Recognition: no theorem link
CSR: Infinite-Horizon Real-Time Policies with Massive Cached State Representations
Pith reviewed 2026-05-11 00:51 UTC · model grok-4.3
The pith
The CSR framework lets massive LLMs act as real-time embodied policies by keeping full state histories in cache without recomputation costs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
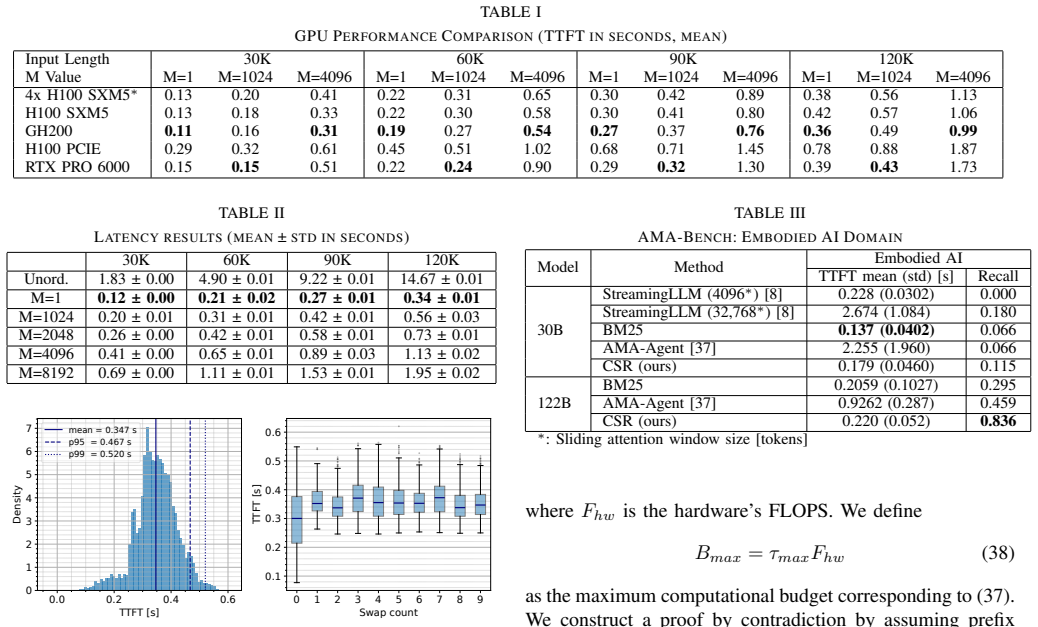
The paper claims that the optimal task structure for minimizing latency requires prefix stability, incremental extensibility, and asynchronous state reconciliation as necessary conditions. The Cached State Representation framework instantiates these to ensure optimal KV-cache reuse, and the Asynchronous State Reconciliation algorithm sustains them over infinite horizons by offloading eviction, resulting in a 26-fold TTFT reduction for 120K token contexts with a 235B model and SOTA performance on embodied benchmarks.
What carries the argument
The Cached State Representation (CSR) that enforces the three necessary properties of prefix stability, incremental extensibility, and asynchronous state reconciliation to achieve optimal key-value cache reuse.
If this is right
- LLM-based robot policies can achieve over 2 Hz operation frequency.
- Processing 120K token contexts takes only 0.56 seconds instead of 14.67 seconds.
- Recall on embodied AI tasks reaches 0.836 compared to 0.459 with baselines.
- Time-to-first-token stays bounded without spikes across repeated state evictions.
Where Pith is reading between the lines
- These cache management techniques could generalize to other domains requiring continuous context, such as autonomous driving or real-time language interfaces.
- Integrating CSR with hardware-specific optimizations might yield further latency improvements.
- Validating the properties in simulation before physical deployment could reduce development risks for new robotic applications.
Load-bearing premise
The load-bearing premise is that the three properties are both necessary and sufficient for optimal KV-cache reuse over infinite horizons and that offloading eviction via ASR introduces no context loss or new bottlenecks in practice.
What would settle it
Running the robot system through more than ten eviction cycles while monitoring for any increase in TTFT or drop in recall would test if the bounded performance holds; a single spike or accuracy loss would falsify the claim of sustained real-time operation.
Figures






read the original abstract
Deploying massive large language models (LLMs) as continuous cognitive engines for robotics is bottlenecked by the time-to-first-token (TTFT) latency required to process extensive state histories. Existing solutions like RAG or sliding windows compromise global context or incur prohibitive re-computation costs. We formalize the optimal task structure for minimizing latency and theoretically prove that prefix stability, incremental extensibility, and asynchronous state reconciliation are necessary conditions for real-time performance. Building on these proofs, we introduce the Cached State Representation (CSR) framework as the practical instantiation of these properties, ensuring optimal KV-cache reuse. To sustain these properties over infinite horizons, we further propose an Asynchronous State Reconciliation (ASR) algorithm that offloads state memory eviction to a parallel computational resource to eliminate latency spikes. On a physical robot wirelessly connected to an on-premise GPU server, CSR achieves a 26-fold latency reduction (14.67s to 0.56s) for 120K token contexts with a 235B parameter model compared to a standard baseline. On an embodied AI benchmark, we achieve SOTA recall (0.836 vs. 0.459) while maintaining RAG-level latency. ASR is validated to sustain bounded, spike-free TTFT over 10 eviction cycles in continuous real-world operation. Together, CSR and ASR enable massive LLMs to function as continuously operating, high-frequency (> 2 Hz) embodied policies.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that prefix stability, incremental extensibility, and asynchronous state reconciliation are necessary conditions for real-time LLM-based robotic policies, instantiated via the CSR framework for optimal KV-cache reuse and the ASR algorithm to offload eviction. It reports a 26-fold TTFT reduction (14.67s to 0.56s) for 120K-token contexts with a 235B model on a physical robot, SOTA recall (0.836 vs. 0.459) on an embodied AI benchmark at RAG-level latency, and bounded spike-free TTFT sustained over 10 eviction cycles, enabling >2 Hz continuous operation.
Significance. If the theoretical conditions and empirical results generalize, the work would enable massive LLMs to serve as high-frequency embodied cognitive engines with full context retention, a notable advance for real-time robotics; the physical robot experiment and concrete latency/recall numbers provide a concrete demonstration of practical impact.
major comments (2)
- [Abstract] Abstract: ASR validation is reported over only 10 eviction cycles; this is insufficient to support the infinite-horizon claim of bounded, spike-free TTFT, as accumulation of reconciliation overhead, partial context loss on the wireless link, or rare spikes may not manifest in such a short test.
- [Abstract] Abstract: The theoretical proof that the three properties are necessary (and implicitly sufficient) for optimal KV-cache reuse indefinitely is asserted without any derivation, equations, or proof sketch, leaving the central claim that CSR+ASR maintains these properties over infinite horizons unverifiable from the provided text.
minor comments (2)
- [Abstract] Abstract: The 'standard baseline' for the 26-fold latency comparison is not specified (e.g., full recomputation vs. sliding window), hindering direct assessment of the improvement.
- [Abstract] Abstract: Details of the embodied AI benchmark (tasks, dataset size, evaluation protocol) are omitted, limiting evaluation of the SOTA recall claim.
Simulated Author's Rebuttal
We thank the referee for the constructive comments, which help strengthen the presentation of our theoretical claims and empirical validation. We address each major comment below and will incorporate revisions to improve verifiability and support for the infinite-horizon assertions.
read point-by-point responses
-
Referee: [Abstract] Abstract: ASR validation is reported over only 10 eviction cycles; this is insufficient to support the infinite-horizon claim of bounded, spike-free TTFT, as accumulation of reconciliation overhead, partial context loss on the wireless link, or rare spikes may not manifest in such a short test.
Authors: We agree that validation over only 10 cycles is insufficient to fully substantiate the infinite-horizon claim, as rare events or gradual accumulation could emerge later. The ASR design offloads eviction to a background process precisely to bound overhead and eliminate spikes, with the 10-cycle test showing no degradation in the physical setup. In the revised manuscript we will extend the continuous-operation experiment to 100+ cycles, add explicit monitoring for reconciliation overhead and wireless packet loss, and include a short theoretical argument bounding the per-cycle cost under the prefix-stability property. revision: yes
-
Referee: [Abstract] Abstract: The theoretical proof that the three properties are necessary (and implicitly sufficient) for optimal KV-cache reuse indefinitely is asserted without any derivation, equations, or proof sketch, leaving the central claim that CSR+ASR maintains these properties over infinite horizons unverifiable from the provided text.
Authors: We acknowledge that the abstract and early sections present the necessity claim without a visible derivation or equations, making it difficult to verify. The full manuscript contains a formalization of the optimal task structure in Section 3 that proves prefix stability, incremental extensibility, and asynchronous state reconciliation are necessary for unbounded KV-cache reuse; however, the proof sketch is not sufficiently highlighted. In the revision we will insert a concise proof outline (with the key equations) into the abstract/introduction and expand the relevant section so the necessity argument is self-contained and directly verifiable. revision: yes
Circularity Check
No circularity: derivation relies on independent theoretical proofs and external empirical benchmarks
full rationale
The paper asserts theoretical proofs that prefix stability, incremental extensibility, and asynchronous state reconciliation are necessary for real-time performance, then instantiates them via CSR and ASR. These steps are presented as first-principles formalization followed by engineering implementation and physical-robot validation (26x latency reduction, SOTA recall, 10-cycle ASR test). No equations, fitted parameters, or self-citations are shown to reduce any claim to its own inputs by construction. The infinite-horizon framing is supported by the stated properties rather than being definitionally equivalent to the 10-cycle test or any internal fit. This is a standard non-circular engineering paper.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Prefix stability, incremental extensibility, and asynchronous state reconciliation are necessary conditions for real-time performance with massive LLMs
invented entities (2)
-
Cached State Representation (CSR)
no independent evidence
-
Asynchronous State Reconciliation (ASR)
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances,
M. Ahnet al., “Do As I Can, Not As I Say: Grounding Language in Robotic Affordances,” inCoRL, 2022
2022
-
[2]
Inner Monologue: Embodied Reasoning through Planning with Language Models,
W. Huang,et al., “Inner Monologue: Embodied Reasoning through Planning with Language Models,” inCoRL, 2022
2022
-
[3]
Code as Policies: Language Model Programs for Embodied Control,
J. Liang,et al., “Code as Policies: Language Model Programs for Embodied Control,” inICRA, 2023
2023
-
[4]
PaLM-E: An Embodied Multimodal Language Model,
D. Driess,et al., “PaLM-E: An Embodied Multimodal Language Model,” inICML, 2023
2023
-
[5]
Voyager: An Open-Ended Embodied Agent with Large Language Models
G. Wang,et al., “Voyager: An Open-Ended Embodied Agent with Large Language Models,”arXiv:2305.16291, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[6]
RT-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovichet al., “RT-2: Vision-language-action models transfer web knowledge to robotic control,” inCoRL, 2023
2023
-
[7]
MemGPT: Towards LLMs as Operating Systems,
C. Packer,et al., “MemGPT: Towards LLMs as Operating Systems,” inICML, 2024
2024
-
[8]
Efficient Streaming Language Models with Attention Sinks,
G. Xiao,et al., “Efficient Streaming Language Models with Attention Sinks,” inICLR, 2024
2024
-
[9]
CacheGen: KV Cache Compression and Streaming for Fast Context Switching in LLM Serving,
Y . Liu,et al., “CacheGen: KV Cache Compression and Streaming for Fast Context Switching in LLM Serving,” inSIGCOMM, 2024
2024
-
[10]
Octo: An Open-Source Generalist Robot Policy,
Octo Model Team,et al., “Octo: An Open-Source Generalist Robot Policy,” inRSS, 2024
2024
-
[11]
OpenVLA: An Open-Source Vision-Language- Action Model,
M. J. Kim,et al., “OpenVLA: An Open-Source Vision-Language- Action Model,” inCoRL, 2024
2024
-
[12]
Efficient Memory Management for Large Language Model Serving with PagedAttention,
W. Kwon,et al., “Efficient Memory Management for Large Language Model Serving with PagedAttention,” inSOSP, 2023
2023
-
[13]
Prompt Cache: Modular Attention Reuse for Low- Latency Inference,
I. Gim,et al., “Prompt Cache: Modular Attention Reuse for Low- Latency Inference,” inMLSys, 2024
2024
-
[14]
Augmenting Language Models with Long-Term Memory,
W. Wang,et al., “Augmenting Language Models with Long-Term Memory,” inNeurIPS, 2023
2023
-
[15]
Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi- Task Agents,
Z. Wang,et al., “Describe, Explain, Plan and Select: Interactive Planning with Large Language Models Enables Open-World Multi- Task Agents,” inNeurIPS, 2023
2023
-
[16]
ReAct: Synergizing Reasoning and Acting in Language Models,
S. Yao,et al., “ReAct: Synergizing Reasoning and Acting in Language Models,” inICLR, 2023
2023
-
[17]
Reflexion: Language Agents with Verbal Reinforce- ment Learning,
N. Shinn,et al., “Reflexion: Language Agents with Verbal Reinforce- ment Learning,” inNeurIPS, 2023
2023
-
[18]
SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning,
K. Rana,et al., “SayPlan: Grounding Large Language Models using 3D Scene Graphs for Scalable Robot Task Planning,” inCoRL, 2023
2023
-
[19]
Do Embodied Agents Dream of Pixelated Sheep?: Embodied Decision Making using Language Guided World Modelling,
K. Nottingham,et al., “Do Embodied Agents Dream of Pixelated Sheep?: Embodied Decision Making using Language Guided World Modelling,” inICML, 2023
2023
-
[20]
LLM+P: Empowering Large Language Models with Optimal Planning Proficiency
B. Liu,et al., “LLM+P: Empowering Large Language Models with Optimal Planning Proficiency,”arXiv:2304.11477, 2023
work page internal anchor Pith review arXiv 2023
-
[21]
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language,
A. Zeng,et al., “Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language,” inICLR, 2023
2023
-
[22]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models,
Open X-Embodiment Collaboration,et al., “Open X-Embodiment: Robotic Learning Datasets and RT-X Models,” inICRA, 2024
2024
-
[23]
Large Language Models Are Semi-Parametric Reinforcement Learning Agents,
D. Zhang,et al., “Large Language Models Are Semi-Parametric Reinforcement Learning Agents,” inNeurIPS, 2023
2023
-
[24]
EUREKA: Human-Level Reward Design via Coding Large Language Models,
Y . J. Ma,et al., “EUREKA: Human-Level Reward Design via Coding Large Language Models,” inICLR, 2024
2024
-
[25]
DrEureka: Language Model Guided Sim-To-Real Transfer,
Y . J. Ma,et al., “DrEureka: Language Model Guided Sim-To-Real Transfer,” inRSS, 2024
2024
-
[26]
ProgPrompt: Generating Situated Robot Task Plans using Large Language Models,
I. Singh,et al., “ProgPrompt: Generating Situated Robot Task Plans using Large Language Models,” inICRA, 2023
2023
-
[27]
RoCo: Dialectic Multi-Robot Col- laboration with Large Language Models,
Z. Mandi, S. Jain, and S. Song, “RoCo: Dialectic Multi-Robot Col- laboration with Large Language Models,” inICRA, 2024
2024
-
[28]
ConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning,
Q. Gu,et al., “ConceptGraphs: Open-Vocabulary 3D Scene Graphs for Perception and Planning,” inRSS, 2024
2024
-
[29]
LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action,
D. Shah,et al., “LM-Nav: Robotic Navigation with Large Pre-Trained Models of Language, Vision, and Action,” inCoRL, 2022
2022
-
[30]
Visual Language Maps for Robot Navigation,
C. Huang,et al., “Visual Language Maps for Robot Navigation,” in ICRA, 2023
2023
-
[31]
Spatialvlm: Endowing vision-language models with spatial reasoning capabilities,
B. Chen,et al., “Spatialvlm: Endowing vision-language models with spatial reasoning capabilities,” inCVPR, 2024
2024
-
[32]
Keypoint action tokens enable in-context imitation learning in robotics,
P. Mariano, N. Di Palo, and E. Johns, “Keypoint action tokens enable in-context imitation learning in robotics,” inRSS, 2024
2024
-
[33]
V oxposer: Composable 3d value maps for robotic manipulation with language models,
W. Huang,et al., “V oxposer: Composable 3d value maps for robotic manipulation with language models,” inCoRL, 2023
2023
-
[34]
Memento: Fine-tuning LLM agents without fine- tuning LLMs,
C. Wanget al., “Memento: Fine-tuning LLM agents without fine- tuning LLMs,” inICLR, 2025
2025
-
[35]
‘ Adaptive (Template-Aware) [24] Note for the evaluator: per the
W. Zhou,et al., “RecurrentGPT: Interactive Generation of (Arbitrarily) Long Text,”arXiv:2305.13304, 2023
-
[36]
Generative Agents: Interactive Simulacra of Human Behavior,
J. S. Park,et al., “Generative Agents: Interactive Simulacra of Human Behavior,” inUIST, 2023
2023
-
[37]
Ama-bench: Evaluating long-horizon memory for agentic applications, 2026
Y . Zhao,et al., “AMA-Bench: Evaluating Long-Horizon Memory for Agentic Applications,”arXiv:2602.22769, 2026
-
[38]
GPTQ: Accurate Post-Ttraining Quantization for Generative Pre-trained Transformers,
E. Frantar,et al., “GPTQ: Accurate Post-Ttraining Quantization for Generative Pre-trained Transformers,” inICLR, 2023
2023
-
[39]
AWQ: Activation-aware Weight Quantization for On- Device LLM Compression and Acceleration,
J. Lin,et al., “AWQ: Activation-aware Weight Quantization for On- Device LLM Compression and Acceleration,” inMLSys, 2024
2024
-
[40]
BitNet: 1-bit Pre-training for Large Language Models,
H. Wang,et al., “BitNet: 1-bit Pre-training for Large Language Models,”JMLR, 2025
2025
-
[41]
Fast Inference from Transformers via Speculative Decoding,
Y . Leviathan, M. Kalman, and Y . Matias, “Fast Inference from Transformers via Speculative Decoding,” inICML, 2023
2023
-
[42]
Medusa: Simple LLM Inference Acceleration Frame- work with Multiple Decoding Heads,
T. Cai,et al., “Medusa: Simple LLM Inference Acceleration Frame- work with Multiple Decoding Heads,” inICML, 2024
2024
-
[43]
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning,
T. Dao, “FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning,” inICLR, 2024
2024
-
[44]
Ring Attention with Blockwise Transformers for Nearly Infinite Context,
H. Liu and P. Abbeel, “Ring Attention with Blockwise Transformers for Nearly Infinite Context,” inICLR, 2024
2024
-
[45]
Orca: A Distributed Serving System for Low-Latency Large Language Model Inference,
G.-I. Yu,et al., “Orca: A Distributed Serving System for Low-Latency Large Language Model Inference,” inOSDI, 2022
2022
-
[46]
Efficiently Programming Large Language Models in SGlang,
L. Zheng,et al., “Efficiently Programming Large Language Models in SGlang,” inASPLOS, 2024
2024
-
[47]
ChunkAttention: Efficient Self-Attention with Arbi- trary Granularity,
T. Pham,et al., “ChunkAttention: Efficient Self-Attention with Arbi- trary Granularity,”arXiv:2402.11131, 2024
-
[48]
Research and development project of the enhanced infrastruc- tures for post-5g information and communication systems,
NEDO, “Research and development project of the enhanced infrastruc- tures for post-5g information and communication systems,” https:// www.nedo.go.jp/english/activities/activities ZZJP 100172.html, 2024, accessed: 2026-04-07
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.