Recognition: 2 theorem links
· Lean TheoremQuadNorm: Resolution-Robust Normalization for Neural Operators
Pith reviewed 2026-05-11 01:55 UTC · model grok-4.3
The pith
Quadrature-based normalization makes neural operators transfer across grid resolutions with quadratically decaying error.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
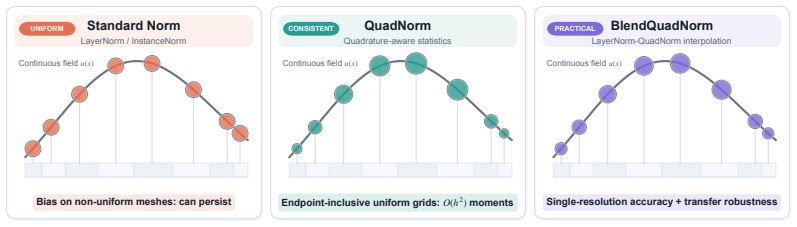
The paper introduces a quadrature normalization family that replaces uniform averaging in normalization layers with numerical quadrature. On endpoint-inclusive uniform grids the resulting moments are O(h²)-consistent across discretizations, meaning their cross-resolution mismatch decays quadratically with grid spacing. A transfer-error bound predicts how normalization-induced mismatch scales with both the resolution gap and network depth. Experiments on Darcy flow and real-data benchmarks match the predicted gap- and depth-scaling trends, with QuadNorm delivering the strongest cross-resolution performance and BlendQuadNorm serving as a conservative default close to LayerNorm for periodic FNO
What carries the argument
QuadNorm and BlendQuadNorm, which replace the uniform average inside normalization layers with numerical quadrature rules that achieve O(h²) consistency across discretizations.
Load-bearing premise
The quadrature moments remain O(h²)-consistent across discretizations specifically on endpoint-inclusive uniform grids.
What would settle it
Direct computation of normalization statistics on successively finer endpoint-inclusive uniform grids that fails to show quadratic decay in the cross-resolution mismatch would disprove the O(h²) consistency.
Figures




read the original abstract
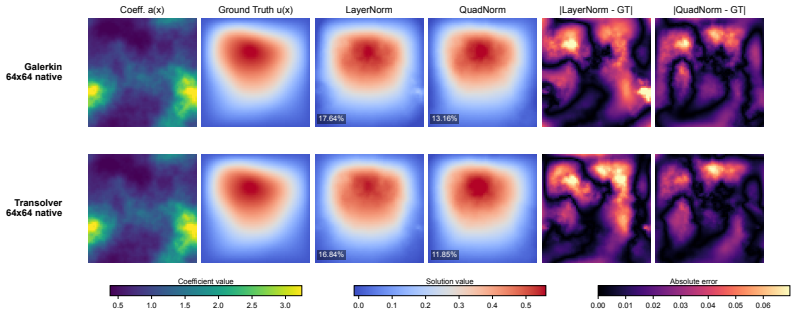
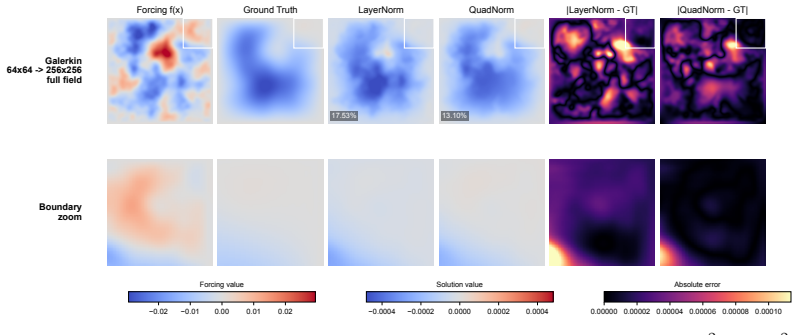
Normalization layers in neural operators usually compute statistics by uniformly averaging discrete grid values, making the normalization itself discretization-dependent and thereby a source of transfer error across different resolutions or meshes. To enable discretization robustness, we introduce a quadrature normalization family that replaces existing uniform averaging in normalization layers with numerical quadrature: QuadNorm and BlendQuadNorm. On endpoint-inclusive uniform grids, the proposed quadrature moments are $O(h^2)$-consistent across discretizations, meaning that their cross-resolution mismatch decays quadratically with grid spacing. A transfer-error bound then predicts how normalization-induced mismatch scales with both the resolution gap and network depth. The experiments show the same gap- and depth-scaling trends predicted by the transfer-error bound. On Darcy, QuadNorm delivers the best cross-resolution performance at every tested target resolution from $64^2$ to $256^2$; on real-data benchmarks, Transolver with QuadNorm achieves nearly resolution-invariant transfer. The largest gains appear on nonperiodic PDEs and nonspectral architectures, where native-resolution improvements also emerge. We also validate BlendQuadNorm, which stays close to LayerNorm behavior and serves as a conservative default for periodic FNO settings. These results identify normalization as a previously overlooked source of resolution dependence in neural operators.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces QuadNorm and BlendQuadNorm, replacing uniform averaging in normalization layers of neural operators with numerical quadrature to reduce discretization dependence. It states that on endpoint-inclusive uniform grids the quadrature moments are O(h²)-consistent across resolutions, derives a transfer-error bound predicting mismatch scaling with resolution gap and network depth, and reports that experiments reproduce the predicted gap- and depth-scaling trends. On Darcy flow, QuadNorm yields the best cross-resolution performance from 64² to 256²; with Transolver on real-data benchmarks it achieves nearly resolution-invariant transfer, with largest gains on nonperiodic PDEs and nonspectral architectures.
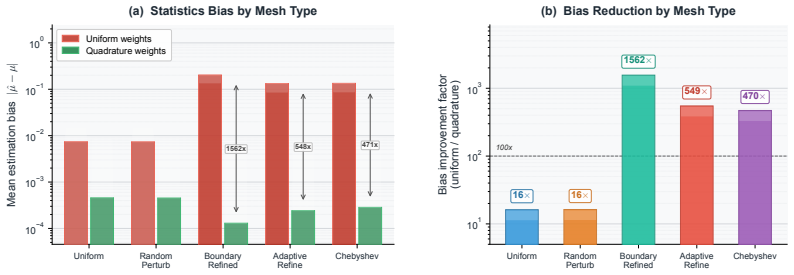
Significance. If the O(h²) consistency and transfer-error bound hold under the tested conditions, the work identifies normalization as an overlooked source of resolution dependence and supplies both a practical remedy and a predictive scaling law. The explicit reproduction of the theoretically predicted gap- and depth-scaling trends in experiments is a positive feature, as are the reported gains on nonperiodic problems. The restriction of the consistency result to endpoint-inclusive uniform grids, however, limits immediate applicability to the irregular or adaptive meshes common in many PDE settings.
major comments (1)
- [Abstract and transfer-error bound derivation] The O(h²)-consistency of the quadrature moments (and therefore the transfer-error bound) is qualified in the abstract to endpoint-inclusive uniform grids. The strongest empirical claims—best cross-resolution performance on Darcy 64²–256² and nearly resolution-invariant transfer on real-data benchmarks—depend on this property holding for the discretizations actually used. The manuscript should explicitly state or verify the grid properties (uniformity, endpoint inclusion, spacing regularity) for every benchmark, including the real-data cases, or report direct moment-mismatch measurements to confirm the bound applies.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive review. The comment highlights an important point about ensuring the theoretical assumptions align with the experimental setups. We address it below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract and transfer-error bound derivation] The O(h²)-consistency of the quadrature moments (and therefore the transfer-error bound) is qualified in the abstract to endpoint-inclusive uniform grids. The strongest empirical claims—best cross-resolution performance on Darcy 64²–256² and nearly resolution-invariant transfer on real-data benchmarks—depend on this property holding for the discretizations actually used. The manuscript should explicitly state or verify the grid properties (uniformity, endpoint inclusion, spacing regularity) for every benchmark, including the real-data cases, or report direct moment-mismatch measurements to confirm the bound applies.
Authors: We agree that the O(h²) consistency and the transfer-error bound are derived under the assumption of endpoint-inclusive uniform grids, and that the strongest empirical claims would be strengthened by explicit verification that the benchmarks satisfy these conditions. In the revised manuscript, we will add a new subsection (or expanded table) in Section 4 (Experiments) that explicitly documents the grid properties—uniformity, endpoint inclusion, and spacing regularity—for every benchmark, including the Darcy flow datasets (generated on uniform Cartesian grids from 64² to 256² that include domain endpoints) and all real-data benchmarks used with Transolver. For the real-data cases, we will report the discretization details from the original data sources. In addition, we will include direct numerical measurements of the quadrature moment mismatch across the tested resolution pairs, either in the main text or as supplementary material, to provide further empirical confirmation that the observed transfer-error scaling is consistent with the derived bound. These additions will make the link between the theoretical qualification and the reported results fully transparent without altering any claims. revision: yes
Circularity Check
No circularity detected in derivation chain
full rationale
The central derivation begins from the definition of quadrature-based moments replacing uniform averaging, then invokes standard numerical quadrature error bounds to establish O(h²) consistency specifically on endpoint-inclusive uniform grids. This consistency property is an external fact from numerical analysis and does not depend on the neural operator architecture, fitted parameters, or target performance metrics. The subsequent transfer-error bound is constructed directly from that consistency property and network depth, without any reduction to self-referential definitions or fitted inputs. Experimental observations of matching gap- and depth-scaling trends constitute validation against the derived bound rather than a circular prediction. No self-citations appear as load-bearing premises, and no ansatz or uniqueness claim is smuggled in. The method remains self-contained against external quadrature theory.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Numerical quadrature can replace uniform averaging to compute normalization statistics in neural operators on discrete grids.
- domain assumption On endpoint-inclusive uniform grids, the quadrature moments are O(h²)-consistent across different discretizations.
invented entities (2)
-
QuadNorm
no independent evidence
-
BlendQuadNorm
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearOn endpoint-inclusive uniform grids, the proposed quadrature moments are O(h²)-consistent across discretizations... Proposition 1 (Second-order consistency of quadrature-weighted means)... Theorem 3 (Output consistency of trapezoidal quadrature-weighted normalization)
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclearA transfer-error bound then predicts how normalization-induced mismatch scales with both the resolution gap and network depth.
Reference graph
Works this paper leans on
-
[1]
Lei Jimmy Ba, Jamie Ryan Kiros, and Geoffrey E. Hinton. Layer Normalization.CoRR, abs/1607.06450, 2016
work page internal anchor Pith review Pith/arXiv arXiv 2016
-
[2]
Representation Equivalent Neural Operators: a Framework for Alias-free Operator Learning
Francesca Bartolucci, Emmanuel de Bézenac, Bogdan Raonic, Roberto Molinaro, Siddhartha Mishra, and Rima Alaifari. Representation Equivalent Neural Operators: a Framework for Alias-free Operator Learning. InNeurIPS, 2023
work page 2023
-
[3]
Aurora: A foundation model of the atmosphere
Cristian Bodnar, Wessel P. Bruinsma, Ana Lucic, Megan Stanley, Johannes Brandstetter, Patrick Garvan, Maik Riechert, Jonathan A. Weyn, Haiyu Dong, Anna Vaughan, Jayesh K. Gupta, Kit Thambiratnam, Alexander T. Archibald, Elizabeth Heider, Max Welling, Richard E. Turner, and Paris Perdikaris. Aurora: A Foundation Model of the Atmosphere.CoRR, abs/2405.13063, 2024
-
[4]
Johannes Brandstetter, Daniel E. Worrall, and Max Welling. Message Passing Neural PDE Solvers. InICLR, 2022
work page 2022
-
[5]
Choose a Transformer: Fourier or Galerkin
Shuhao Cao. Choose a Transformer: Fourier or Galerkin. InNeurIPS, pages 24924–24940, 2021
work page 2021
-
[6]
Finite volume methods.Handbook of numerical analysis, 7:713–1018, 2000
Robert Eymard, Thierry Gallouët, and Raphaèle Herbin. Finite volume methods.Handbook of numerical analysis, 7:713–1018, 2000
work page 2000
- [7]
-
[8]
Improving the Accuracy of the Trapezoidal Rule.SIAM Rev., 63(1):167–180, 2021
Bengt Fornberg. Improving the Accuracy of the Trapezoidal Rule.SIAM Rev., 63(1):167–180, 2021
work page 2021
-
[9]
Discretization-invariance? On the Discretization Mismatch Errors in Neural Operators
Wenhan Gao, Ruichen Xu, Yuefan Deng, and Yi Liu. Discretization-invariance? On the Discretization Mismatch Errors in Neural Operators. InICLR, 2025
work page 2025
-
[10]
GNOT: A General Neural Operator Transformer for Operator Learning
Zhongkai Hao, Zhengyi Wang, Hang Su, Chengyang Ying, Yinpeng Dong, Songming Liu, Ze Cheng, Jian Song, and Jun Zhu. GNOT: A General Neural Operator Transformer for Operator Learning. InICML, pages 12556–12569, 2023
work page 2023
-
[11]
DPOT: Auto-Regressive Denoising Operator Transformer for Large-Scale PDE Pre-Training
Zhongkai Hao, Chang Su, Songming Liu, Julius Berner, Chengyang Ying, Hang Su, Anima Anandkumar, Jian Song, and Jun Zhu. DPOT: Auto-Regressive Denoising Operator Transformer for Large-Scale PDE Pre-Training. InICML, pages 17616–17635, 2024
work page 2024
-
[12]
Poseidon: Efficient Foundation Models for PDEs
Maximilian Herde, Bogdan Raonic, Tobias Rohner, Roger Käppeli, Roberto Molinaro, Em- manuel de Bézenac, and Siddhartha Mishra. Poseidon: Efficient Foundation Models for PDEs. InNeurIPS, 2024
work page 2024
-
[13]
Sture Holm. A simple sequentially rejective multiple test procedure.Scandinavian journal of statistics, pages 65–70, 1979
work page 1979
-
[14]
Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift
Sergey Ioffe and Christian Szegedy. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. InICML, pages 448–456, 2015
work page 2015
-
[15]
Dmitrii Kochkov, Janni Yuval, Ian Langmore, Peter C. Norgaard, Jamie A. Smith, Griffin Mooers, Milan Klöwer, James Lottes, Stephan Rasp, Peter D. Düben, Sam Hatfield, Peter W. Battaglia, Alvaro Sanchez-Gonzalez, Matthew Willson, Michael P. Brenner, and Stephan Hoyer. Neural general circulation models for weather and climate.Nat., 632(8027):1060–1066, 2024
work page 2024
-
[16]
Jean Kossaifi, Nikola B. Kovachki, Zongyi Li, David Pitt, Miguel Liu-Schiaffini, Robert Joseph George, Boris Bonev, Kamyar Azizzadenesheli, Julius Berner, and Anima Anandkumar. A Library for Learning Neural Operators.CoRR, abs/2412.10354, 2024
-
[17]
Kovachki, Samuel Lanthaler, and Siddhartha Mishra
Nikola B. Kovachki, Samuel Lanthaler, and Siddhartha Mishra. On Universal Approximation and Error Bounds for Fourier Neural Operators.J. Mach. Learn. Res., 22:290:1–290:76, 2021. 10
work page 2021
-
[18]
Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew M
Nikola B. Kovachki, Zongyi Li, Burigede Liu, Kamyar Azizzadenesheli, Kaushik Bhattacharya, Andrew M. Stuart, and Anima Anandkumar. Neural Operator: Learning Maps Between Function Spaces With Applications to PDEs.J. Mach. Learn. Res., 24:89:1–89:97, 2023
work page 2023
-
[19]
Simon Lang, Mihai Alexe, Matthew Chantry, Jesper Dramsch, Florian Pinault, Baudouin Raoult, Mariana CA Clare, Christian Lessig, Michael Maier-Gerber, Linus Magnusson, et al. AIFS–ECMWF’s data-driven forecasting system.arXiv preprint arXiv:2406.01465, 2024
-
[20]
Samuel Lanthaler, Andrew M. Stuart, and Margaret Trautner. Discretization Error of Fourier Neural Operators.CoRR, abs/2405.02221, 2024
-
[21]
Randall J LeVeque.Finite volume methods for hyperbolic problems, volume 31. 2002
work page 2002
-
[22]
Transformer for partial differential equations’ operator learning, 2023
Zijie Li, Kazem Meidani, and Amir Barati Farimani. Transformer for Partial Differential Equations’ Operator Learning.CoRR, abs/2205.13671, 2022
-
[23]
Zongyi Li, Nikola B. Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew M. Stuart, and Anima Anandkumar. Neural Operator: Graph Kernel Network for Partial Differential Equations.CoRR, abs/2003.03485, 2020
-
[24]
Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Andrew M
Zongyi Li, Nikola B. Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Andrew M. Stu- art, Kaushik Bhattacharya, and Anima Anandkumar. Multipole Graph Neural Operator for Parametric Partial Differential Equations. InNeurIPS, 2020
work page 2020
-
[25]
Zongyi Li, Nikola Borislavov Kovachki, Kamyar Azizzadenesheli, Burigede Liu, Kaushik Bhattacharya, Andrew M. Stuart, and Anima Anandkumar. Fourier Neural Operator for Parametric Partial Differential Equations. InICLR, 2021
work page 2021
-
[26]
arXiv preprint arXiv:2111.03794 , year =
Zongyi Li, Hongkai Zheng, Nikola B. Kovachki, David Jin, Haoxuan Chen, Burigede Liu, Kamyar Azizzadenesheli, and Anima Anandkumar. Physics-Informed Neural Operator for Learning Partial Differential Equations.CoRR, abs/2111.03794, 2021
-
[27]
Fourier Neural Operator with Learned Deformations for PDEs on General Geometries.J
Zongyi Li, Daniel Zhengyu Huang, Burigede Liu, and Anima Anandkumar. Fourier Neural Operator with Learned Deformations for PDEs on General Geometries.J. Mach. Learn. Res., 24:388:1–388:26, 2023
work page 2023
-
[28]
Zongyi Li, Nikola B. Kovachki, Christopher B. Choy, Boyi Li, Jean Kossaifi, Shourya Prakash Otta, Mohammad Amin Nabian, Maximilian Stadler, Christian Hundt, Kamyar Azizzadenesheli, and Animashree Anandkumar. Geometry-Informed Neural Operator for Large-Scale 3D PDEs. InNeurIPS, 2023
work page 2023
-
[29]
Turner, and Johannes Brandstetter
Phillip Lippe, Bas Veeling, Paris Perdikaris, Richard E. Turner, and Johannes Brandstetter. PDE-Refiner: Achieving Accurate Long Rollouts with Neural PDE Solvers. InNeurIPS, 2023
work page 2023
-
[30]
Domain Agnostic Fourier Neural Operators
Ning Liu, Siavash Jafarzadeh, and Yue Yu. Domain Agnostic Fourier Neural Operators. In NeurIPS, 2023
work page 2023
-
[31]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled Weight Decay Regularization. InICLR, 2019
work page 2019
-
[32]
Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators
Lu Lu, Pengzhan Jin, Guofei Pang, Zhongqiang Zhang, and George Em Karniadakis. Learning nonlinear operators via DeepONet based on the universal approximation theorem of operators. Nat. Mach. Intell., 3(3):218–229, 2021
work page 2021
-
[33]
Michael McCabe, Bruno Régaldo-Saint Blancard, Liam Holden Parker, Ruben Ohana, Miles D. Cranmer, Alberto Bietti, Michael Eickenberg, Siavash Golkar, Géraud Krawezik, François Lanusse, Mariel Pettee, Tiberiu Tesileanu, Kyunghyun Cho, and Shirley Ho. Multiple Physics Pretraining for Spatiotemporal Surrogate Models. InNeurIPS, 2024
work page 2024
-
[34]
Spectral Normaliza- tion for Generative Adversarial Networks
Takeru Miyato, Toshiki Kataoka, Masanori Koyama, and Yuichi Yoshida. Spectral Normaliza- tion for Generative Adversarial Networks. InICLR, 2018
work page 2018
-
[35]
Jaideep Pathak, Shashank Subramanian, Peter Harrington, Sanjeev Raja, Ashesh Chattopadhyay, Morteza Mardani, Thorsten Kurth, David Hall, Zongyi Li, Kamyar Azizzadenesheli, Pedram Hassanzadeh, Karthik Kashinath, and Animashree Anandkumar. FourCastNet: A Global Data-driven High-resolution Weather Model using Adaptive Fourier Neural Operators.CoRR, abs/2202....
work page internal anchor Pith review arXiv 2022
- [36]
-
[37]
Ross, and Kamyar Azizzadenesheli
Md Ashiqur Rahman, Zachary E. Ross, and Kamyar Azizzadenesheli. U-NO: U-shaped Neural Operators.Trans. Mach. Learn. Res., 2023
work page 2023
-
[38]
Convolutional Neural Operators for robust and accurate learning of PDEs
Bogdan Raonic, Roberto Molinaro, Tim De Ryck, Tobias Rohner, Francesca Bartolucci, Rima Alaifari, Siddhartha Mishra, and Emmanuel de Bézenac. Convolutional Neural Operators for robust and accurate learning of PDEs. InNeurIPS, 2023
work page 2023
-
[39]
Tim Salimans and Diederik P. Kingma. Weight Normalization: A Simple Reparameterization to Accelerate Training of Deep Neural Networks. InNIPS, page 901, 2016
work page 2016
-
[40]
Wang, Etienne Le Naour, Jean-Noël Vittaut, and Patrick Gallinari
Louis Serrano, Thomas X. Wang, Etienne Le Naour, Jean-Noël Vittaut, and Patrick Gallinari. AROMA: Preserving Spatial Structure for Latent PDE Modeling with Local Neural Fields. In NeurIPS, 2024
work page 2024
-
[41]
Unique Subedi and Ambuj Tewari. Controlling Statistical, Discretization, and Truncation Errors in Learning Fourier Linear Operators.Trans. Mach. Learn. Res., 2025
work page 2025
-
[42]
Shashank Subramanian, Peter Harrington, Kurt Keutzer, Wahid Bhimji, Dmitriy Morozov, Michael W. Mahoney, and Amir Gholami. Towards Foundation Models for Scientific Machine Learning: Characterizing Scaling and Transfer Behavior. InNeurIPS, 2023
work page 2023
-
[43]
PDEBench: An Extensive Benchmark for Scientific Machine Learning
Makoto Takamoto, Timothy Praditia, Raphael Leiteritz, Daniel MacKinlay, Francesco Alesiani, Dirk Pflüger, and Mathias Niepert. PDEBench: An Extensive Benchmark for Scientific Machine Learning. InNeurIPS, 2022
work page 2022
-
[44]
Factorized Fourier Neural Operators
Alasdair Tran, Alexander Patrick Mathews, Lexing Xie, and Cheng Soon Ong. Factorized Fourier Neural Operators. InICLR, 2023
work page 2023
-
[45]
Lloyd N. Trefethen and J. A. C. Weideman. The Exponentially Convergent Trapezoidal Rule. SIAM Rev., 56(3):385–458, 2014
work page 2014
-
[46]
Instance normalization: The missing in- gredient for fast stylization
Dmitry Ulyanov, Andrea Vedaldi, and Victor S. Lempitsky. Instance Normalization: The Missing Ingredient for Fast Stylization.CoRR, abs/1607.08022, 2016
-
[47]
Hrishikesh Viswanath, Md Ashiqur Rahman, Abhijeet Vyas, Andrey Shor, Beatriz Medeiros, Stephanie Hernandez, Suhas Eswarappa Prameela, and Aniket Bera. Fast Resolution Agnostic Neural Techniques to Solve Partial Differential Equations.CoRR, abs/2301.13331, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[48]
Seidman, Shyam Sankaran, Hanwen Wang, George J
Sifan Wang, Jacob H. Seidman, Shyam Sankaran, Hanwen Wang, George J. Pappas, and Paris Perdikaris. CViT: Continuous Vision Transformer for Operator Learning. InICLR, 2025
work page 2025
-
[49]
Latent Neural Operator for Solving Forward and Inverse PDE Problems
Tian Wang and Chuang Wang. Latent Neural Operator for Solving Forward and Inverse PDE Problems. InNeurIPS, 2024
work page 2024
-
[50]
Shizheng Wen, Arsh Kumbhat, Levi E. Lingsch, Sepehr Mousavi, Yizhou Zhao, Praveen Chandrashekar, and Siddhartha Mishra. Geometry Aware Operator Transformer as an Efficient and Accurate Neural Surrogate for PDEs on Arbitrary Domains.CoRR, abs/2505.18781, 2025
-
[51]
Transolver: A Fast Transformer Solver for PDEs on General Geometries
Haixu Wu, Huakun Luo, Haowen Wang, Jianmin Wang, and Mingsheng Long. Transolver: A Fast Transformer Solver for PDEs on General Geometries. InICML, pages 53681–53705, 2024
work page 2024
-
[52]
Yuxin Wu and Kaiming He. Group Normalization. InECCV (13), pages 3–19, 2018
work page 2018
-
[53]
Root Mean Square Layer Normalization
Biao Zhang and Rico Sennrich. Root Mean Square Layer Normalization. InNeurIPS, pages 12360–12371, 2019
work page 2019
-
[54]
Jianwei Zheng, Wei Li, Ni Xu, Junwei Zhu, Xiaoxu Lin, and Xiaoqin Zhang. Alias-Free Mamba Neural Operator. InNeurIPS, 2024. 12 Appendix Table of Contents A Notation 14 B Theoretical Details and Proofs 14 B.1 Conditional Transfer Error Propagation Bound . . . . . . . . . . . . . . . . . . . . 15 C Implementation and Experimental Setup 17 D Supporting Main-...
work page 2024
-
[55]
Hyperparameter sensitivity.All normalization variants use identical hyperparameters
All inputs include two coordinate channels; outputs are single-channel solution fields. Hyperparameter sensitivity.All normalization variants use identical hyperparameters. The only BlendQuadNorm-specific hyperparameter is α= 0.3 , fixed across experiments; architecture-specific lower-α alternatives are evaluated separately in Appendix Table 16. Beyond th...
-
[56]
In this setting, it therefore yields less degradation than the no-normalization model
QuadNorm shows only 0.22 times to 0.23 times the reference degradation, which is a reduction by a factor of 4.4 to 4.5. In this setting, it therefore yields less degradation than the no-normalization model. BlendQuadNorm achieves 0.91 times to 0.93 times while maintaining LayerNorm’s native accuracy. This degradation comparison, visualized in Figure 3, su...
work page 1943
-
[57]
The table includes SpectralNorm, RI-BandNorm, and QuadBandNorm alongside the standard normalization baselines. Normalization 642 1282 2562 None 3.02±0.09 4.73±0.08 6.12±0.11 LayerNorm2.65±0.06 4.14±0.095.34±0.13 InstanceNorm 3.82±0.06 5.02±0.05 6.10±0.04 GroupNorm2.76±0.074.25±0.08 5.47±0.11 RMSNorm 3.07±0.08 4.48±0.06 5.68±0.08 QuadNorm 3.86±0.06 4.25±0....
-
[58]
[9] address discretization mismatch in kernel and interpolation components
study aliasing; and Gao et al. [9] address discretization mismatch in kernel and interpolation components. Our work is complementary, identifying normalization as an additional source of discretization dependence. Resolution robustness.Recent analyses also quantify discretization and truncation effects in FNO and related pipelines [9, 20, 41]. Multi-resol...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.