Recognition: no theorem link
When Stored Evidence Stops Being Usable: Scale-Conditioned Evaluation of Agent Memory
Pith reviewed 2026-05-11 01:12 UTC · model grok-4.3
The pith
Agent memory reliability is not uniform but degrades at different rates as irrelevant sessions accumulate, shown by holding task evidence fixed while scaling noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
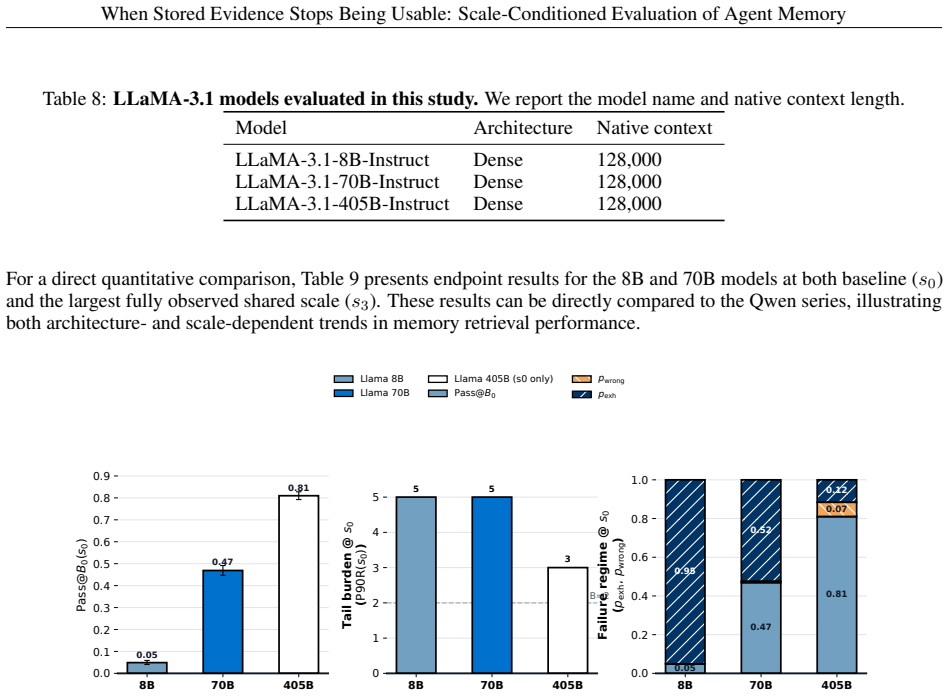
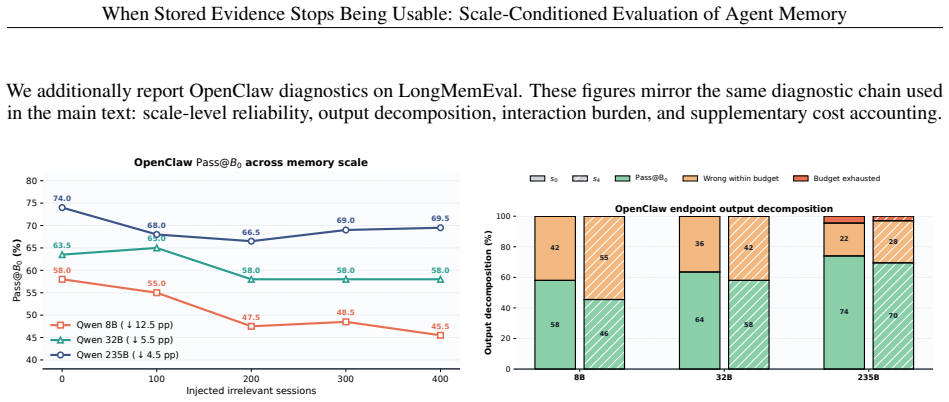
The protocol demonstrates that reliability loss is not a single phenomenon. On LongMemEval, HippoRAG stays inside the two-call budget yet loses 16-20 percentage points in budget-compliant reliability as irrelevant sessions are added; LiCoMemory outcomes depend strongly on the agent, with Qwen3-8B exceeding the budget while Qwen3-32B and Qwen3-235B remain reliable across the tested range. The same pattern appears on LoCoMo across flat, planar, and hierarchical memory interfaces, supporting a framework in which scalable-memory claims must be stated conditional on agent, interface, scale range, and interaction budget.
What carries the argument
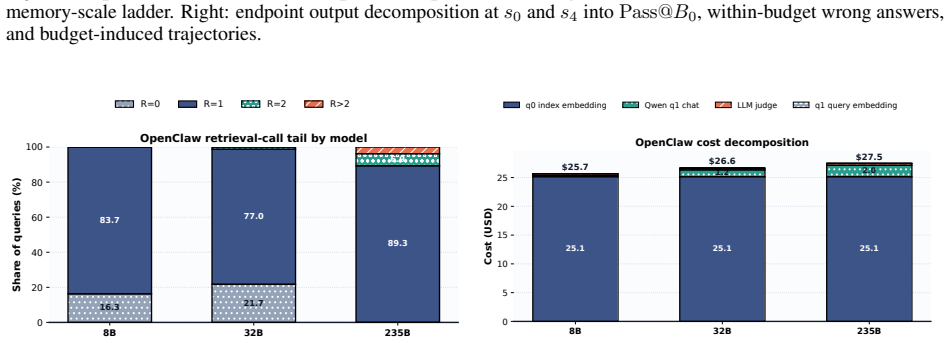
The scale-conditioned evaluation protocol: task evidence is held fixed for each query while irrelevant sessions are added, agent-memory trajectories are logged, and four diagnostics are reported including budget-compliant reliability and the usable-scale boundary.
If this is right
- Memory evaluations must condition on scale growth to produce valid usability measurements.
- Different memory interfaces and agent models exhibit distinct degradation patterns under identical scale increases.
- The usable-scale boundary supplies a concrete limit beyond which a given system cannot be trusted to stay reliable.
- Scalable-memory claims are meaningful only when they specify the interaction budget and the range of scales tested.
Where Pith is reading between the lines
- Real-world agents that accumulate data over months or years would require explicit mechanisms to prevent irrelevant content from crowding out usable evidence.
- The same conditioning approach could be applied to test whether memory-compression or selective-forgetting techniques extend the usable-scale boundary.
- Problems such as continual learning and lifelong agents share the same core issue of data accumulation and could adopt similar scale-aware diagnostics.
Load-bearing premise
Benchmark annotations correctly identify every piece of task-relevant evidence so that the added sessions are genuinely irrelevant.
What would settle it
Running the protocol on a benchmark whose annotations have been exhaustively verified to contain all relevant evidence and finding that reliability curves remain flat across scales for the tested systems would falsify the observed patterns of degradation.
Figures








read the original abstract
Memory-agent evaluations report fixed-snapshot accuracy or retrieval quality, but these scores do not show whether evidence remains usable as irrelevant sessions (sessions not annotated as task-relevant evidence for the query) accumulate. We present a scale-conditioned evaluation protocol for agent memory under evidence-preserving growth: for each query, task evidence is held fixed while irrelevant sessions are added. The protocol logs agent--memory trajectories and reports four diagnostics: budget-compliant reliability, tail memory-call burden, failure-regime decomposition, and the usable-scale boundary where reliability falls below the target. Applied to LongMemEval and LoCoMo across flat, planar, and hierarchical memory interfaces, the protocol shows reliability loss is not a single phenomenon. On LongMemEval, HippoRAG stays within the two-call budget but loses 16--20 percentage points in budget-compliant reliability as irrelevant sessions are added; LiCoMemory's observed failures depend strongly on the agent, with Qwen3-8B exceeding the budget while Qwen3-32B and Qwen3-235B remain reliable in the tested range. The result supports a framework for making scalable-memory claims conditional on agent, interface, scale range, and interaction budget.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a scale-conditioned evaluation protocol for agent memory that holds task-relevant evidence fixed for each query while adding sessions labeled irrelevant via existing benchmark annotations. It logs agent-memory trajectories and computes four diagnostics—budget-compliant reliability, tail memory-call burden, failure-regime decomposition, and the usable-scale boundary—applied to LongMemEval and LoCoMo across flat, planar, and hierarchical memory interfaces. The central empirical claim is that reliability loss is not a single phenomenon: HippoRAG on LongMemEval loses 16–20 percentage points in budget-compliant reliability while remaining within the two-call budget, whereas LiCoMemory failures are strongly agent-dependent (Qwen3-8B exceeds budget while larger Qwen3 variants remain reliable).
Significance. If the protocol's assumptions hold, the work provides a valuable framework for conditioning scalable-memory claims on agent, interface, scale range, and interaction budget, moving beyond fixed-snapshot accuracy metrics. Concrete quantitative results and trajectory logging offer actionable distinctions between memory interfaces and highlight non-uniform degradation patterns. Strengths include the empirical application to established benchmarks without new fitted parameters and the focus on interaction budgets rather than static retrieval quality.
major comments (2)
- [Protocol definition] Protocol section (description of scale-conditioning): The central claim that reliability loss varies by agent and interface (e.g., 16–20 pp drop for HippoRAG, agent-dependent budget exceedance for LiCoMemory) depends on the assumption that benchmark annotations exhaustively identify all task-relevant evidence so that added sessions contain zero query-relevant information. No validation, sensitivity analysis, or check for missed relevant content is described; if annotations are incomplete, observed reliability curves and usable-scale boundaries could reflect interference rather than pure scale-induced memory effects, directly undermining the four diagnostics.
- [Results and diagnostics] Experimental results (reporting of quantitative drops and agent behaviors): The manuscript states specific percentage-point losses and budget exceedances but provides no full data tables, error bars, or statistical tests in the reported findings. This limits verification of the robustness of the 'not a single phenomenon' conclusion and the precise usable-scale boundaries across the tested range.
minor comments (2)
- [Abstract] The abstract lists the four diagnostics but does not name them until later; early explicit enumeration would improve readability.
- [Protocol] Notation for 'budget-compliant reliability' and 'tail memory-call burden' should be formally defined with equations or pseudocode in the protocol section to avoid ambiguity in trajectory logging.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We address each major point below, clarifying our approach and indicating revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Protocol definition] Protocol section (description of scale-conditioning): The central claim that reliability loss varies by agent and interface (e.g., 16–20 pp drop for HippoRAG, agent-dependent budget exceedance for LiCoMemory) depends on the assumption that benchmark annotations exhaustively identify all task-relevant evidence so that added sessions contain zero query-relevant information. No validation, sensitivity analysis, or check for missed relevant content is described; if annotations are incomplete, observed reliability curves and usable-scale boundaries could reflect interference rather than pure scale-induced memory effects, directly undermining the four diagnostics.
Authors: We thank the referee for identifying this foundational assumption. The protocol is explicitly built on the query-specific evidence annotations supplied by LongMemEval and LoCoMo; sessions not marked as relevant are treated as irrelevant and added while holding the annotated evidence fixed. No additional validation or sensitivity analysis appears in the submitted version because the design deliberately avoids introducing new parameters or manual labeling beyond the benchmarks. We agree that incomplete annotations could allow residual interference, which would affect the diagnostics. In revision we will add a dedicated limitations subsection to the protocol description and include a sensitivity analysis that samples added sessions, checks them for overlooked relevance via the evaluated agents, and reports any impact on the observed curves. revision: partial
-
Referee: [Results and diagnostics] Experimental results (reporting of quantitative drops and agent behaviors): The manuscript states specific percentage-point losses and budget exceedances but provides no full data tables, error bars, or statistical tests in the reported findings. This limits verification of the robustness of the 'not a single phenomenon' conclusion and the precise usable-scale boundaries across the tested range.
Authors: We agree that the current reporting can be made more verifiable. The manuscript presents the main quantitative results in the text and figures, but omits exhaustive tables, error bars, and formal statistical tests. In the revised version we will move all per-agent, per-interface, and per-scale metrics into an appendix table, add error bars (bootstrap or standard error) to the reliability and burden plots, and include statistical comparisons (e.g., paired tests or confidence intervals) for the reported drops and boundary differences to support the claim that degradation is not uniform. revision: yes
Circularity Check
No circularity: purely empirical protocol on fixed benchmarks
full rationale
The paper defines a scale-conditioned evaluation protocol that holds task evidence fixed while adding sessions labeled irrelevant by existing benchmark annotations, then computes four diagnostics directly from logged agent-memory trajectories. No equations, fitted parameters, or predictions appear; results (e.g., 16-20 pp reliability drop for HippoRAG) are observed outcomes on LongMemEval and LoCoMo rather than reductions to inputs by construction. No self-citations are invoked as load-bearing premises, and the central claim that reliability loss is not monolithic follows from the empirical variation across agents and interfaces.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Benchmark annotations accurately separate task-relevant evidence from irrelevant sessions
Reference graph
Works this paper leans on
-
[2]
Advances in Neural Information Processing Systems , volume=
Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks , author=. Advances in Neural Information Processing Systems , volume=. 2020 , url=
work page 2020
-
[6]
Voyager: An Open-Ended Embodied Agent with Large Language Models
Voyager: An Open-Ended Embodied Agent with Large Language Models , author=. arXiv preprint arXiv:2305.16291 , year=. 2305.16291 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , pages=
Generative Agents: Interactive Simulacra of Human Behavior , author=. Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology , pages=. 2023 , doi=
work page 2023
-
[12]
Memory Overview , author =
- [14]
-
[17]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
From Local to Global: A Graph RAG Approach to Query-Focused Summarization , author=. arXiv preprint arXiv:2404.16130 , year=. doi:10.48550/arXiv.2404.16130 , url=. 2404.16130 , archivePrefix=
work page internal anchor Pith review doi:10.48550/arxiv.2404.16130
-
[18]
EverMemOS: A Self-Organizing Memory Operating System for Structured Long-Horizon Reasoning , author=. arXiv preprint arXiv:2601.02163 , year=. 2601.02163 , archivePrefix=
-
[21]
Evaluating Memory in LLM Agents via Incremental Multi-Turn Interactions , author=. 2026 , eprint=
work page 2026
-
[22]
Transactions of the Association for Computational Linguistics , volume=
Lost in the Middle: How Language Models Use Long Contexts , author=. Transactions of the Association for Computational Linguistics , volume=. 2024 , doi=
work page 2024
-
[23]
LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2024 , doi=
work page 2024
-
[25]
Jingzhe Shi, Qinwei Ma, Hongyi Liu, Hang Zhao, Jeng- Neng Hwang, and Lei Li
Intrinsic Entropy of Context Length Scaling in LLMs , author=. arXiv preprint arXiv:2502.01481 , year=. 2502.01481 , archivePrefix=
-
[26]
Long-Context: Learning Distraction-Aware Retrieval for Efficient Knowledge Grounding , author=
Beyond RAG vs. Long-Context: Learning Distraction-Aware Retrieval for Efficient Knowledge Grounding , author=. arXiv preprint arXiv:2509.21865 , year=. 2509.21865 , archivePrefix=
-
[27]
arXiv preprint arXiv:2602.07962 , year=
LOCA-bench: Benchmarking Language Agents Under Controllable and Extreme Context Growth , author=. arXiv preprint arXiv:2602.07962 , year=. 2602.07962 , archivePrefix=
- [31]
-
[33]
The Llama 3 Herd of Models , author=. arXiv preprint arXiv:2407.21783 , year=. doi:10.48550/arXiv.2407.21783 , url=. 2407.21783 , archivePrefix=
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2407.21783
-
[35]
Toolformer: Language Models Can Teach Themselves to Use Tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dess \`i , Roberta Raileanu, Maria Lomeli, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. arXiv preprint arXiv:2302.04761, 2023. doi:10.48550/arXiv.2302.04761. URL https://arxiv.org/abs/2302.04761
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.04761 2023
-
[36]
ReAct: Synergizing Reasoning and Acting in Language Models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629, 2022. URL https://arxiv.org/abs/2210.03629
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[37]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, Ahmed Hassan Awadallah, Ryen W White, Doug Burger, and Chi Wang. Autogen: Enabling next-gen llm applications via multi-agent conversation. arXiv preprint arXiv:2308.08155, 2023. URL https://arxiv.org/abs/2308.08155
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[38]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. Webarena: A realistic web environment for building autonomous agents. arXiv preprint arXiv:2307.13854, 2023. URL https://arxiv.org/abs/2307.13854
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[39]
Joon Sung Park, Joseph O'Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S. Bernstein. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th Annual ACM Symposium on User Interface Software and Technology, pages 1--22. ACM, 2023. doi:10.1145/3586183.3606763. URL https://doi.org/10.1145/3586183.3606763
-
[40]
MemGPT: Towards LLMs as Operating Systems
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems. arXiv preprint arXiv:2310.08560, 2023. URL https://arxiv.org/abs/2310.08560
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[41]
Memorybank: Enhancing large language models with long-term memory
Wanjun Zhong, Lianghong Guo, Qiqi Gao, He Ye, and Yanlin Wang. Memorybank: Enhancing large language models with long-term memory. arXiv preprint arXiv:2305.10250, 2023. doi:10.48550/arXiv.2305.10250. URL https://arxiv.org/abs/2305.10250
-
[42]
A-MEM: Agentic Memory for LLM Agents
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents. arXiv preprint arXiv:2502.12110, 2025. URL https://arxiv.org/abs/2502.12110
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Zhiyu Li, Shichao Song, Hanyu Wang, Simin Niu, Ding Chen, Jiawei Yang, Chenyang Xi, Huayi Lai, Jihao Zhao, Yezhaohui Wang, Junpeng Ren, Zehao Lin, Jiahao Huo, Tianyi Chen, Kai Chen, Kehang Li, Zhiqiang Yin, Qingchen Yu, Bo Tang, Hongkang Yang, Zhi-Qin John Xu, and Feiyu Xiong. Memos: An operating system for memory-augmented generation (mag) in large langu...
-
[44]
Jizhan Fang, Xinle Deng, Haoming Xu, Ziyan Jiang, Yuqi Tang, Ziwen Xu, Shumin Deng, Yunzhi Yao, Mengru Wang, Shuofei Qiao, Huajun Chen, and Ningyu Zhang. Lightmem: Lightweight and efficient memory-augmented generation. arXiv preprint arXiv:2510.18866, 2025. URL https://arxiv.org/abs/2510.18866
-
[45]
Hipporag: Neurobiologically inspired long-term memory for large language models,
Bernal Jim \'e nez Guti \'e rrez, Yiheng Shu, Yu Gu, Michihiro Yasunaga, and Yu Su. Hipporag: Neurobiologically inspired long-term memory for large language models. arXiv preprint arXiv:2405.14831, 2024. URL https://arxiv.org/abs/2405.14831
-
[46]
arXiv preprint arXiv:2511.01448 , year=
Zhengjun Huang, Zhoujin Tian, Qintian Guo, Fangyuan Zhang, Yingli Zhou, Di Jiang, Zeying Xie, and Xiaofang Zhou. Licomemory: Lightweight and cognitive agentic memory for efficient long-term reasoning. arXiv preprint arXiv:2511.01448, 2025. URL https://arxiv.org/abs/2511.01448
-
[47]
LongMemEval: Benchmarking Chat Assistants on Long-Term Interactive Memory
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Longmemeval: Benchmarking chat assistants on long-term interactive memory. arXiv preprint arXiv:2410.10813, 2024. URL https://arxiv.org/abs/2410.10813
work page internal anchor Pith review arXiv 2024
-
[48]
Evaluating Very Long-Term Conversational Memory of LLM Agents
Adyasha Maharana, Dong-Ho Lee, Sergey Tulyakov, Mohit Bansal, Francesco Barbieri, and Yuwei Fang. Evaluating very long-term conversational memory of llm agents. arXiv preprint arXiv:2402.17753, 2024. URL https://arxiv.org/abs/2402.17753
work page internal anchor Pith review arXiv 2024
-
[49]
Zexue He, Yu Wang, Churan Zhi, Yuanzhe Hu, Tzu-Ping Chen, Lang Yin, Ze Chen, Tong Arthur Wu, Siru Ouyang, Zihan Wang, Jiaxin Pei, Julian McAuley, Yejin Choi, and Alex Pentland. Memoryarena: Benchmarking agent memory in interdependent multi-session agentic tasks. arXiv preprint arXiv:2602.16313, 2026. URL https://arxiv.org/abs/2602.16313
-
[50]
Memory in the Age of AI Agents
Yuyang Hu, Shichun Liu, Yanwei Yue, Guibin Zhang, Boyang Liu, Fangyi Zhu, Jiahang Lin, Honglin Guo, Shihan Dou, Zhiheng Xi, Senjie Jin, Jiejun Tan, Yanbin Yin, Jiongnan Liu, Zeyu Zhang, Zhongxiang Sun, Yutao Zhu, Hao Sun, Boci Peng, Zhenrong Cheng, Xuanbo Fan, Jiaxin Guo, Xinlei Yu, Zhenhong Zhou, Zewen Hu, Jiahao Huo, Junhao Wang, Yuwei Niu, Yu Wang, Zhe...
work page internal anchor Pith review arXiv 2025
-
[51]
Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang
Nelson F. Liu, Kevin Lin, John Hewitt, Ashwin Paranjape, Michele Bevilacqua, Fabio Petroni, and Percy Liang. Lost in the middle: How language models use long contexts. Transactions of the Association for Computational Linguistics, 12: 0 157--173, 2024. doi:10.1162/tacl_a_00638. URL https://doi.org/10.1162/tacl_a_00638
-
[52]
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, Yuxiao Dong, Jie Tang, and Juanzi Li. Longbench: A bilingual, multitask benchmark for long context understanding. In Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages...
-
[53]
RULER: What's the Real Context Size of Your Long-Context Language Models?
Cheng-Ping Hsieh, Simeng Sun, Samuel Kriman, Shantanu Acharya, Dima Rekesh, Fei Jia, Yang Zhang, and Boris Ginsburg. Ruler: What's the real context size of your long-context language models? arXiv preprint arXiv:2404.06654, 2024. doi:10.48550/arXiv.2404.06654. URL https://arxiv.org/abs/2404.06654
work page internal anchor Pith review doi:10.48550/arxiv.2404.06654 2024
-
[54]
Yuanzhe Hu, Yu Wang, and Julian McAuley. Evaluating memory in llm agents via incremental multi-turn interactions, 2026. URL https://arxiv.org/abs/2507.05257
-
[55]
arXiv preprint arXiv:2602.19320 , year=
Dongming Jiang, Yi Li, Songtao Wei, Jinxin Yang, Ayushi Kishore, Alysa Zhao, Dingyi Kang, Xu Hu, Feng Chen, Qiannan Li, and Bingzhe Li. Anatomy of agentic memory: Taxonomy and empirical analysis of evaluation and system limitations. arXiv preprint arXiv:2602.19320, 2026. URL https://arxiv.org/abs/2602.19320
-
[56]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, Chujie Zheng, Dayiheng Liu, Fan Zhou, Fei Huang, Feng Hu, Hao Ge, Haoran Wei, Huan Lin, Jialong Tang, Jian Yang, Jianhong Tu, Jianwei Zhang, Jianxin Yang, Jiaxi Yang, Jing Zhou, Jingren Zhou, Junyang Lin, Kai Dang, Keqin Bao, Kexin Yang, ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388 2025
-
[57]
gpt-oss-120b & gpt-oss-20b Model Card
OpenAI , Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K. Arora, Yu Bai, Bowen Baker, Haiming Bao, Boaz Barak, Ally Bennett, Tyler Bertao, Nivedita Brett, Eugene Brevdo, Greg Brockman, Sebastien Bubeck, Che Chang, Kai Chen, et al. gpt-oss-120b & gpt-oss-20b model card. arXiv preprint arXiv:2508.10925, 2025. doi:10....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2508.10925 2025
-
[58]
OpenClaw . Memory overview. https://docs.openclaw.ai/concepts/memory, 2026. Accessed: 2026-05-05
work page 2026
-
[59]
Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory
Prateek Chhikara, Dev Khant, Saket Aryan, Taranjeet Singh, and Deshraj Yadav. Mem0: Building production-ready ai agents with scalable long-term memory. arXiv preprint arXiv:2504.19413, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.