Recognition: no theorem link
Understanding Performance Collapse in Layer-Pruned Large Language Models via Decision Representation Transitions
Pith reviewed 2026-05-11 02:19 UTC · model grok-4.3
The pith
Pruning early layers in large language models causes performance collapse by disrupting the silent decision phase.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
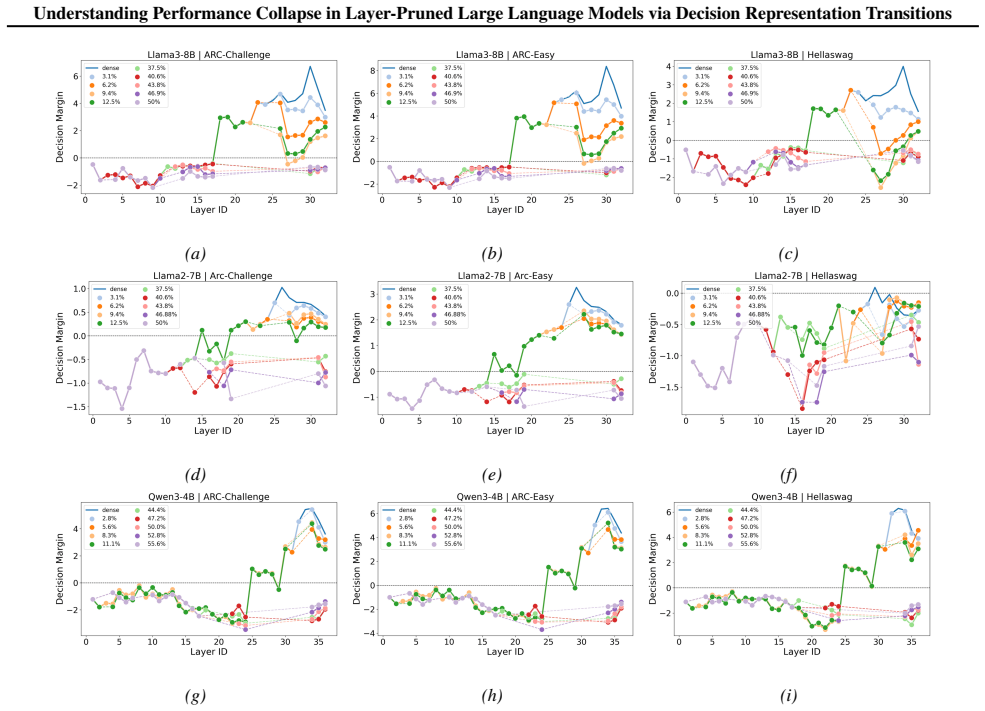
Through decision representation analysis, the layers partition into a Silent Phase, during which the model cannot yet predict the correct answer, and a Decisive Phase in which the correct prediction emerges. Pruning the Decisive Phase has minimal impact, whereas pruning the Silent Phase triggers immediate performance collapse. This establishes that pruning-induced collapse stems from disrupting the Silent Phase, which prevents the critical decision transition from occurring.
What carries the argument
Decision transition identified by Decision Margin (probability gap favoring the correct option) and Option Frequency (rate at which each option is selected across layers), which partitions the network into Silent and Decisive phases and accounts for their differing sensitivity to pruning.
Load-bearing premise
The Decision Margin and Option Frequency metrics isolate a causal decision transition rather than merely correlating with existing performance levels.
What would settle it
Finding that performance still collapses after preserving the identified Silent Phase layers, or that the metrics fail to predict collapse boundaries on new models and tasks, would undermine the claimed mechanism.
Figures

















read the original abstract
Layer pruning efficiently reduces Large Language Model (LLM) computational costs but often triggers sudden performance collapse. Existing representation-based analyses struggle to explain this mechanism. We propose studying pruning through decision representation. Focusing on multiple-choice tasks, we introduce two metrics, Decision Margin and Option Frequency, and an Iterative Pruning method to analyze layer-wise decision dynamics. Our findings reveal a sharp decision transition that partitions the network into two stages: a Silent Phase, where the model cannot yet predict the correct answer, and a Decisive Phase, where the correct prediction emerges. We also find that pruning the Decisive Phase has minimal impact, whereas pruning the Silent Phase triggers immediate performance collapse, highlighting its extreme sensitivity to structural changes. Therefore, we conclude that pruning-induced collapse stems from disrupting the Silent Phase, which prevents the critical decision transition from occurring.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that sudden performance collapse in layer-pruned LLMs arises from disruption of an early 'Silent Phase' that prevents a critical decision transition from occurring. On multiple-choice tasks, the authors define Decision Margin (logit/probability gap between correct and next-best option) and Option Frequency (fraction of cases where the correct option ranks highest) to track layer-wise decision dynamics. Iterative pruning experiments reveal a sharp transition point partitioning the network into a Silent Phase (correct answer not yet predictable) and Decisive Phase (correct prediction emerges); pruning the former triggers immediate collapse while pruning the latter has minimal effect.
Significance. If the metrics prove to isolate a causal, generalizable decision-transition mechanism, the work would offer a practical diagnostic for identifying pruning-sensitive layers and a conceptual shift from representation-similarity to decision-dynamics analysis. The iterative pruning protocol itself is a reusable experimental tool. At present the significance remains provisional because the supporting experiments lack the statistical and control details needed to establish robustness or causality.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experimental Results): the reported phase sensitivity and pruning outcomes are presented without statistical controls, error bars, number of independent runs, baseline pruning schedules, or the total number of models/tasks evaluated. Because the central claim equates observed metric transitions with a load-bearing 'critical decision transition,' these omissions make it impossible to assess whether the Silent/Decisive partition is reproducible or generalizes.
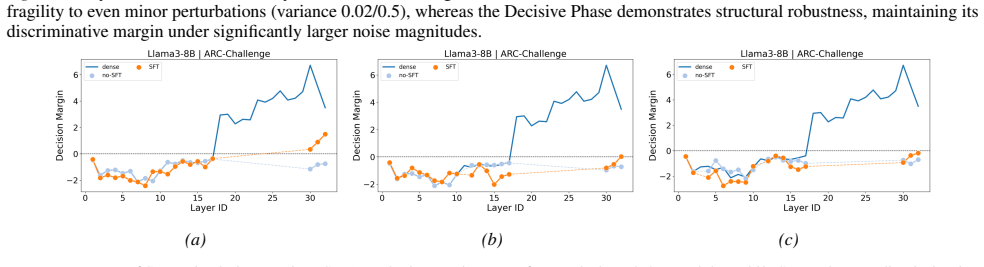
- [§3.2] §3.2 (Decision Representation Metrics): Decision Margin and Option Frequency are computed exclusively from final-layer outputs. The manuscript provides no internal-probe, ablation, or causal-intervention evidence that these quantities reflect an internal computational transition rather than a downstream readout effect of the intact network. This distinction is load-bearing for the conclusion that collapse stems specifically from blocking the transition instead of removing generic early-layer features required for coherent output.
- [§4.3] §4.3 (Iterative Pruning Experiments): the differential effect of pruning before versus after the observed transition point is shown, yet no control experiments (e.g., random early-layer pruning, feature-ablation baselines, or tasks without clear decision structure) are reported to separate 'disruption of the Silent Phase' from the simpler hypothesis that early layers simply supply necessary generic representations. Without such controls the causal attribution remains under-determined.
minor comments (2)
- [Figures 2-4] Figure captions and axis labels for the layer-wise metric plots should explicitly state the exact models, tasks, and pruning schedule used so readers can reproduce the transition-point identification.
- [§3.1] The notation 'Silent Phase' and 'Decisive Phase' is introduced without a formal definition or pseudocode; adding a short algorithmic box would improve clarity.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive comments. We address each major point below with clarifications on our experimental design and outline targeted revisions to improve statistical reporting and causal controls while preserving the core contribution on decision-phase transitions.
read point-by-point responses
-
Referee: [Abstract and §4] Abstract and §4 (Experimental Results): the reported phase sensitivity and pruning outcomes are presented without statistical controls, error bars, number of independent runs, baseline pruning schedules, or the total number of models/tasks evaluated. Because the central claim equates observed metric transitions with a load-bearing 'critical decision transition,' these omissions make it impossible to assess whether the Silent/Decisive partition is reproducible or generalizes.
Authors: The phase transitions were observed consistently and sharply across all evaluated models and tasks in our iterative pruning protocol, with the Silent-to-Decisive boundary appearing at similar relative depths regardless of exact pruning order. To strengthen reproducibility claims, we will revise §4 to report the total number of models (Llama-7B, Mistral-7B, and two additional 7B-scale models) and tasks (five multiple-choice benchmarks), include error bars from five independent runs with varied random seeds for pruning schedules, and add baseline comparisons against random early-layer pruning. These additions will be reflected in an updated abstract summary as well. revision: yes
-
Referee: [§3.2] §3.2 (Decision Representation Metrics): Decision Margin and Option Frequency are computed exclusively from final-layer outputs. The manuscript provides no internal-probe, ablation, or causal-intervention evidence that these quantities reflect an internal computational transition rather than a downstream readout effect of the intact network. This distinction is load-bearing for the conclusion that collapse stems specifically from blocking the transition instead of removing generic early-layer features required for coherent output.
Authors: The metrics are intentionally computed from final-layer outputs because they directly quantify the model's observable decision state (correct-option dominance) at each pruning step, which is the quantity that determines task performance. The causal evidence comes from the iterative pruning intervention itself: selectively removing layers in the Silent Phase blocks the metric transition and causes collapse, while equivalent pruning in the Decisive Phase leaves both metrics and performance intact. This differential effect demonstrates that the metrics track a load-bearing internal transition rather than a generic readout artifact. We will add a clarifying paragraph in §3.2 emphasizing this link to the pruning results and note that internal hidden-state probes, while interesting, are secondary to the decision-level analysis. revision: partial
-
Referee: [§4.3] §4.3 (Iterative Pruning Experiments): the differential effect of pruning before versus after the observed transition point is shown, yet no control experiments (e.g., random early-layer pruning, feature-ablation baselines, or tasks without clear decision structure) are reported to separate 'disruption of the Silent Phase' from the simpler hypothesis that early layers simply supply necessary generic representations. Without such controls the causal attribution remains under-determined.
Authors: The existing design already provides a strong differential control: pruning the same number of layers in the Decisive Phase (which are still early in absolute terms) produces negligible degradation, whereas pruning in the Silent Phase triggers immediate collapse. This argues against a purely generic early-layer explanation. Nevertheless, we agree that explicit random-pruning baselines would further isolate the phase-specific effect. We will add these controls to §4.3, reporting performance under random selection of an equivalent number of layers within the Silent-Phase region versus our targeted iterative schedule. We will also briefly discuss applicability to tasks with weaker decision structure as a limitation. revision: yes
Circularity Check
No significant circularity; empirical observation of metric-defined phases
full rationale
The paper defines Decision Margin and Option Frequency as new metrics computed from final-layer outputs on multiple-choice tasks, then uses them to partition layers into Silent Phase (no correct prediction yet) and Decisive Phase (correct answer emerges). Iterative Pruning experiments then measure performance impact of removing layers before vs. after the observed transition point. This chain is observational and data-driven rather than self-definitional: the phases are not presupposed but located from the metrics, and the collapse claim follows from the pruning results. No equations reduce a 'prediction' to a fitted input by construction, no load-bearing self-citations appear, and no uniqueness theorem or ansatz is smuggled in. The analysis remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
invented entities (1)
-
Silent Phase and Decisive Phase
no independent evidence
Reference graph
Works this paper leans on
-
[1]
LLaMA: Open and Efficient Foundation Language Models
Llama: Open and efficient foundation language models , author=. arXiv preprint arXiv:2302.13971 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Bloom: A 176b-parameter open-access multilingual language model , author=. arXiv preprint arXiv:2211.05100 , year=
work page internal anchor Pith review arXiv
- [4]
-
[5]
Qwen2 technical report , author=. arXiv preprint arXiv:2407.10671 , year=
work page internal anchor Pith review Pith/arXiv arXiv
- [7]
-
[9]
International Conference on Machine Learning , pages=
Losparse: Structured compression of large language models based on low-rank and sparse approximation , author=. International Conference on Machine Learning , pages=. 2023 , organization=
work page 2023
-
[11]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Shortgpt: Layers in large language models are more redundant than you expect , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
work page 2025
-
[12]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
IG-Pruning: Input-Guided Block Pruning for Large Language Models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[16]
Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , year=
HellaSwag: Can a Machine Really Finish Your Sentence? , author=. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics , year=
-
[18]
Advances in neural information processing systems , volume=
Llm-pruner: On the structural pruning of large language models , author=. Advances in neural information processing systems , volume=
-
[20]
Pruning via Merging: Compressing LLMs via Manifold Alignment Based Layer Merging , author=. ArXiv , year=
-
[21]
arXiv preprint arXiv:2401.08139 , year=
Transferring core knowledge via learngenes , author=. arXiv preprint arXiv:2401.08139 , year=
-
[22]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Learngene: From open-world to your learning task , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[23]
Advances in Neural Information Processing Systems , volume=
Initializing variable-sized vision transformers from learngene with learnable transformation , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Building variable-sized models via learngene pool , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[27]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Inheriting Generalized Learngene for Efficient Knowledge Transfer across Multiple Tasks , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[28]
arXiv preprint arXiv:2506.16673 , year=
Extracting Multimodal Learngene in CLIP: Unveiling the Multimodal Generalizable Knowledge , author=. arXiv preprint arXiv:2506.16673 , year=
-
[29]
Forty-first International Conference on Machine Learning , year=
Vision transformers as probabilistic expansion from learngene , author=. Forty-first International Conference on Machine Learning , year=
-
[30]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Transformer as linear expansion of learngene , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[31]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Winogrande: An adversarial winograd schema challenge at scale , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[32]
Proceedings of the AAAI conference on artificial intelligence , volume=
Piqa: Reasoning about physical commonsense in natural language , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[33]
BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions , author =. NAACL , year =
-
[34]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Measuring Massive Multitask Language Understanding , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[35]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Aligning AI With Shared Human Values , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[36]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Fluctuation-based adaptive structured pruning for large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[37]
arXiv preprint arXiv:2402.09025 , year=
Sleb: Streamlining llms through redundancy verification and elimination of transformer blocks , author=. arXiv preprint arXiv:2402.09025 , year=
-
[38]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Pruning via merging: Compressing llms via manifold alignment based layer merging , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2024
-
[39]
International conference on machine learning , pages=
Similarity of neural network representations revisited , author=. International conference on machine learning , pages=. 2019 , organization=
work page 2019
- [44]
-
[45]
Understanding intermediate layers using linear classifier probes
Alain, G. and Bengio, Y. Understanding intermediate layers using linear classifier probes. arXiv preprint arXiv:1610.01644, 2016
work page Pith review arXiv 2016
-
[46]
Slicegpt: Compress large language models by deleting rows and columns,
Ashkboos, S., Croci, M. L., Nascimento, M. G. d., Hoefler, T., and Hensman, J. Slicegpt: Compress large language models by deleting rows and columns. arXiv preprint arXiv:2401.15024, 2024
-
[47]
Eliciting Latent Predictions from Transformers with the Tuned Lens
Belrose, N., Furman, Z., Smith, L., Halawi, D., Ostrovsky, I., McKinney, L., Biderman, S., and Steinhardt, J. Eliciting latent predictions from transformers with the tuned lens. arXiv preprint arXiv:2303.08112, 2023
work page internal anchor Pith review arXiv 2023
-
[48]
Piqa: Reasoning about physical commonsense in natural language
Bisk, Y., Zellers, R., Gao, J., Choi, Y., et al. Piqa: Reasoning about physical commonsense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, pp.\ 7432--7439, 2020
work page 2020
-
[49]
Boolq: Exploring the surprising difficulty of natural yes/no questions
Clark, C., Lee, K., Chang, M.-W., Kwiatkowski, T., Collins, M., and Toutanova, K. Boolq: Exploring the surprising difficulty of natural yes/no questions. In NAACL, 2019
work page 2019
-
[50]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., and Tafjord, O. Think you have solved question answering? try arc, the ai2 reasoning challenge. arXiv:1803.05457v1, 2018
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[51]
Dubey, A., Jauhri, A., Pandey, A., Kadian, A., Al-Dahle, A., Letman, A., Mathur, A., Schelten, A., Yang, A., Fan, A., et al. The llama 3 herd of models. arXiv e-prints, pp.\ arXiv--2407, 2024
work page 2024
- [52]
-
[53]
Measuring massive multitask language understanding
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., and Steinhardt, J. Measuring massive multitask language understanding. Proceedings of the International Conference on Learning Representations (ICLR), 2021
work page 2021
-
[54]
Shortened llama: Depth pruning for large language models with comparison of retraining methods, 2024
Kim, B.-K., Kim, G., Kim, T.-H., Castells, T., Choi, S., Shin, J., and Song, H.-K. Shortened llama: A simple depth pruning for large language models. arXiv preprint arXiv:2402.02834, 11: 0 1, 2024
-
[55]
Similarity of neural network representations revisited
Kornblith, S., Norouzi, M., Lee, H., and Hinton, G. Similarity of neural network representations revisited. In International conference on machine learning, pp.\ 3519--3529. PMlR, 2019
work page 2019
-
[56]
Losparse: Structured compression of large language models based on low-rank and sparse approximation
Li, Y., Yu, Y., Zhang, Q., Liang, C., He, P., Chen, W., and Zhao, T. Losparse: Structured compression of large language models based on low-rank and sparse approximation. In International Conference on Machine Learning, pp.\ 20336--20350. PMLR, 2023
work page 2023
-
[57]
Pruning via merging: Compressing llms via manifold alignment based layer merging
Liu, D., Qin, Z., Wang, H., Yang, Z., Wang, Z., Rong, F., Liu, Q., Hao, Y., Chen, X., Fan, C., Lv, Z., Tu, Z., Chu, D., and Sui, D. Pruning via merging: Compressing llms via manifold alignment based layer merging. ArXiv, abs/2406.16330, 2024. URL https://api.semanticscholar.org/CorpusID:270702954
-
[58]
Llm-pruner: On the structural pruning of large language models
Ma, X., Fang, G., and Wang, X. Llm-pruner: On the structural pruning of large language models. Advances in neural information processing systems, 36: 0 21702--21720, 2023
work page 2023
-
[59]
Shortgpt: Layers in large language models are more redundant than you expect
Men, X., Xu, M., Zhang, Q., Yuan, Q., Wang, B., Lin, H., Lu, Y., Han, X., and Chen, W. Shortgpt: Layers in large language models are more redundant than you expect. In Findings of the Association for Computational Linguistics: ACL 2025, pp.\ 20192--20204, 2025
work page 2025
-
[60]
Interpreting GPT : the logit lens
nostalgebraist. Interpreting GPT : the logit lens. https://www.lesswrong.com/posts/AcKRB8wDpdaN6v6ru/interpreting-gpt-the-logit-lens, August 2020. Accessed: 2025-11-22
work page 2020
-
[61]
In-context Learning and Induction Heads
Olsson, C., Elhage, N., Nanda, N., Joseph, N., DasSarma, N., Henighan, T., Mann, B., Askell, A., Bai, Y., Chen, A., et al. In-context learning and induction heads. arXiv preprint arXiv:2209.11895, 2022
work page internal anchor Pith review arXiv 2022
-
[62]
Ig-pruning: Input-guided block pruning for large language models
Qiao, K., Zhang, S., and Feng, Y. Ig-pruning: Input-guided block pruning for large language models. In Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pp.\ 10629--10640, 2025
work page 2025
-
[63]
Winogrande: An adversarial winograd schema challenge at scale
Sakaguchi, K., Le Bras, R., Bhagavatula, C., and Choi, Y. Winogrande: An adversarial winograd schema challenge at scale. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, pp.\ 8732--8740, 2020
work page 2020
-
[64]
Building variable-sized models via learngene pool
Shi, B., Xia, S., Yang, X., Chen, H., Kou, Z., and Geng, X. Building variable-sized models via learngene pool. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp.\ 14946--14954, 2024
work page 2024
-
[65]
Pocketllm: Ultimate compression of large language models via meta networks
Tian, Y., Wang, C., Han, J., Tang, Y., and Han, K. Pocketllm: Ultimate compression of large language models via meta networks. arXiv preprint arXiv:2511.17637, 2025
-
[66]
Llama 2: Open Foundation and Fine-Tuned Chat Models
Touvron, H., Martin, L., Stone, K., Albert, P., Almahairi, A., Babaei, Y., Bashlykov, N., Batra, S., Bhargava, P., Bhosale, S., et al. Llama 2: Open foundation and fine-tuned chat models. arXiv preprint arXiv:2307.09288, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[67]
Layer as puzzle pieces: Compressing large language models through layer concatenation
Wang, F., Shen, L., Ding, L., Xue, C., Liu, Y., and Ding, C. Layer as puzzle pieces: Compressing large language models through layer concatenation. arXiv preprint arXiv:2510.15304, 2025
-
[68]
arXiv preprint arXiv:2305.02279 , year=
Wang, Q., Yang, X., Lin, S., Wang, J., and Geng, X. Learngene: Inheriting condensed knowledge from the ancestry model to descendant models. arXiv preprint arXiv:2305.02279, 2023
-
[69]
Vision transformers as probabilistic expansion from learngene
Wang, Q., Yang, X., Chen, H., and Geng, X. Vision transformers as probabilistic expansion from learngene. In Forty-first International Conference on Machine Learning, 2024
work page 2024
-
[70]
Learngene: From open-world to your learning task
Wang, Q.-F., Geng, X., Lin, S.-X., Xia, S.-Y., Qi, L., and Xu, N. Learngene: From open-world to your learning task. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, pp.\ 8557--8565, 2022
work page 2022
-
[71]
Wang, Z. Logitlens4llms: Extending logit lens analysis to modern large language models. arXiv preprint arXiv:2503.11667, 2025
-
[72]
Transformer as linear expansion of learngene
Xia, S., Zhang, M., Yang, X., Chen, R., Chen, H., and Geng, X. Transformer as linear expansion of learngene. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pp.\ 16014--16022, 2024 a
work page 2024
-
[73]
arXiv preprint arXiv:2404.16897 , year=
Xia, S.-Y., Zhu, W., Yang, X., and Geng, X. Exploring learngene via stage-wise weight sharing for initializing variable-sized models. arXiv preprint arXiv:2404.16897, 2024 b
-
[74]
Yang, A., Li, A., Yang, B., Zhang, B., Hui, B., Zheng, B., Yu, B., Gao, C., Huang, C., Lv, C., et al. Qwen3 technical report. arXiv preprint arXiv:2505.09388, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[75]
Laco: Large language model pruning via layer collapse, 2024
Yang, Y., Cao, Z., and Zhao, H. Laco: Large language model pruning via layer collapse. arXiv preprint arXiv:2402.11187, 2024
-
[76]
Zellers, R., Holtzman, A., Bisk, Y., Farhadi, A., and Choi, Y. Hellaswag: Can a machine really finish your sentence? In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 2019
work page 2019
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.