Recognition: 2 theorem links
· Lean TheoremEvaluating voice anonymisation using similarity rank disclosure
Pith reviewed 2026-05-11 00:51 UTC · model grok-4.3
The pith
Similarity rank disclosure exposes voice anonymisation privacy leaks that equal error rates miss.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
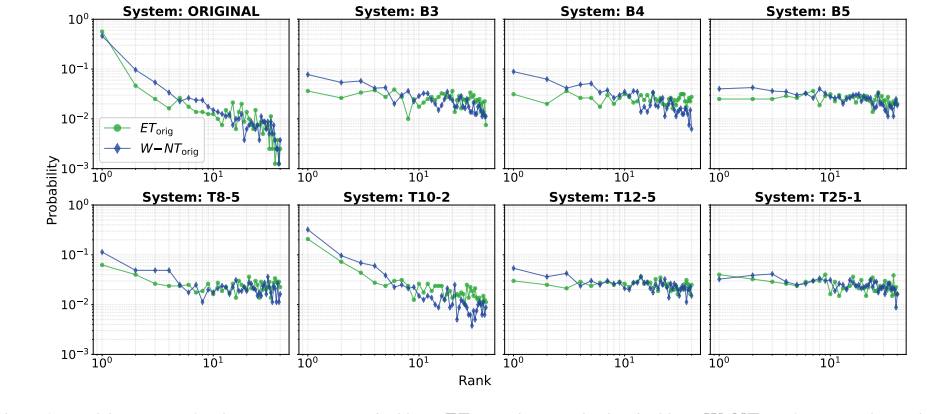
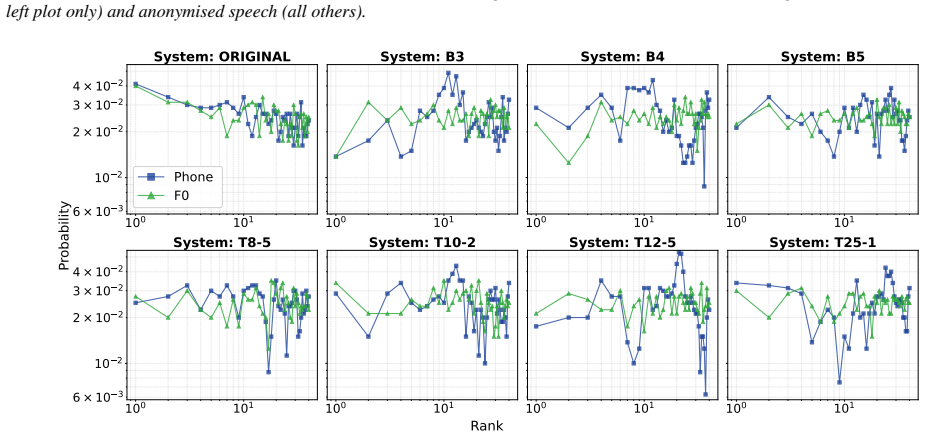
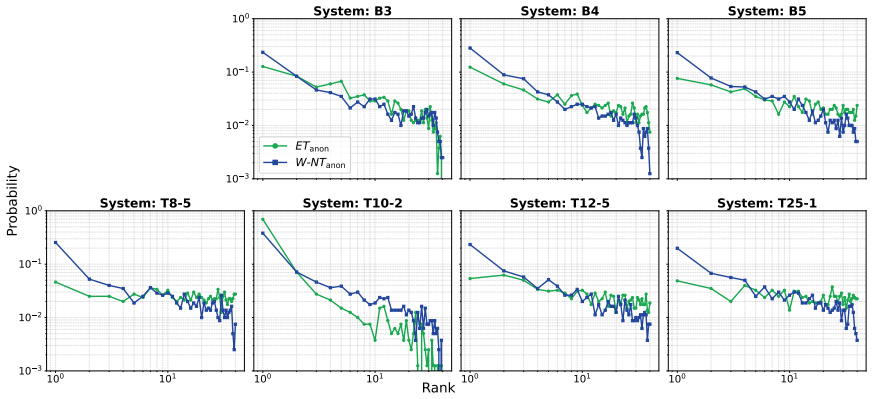
Similarity rank disclosure is an information-theoretic metric that ranks similarities between original and anonymised feature representations to quantify privacy leakage without reference to any classifier or decision threshold. Applied to the 2024 VoicePrivacy Challenge submissions, the metric detects privacy leaks and system-specific weaknesses in speaker embeddings, fundamental frequency, and phone embeddings that remain hidden when the same systems are assessed solely by equal error rate.
What carries the argument
Similarity rank disclosure (SRD), an information-theoretic rank metric computed on feature representations that measures how much original speaker identity remains distinguishable through ordered similarity scores.
If this is right
- SRD identifies privacy leaks missed by EER-based evaluation of voice anonymisation systems.
- The metric supports separate assessment of average and worst-case disclosure without choosing a threshold.
- Representation-level analysis reveals weaknesses tied to particular features such as embeddings or fundamental frequency.
- SRD functions as a flexible, interpretable complement to existing verification metrics for anonymisation evaluation.
Where Pith is reading between the lines
- Adoption of SRD would encourage anonymisation algorithms to reduce ranked similarity leakage rather than optimise only for classifier error rates.
- The same rank-based approach could be tested on other biometric modalities where feature representations are available.
- Worst-case SRD scores might become a practical target for regulatory or auditing standards that require guaranteed privacy bounds.
Load-bearing premise
That operating on feature representations with an information-theoretic rank metric supplies a more complete and less misleading characterisation of privacy risk than classifier-dependent equal error rates.
What would settle it
A controlled test in which the same anonymised utterances produce low equal error rate (suggesting strong privacy) but high similarity rank disclosure (suggesting substantial leakage), or the reverse mismatch, on identical data.
Figures

read the original abstract
The evaluation of voice anonymisation remains challenging. Current practice relies on automatic speaker verification metrics such as the equal error rate (EER). Performance estimates dependent on the classifier and operating point provide an incomplete or even misleading characterisation of privacy risk. We investigate the use of similarity rank disclosure (SRD), an information-theoretic metric, which operates on feature representations rather than classifier decisions, providing a threshold-independent assessment of privacy and analysis of both average and worst-case disclosure. We report its application to speaker embeddings, fundamental frequency, and phone embeddings using 2024 VoicePrivacy Challenge systems. The SRD reveals privacy leaks and system-specific weaknesses missed by EER-based evaluation. Findings highlight the merit of representation-level metrics and demonstrate the potential of SRD as a flexible and interpretable tool for the evaluation of voice anonymisation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that similarity rank disclosure (SRD), an information-theoretic metric operating directly on feature representations (speaker embeddings, F0, phone embeddings), provides a threshold-independent evaluation of voice anonymisation privacy that reveals leaks and system-specific weaknesses missed by equal error rate (EER) assessments. It demonstrates this by applying SRD to the 2024 VoicePrivacy Challenge systems.
Significance. If the central claim holds, the work supplies a concrete, representation-level alternative to classifier-dependent EER that could improve privacy auditing in voice anonymisation. The explicit application to recent challenge systems and the focus on both average and worst-case disclosure are strengths that would make the metric practically useful if validated.
major comments (2)
- [§4, §5] §4 (Results) and §5 (Discussion): the central assertion that SRD 'reveals privacy leaks and system-specific weaknesses missed by EER' is load-bearing but unsupported by any side-by-side comparison. No table or figure shows that utterances or systems flagged as high-SRD by the rank metric actually produce higher identification success rates under a concrete attacker model than EER predicts.
- [§3.2] §3.2 (SRD definition): the information-theoretic rank disclosure is defined on feature representations, yet the manuscript provides no quantitative check that the additional disclosures flagged by SRD correspond to practically exploitable privacy risks rather than statistical dependencies that remain non-actionable for an adversary.
minor comments (2)
- [§3] Notation for the SRD formula is introduced without an explicit equation number; cross-referencing would improve readability.
- [Abstract, §4] The abstract states that SRD is 'threshold-independent,' but the results section should explicitly contrast the operating-point dependence of EER with the rank-based formulation to make the advantage concrete.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. The comments highlight important aspects of how SRD should be positioned relative to EER and practical attacker models. We address each major comment below and propose targeted revisions to improve clarity and strengthen the claims without overstating the current evidence.
read point-by-point responses
-
Referee: [§4, §5] §4 (Results) and §5 (Discussion): the central assertion that SRD 'reveals privacy leaks and system-specific weaknesses missed by EER' is load-bearing but unsupported by any side-by-side comparison. No table or figure shows that utterances or systems flagged as high-SRD by the rank metric actually produce higher identification success rates under a concrete attacker model than EER predicts.
Authors: We agree that a direct empirical comparison between SRD-flagged cases and actual identification success rates under a concrete attacker would provide stronger validation. The current manuscript demonstrates that SRD can surface differences (e.g., systems with comparable EER but divergent SRD) at the representation level, which EER cannot capture because it depends on a specific verifier and threshold. However, we do not include an explicit attacker simulation linking high-SRD utterances to higher success rates. In revision we will add a new paragraph in §5 that (a) explicitly states this limitation, (b) illustrates with the existing data how rank information could be leveraged by an adversary (e.g., nearest-neighbor lookup in the embedding space), and (c) outlines a possible future experiment that would close the gap. This keeps the focus on the representation-level contribution while acknowledging the missing link to end-to-end attack performance. revision: partial
-
Referee: [§3.2] §3.2 (SRD definition): the information-theoretic rank disclosure is defined on feature representations, yet the manuscript provides no quantitative check that the additional disclosures flagged by SRD correspond to practically exploitable privacy risks rather than statistical dependencies that remain non-actionable for an adversary.
Authors: SRD is intentionally defined on the raw feature representations precisely because voice anonymization is intended to prevent an adversary from extracting usable speaker information from those representations. The rank statistic directly quantifies how much similarity ordering is preserved, which is actionable for any downstream nearest-neighbor or ranking-based attack. That said, the manuscript does not provide a quantitative mapping from SRD values to measured attack success rates. We will revise §3.2 to include a short paragraph explaining why representation-level rank disclosure is a conservative (i.e., upper-bound) indicator of risk, and we will expand the discussion in §5 to reference existing literature on embedding-based attacks that could exploit the disclosed ranks. No new attack experiments will be added in this revision, but the text will make the actionability argument more explicit. revision: partial
Circularity Check
SRD introduced as independent information-theoretic metric on features; no reduction to EER or self-inputs
full rationale
The paper defines SRD explicitly as an information-theoretic metric operating directly on feature representations (speaker embeddings, F0, phone embeddings) rather than classifier outputs or decisions. This is positioned as an alternative to EER-based evaluation without deriving SRD from EER, fitting parameters to EER data, or invoking self-citations as load-bearing uniqueness theorems. The reported application to 2024 VoicePrivacy systems and the claim that SRD reveals additional leaks are empirical observations, not tautological redefinitions or predictions forced by construction. No equations or steps in the provided text reduce the central metric or claims to the inputs by definition, self-citation chains, or ansatzes smuggled from prior author work.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
The SRD is an information-theoretic metric, which operates on feature representations rather than classifier decisions, providing a threshold-independent assessment of privacy and analysis of both average and worst-case disclosure.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Beyond voice iden- tity, speech recordings can reveal sensitive attributes such as the speaker’s age, gender, emotional state, etc
Introduction Smart devices and cloud services are nowadays constantly cap- turing and processing speech data [1, 2]. Beyond voice iden- tity, speech recordings can reveal sensitive attributes such as the speaker’s age, gender, emotional state, etc. [2, 3]. The per- vasive capture and inherent sensitivity of speech data, coupled with evolving privacy regul...
2020
-
[2]
Evaluating voice anonymisation using similarity rank disclosure
Related work The strength of any approach to privacy protection is usually es- timated empirically according to a particular threat model [12] and simulated attacks launched to defeat the protection. The strength is then quantified according to some objective met- ric that indicates the attack success rate. In the case of voice anonymisation, the metric r...
work page internal anchor Pith review Pith/arXiv arXiv 2020
-
[3]
Information is quantified in bits, hence enabling comparisons between the disclosure of information contained in different speech characteristics
Similarity Rank Disclosure The SRD provides a framework to measure PII contained within speech utterances [7]. Information is quantified in bits, hence enabling comparisons between the disclosure of information contained in different speech characteristics. Operating di- rectly upon speech features instead of classifier decisions, the SRD provides a class...
-
[4]
In the following section, we describe the data used and a set of four feature representations
Experimental Setup While the original work [7] reports a study of privacy disclo- sure for original, unprotected speech data, we have applied the SRD to the study and comparison of privacy disclosure for speech data treated with different approaches to voice anonymi- sation [6]. In the following section, we describe the data used and a set of four feature...
2024
-
[5]
Results We present rank histograms for features described in Section 4.2 and differences in qualitative results derived using a stronger semi-informed attack model. We then present quantitative re- sults derived using metrics described in Section 3.3, followed by a comparison to results from the use of statistical approxi- mations described in Section 3.2...
-
[6]
These go beyond a single snapshot like that provided from estimates of the EER in the form of the mean and worst case disclosure and the rank spread
Discussion The SRD provides revealing insights into the differences in pri- vacy protection for competing anonymisation solutions. These go beyond a single snapshot like that provided from estimates of the EER in the form of the mean and worst case disclosure and the rank spread. By casting evaluation as an identification prob- lem instead of verification...
2024
-
[7]
Compared to the automatic speaker verification equal error rate (EER), the SRD offers a more interpretable and fine-grained characterisation of resid- ual privacy risk
Conclusions We investigated use of the similarity rank disclosure (SRD) for evaluating voice anonymisation, providing an information- theoretic assessment of privacy. Compared to the automatic speaker verification equal error rate (EER), the SRD offers a more interpretable and fine-grained characterisation of resid- ual privacy risk. Results for 2024 V oi...
2024
-
[8]
We would also like to thank Rayane Bakari, Nicolas Gengembre, and Olivier Le Blouch (Orange innovation, France) for provid- ing the pre-trained models for W-NT
Acknowledgements This work was funded by the European Union’s Horizon Europe research and innovation programme grant No 101168193. We would also like to thank Rayane Bakari, Nicolas Gengembre, and Olivier Le Blouch (Orange innovation, France) for provid- ing the pre-trained models for W-NT
-
[9]
Understanding the tradeoffs in client-side privacy for downstream speech tasks,
P. Wu, P. P. Liang, J. Shi, R. Salakhutdinov, S. Watanabe, and L.-P. Morency, “Understanding the tradeoffs in client-side privacy for downstream speech tasks,” in2021 Asia-Pacific Signal and Infor- mation Processing Association Annual Summit and Conference (APSIPA ASC). IEEE, 2021, pp. 841–848
2021
-
[10]
Privacy in speech technology,
T. Bäckström, “Privacy in speech technology,”Proceedings of the IEEE, vol. 113, no. 7, pp. 668–692, 2025
2025
-
[11]
Preserving privacy in speaker and speech characterisation,
A. Nautsch, A. Jiménez, A. Treiber, J. Kolberg, C. Jasserand, E. Kindt, H. Delgado, M. Todisco, M. A. Hmani, A. Mtibaa, M. A. Abdelraheem, A. Abad, F. Teixeira, D. Matrouf, M. Gomez- Barrero, D. Petrovska-Delacrétaz, G. Chollet, N. Evans, T. Schneider, J.-F. Bonastre, B. Raj, I. Trancoso, and C. Busch, “Preserving privacy in speaker and speech characteris...
2019
-
[12]
The GDPR & Speech Data: Reflections of Legal and Technology Communities, First Steps Towards a Common Un- derstanding,
A. Nautsch, C. Jasserand, E. Kindt, M. Todisco, I. Trancoso, and N. Evans, “The GDPR & Speech Data: Reflections of Legal and Technology Communities, First Steps Towards a Common Un- derstanding,” inInterspeech 2019. ISCA, Sep. 2019, pp. 3695– 3699
2019
-
[13]
Introducing the V oicePrivacy Initiative,
N. Tomashenko, B. M. L. Srivastava, X. Wang, E. Vincent, A. Nautsch, J. Yamagishi, N. Evans, J. Patino, J.-F. Bonastre, P.-G. Noé, and M. Todisco, “Introducing the V oicePrivacy Initiative,” in Interspeech 2020. ISCA, Oct. 2020, pp. 1693–1697
2020
-
[14]
N. Tomashenko, X. Miao, P. Champion, S. Meyer, X. Wang, E. Vincent, M. Panariello, N. Evans, J. Yamagishi, and M. Todisco. The V oicePrivacy 2024 Challenge Evaluation Plan. [Online]. Available: http://arxiv.org/abs/2404.02677
-
[15]
Privacy disclosure of similarity rank in speech and language processing,
T. Bäckström, M. H. Vali, M. Nguyen, and S. Rech, “Privacy disclosure of similarity rank in speech and language processing,” IEEE Transactions on Audio, Speech and Language Processing, vol. 34, pp. 196–205, 2026
2026
-
[16]
YIN, a fundamental frequency estimator for speech and music,
A. de Cheveigné and H. Kawahara, “YIN, a fundamental frequency estimator for speech and music,”The Journal of the Acoustical Society of America, vol. 111, no. 4, pp. 1917–1930, 04
1917
-
[17]
Alexandre Défossez, Jade Copet, Gabriel Synnaeve, and Yossi Adi
[Online]. Available: https://doi.org/10.1121/1.1458024
-
[18]
Vector-Quantized Neural Networks for Acoustic Unit Discovery in the ZeroSpeech 2020 Challenge,
B. van Niekerk, L. Nortje, and H. Kamper, “Vector-Quantized Neural Networks for Acoustic Unit Discovery in the ZeroSpeech 2020 Challenge,” inInterspeech 2020, 2020, pp. 4836–4840
2020
-
[19]
ECAPA- TDNN: Emphasized Channel Attention, Propagation and Ag- gregation in TDNN Based Speaker Verification,
B. Desplanques, J. Thienpondt, and K. Demuynck, “ECAPA- TDNN: Emphasized Channel Attention, Propagation and Ag- gregation in TDNN Based Speaker Verification,” inInterspeech 2020, 2020, pp. 3830–3834
2020
-
[20]
The influence of non-timbral cues in voice anonymisation and evaluation,
R. Bakari, O. L. Blouch, N. Evans, N. Gengembre, M. Panariello, and M. Todisco, “The influence of non-timbral cues in voice anonymisation and evaluation,” in5th Symposium on Security and Privacy in Speech Communication, 2025, pp. 35–42
2025
-
[21]
Scenario of Use Scheme: Threat Modelling for Speaker Privacy Protection in the Medical Domain,
M. U. Rahman, M. Larson, L. ten Bosch, and C. Tejedor-García, “Scenario of Use Scheme: Threat Modelling for Speaker Privacy Protection in the Medical Domain,” in4th Symposium on Security and Privacy in Speech Communication, 2024, pp. 21–25
2024
-
[22]
A comparative study of speech anonymization metrics,
M. Maouche, B. M. L. Srivastava, N. Vauquier, A. Bellet, M. Tommasi, and E. Vincent, “A comparative study of speech anonymization metrics,” inINTERSPEECH 2020, 2020
2020
-
[23]
The V oicePrivacy 2020 challenge: results and findings,
N. Tomashenko, X. Wang, E. Vincent, J. Patino, B. M. L. Srivas- tava, P.-G. Noé, A. Nautsch, N. Evans, J. Yamagishi, B. O’Brien et al., “The V oicePrivacy 2020 challenge: results and findings,” Computer Speech & Language, vol. 74, p. 101362, 2022
2020
-
[24]
Out of a Hundred Trials, How Many Errors Does Your Speaker Verifier Make?
N. Brümmer, L. Ferrer, and A. Swart, “Out of a Hundred Trials, How Many Errors Does Your Speaker Verifier Make?” inInter- speech 2021, 2021, pp. 1059–1063
2021
-
[25]
t-eer: Parameter-free tandem evaluation of countermeasures and biometric comparators,
T. H. Kinnunen, K. A. Lee, H. Tak, N. Evans, and A. Nautsch, “t-eer: Parameter-free tandem evaluation of countermeasures and biometric comparators,”IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 46, no. 5, pp. 2622–2637, 2024
2024
-
[26]
The Privacy ZE- BRA: Zero Evidence Biometric Recognition Assessment,
A. Nautsch, J. Patino, N. Tomashenko, J. Yamagishi, P.-G. Noé, J.-F. Bonastre, M. Todisco, and N. Evans, “The Privacy ZE- BRA: Zero Evidence Biometric Recognition Assessment,” inIn- terspeech 2020, 2020, pp. 1698–1702
2020
-
[27]
Application-independent evaluation of speaker detection,
N. Brümmer and J. du Preez, “Application-independent evaluation of speaker detection,”Computer Speech & Language, vol. 20, no. 2, pp. 230–275, 2006, odyssey 2004: The speaker and Language Recognition Workshop. [Online]. Available: https:// www.sciencedirect.com/science/article/pii/S0885230805000483
2006
-
[28]
Gen- eral framework to evaluate unlinkability in biometric template protection systems,
M. Gomez-Barrero, J. Galbally, C. Rathgeb, and C. Busch, “Gen- eral framework to evaluate unlinkability in biometric template protection systems,”IEEE Transactions on Information Forensics and Security, vol. 13, no. 6, pp. 1406–1420, 2017
2017
-
[29]
Legally validated evaluation framework for voice anonymiza- tion,
N. Vauquier, B. M. L. Srivastava, S. A. Hosseini, and E. Vincent, “Legally validated evaluation framework for voice anonymiza- tion,” inInterspeech 2025, 2025, pp. 3229–3233
2025
-
[30]
N. Tomashenko, X. Miao, E. Vincent, and J. Yamagishi. The First V oicePrivacy Attacker Challenge Evaluation Plan. [Online]. Available: http://arxiv.org/abs/2410.07428
-
[31]
N. Tomashenko, X. Wang, X. Miao, H. Nourtel, P. Champion, M. Todisco, E. Vincent, N. Evans, J. Yamagishi, and J.-F. Bonastre. The V oicePrivacy 2022 Challenge Evaluation Plan. [Online]. Available: http://arxiv.org/abs/2203.12468
-
[32]
WavLM: Large- Scale Self-Supervised Pre-Training for Full Stack Speech Pro- cessing,
S. Chen, C. Wang, Z. Chen, Y . Wu, S. Liu, Z. Chen, J. Li, N. Kanda, T. Yoshioka, X. Xiao, J. Wu, L. Zhou, S. Ren, Y . Qian, Y . Qian, J. Wu, M. Zeng, X. Yu, and F. Wei, “WavLM: Large- Scale Self-Supervised Pre-Training for Full Stack Speech Pro- cessing,”IEEE Journal of Selected Topics in Signal Processing, vol. 16, no. 6, pp. 1505–1518, 2022
2022
-
[33]
Lib- rispeech: An ASR corpus based on public domain audio books,
V . Panayotov, G. Chen, D. Povey, and S. Khudanpur, “Lib- rispeech: An ASR corpus based on public domain audio books,” in2015 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 2015, pp. 5206–5210
2015
-
[34]
SpeechBrain: A general-purpose speech toolkit,
M. Ravanelli, T. Parcollet, P. Plantinga, A. Rouhe, S. Cornell, L. Lugosch, C. Subakan, N. Dawalatabad, A. Heba, J. Zhong, J.-C. Chou, S.-L. Yeh, S.-W. Fu, C.-F. Liao, E. Rastorgueva, F. Grondin, W. Aris, H. Na, Y . Gao, R. D. Mori, and Y . Bengio. SpeechBrain: A General-Purpose Speech Toolkit. [Online]. Available: http://arxiv.org/abs/2106.04624
-
[35]
Disentangling prosody and timbre embeddings via voice conversion,
N. Gengembre, O. Le Blouch, and C. Gendrot, “Disentangling prosody and timbre embeddings via voice conversion,” inInter- speech 2024, 2024, pp. 2765–2769
2024
-
[36]
PYIN a fundamental frequency esti- mator using probabilistic threshold distributions,
M. Mauch and S. Dixon, “PYIN a fundamental frequency esti- mator using probabilistic threshold distributions,” in2014 IEEE International Conference on Acoustics, Speech and Signal Pro- cessing (ICASSP), 2014, pp. 659–663
2014
-
[37]
Interpretable Latent Space Using Space-Filling Curves for Phonetic Analysis in V oice Conversion,
M. H. Vali and T. Bäckström, “Interpretable Latent Space Using Space-Filling Curves for Phonetic Analysis in V oice Conversion,” inInterspeech 2023, 2023, pp. 306–310
2023
-
[38]
Exploiting Context-dependent Duration Features for V oice Anonymization Attack Systems,
N. Tomashenko, E. Vincent, and M. Tommasi, “Exploiting Context-dependent Duration Features for V oice Anonymization Attack Systems,” inInterspeech 2025, 2025, pp. 5128–5132
2025
-
[39]
Available: https://arxiv.org/abs/2601.11846
N. Tomashenko, X. Miao, P. Champion, S. Meyer, M. Panariello, X. Wang, N. Evans, E. Vincent, J. Yamagishi, and M. Todisco, “The third V oicePrivacy challenge: preserving emotional expres- siveness and linguistic content in voice anonymization,”arXiv preprint arXiv:2601.11846, 2026
-
[40]
The Risks and Detection of Overestimated Privacy Protection in V oice Anonymisation,
M. Panariello, S. Meyer, P. Champion, X. Miao, M. Todisco, N. T. Vu, and N. Evans, “The Risks and Detection of Overestimated Privacy Protection in V oice Anonymisation,” in5th Symposium on Security and Privacy in Speech Communication, 2025, pp. 8– 12
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.