniques, the method could serve as a standard post-processing step for many embedding-based generators.
- The same anchoring-plus-projection logic might apply to drift issues in other modalities such as video or audio generation.
- Further tests with prompts that vary in complexity could clarify the dimensional limits of the drift subspace.
Load-bearing premise
The semantic drift is concentrated within a specific identifiable low-dimensional subspace that can be isolated and projected without losing subject identity or introducing new artifacts.
What would settle it
Applying the subspace projection to personalized embeddings and then generating images from complex contextual prompts yields no measurable gain in how accurately the outputs reflect all elements of the prompt compared to the unadjusted embeddings.
Figures


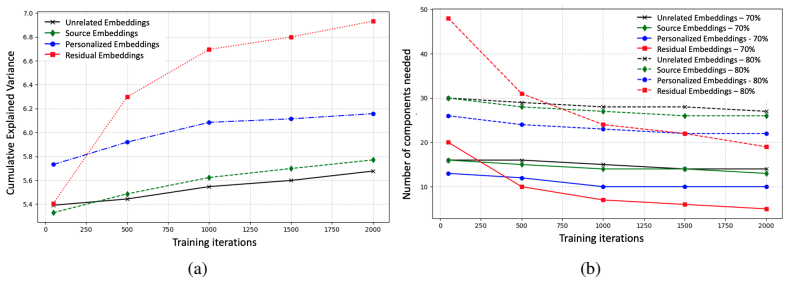

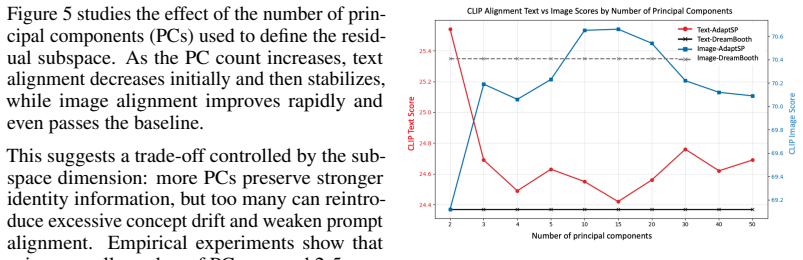













read the original abstract
Generative personalization often suffers from the semantic collapsing problem (SCP), where a learned personalized concept overpowers the rest of the text prompt, causing the model to ignore important contextual details. To address this, we first analyze the underlying cause, revealing that the semantic drift responsible for SCP is not random but is concentrated within a specific low-dimensional subspace. We also discover that the personalization process perturbs the embedding of the original base concept, making it an unstable reference point. Based on these insights, we introduce Test-time Embedding Adjustment with Adaptive Subspace Projection (AdaptSP), a training-free method that uses the stable, pre-trained embedding as an anchor. AdaptSP isolates the semantic drift and projects it onto the identified subspace, performing a precise adjustment that mitigates SCP while maintaining the subject identity. Our experiments show that this targeted approach significantly improves prompt fidelity and contextual alignment.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that the semantic collapsing problem (SCP) in generative personalization arises because semantic drift is not random but concentrated in a specific low-dimensional subspace, and because personalization perturbs the base concept embedding into an unstable reference. It introduces AdaptSP, a training-free test-time method that anchors to the stable pre-trained embedding, adaptively identifies the drift subspace, and performs a projection adjustment to mitigate SCP while preserving subject identity, with claimed experimental gains in prompt fidelity and contextual alignment.
Significance. If the core empirical pattern and projection mechanism hold under rigorous validation, the result would be significant as a lightweight, training-free intervention that directly targets a common failure mode in personalized text-to-image models. The structured-subspace insight, if mathematically characterized, could inform embedding-space analysis more broadly in diffusion models.
major comments (3)
- [Abstract] Abstract and analysis section: the claim that semantic drift is 'concentrated within a specific low-dimensional subspace' is presented as the result of analysis, yet no equation, covariance construction, basis-vector definition, or invariance argument is supplied to show why the subspace is low-dimensional, consistent across subjects, or separable from identity features.
- [Method] Method description (AdaptSP): the projection step is described only at the level of 'isolates the semantic drift and projects it onto the identified subspace,' without a mathematical definition of the drift vector (e.g., difference between personalized and pre-trained embeddings), the adaptive subspace basis, or the orthogonal projection operator, leaving open whether identity information is inadvertently removed.
- [Experiments] Experiments: the abstract asserts that AdaptSP 'significantly improves prompt fidelity and contextual alignment,' but no quantitative metrics, baselines (e.g., DreamBooth or Textual Inversion), ablation studies, or error analysis are referenced, rendering the performance claims unverifiable.
Simulated Author's Rebuttal
We thank the referee for the thorough review and the recommendation for major revision. The comments highlight areas where mathematical formalization and experimental referencing can be strengthened, and we will incorporate these improvements in the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract and analysis section: the claim that semantic drift is 'concentrated within a specific low-dimensional subspace' is presented as the result of analysis, yet no equation, covariance construction, basis-vector definition, or invariance argument is supplied to show why the subspace is low-dimensional, consistent across subjects, or separable from identity features.
Authors: We agree that the supporting mathematical details were not made explicit. In the revision we will expand the analysis section with the definition of the drift vector as the difference between personalized and pre-trained embeddings, the covariance matrix constructed from drift vectors across multiple subjects, the basis vectors obtained as the leading eigenvectors of that matrix, and an invariance argument based on the stability of the dominant eigenspace under changes in personalization strength. This will also demonstrate separability by showing that identity-related directions remain orthogonal to the identified drift subspace. revision: yes
-
Referee: [Method] Method description (AdaptSP): the projection step is described only at the level of 'isolates the semantic drift and projects it onto the identified subspace,' without a mathematical definition of the drift vector (e.g., difference between personalized and pre-trained embeddings), the adaptive subspace basis, or the orthogonal projection operator, leaving open whether identity information is inadvertently removed.
Authors: We acknowledge the need for a precise formulation. The revised method section will explicitly define the drift vector, describe the adaptive construction of the subspace basis (via principal components of observed drift vectors with variance-based rank selection), and state the orthogonal projection operator applied to adjust the embedding. We will add a short argument that identity is preserved because the adjustment operates only within the drift subspace while leaving the orthogonal complement unchanged, supported by similarity measurements before and after projection. revision: yes
-
Referee: [Experiments] Experiments: the abstract asserts that AdaptSP 'significantly improves prompt fidelity and contextual alignment,' but no quantitative metrics, baselines (e.g., DreamBooth or Textual Inversion), ablation studies, or error analysis are referenced, rendering the performance claims unverifiable.
Authors: We agree that the abstract should reference the supporting evidence. Our experiments section reports quantitative results using CLIP-based prompt fidelity and contextual alignment scores, direct comparisons against DreamBooth and Textual Inversion, ablation studies on subspace dimension and projection strength, and error analysis on failure cases. In the revision we will update the abstract to cite these metrics, baselines, and studies so that the performance claims are directly traceable to the reported results. revision: yes
Circularity Check
No significant circularity; derivation rests on independent empirical analysis of drift subspace
full rationale
The paper first performs an analysis to reveal that semantic drift is concentrated in a low-dimensional subspace and that personalization perturbs the base embedding. It then introduces AdaptSP as a training-free test-time projection method that uses the pre-trained embedding as an external anchor and projects the identified drift. No equations, parameter fits, or self-citations are shown that would make the claimed mitigation equivalent to the input observations by construction. The subspace identification is presented as a data-driven discovery rather than a definitional or fitted tautology, and the adjustment step operates on quantities treated as independently observable. The derivation chain therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Palp: Prompt aligned personalization of text-to-image models
Moab Arar, Andrey V oynov, Amir Hertz, Omri Avrahami, Shlomi Fruchter, Yael Pritch, Daniel Cohen-Or, and Ariel Shamir. Palp: Prompt aligned personalization of text-to-image models. In SIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024
work page 2024
-
[2]
Break-a- scene: Extracting multiple concepts from a single image
Omri Avrahami, Kfir Aberman, Ohad Fried, Daniel Cohen-Or, and Dani Lischinski. Break-a- scene: Extracting multiple concepts from a single image. InSIGGRAPH Asia 2023 Conference Papers, pages 1–12, 2023
work page 2023
-
[3]
Interpreting CLIP with sparse linear concept embeddings (spliCE)
Usha Bhalla, Alex Oesterling, Suraj Srinivas, Flavio Calmon, and Himabindu Lakkaraju. Interpreting CLIP with sparse linear concept embeddings (spliCE). InThe Thirty-eighth Annual Conference on Neural Information Processing Systems, 2024
work page 2024
-
[4]
Anh Bui, Trang Vu, Trung Le, Junae Kim, Tamas Abraham, Rollin Omari, Amar Kaur, and Dinh Phung. Mitigating semantic collapse in generative personalization with a surprisingly simple test-time embedding adjustment.arXiv e-prints, pages arXiv–2506, 2025
work page 2025
-
[5]
Emerging properties in self-supervised vision transformers
Mathilde Caron, Hugo Touvron, Ishan Misra, Hervé Jégou, Julien Mairal, Piotr Bojanowski, and Armand Joulin. Emerging properties in self-supervised vision transformers. InProceedings of the IEEE/CVF international conference on computer vision, pages 9650–9660, 2021
work page 2021
-
[6]
Artadapter: Text-to-image style transfer using multi-level style encoder and explicit adaptation
Dar-Yen Chen, Hamish Tennent, and Ching-Wen Hsu. Artadapter: Text-to-image style transfer using multi-level style encoder and explicit adaptation. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8619–8628, 2024
work page 2024
-
[7]
Hong Chen, Yipeng Zhang, Simin Wu, Xin Wang, Xuguang Duan, Yuwei Zhou, and Wenwu Zhu. Disenbooth: Identity-preserving disentangled tuning for subject-driven text-to-image generation.arXiv preprint arXiv:2305.03374, 2023
-
[8]
Li Chen, Mengyi Zhao, Yiheng Liu, Mingxu Ding, Yangyang Song, Shizun Wang, Xu Wang, Hao Yang, Jing Liu, Kang Du, et al. Photoverse: Tuning-free image customization with text-to-image diffusion models.arXiv preprint arXiv:2309.05793, 2023
-
[9]
Dreamidentity: enhanced editability for efficient face-identity preserved image generation
Zhuowei Chen, Shancheng Fang, Wei Liu, Qian He, Mengqi Huang, and Zhendong Mao. Dreamidentity: enhanced editability for efficient face-identity preserved image generation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 1281–1289, 2024
work page 2024
-
[10]
An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit H Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion.arXiv preprint arXiv:2208.01618, 2022
work page internal anchor Pith review arXiv 2022
-
[11]
Svdiff: Compact parameter space for diffusion fine-tuning
Ligong Han, Yinxiao Li, Han Zhang, Peyman Milanfar, Dimitris Metaxas, and Feng Yang. Svdiff: Compact parameter space for diffusion fine-tuning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 7323–7334, 2023
work page 2023
-
[12]
CLIPScore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. CLIPScore: A reference-free evaluation metric for image captioning. In Marie-Francine Moens, Xuanjing Huang, Lucia Specia, and Scott Wen-tau Yih, editors,Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, pages 7514–7528, Online and Punta Cana, D...
work page 2021
-
[13]
Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models.Advances in neural information processing systems, 33:6840–6851, 2020
work page 2020
-
[14]
Classdiffusion: More aligned personalization tuning with explicit class guidance
Jiannan Huang, Jun Hao Liew, Hanshu Yan, Yuyang Yin, Yao Zhao, Humphrey Shi, and Yunchao Wei. Classdiffusion: More aligned personalization tuning with explicit class guidance. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[15]
Reversion: Diffusion- based relation inversion from images
Ziqi Huang, Tianxing Wu, Yuming Jiang, Kelvin CK Chan, and Ziwei Liu. Reversion: Diffusion- based relation inversion from images. InSIGGRAPH Asia 2024 Conference Papers, pages 1–11, 2024. 11
work page 2024
-
[16]
Scedit: Efficient and controllable image diffusion generation via skip connection editing
Zeyinzi Jiang, Chaojie Mao, Yulin Pan, Zhen Han, and Jingfeng Zhang. Scedit: Efficient and controllable image diffusion generation via skip connection editing. InProceedings of the IEEE/CVF conference on computer vision and pattern Recognition, pages 8995–9004, 2024
work page 2024
-
[17]
Chen Jin, Ryutaro Tanno, Amrutha Saseendran, Tom Diethe, and Philip Alexander Teare. An image is worth multiple words: Discovering object level concepts using multi-concept prompt learning. InForty-first International Conference on Machine Learning, 2024
work page 2024
-
[18]
Omg: Occlusion-friendly personalized multi-concept generation in diffusion models
Zhe Kong, Yong Zhang, Tianyu Yang, Tao Wang, Kaihao Zhang, Bizhu Wu, Guanying Chen, Wei Liu, and Wenhan Luo. Omg: Occlusion-friendly personalized multi-concept generation in diffusion models. InEuropean Conference on Computer Vision, pages 253–270. Springer, 2024
work page 2024
-
[19]
Multi- concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi- concept customization of text-to-image diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1931–1941, 2023
work page 1931
-
[20]
Generate anything anywhere in any scene.arXiv preprint arXiv:2306.17154, 2023
Yuheng Li, Haotian Liu, Yangming Wen, and Yong Jae Lee. Generate anything anywhere in any scene.arXiv preprint arXiv:2306.17154, 2023
-
[21]
Zeke Li, Yue Bai, Yi Zhou, Youtao Li, Haoran Zhou, Yanhong Zhang, Lun Qi, Hongfang He, and Liang Zhao. Photomaker: Customizing realistic human photos via stacked id embedding. arXiv preprint arXiv:2312.04461, 2023
-
[22]
Gongye Liu, Menghan Xia, Yong Zhang, Haoxin Chen, Jinbo Xing, Yibo Wang, Xintao Wang, Yujiu Yang, and Ying Shan. Stylecrafter: Enhancing stylized text-to-video generation with style adapter.arXiv preprint arXiv:2312.00330, 2023
-
[23]
Deep learning face attributes in the wild
Ziwei Liu, Ping Luo, Xiaogang Wang, and Xiaoou Tang. Deep learning face attributes in the wild. InProceedings of International Conference on Computer Vision (ICCV), December 2015
work page 2015
-
[24]
Saman Motamed, Danda Pani Paudel, and Luc Van Gool. Lego: Learning to disentangle and invert personalized concepts beyond object appearance in text-to-image diffusion models. In European Conference on Computer Vision, pages 116–133. Springer, 2024
work page 2024
-
[25]
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2i-adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. InProceedings of the AAAI conference on artificial intelligence, volume 38, pages 4296–4304, 2024
work page 2024
- [26]
-
[27]
Controlling text-to-image diffusion by orthogonal finetuning
Zeju Qiu, Weiyang Liu, Haiwen Feng, Yuxuan Xue, Yao Feng, Zhen Liu, Dan Zhang, Adrian Weller, and Bernhard Schölkopf. Controlling text-to-image diffusion by orthogonal finetuning. Advances in Neural Information Processing Systems, 36:79320–79362, 2023
work page 2023
-
[28]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual models from natural language supervision. InInternational conference on machine learning, pages 8748–8763. PMLR, 2021
work page 2021
-
[29]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
work page 2022
-
[30]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22500–22510, 2023
work page 2023
-
[31]
Clic: Concept learning in context
Mehdi Safaee, Aryan Mikaeili, Or Patashnik, Daniel Cohen-Or, and Ali Mahdavi-Amiri. Clic: Concept learning in context. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6924–6933, 2024. 12
work page 2024
-
[32]
Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding
Chitwan Saharia, William Chan, Saurabh Saxena, et al. Imagen: Photorealistic text-to-image diffusion models with deep language understanding.arXiv preprint arXiv:2205.11487, 2022
work page internal anchor Pith review arXiv 2022
-
[33]
Styledrop: Text-to-image generation in any style.arXiv preprint arXiv:2306.00983,
Kihyuk Sohn, Nataniel Ruiz, Kimin Lee, Daniel Castro Chin, Irina Blok, Huiwen Chang, Jarred Barber, Lu Jiang, Glenn Entis, Yuanzhen Li, et al. Styledrop: Text-to-image generation in any style.arXiv preprint arXiv:2306.00983, 2023
-
[34]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[35]
Ominicontrol: Minimal and universal control for diffusion transformer
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang. Ominicontrol: Minimal and universal control for diffusion transformer. 2025
work page 2025
-
[36]
Zhenxiong Tan, Qiaochu Xue, Xingyi Yang, Songhua Liu, and Xinchao Wang. Ominicontrol2: Efficient conditioning for diffusion transformers.arXiv preprint arXiv:2503.08280, 2025
-
[37]
Key-locked rank one editing for text-to-image personalization
Yoad Tewel, Rinon Gal, Gal Chechik, and Yuval Atzmon. Key-locked rank one editing for text-to-image personalization. InACM SIGGRAPH 2023 conference proceedings, pages 1–11, 2023
work page 2023
-
[38]
Face0: Instantaneously conditioning a text-to-image model on a face
Dani Valevski, Danny Lumen, Yossi Matias, and Yaniv Leviathan. Face0: Instantaneously conditioning a text-to-image model on a face. InSIGGRAPH Asia 2023 Conference Papers, pages 1–10, 2023
work page 2023
-
[39]
Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519, 2024
Qixun Wang, Xu Bai, Haofan Wang, Zekui Qin, and Anthony Chen. Instantid: Zero-shot identity-preserving generation in seconds.arXiv preprint arXiv:2401.07519, 2024
-
[40]
Guangxuan Xiao, Tianwei Yin, William T Freeman, Frédo Durand, and Song Han. Fastcom- poser: Tuning-free multi-subject image generation with localized attention.International Journal of Computer Vision, pages 1–20, 2024
work page 2024
-
[41]
IP-Adapter: Text Compatible Image Prompt Adapter for Text-to-Image Diffusion Models
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[42]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
work page 2023
-
[43]
Yuxuan Zhang, Yirui Yuan, Yiren Song, Haofan Wang, and Jiaming Liu. Easycontrol: Adding efficient and flexible control for diffusion transformer.arXiv preprint arXiv:2503.07027, 2025
-
[44]
Jitian Zhao, Chenghui Li, Frederic Sala, and Karl Rohe. Quantifying structure in CLIP embeddings: A statistical framework for concept interpretation.Transactions on Machine Learning Research, 2026
work page 2026
-
[45]
Chenyang Zhu, Kai Li, Yue Ma, Chunming He, and Xiu Li. Multibooth: Towards generating all your concepts in an image from text. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 10923–10931, 2025. 13 Figure 6: Problem of Subject Fidelity Metrics that can assign artificially high subject-fidelity scores to overfitting generat...
-
[46]
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.