Recognition: no theorem link
Teacher-Feature Drifting: One-Step Diffusion Distillation with Pretrained Diffusion Representations
Pith reviewed 2026-05-11 01:23 UTC · model grok-4.3
The pith
Pretrained teacher features enable one-step distillation via a single drifting loss
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By using intermediate hidden states of the pretrained diffusion teacher as feature representations in the drifting loss, a single drifting objective can directly distill the teacher into a one-step generator without extra networks, and the added mode coverage loss ensures the student covers diverse modes, leading to competitive performance.
What carries the argument
The teacher-feature drifting loss, which applies the drifting objective in the space of the teacher's intermediate hidden states.
If this is right
- The overall distillation process is simplified by avoiding auxiliary representation networks.
- One-step models achieve strong FID scores of 1.58 on ImageNet-64x64 and 18.4 on SDXL.
- The method preserves semantically meaningful feature geometry from the teacher.
- A mode coverage loss mitigates mode collapse during training.
Where Pith is reading between the lines
- This method could be tested on other diffusion-based tasks like text-to-image or video generation.
- It suggests internal representations in diffusion models are rich enough to guide distillation directly.
- Similar feature reuse might simplify other teacher-student setups in generative modeling.
Load-bearing premise
The pretrained diffusion teacher model already encodes a strong, semantically meaningful feature geometry in its intermediate hidden states suitable for the drifting objective.
What would settle it
An experiment where distilling with the teacher's features yields substantially worse FID or diversity than using a dedicated external feature extractor would disprove the sufficiency of the teacher's representations.
Figures





read the original abstract
Sampling from pretrained diffusion and flow-matching models typically requires many forward passes to generate diverse and high-fidelity images. Existing distillation methods often rely on multiple auxiliary networks, carefully designed training stages, or complex optimization pipelines. In this work, we revisit the recently proposed Drifting Model objective and show that a single drifting loss can be directly used to simplify one step distillation. A key observation is that the pretrained diffusion teacher itself already provides a strong representation space. Unlike the original Drifting Model, which relies on an additional pretrained feature extractor, we use intermediate hidden states of the pretrained teacher model as the feature representation. This removes the need for training or introducing an extra representation network while preserving a semantically meaningful feature geometry for drifting. Furthermore, we introduce a lightweight mode coverage loss to mitigate mode collapse during distillation and encourage the student generator to cover diverse teacher-supported regions. Extensive experiments on ImageNet and SDXL demonstrate that our method achieves efficient one step generation with competitive image quality and diversity, achieving FID scores of 1.58 on ImageNet-64$\times$64 and 18.4 on SDXL, while substantially simplifying the overall distillation framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Teacher-Feature Drifting, a simplified one-step distillation method for pretrained diffusion and flow-matching models. It shows that a single drifting loss suffices when intermediate hidden states from the teacher UNet itself are used as the feature representation, removing the need for a separate pretrained extractor. A lightweight mode coverage loss is added to reduce mode collapse. The approach is claimed to achieve competitive one-step generation with FID 1.58 on ImageNet-64×64 and 18.4 on SDXL while substantially reducing the distillation pipeline complexity.
Significance. If the central assumption holds, the work offers a meaningful simplification of one-step diffusion distillation by reusing the teacher's own representations, eliminating auxiliary networks and multi-stage training. This could make high-fidelity single-step sampling more accessible and reproducible. The reported FIDs, if substantiated, would place the method competitively with prior distillation techniques.
major comments (3)
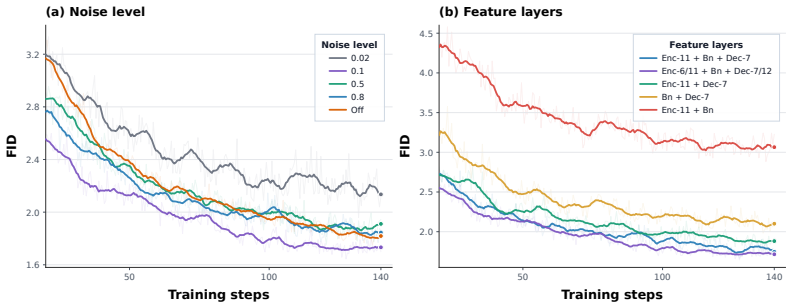
- [Abstract] Abstract: The claim that 'the pretrained diffusion teacher itself already provides a strong representation space' and 'preserving a semantically meaningful feature geometry for drifting' is load-bearing for the simplification, yet no layer indices, timestep handling, or ablation evidence is supplied to show that teacher hidden states are equivalent to the external extractor used in prior Drifting Model work.
- [Abstract] Abstract: The mode coverage loss is introduced to 'mitigate mode collapse' and 'encourage the student generator to cover diverse teacher-supported regions,' but no equation, weighting hyperparameter, or ablation isolating its effect on the reported FID scores is provided, leaving its necessity and contribution unverified.
- [Abstract] Abstract: FID scores of 1.58 (ImageNet-64×64) and 18.4 (SDXL) are presented as competitive, but the text supplies no baselines, training details, or error bars, preventing assessment of whether the results support the 'substantially simplifying' claim.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the abstract would benefit from additional details to support its claims and will revise it accordingly. We respond to each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that 'the pretrained diffusion teacher itself already provides a strong representation space' and 'preserving a semantically meaningful feature geometry for drifting' is load-bearing for the simplification, yet no layer indices, timestep handling, or ablation evidence is supplied to show that teacher hidden states are equivalent to the external extractor used in prior Drifting Model work.
Authors: We acknowledge that the abstract is concise and omits these specifics. In the revised manuscript we will add a brief description of the layer indices selected from the teacher UNet, the timestep handling strategy employed during feature extraction, and a reference to the ablation studies (presented in the main text and supplementary material) that compare the geometry and downstream performance of teacher hidden states against external feature extractors. revision: yes
-
Referee: [Abstract] Abstract: The mode coverage loss is introduced to 'mitigate mode collapse' and 'encourage the student generator to cover diverse teacher-supported regions,' but no equation, weighting hyperparameter, or ablation isolating its effect on the reported FID scores is provided, leaving its necessity and contribution unverified.
Authors: We agree that the abstract should make the mode coverage term more verifiable. In the revision we will include the loss equation, state the weighting hyperparameter, and add a short reference to an ablation that isolates its contribution to FID and diversity metrics. revision: yes
-
Referee: [Abstract] Abstract: FID scores of 1.58 (ImageNet-64×64) and 18.4 (SDXL) are presented as competitive, but the text supplies no baselines, training details, or error bars, preventing assessment of whether the results support the 'substantially simplifying' claim.
Authors: We will expand the abstract to list the primary baseline methods, summarize key training hyperparameters, and indicate result variability (e.g., via standard deviations across runs) so that readers can directly evaluate the competitiveness of the reported FIDs. revision: yes
Circularity Check
No circularity in abstract; claims are empirical without shown derivations
full rationale
The abstract revisits the Drifting Model objective from prior work and asserts that teacher UNet hidden states can substitute for an external feature extractor while preserving geometry for the drifting loss, plus a new mode coverage loss. No equations, layer selections, or derivation steps appear in the provided text, so no self-definitional reductions, fitted inputs renamed as predictions, or self-citation chains can be exhibited. The reported FID scores are presented as experimental outcomes rather than tautological results, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pretrained diffusion teacher provides a strong representation space via its intermediate hidden states that preserves semantically meaningful feature geometry for drifting
Reference graph
Works this paper leans on
-
[1]
Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei
doi: 10.1007/978-3-031-43415-0_32. Jia Deng, Wei Dong, Richard Socher, Li-Jia Li, Kai Li, and Li Fei-Fei. Imagenet: A large-scale hierarchical image database. In2009 IEEE conference on computer vision and pattern recognition, pages 248–255. Ieee,
-
[2]
Generative Modeling via Drifting
Mingyang Deng, He Li, Tianhong Li, Yilun Du, and Kaiming He. Generative modeling via drifting. arXiv preprint arXiv:2602.04770,
work page internal anchor Pith review arXiv
-
[3]
arXiv preprint arXiv:2407.00783 , year =
Michael Fuest, Pingchuan Ma, Ming Gui, Johannes Schusterbauer, Vincent Tao Hu, and Björn Ommer. Diffusion models and representation learning: A survey.arXiv preprint arXiv:2407.00783,
-
[4]
Mean Flows for One-step Generative Modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447,
work page internal anchor Pith review arXiv
-
[5]
Generative Sliced MMD Flows with Riesz Kernels
Ping He, Om Khangaonkar, Hamed Pirsiavash, Yikun Bai, and Soheil Kolouri. Sinkhorn-drifting generative models.arXiv preprint arXiv:2603.12366,
-
[6]
Consistency Trajectory Models: Learning Probability Flow ODE Trajectory of Diffusion, March 2024
Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Naoki Murata, Yuhta Takida, Toshimitsu Ue- saka, Yutong He, Yuki Mitsufuji, and Stefano Ermon. Consistency trajectory models: Learning probability flow ode trajectory of diffusion.arXiv preprint arXiv:2310.02279,
-
[7]
A unified view of drifting and score-based models.arXiv preprint arXiv:2603.07514, 2026
Chieh-Hsin Lai, Bac Nguyen, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yuki Mitsufuji, Stefano Ermon, and Molei Tao. A unified view of drifting and score-based models.arXiv preprint arXiv:2603.07514,
-
[8]
Sdxl- lightning: Progressive adversarial diffusion distillation
Shanchuan Lin, Anran Wang, and Xiao Yang. Sdxl-lightning: Progressive adversarial diffusion distillation.arXiv preprint arXiv:2402.13929,
-
[9]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Flow Straight and Fast: Learning to Generate and Transfer Data with Rectified Flow
Xingchao Liu, Chengyue Gong, and Qiang Liu. Flow straight and fast: Learning to generate and transfer data with rectified flow.arXiv preprint arXiv:2209.03003,
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
Lcm-lora: A universal stable-diffusion acceleration module,
11 Simian Luo, Yiqin Tan, Suraj Patil, Daniel Gu, Patrick V on Platen, Apolinà ˛ Ario Passos, Longbo Huang, Jian Li, and Hang Zhao. Lcm-lora: A universal stable-diffusion acceleration module.arXiv preprint arXiv:2311.05556,
-
[12]
doi: 10.52202/079017-3664. Soumik Mukhopadhyay, Matthew Gwilliam, Yosuke Yamaguchi, Vatsal Agarwal, Namitha Padman- abhan, Archana Swaminathan, Tianyi Zhou, Jun Ohya, and Abhinav Shrivastava. Do text-free diffusion models learn discriminative visual representations? InEuropean Conference on Computer Vision, pages 253–272,
-
[13]
SDXL: Improving Latent Diffusion Models for High-Resolution Image Synthesis
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas Müller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952,
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Fast High-Resolution Image Synthesis with Latent Adversarial Diffusion Distillation
Axel Sauer, Frederic Boesel, Tim Dockhorn, Andreas Blattmann, Patrick Esser, and Robin Rom- bach. Fast high-resolution image synthesis with latent adversarial diffusion distillation. InACM SIGGRAPH Asia Conference Papers, pages 106:1–106:11, 2024a. doi: 10.1145/3680528.3687625. Axel Sauer, Dominik Lorenz, Andreas Blattmann, and Robin Rombach. Adversarial ...
-
[15]
Improved techniques for training consistency models
Yang Song and Prafulla Dhariwal. Improved techniques for training consistency models.arXiv preprint arXiv:2310.14189,
-
[16]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456,
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[17]
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. 2023a. Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models.arXiv preprint arXiv:2303.01469, 2023b. Changyao Tian, Chenxin Tao, Jifeng Dai, Hao Li, Ziheng Li, Lewei Lu, Xiaogang Wang, Hongsheng Li, Gao Huang, and Xizhou Zhu. ADDP: Learning general r...
work page internal anchor Pith review arXiv
-
[18]
Erkan Turan and Maks Ovsjanikov. Generative drifting is secretly score matching: a spectral and variational perspective.arXiv preprint arXiv:2603.09936,
-
[19]
Your ViT is secretly a hybrid discriminative-generative diffusion model
12 Xiulong Yang, Sheng-Min Shih, Yinlin Fu, Xiaoting Zhao, and Shihao Ji. Your ViT is secretly a hybrid discriminative-generative diffusion model.arXiv preprint arXiv:2208.07791,
-
[20]
Generative pre-trained autoregressive diffusion transformer.arXiv preprint arXiv:2505.07344,
Yuan Zhang, Jiacheng Jiang, Guoqing Ma, Zhiying Lu, Haoyang Huang, Jianlong Yuan, Nan Duan, and Daxin Jiang. Generative pre-trained autoregressive diffusion transformer.arXiv preprint arXiv:2505.07344,
-
[21]
Table 3: Hyperparameter settings for the SDXL and ImageNet-64×64experiments
13 A Training Hyperparameters Table 3 summarizes the hyperparameters used for training on SDXL and ImageNet-64×64. Table 3: Hyperparameter settings for the SDXL and ImageNet-64×64experiments. Setting SDXL ImageNet-64 Task Text-to-image generation Class-conditional image generation Training data LAION prompts with SDXL V AE latents ImageNet-64training imag...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.