Recognition: 2 theorem links
· Lean TheoremGEM: Generating LiDAR World Model via Deformable Mamba
Pith reviewed 2026-05-11 01:28 UTC · model grok-4.3
The pith
GEM generates realistic future LiDAR observations by tokenizing point clouds, separating dynamic from static elements, and processing them with a tri-path deformable Mamba.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
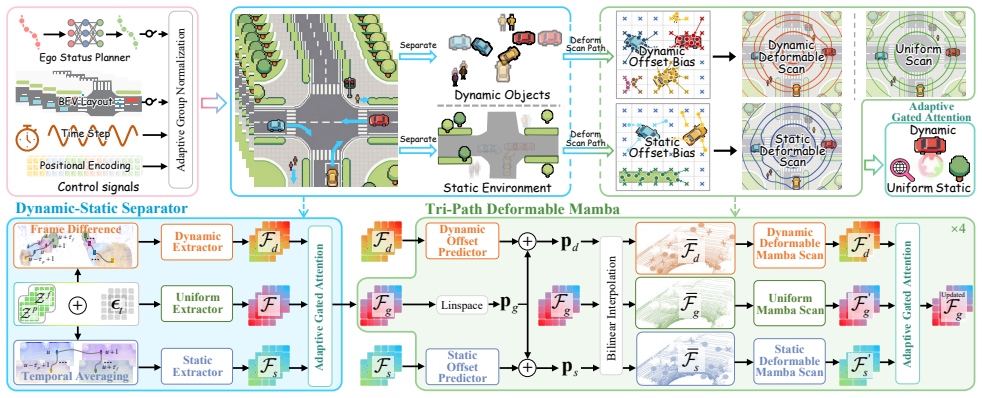
GEM first tokenizes LiDAR sweeps via a custom scene tokenizer, applies unsupervised dynamic-static separation on the tokens, and feeds the disentangled features into a tri-path deformable Mamba that conducts selective scanning and adaptive gating fusion, thereby improving spatial-temporal modeling of world evolution and enabling high-fidelity future LiDAR generation.
What carries the argument
The tri-path deformable Mamba, which adaptively scans and fuses disentangled dynamic-static features from tokenized LiDAR sweeps to model environmental change.
If this is right
- Adding a planner lets the model perform autonomous rollout of driving trajectories in simulated worlds.
- A BEV layout controller allows generation of alternative what-if scenarios by altering scene layouts.
- The architecture produces state-of-the-art performance across diverse LiDAR benchmarks and evaluation protocols.
- The unsupervised separation step supports clearer distinction between moving objects and static background in generated outputs.
Where Pith is reading between the lines
- The same tokenization and scanning approach might transfer to other sequential range sensors such as radar if their scan patterns exhibit comparable ordering.
- Generated worlds could serve as training data for perception modules when real LiDAR captures of rare events are scarce.
- Closed-loop testing of the model inside full driving simulators would reveal whether the improved forecasts translate to safer planning decisions.
Load-bearing premise
That sequential laser scanning shares enough structural similarity with Mamba's selective processing to support effective tokenization and scanning of LiDAR data.
What would settle it
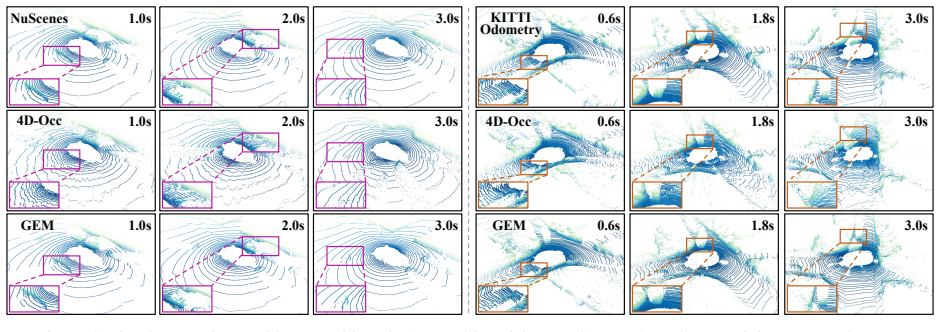
An ablation study in which removing the dynamic-static separator or the deformable scanning paths causes the model's LiDAR generation quality to fall to or below that of standard transformer or Mamba baselines on metrics such as Chamfer distance for predicted sweeps.
Figures




read the original abstract
World models, which simulate environmental dynamics and generate sensor observations, are gaining increasing attention in autonomous driving. However, progress in LiDAR-based world models has lagged behind those built on camera videos or occupancy data, primarily due to two core challenges: the inherent disorder of LiDAR point clouds and the difficulty of distinguishing dynamic objects from static structures. To address these issues, we propose GEM: a Generative LiDAR world model that leverages deformable mamba architecture, significantly improving fidelity and imaginative capability. Specifically, leveraging the structural similarity between sequential laser scanning and Mamba's processing mechanism, we first tokenize LiDAR sweeps into compact representations via a custom LiDAR scene tokenizer. After unsupervised disentanglement of tokenized features via a dynamic-static separator, a tri-path deformable Mamba is introduced to perform selective scanning and adaptive gating fusion over the disentangled features, leading to enhanced spatial-temporal understanding of the world evolution. Optionally, a planner and a BEV layout controller can be integrated to explore the model's capability for autonomous rollout and its potential to generate ``what-if" scenarios. Extensive experiments show that GEM achieves state-of-the-art performances across diverse benchmarks and evaluation settings, demonstrating its superiority and effectiveness. Project page: https://github.com/wuyang98/GEM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes GEM, a generative LiDAR world model for autonomous driving that addresses point-cloud disorder and dynamic/static separation. It introduces a custom LiDAR scene tokenizer, an unsupervised dynamic-static feature separator, and a tri-path deformable Mamba module that performs selective scanning and adaptive gating fusion on disentangled features. The architecture optionally incorporates a planner and BEV layout controller for rollout and counterfactual generation. The central claim is that this design yields state-of-the-art performance across diverse benchmarks and evaluation settings by exploiting the structural similarity between sequential laser scanning and Mamba's selective mechanism.
Significance. If the reported results hold under rigorous verification, GEM would represent a meaningful advance for LiDAR-based world models, which have trailed camera-video and occupancy approaches. The unsupervised disentanglement and deformable Mamba components directly target the stated challenges of unstructured point clouds and temporal evolution, offering a parameter-efficient alternative to transformer-based generative models. The optional planner integration further demonstrates practical utility for closed-loop simulation.
minor comments (3)
- [Abstract] The abstract states that GEM achieves SOTA 'across diverse benchmarks' but does not name the specific datasets or metrics; the experiments section should include a clear table listing all evaluated benchmarks, baselines, and quantitative improvements with standard deviations.
- Reproducibility would be strengthened by releasing the full training code, tokenizer weights, and exact hyperparameter configurations referenced in the project page, along with ablation studies isolating the contribution of the tri-path deformable Mamba versus standard Mamba.
- Notation for the dynamic-static separator (e.g., the unsupervised loss terms) should be defined explicitly in the methods section with a diagram showing the feature flow before and after disentanglement.
Simulated Author's Rebuttal
We thank the referee for the positive review and recommendation for minor revision. We are encouraged by the recognition of GEM's contributions in addressing LiDAR point-cloud disorder and dynamic-static separation through the custom tokenizer, unsupervised separator, and tri-path deformable Mamba. Since the report contains no specific major comments requiring point-by-point rebuttal, we will proceed with minor revisions to enhance clarity, presentation, and any potential ambiguities in the manuscript.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes GEM as a new architecture motivated by an observed structural similarity between sequential LiDAR scanning and Mamba's selective mechanism. It introduces a custom tokenizer, unsupervised dynamic-static separator, and tri-path deformable Mamba to address point-cloud disorder and dynamic/static separation. These are presented as design choices whose effectiveness is validated through experiments on diverse benchmarks, not by any equation that reduces a prediction to a fitted input by construction, nor by self-citation chains, uniqueness theorems imported from prior work, or renaming of known results. The optional planner/BEV controller is an extension, not core to the SOTA claim. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Mamba architecture can be adapted for LiDAR point cloud sequences via tokenization
invented entities (1)
-
Deformable Mamba
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and embed_strictMono_of_one_lt unclearleveraging the structural similarity between sequential laser scanning and Mamba’s processing mechanism, we first tokenize LiDAR sweeps into compact representations via a custom LiDAR scene tokenizer. After unsupervised disentanglement of tokenized features via a dynamic-static separator, a tri-path deformable Mamba is introduced to perform selective scanning and adaptive gating fusion
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (D=3) uncleartri-path deformable Mamba that adaptively generates specialized scan paths {p_g, p_d, p_s} for each branch
Reference graph
Works this paper leans on
-
[1]
Cosmos-transfer1: Conditional world generation with adaptive multimodal control, 2025
Hassan Abu Alhaija, Jose Alvarez, Maciej Bala, Tiffany Cai, Tianshi Cao, Liz Cha, Joshua Chen, Mike Chen, Francesco Ferroni, Sanja Fidler, et al. Cosmos-transfer1: Conditional world generation with adaptive multimodal control.arXiv preprint arXiv:2503.14492, 2025. 1
-
[2]
Seeing through fog without seeing fog: Deep multimodal sensor fusion in unseen adverse weather
Mario Bijelic, Tobias Gruber, Fahim Mannan, Florian Kraus, Werner Ritter, Klaus Dietmayer, and Felix Heide. Seeing through fog without seeing fog: Deep multimodal sensor fusion in unseen adverse weather. InCVPR, pages 11682– 11692, 2020. 2
work page 2020
-
[3]
nuscenes: A mul- timodal dataset for autonomous driving
Holger Caesar, Varun Bankiti, Alex H Lang, Sourabh V ora, Venice Erin Liong, Qiang Xu, Anush Krishnan, Yu Pan, Giancarlo Baldan, and Oscar Beijbom. nuscenes: A mul- timodal dataset for autonomous driving. InCVPR, pages 11621–11631, 2020. 2, 6, 7
work page 2020
-
[4]
4d spatio-temporal convnets: Minkowski convolutional neural networks
Christopher Choy, JunYoung Gwak, and Silvio Savarese. 4d spatio-temporal convnets: Minkowski convolutional neural networks. InCVPR, pages 3075–3084, 2019. 6
work page 2019
-
[5]
Diffusion mod- els beat gans on image synthesis.NeurIPS, 34:8780–8794,
Prafulla Dhariwal and Alexander Nichol. Diffusion mod- els beat gans on image synthesis.NeurIPS, 34:8780–8794,
-
[6]
Carla: An open urban driving simulator
Alexey Dosovitskiy, German Ros, Felipe Codevilla, Antonio Lopez, and Vladlen Koltun. Carla: An open urban driving simulator. InCoRL, pages 1–16. PMLR, 2017. 2
work page 2017
-
[7]
Are we ready for autonomous driving? the kitti vision benchmark suite
Andreas Geiger, Philip Lenz, and Raquel Urtasun. Are we ready for autonomous driving? the kitti vision benchmark suite. InCVPR, pages 3354–3361. IEEE, 2012. 2, 6
work page 2012
-
[8]
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
Albert Gu and Tri Dao. Mamba: Linear-time sequence modeling with selective state spaces.arXiv preprint arXiv:2312.00752, 2023. 2, 3, 5
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Dome: Taming diffusion model into high-fidelity controllable occu- pancy world model,
Songen Gu, Wei Yin, Bu Jin, Xiaoyang Guo, Junming Wang, Haodong Li, Qian Zhang, and Xiaoxiao Long. Dome: Tam- ing diffusion model into high-fidelity controllable occupancy world model.arXiv preprint arXiv:2410.10429, 2024. 2, 3, 5
-
[10]
Fog simulation on real lidar point clouds for 3d object detection in adverse weather
Martin Hahner, Christos Sakaridis, Dengxin Dai, and Luc Van Gool. Fog simulation on real lidar point clouds for 3d object detection in adverse weather. InICCV, pages 15283– 15292, 2021. 2
work page 2021
-
[11]
Lidar snowfall simulation for robust 3d object detection
Martin Hahner, Christos Sakaridis, Mario Bijelic, Felix Heide, Fisher Yu, Dengxin Dai, and Luc Van Gool. Lidar snowfall simulation for robust 3d object detection. InCVPR, pages 16364–16374, 2022. 2
work page 2022
-
[12]
GAIA-1: A Generative World Model for Autonomous Driving
Anthony Hu, Lloyd Russell, Hudson Yeo, Zak Murez, George Fedoseev, Alex Kendall, Jamie Shotton, and Gian- luca Corrado. Gaia-1: A generative world model for au- tonomous driving.arXiv preprint arXiv:2309.17080, 2023. 2
work page internal anchor Pith review arXiv 2023
-
[13]
Point cloud forecasting as a proxy for 4d occupancy forecasting
Tarasha Khurana, Peiyun Hu, David Held, and Deva Ra- manan. Point cloud forecasting as a proxy for 4d occupancy forecasting. InCVPR, pages 1116–1124, 2023. 1, 2, 3, 6, 7
work page 2023
-
[14]
Velat Kilic, Deepti Hegde, A Brinton Cooper, Vishal M Pa- tel, and Mark Foster. Lidar light scattering augmentation (lisa): Physics-based simulation of adverse weather condi- tions for 3d object detection. InICASSP, pages 1–5. IEEE,
-
[15]
Adam: A method for stochastic optimization.ICLR, 2015
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.ICLR, 2015. 6
work page 2015
-
[16]
arXiv preprint arXiv:2509.07996 (2025)
Lingdong Kong, Wesley Yang, Jianbiao Mei, Youquan Liu, Ao Liang, Dekai Zhu, Dongyue Lu, Wei Yin, Xiaotao Hu, Mingkai Jia, et al. 3d and 4d world modeling: A survey. arXiv preprint arXiv:2509.07996, 2025. 1, 3
-
[17]
Yingyan Li, Yuqi Wang, Yang Liu, Jiawei He, Lue Fan, and Zhaoxiang Zhang. End-to-end driving with online tra- jectory evaluation via bev world model.arXiv preprint arXiv:2504.01941, 2025. 2
-
[18]
Zhiqi Li, Zhiding Yu, Shiyi Lan, Jiahan Li, Jan Kautz, Tong Lu, and Jose M Alvarez. Is ego status all you need for open-loop end-to-end autonomous driving? InCVPR, pages 14864–14873, 2024. 5
work page 2024
-
[19]
Learning to generate 4d lidar sequences.arXiv preprint arXiv:2509.11959, 2025
Ao Liang, Youquan Liu, Yu Yang, Dongyue Lu, Linfeng Li, Lingdong Kong, Huaici Zhao, and Wei Tsang Ooi. Learning to generate 4d lidar sequences.arXiv preprint arXiv:2509.11959, 2025. 1, 2
-
[20]
Lidar- crafter: Dynamic 4d world modeling from lidar sequences
Ao Liang, Youquan Liu, Yu Yang, Dongyue Lu, Linfeng Li, Lingdong Kong, Huaici Zhao, and Wei Tsang Ooi. Lidar- crafter: Dynamic 4d world modeling from lidar sequences. arXiv preprint arXiv:2508.03692, 2025. 2
-
[21]
Yiyi Liao, Jun Xie, and Andreas Geiger. Kitti-360: A novel dataset and benchmarks for urban scene understanding in 2d and 3d.TPAMI, 45(3):3292–3310, 2022. 6, 7
work page 2022
-
[22]
Defmamba: Deformable visual state space model
Leiye Liu, Miao Zhang, Jihao Yin, Tingwei Liu, Wei Ji, Yon- gri Piao, and Huchuan Lu. Defmamba: Deformable visual state space model. InCVPR, pages 8838–8847, 2025. 5
work page 2025
-
[23]
Point- voxel cnn for efficient 3d deep learning.NeurIPS, 32, 2019
Zhijian Liu, Haotian Tang, Yujun Lin, and Song Han. Point- voxel cnn for efficient 3d deep learning.NeurIPS, 32, 2019. 2
work page 2019
-
[24]
A survey: Learning embodied intelligence from physical simulators and world models,
Xiaoxiao Long, Qingrui Zhao, Kaiwen Zhang, Zihao Zhang, Dingrui Wang, Yumeng Liu, Zhengjie Shu, Yi Lu, Shouzheng Wang, Xinzhe Wei, et al. A survey: Learning embodied intelligence from physical simulators and world models.arXiv preprint arXiv:2507.00917, 2025. 3
-
[25]
Decoupled weight decay regularization.ICLR, 2018
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.ICLR, 2018. 6
work page 2018
-
[26]
V oxnet: A 3d con- volutional neural network for real-time object recognition
Daniel Maturana and Sebastian Scherer. V oxnet: A 3d con- volutional neural network for real-time object recognition. In IROS, pages 922–928. Ieee, 2015. 2
work page 2015
-
[27]
Self-supervised point cloud prediction using 3d spatio-temporal convolutional networks
Benedikt Mersch, Xieyuanli Chen, Jens Behley, and Cyrill Stachniss. Self-supervised point cloud prediction using 3d spatio-temporal convolutional networks. InCoRL, pages 1444–1454. PMLR, 2022. 6, 7
work page 2022
-
[28]
Rangenet++: Fast and accurate lidar semantic segmentation
Andres Milioto, Ignacio Vizzo, Jens Behley, and Cyrill Stachniss. Rangenet++: Fast and accurate lidar semantic segmentation. InIROS, pages 4213–4220. IEEE, 2019. 3, 6
work page 2019
-
[29]
Learning to drop points for lidar scan synthesis
Kazuto Nakashima and Ryo Kurazume. Learning to drop points for lidar scan synthesis. InIROS, pages 222–229. IEEE, 2021. 2
work page 2021
-
[30]
Kazuto Nakashima and Ryo Kurazume. Lidar data synthesis with denoising diffusion probabilistic models.arXiv preprint arXiv:2309.09256, 2023. 2, 7
-
[31]
Scalable diffusion models with transformers
William Peebles and Saining Xie. Scalable diffusion models with transformers. InICCV, pages 4195–4205, 2023. 5, 7
work page 2023
-
[32]
Pointnet: Deep learning on point sets for 3d classification and segmentation
Charles R Qi, Hao Su, Kaichun Mo, and Leonidas J Guibas. Pointnet: Deep learning on point sets for 3d classification and segmentation. InCVPR, pages 652–660, 2017. 2
work page 2017
-
[33]
Pointnet++: Deep hierarchical feature learning on point sets in a metric space.NeurIPS, 30, 2017
Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space.NeurIPS, 30, 2017. 2
work page 2017
-
[34]
Gated Attention for Large Language Models: Non-linearity, Sparsity, and Attention-Sink-Free
Zihan Qiu, Zekun Wang, Bo Zheng, Zeyu Huang, Kaiyue Wen, Songlin Yang, Rui Men, Le Yu, Fei Huang, Suozhi Huang, et al. Gated attention for large language mod- els: Non-linearity, sparsity, and attention-sink-free.arXiv preprint arXiv:2505.06708, 2025. 4
work page internal anchor Pith review arXiv 2025
-
[35]
Wentao Qu, Guofeng Mei, Jing Wang, Yujiao Wu, Xiaoshui Huang, and Liang Xiao. Robust single-stage fully sparse 3d object detection via detachable latent diffusion.arXiv preprint arXiv:2508.03252, 2025. 2
-
[36]
Wentao Qu, Guofeng Mei, Yang Wu, Yongshun Gong, Xi- aoshui Huang, and Liang Xiao. A self-conditioned represen- tation guided diffusion model for realistic text-to-lidar scene generation.arXiv preprint arXiv:2511.19004, 2025. 1
-
[37]
Towards realis- tic scene generation with lidar diffusion models
Haoxi Ran, Vitor Guizilini, and Yue Wang. Towards realis- tic scene generation with lidar diffusion models. InCVPR, pages 14738–14748, 2024. 2, 4, 6
work page 2024
-
[38]
High-resolution image syn- thesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image syn- thesis with latent diffusion models. InCVPR, pages 10684– 10695, 2022. 5
work page 2022
-
[39]
Chen Shi, Shaoshuai Shi, Kehua Sheng, Bo Zhang, and Li Jiang. Drivex: Omni scene modeling for learning generaliz- able world knowledge in autonomous driving.arXiv preprint arXiv:2505.19239, 2025. 2
-
[40]
Pillarnet: Real- time and high-performance pillar-based 3d object detection
Guangsheng Shi, Ruifeng Li, and Chao Ma. Pillarnet: Real- time and high-performance pillar-based 3d object detection. InECCV, pages 35–52. Springer, 2022. 2
work page 2022
-
[41]
Yining Shi, Kun Jiang, Qiang Meng, Ke Wang, Jiabao Wang, Wenchao Sun, Tuopu Wen, Mengmeng Yang, and Diange Yang. Come: Adding scene-centric forecasting control to occupancy world model.arXiv preprint arXiv:2506.13260,
-
[42]
Searching efficient 3d architec- tures with sparse point-voxel convolution
Haotian Tang, Zhijian Liu, Shengyu Zhao, Yujun Lin, Ji Lin, Hanrui Wang, and Song Han. Searching efficient 3d architec- tures with sparse point-voxel convolution. InECCV, pages 685–702. Springer, 2020. 6
work page 2020
-
[43]
Drivedreamer: Towards real-world- drive world models for autonomous driving
Xiaofeng Wang, Zheng Zhu, Guan Huang, Xinze Chen, Jia- gang Zhu, and Jiwen Lu. Drivedreamer: Towards real-world- drive world models for autonomous driving. InECCV, pages 55–72. Springer, 2024. 2
work page 2024
-
[44]
Yuqi Wang, Jiawei He, Lue Fan, Hongxin Li, Yuntao Chen, and Zhaoxiang Zhang. Driving into the future: Multiview visual forecasting and planning with world model for au- tonomous driving. InCVPR, pages 14749–14759, 2024. 2
work page 2024
-
[45]
Xinshuo Weng, Jianren Wang, Sergey Levine, Kris Kitani, and Nicholas Rhinehart. Inverting the pose forecasting pipeline with spf2: Sequential pointcloud forecasting for se- quential pose forecasting. InCoRL, pages 11–20. PMLR,
-
[46]
S2net: Stochastic sequential pointcloud forecasting
Xinshuo Weng, Junyu Nan, Kuan-Hui Lee, Rowan McAl- lister, Adrien Gaidon, Nicholas Rhinehart, and Kris M Ki- tani. S2net: Stochastic sequential pointcloud forecasting. In ECCV, pages 549–564. Springer, 2022. 1, 2, 6, 7
work page 2022
-
[47]
Co-salient object detection with uncertainty-aware group exchange-masking
Yang Wu, Huihui Song, Bo Liu, Kaihua Zhang, and Dong Liu. Co-salient object detection with uncertainty-aware group exchange-masking. InCVPR, pages 19639–19648,
-
[48]
Yang Wu, Kaihua Zhang, Jianjun Qian, Jin Xie, and Jian Yang. Text2lidar: Text-guided lidar point cloud gen- eration via equirectangular transformer.arXiv preprint arXiv:2407.19628, 2024. 2, 4, 6
-
[49]
Weathergen: A unified diverse weather gen- erator for lidar point clouds via spider mamba diffusion
Yang Wu, Yun Zhu, Kaihua Zhang, Jianjun Qian, Jin Xie, and Jian Yang. Weathergen: A unified diverse weather gen- erator for lidar point clouds via spider mamba diffusion. In CVPR, pages 17019–17028, 2025. 6
work page 2025
-
[50]
Learning compact representations for lidar com- pletion and generation
Yuwen Xiong, Wei-Chiu Ma, Jingkang Wang, and Raquel Urtasun. Learning compact representations for lidar com- pletion and generation. InCVPR, pages 1074–1083, 2023. 6
work page 2023
-
[51]
Second: Sparsely embed- ded convolutional detection.Sensors, 18(10):3337, 2018
Yan Yan, Yuxing Mao, and Bo Li. Second: Sparsely embed- ded convolutional detection.Sensors, 18(10):3337, 2018. 2
work page 2018
-
[52]
Copilot4d: Learning unsupervised world models for autonomous driving via discrete diffusion
Lunjun Zhang, Yuwen Xiong, Ze Yang, Sergio Casas, Rui Hu, and Raquel Urtasun. Copilot4d: Learning unsupervised world models for autonomous driving via discrete diffusion. InICLR, 2024. 1, 2, 3, 6, 7
work page 2024
-
[53]
Drivedreamer4d: World models are effective data machines for 4d driving scene rep- resentation
Guosheng Zhao, Chaojun Ni, Xiaofeng Wang, Zheng Zhu, Xueyang Zhang, Yida Wang, Guan Huang, Xinze Chen, Boyuan Wang, Youyi Zhang, et al. Drivedreamer4d: World models are effective data machines for 4d driving scene rep- resentation. InCVPR, pages 12015–12026, 2025. 2
work page 2025
-
[54]
Occworld: Learning a 3d occupancy world model for autonomous driving
Wenzhao Zheng, Weiliang Chen, Yuanhui Huang, Borui Zhang, Yueqi Duan, and Jiwen Lu. Occworld: Learning a 3d occupancy world model for autonomous driving. InECCV, pages 55–72. Springer, 2024. 1, 2, 3
work page 2024
-
[55]
Vision Mamba: Efficient Visual Representation Learning with Bidirectional State Space Model
Lianghui Zhu, Bencheng Liao, Qian Zhang, Xinlong Wang, Wenyu Liu, and Xinggang Wang. Vision mamba: Efficient visual representation learning with bidirectional state space model.arXiv preprint arXiv:2401.09417, 2024. 7
work page internal anchor Pith review arXiv 2024
-
[56]
Learning class prototypes for unified sparse- supervised 3d object detection
Yun Zhu, Le Hui, Hang Yang, Jianjun Qian, Jin Xie, and Jian Yang. Learning class prototypes for unified sparse- supervised 3d object detection. InCVPR, pages 9911–9920,
-
[57]
Learning to generate realistic lidar point clouds
Vlas Zyrianov, Xiyue Zhu, and Shenlong Wang. Learning to generate realistic lidar point clouds. InECCV, pages 17–35. Springer, 2022. 2
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.