Recognition: 1 theorem link
· Lean TheoremSEIF: Self-Evolving Reinforcement Learning for Instruction Following
Pith reviewed 2026-05-11 01:47 UTC · model grok-4.3
The pith
Language models improve instruction following by generating harder tasks for themselves and learning from their own reward signals in a closed loop.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
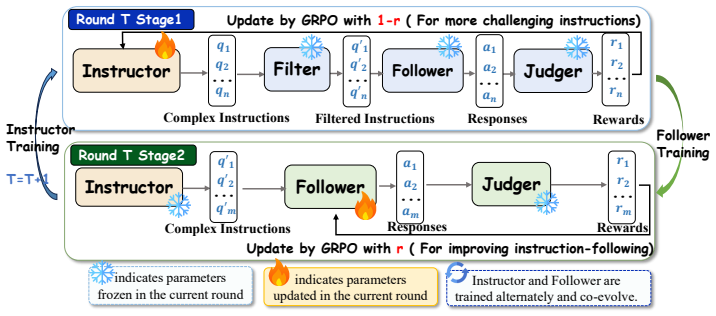
SEIF forms a closed self-evolution loop that improves the model's instruction-following ability, where instruction difficulty evolution and model capability evolution reinforce each other. The Instructor generates increasingly challenging instructions, the Filter removes invalid ones, the Follower learns via reinforcement learning with rewards supplied by the Judger, and the Instructor and Follower are alternately trained to co-evolve.
What carries the argument
The SEIF four-role closed loop in which instruction generation, filtering, following, and self-judged reinforcement rewards alternate and mutually reinforce one another.
If this is right
- Instruction difficulty and model capability co-evolve, enabling continuous gains beyond static-difficulty training.
- Performance improves consistently across multiple model scales and architectures, indicating the approach generalizes.
- A training schedule of sufficient early-stage work followed by moderate late-stage work yields better final results by avoiding overfitting.
Where Pith is reading between the lines
- If the self-judgment mechanism proves stable, the method could lower reliance on human feedback for other LLM capabilities such as reasoning or tool use.
- Repeated cycles might allow models to discover new task distributions that were not present in the original training data.
- The same role-separation structure could be tested on domains with clearer success metrics to check whether the loop remains stable without an explicit Filter.
Load-bearing premise
The Judger supplies reliable reward signals from self-generated data without systematic bias or reward hacking, and the Instructor produces valid instructions that genuinely advance the Follower's capabilities rather than reinforcing existing limitations.
What would settle it
Measure instruction-following benchmark scores after multiple full evolution cycles; if scores plateau or decline rather than rise, or if human raters find that Judger scores diverge from actual task success, the loop claim would be falsified.
Figures




read the original abstract
Instruction following is a fundamental capability of large language models (LLMs), yet continuously improving this capability remains challenging. Existing methods typically rely either on costly external supervision from humans or strong teacher models, or on self-play training with static-difficulty instructions that cannot evolve as the model's capabilities improve. To address these limitations, we propose SEIF (Self-Evolving Reinforcement Learning for Instruction Following), a self-evolving framework for enhancing the instruction-following ability of LLMs. SEIF forms a closed self-evolution loop that improves the model's instruction-following ability, where instruction difficulty evolution and model capability evolution reinforce each other. SEIF consists of four roles: an Instructor that generates increasingly challenging instructions, a Filter that removes conflicting or invalid instructions to ensure data quality, a Follower that learns to follow evolved instructions, and a Judger that provides reward signals for reinforcement learning. The Instructor and Follower are alternately trained and co-evolve throughout the process. Experiments across multiple model scales and architectures show that SEIF consistently improves instruction-following performance, suggesting strong generality. Further analyses reveal the sources of improvement and identify an effective training strategy for self-evolution on open-ended tasks: sufficient early-stage training to build a solid foundation, followed by moderate late-stage training to mitigate overfitting and achieve better final performance. The code and data are publicly available at https://github.com/Rainier-rq1/SEIF.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SEIF, a self-evolving reinforcement learning framework for improving instruction-following in LLMs. It consists of four co-trained roles forming a closed loop: an Instructor that generates progressively harder instructions, a Filter that removes invalid ones, a Follower that learns via RL on the evolved instructions, and a Judger that supplies reward signals. The Instructor and Follower are alternately trained to enable mutual evolution of instruction difficulty and model capability. Experiments across multiple model scales and architectures report consistent performance gains, accompanied by analysis identifying an effective strategy of sufficient early-stage training followed by moderate late-stage training to mitigate overfitting. Code and data are released publicly.
Significance. If the reported gains reflect genuine capability advancement rather than self-reinforcement artifacts, SEIF could reduce dependence on external supervision for LLM improvement and provide a scalable path for self-evolution on open-ended tasks. The public code and data release is a clear strength that supports reproducibility and extension by the community.
major comments (2)
- [Abstract] Abstract: The central claim that 'instruction difficulty evolution and model capability evolution reinforce each other' is load-bearing for the contribution, yet the manuscript provides no tracked metrics of instruction difficulty over iterations, no reward-distribution diagnostics, and no ablations isolating the Judger's self-generated signals from potential bias amplification.
- [Experiments] Experiments (as summarized): The statement of 'consistent improvements across multiple model scales and architectures' lacks reported exact metrics, baseline comparisons, statistical significance tests, or controls for self-reinforcement artifacts, leaving open whether gains exceed what would arise from amplified model preferences alone.
minor comments (1)
- [Abstract] Abstract: The interactions among the four roles (particularly how the Filter prevents propagation of model-specific biases into the Judger's rewards) could be stated more explicitly to clarify the claimed independence.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify how to strengthen the presentation of SEIF's self-evolution mechanism. We agree that more explicit evidence for mutual reinforcement between instruction difficulty and model capability, along with fuller experimental reporting, will improve the manuscript. We address each major comment below and indicate the revisions we will make.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'instruction difficulty evolution and model capability evolution reinforce each other' is load-bearing for the contribution, yet the manuscript provides no tracked metrics of instruction difficulty over iterations, no reward-distribution diagnostics, and no ablations isolating the Judger's self-generated signals from potential bias amplification.
Authors: We acknowledge that the manuscript would benefit from more direct evidence supporting the mutual-evolution claim. In the revised version we will add (i) tracked metrics of instruction difficulty across iterations (using both surface proxies such as length and lexical diversity and model-based complexity estimates), (ii) reward-distribution histograms and statistics from the Judger at multiple training stages, and (iii) an ablation that replaces the self-generated Judger signals with either a fixed external judge or randomized rewards while keeping all other components identical. These additions will be placed in a new subsection of the Experiments section and will directly address concerns about bias amplification. revision: yes
-
Referee: [Experiments] Experiments (as summarized): The statement of 'consistent improvements across multiple model scales and architectures' lacks reported exact metrics, baseline comparisons, statistical significance tests, or controls for self-reinforcement artifacts, leaving open whether gains exceed what would arise from amplified model preferences alone.
Authors: We agree that the current reporting is insufficiently precise. The revised manuscript will include: exact numerical results (means and standard deviations) for every model scale and architecture; expanded baseline tables that compare against standard RLHF, static self-play, and non-evolving instruction sets; statistical significance tests (paired t-tests or Wilcoxon tests with p-values) computed over multiple random seeds; and an explicit control experiment that trains the Follower on instructions generated without the Instructor's evolution loop. These results will be presented in updated tables and a new figure, allowing readers to assess whether observed gains exceed self-reinforcement artifacts. revision: yes
Circularity Check
No circularity: self-evolution is an explicit training mechanism with independent empirical validation.
full rationale
The paper proposes SEIF as a four-role closed loop (Instructor, Filter, Follower, Judger) in which difficulty and capability co-evolve via alternating training on self-generated data. The central claim—that this process improves instruction-following—is not derived by reducing any quantity to its inputs by definition, nor by renaming a known result, nor by a self-citation chain that supplies the uniqueness theorem. Instead, the authors report performance gains measured on held-out benchmarks across model scales and architectures. The self-referential data generation is the method itself, not a hidden tautology that forces the reported outcome; the experiments supply the external check. No load-bearing step equates the final performance metric to the initial model outputs by construction.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A learned Judger can provide accurate scalar rewards for instruction-following quality without external ground truth.
- domain assumption Self-generated instructions can be filtered to remain valid and progressively more difficult without external supervision.
invented entities (3)
-
Instructor role
no independent evidence
-
Filter role
no independent evidence
-
Judger role
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/SelfBootstrapDistinguishability.leanreality_from_one_distinction unclearSEIF forms a closed self-evolution loop that improves the model's instruction-following ability, where instruction difficulty evolution and model capability evolution reinforce each other. ... Instructor and Follower are alternately trained and co-evolve throughout the process.
Reference graph
Works this paper leans on
-
[1]
Ultraif: Advancing instruction following from the wild
Kaikai An, Li Sheng, Ganqu Cui, Shuzheng Si, Ning Ding, Yu Cheng, and Baobao Chang. Ultraif: Advancing instruction following from the wild. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 18722–18737, 2025
work page 2025
-
[2]
Introducing claude opus 4.7, 2026
Anthropic. Introducing claude opus 4.7, 2026. URL https://www.anthropic.com/news/ claude-opus-4-7
work page 2026
-
[3]
Self-evolving curriculum for LLM reasoning.arXiv preprint arXiv:2505.14970, 2025
Xiaoyin Chen, Jiarui Lu, Minsu Kim, Dinghuai Zhang, Jian Tang, Alexandre Piché, Nicolas Gontier, Yoshua Bengio, and Ehsan Kamalloo. Self-evolving curriculum for llm reasoning. arXiv preprint arXiv:2505.14970, 2025
-
[4]
Jiale Cheng, Xiao Liu, Cunxiang Wang, Xiaotao Gu, Yida Lu, Dan Zhang, Yuxiao Dong, Jie Tang, Hongning Wang, and Minlie Huang. Spar: Self-play with tree-search refinement to improve instruction-following in large language models.arXiv preprint arXiv:2412.11605, 2024
-
[5]
Thomas Palmeira Ferraz, Kartik Mehta, Yu-Hsiang Lin, Haw-Shiuan Chang, Shereen Oraby, Sijia Liu, Vivek Subramanian, Tagyoung Chung, Mohit Bansal, and Nanyun Peng. Llm self- correction with decrim: Decompose, critique, and refine for enhanced following of instructions with multiple constraints. InFindings of the Association for Computational Linguistics: E...
work page 2024
-
[6]
Yunhao Gou, Zhili Liu, Kai Chen, Lanqing Hong, Hang Xu, Zhenguo Li, Dit-Yan Yeung, James T Kwok, and Yu Zhang. Mixture of cluster-conditional lora experts for vision-language instruction tuning.IEEE Transactions on Image Processing, 35:3881–3892, 2026
work page 2026
-
[7]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Peiyi Wang, Qihao Zhu, Runxin Xu, Ruoyu Zhang, Shirong Ma, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
Xu Guo, Tianyi Liang, Tong Jian, Xiaogui Yang, Ling-I Wu, Chenhui Li, Zhihui Lu, Qipeng Guo, and Kai Chen. Ifdecorator: Wrapping instruction following reinforcement learning with verifiable rewards.arXiv preprint arXiv:2508.04632, 2025
-
[9]
From general to targeted rewards: Surpassing gpt-4 in open-ended long-context generation
Zhihan Guo, Jiele Wu, Wenqian Cui, Yifei Zhang, Minda Hu, Yufei Wang, and Irwin King. From general to targeted rewards: Surpassing gpt-4 in open-ended long-context generation. arXiv preprint arXiv:2506.16024, 2025
-
[10]
Qianyu He, Jie Zeng, Qianxi He, Jiaqing Liang, and Yanghua Xiao. From complex to simple: Enhancing multi-constraint complex instruction following ability of large language models. In Findings of the Association for Computational Linguistics: EMNLP 2024, pages 10864–10882, 2024
work page 2024
-
[11]
arXiv preprint arXiv:2410.15553 , year=
Yun He, Di Jin, Chaoqi Wang, Chloe Bi, Karishma Mandyam, Hejia Zhang, Chen Zhu, Ning Li, Tengyu Xu, Hongjiang Lv, et al. Multi-if: Benchmarking llms on multi-turn and multilingual instructions following.arXiv preprint arXiv:2410.15553, 2024
-
[12]
R-Zero: Self-Evolving Reasoning LLM from Zero Data
Chengsong Huang, Wenhao Yu, Xiaoyang Wang, Hongming Zhang, Zongxia Li, Ruosen Li, Jiaxin Huang, Haitao Mi, and Dong Yu. R-zero: Self-evolving reasoning llm from zero data. arXiv preprint arXiv:2508.05004, 2025
work page internal anchor Pith review arXiv 2025
-
[13]
Musc: Improving complex instruction following with multi-granularity self-contrastive training
Hui Huang, Jiaheng Liu, Yancheng He, Shilong Li, Bing Xu, Conghui Zhu, Muyun Yang, and Tiejun Zhao. Musc: Improving complex instruction following with multi-granularity self-contrastive training. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 10667–10686, 2025
work page 2025
-
[14]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. Gpt-4o system card.arXiv preprint arXiv:2410.21276, 2024. 10
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[15]
Followbench: A multi-level fine-grained constraints following benchmark for large language models
Yuxin Jiang, Yufei Wang, Xingshan Zeng, Wanjun Zhong, Liangyou Li, Fei Mi, Lifeng Shang, Xin Jiang, Qun Liu, and Wei Wang. Followbench: A multi-level fine-grained constraints following benchmark for large language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 4667–4688, 2024
work page 2024
-
[16]
Mehran Kazemi, Bahare Fatemi, Hritik Bansal, John Palowitch, Chrysovalantis Anastasiou, Sanket Vaibhav Mehta, Lalit K Jain, Virginia Aglietti, Disha Jindal, Yuanzhu Peter Chen, et al. Big-bench extra hard. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 26473–26501, 2025
work page 2025
-
[17]
Andreas Köpf, Yannic Kilcher, Dimitri V on Rütte, Sotiris Anagnostidis, Zhi Rui Tam, Keith Stevens, Abdullah Barhoum, Duc Nguyen, Oliver Stanley, Richárd Nagyfi, et al. Openassistant conversations-democratizing large language model alignment.Advances in neural information processing systems, 36:47669–47681, 2023
work page 2023
-
[18]
Self-alignment with instruction backtranslation
Xian Li, Ping Yu, Chunting Zhou, Timo Schick, Omer Levy, Luke Zettlemoyer, Jason We- ston, and Mike Lewis. Self-alignment with instruction backtranslation.arXiv preprint arXiv:2308.06259, 2023
-
[19]
Yiming Liang, Ge Zhang, Xingwei Qu, Tianyu Zheng, Jiawei Guo, Xinrun Du, Zhenzhu Yang, Jiaheng Liu, Chenghua Lin, Lei Ma, et al. I-sheep: Self-alignment of llm from scratch through an iterative self-enhancement paradigm.arXiv preprint arXiv:2408.08072, 2024
-
[20]
Self: Language-driven self-evolution for large language model
Jianqiao Lu, Wanjun Zhong, Wenyong Huang, Yufei Wang, Fei Mi, Baojun Wang, Weichao Wang, Lifeng Shang, and Qun Liu. Self: Language-driven self-evolution for large language model. 2023
work page 2023
-
[21]
Tianjun Pan, Xuan Lin, Wenyan Yang, Qianyu He, Shisong Chen, Licai Qi, Wanqing Xu, Hong- wei Feng, Bo Xu, and Yanghua Xiao. Rubriceval: A rubric-level meta-evaluation benchmark for llm judges in instruction following.arXiv preprint arXiv:2603.25133, 2026
-
[22]
Verif: Verification engineering for reinforcement learning in instruction following
Hao Peng, Yunjia Qi, Xiaozhi Wang, Bin Xu, Lei Hou, and Juanzi Li. Verif: Verification engineering for reinforcement learning in instruction following. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 30312–30327, 2025
work page 2025
-
[23]
Generalizing verifiable instruction following.arXiv preprint arXiv:2507.02833,
Valentina Pyatkin, Saumya Malik, Victoria Graf, Hamish Ivison, Shengyi Huang, Pradeep Dasigi, Nathan Lambert, and Hannaneh Hajishirzi. Generalizing verifiable instruction following. arXiv preprint arXiv:2507.02833, 2025
-
[24]
Agentif: Benchmarking instruction following of large language models in agentic scenarios
Yunjia Qi, Hao Peng, Xiaozhi Wang, Amy Xin, Youfeng Liu, Bin Xu, Lei Hou, and Juanzi Li. Agentif: Benchmarking instruction following of large language models in agentic scenarios. arXiv preprint arXiv:2505.16944, 2025
-
[25]
Constraint back-translation improves complex instruction following of large language models
Yunjia Qi, Hao Peng, Xiaozhi Wang, Bin Xu, Lei Hou, and Juanzi Li. Constraint back-translation improves complex instruction following of large language models. InProceedings of the 34th ACM International Conference on Information and Knowledge Management, pages 2388–2398, 2025
work page 2025
-
[26]
Incentivizing reasoning for advanced instruction-following of large language models
Yulei Qin, Gang Li, Zongyi Li, Zihan Xu, Yuchen Shi, Zhekai Lin, Xiao Cui, Ke Li, and Xing Sun. Incentivizing reasoning for advanced instruction-following of large language models. arXiv preprint arXiv:2506.01413, 2025
-
[27]
GPQA: A Graduate-Level Google-Proof Q&A Benchmark
David Rein, Betty Li Hou, Asa Cooper Stickland, Jackson Petty, Richard Yuanzhe Pang, Julien Dirani, Julian Michael, and Samuel R Bowman. Gpqa: A graduate-level google-proof q&a benchmark.arXiv preprint arXiv:2311.12022, 2023
work page internal anchor Pith review arXiv 2023
-
[28]
Instructions are all you need: Self-supervised Reinforcement Learning for Instruction Following
Qingyu Ren, Qianyu He, Powei Chang, Jie Zeng, Zeye Sun, Fei Yu, Jiaqing Liang, and Yanghua Xiao. Instructions are all you need: Self-supervised reinforcement learning for instruction following.arXiv preprint arXiv:2510.14420, 2025. 11
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[29]
Lucy Xiaoyang Shi, Brian Ichter, Michael Equi, Liyiming Ke, Karl Pertsch, Quan Vuong, James Tanner, Anna Walling, Haohuan Wang, Niccolo Fusai, et al. Hi robot: Open-ended instruction following with hierarchical vision-language-action models.arXiv preprint arXiv:2502.19417, 2025
-
[30]
arxiv preprint arXiv:2404.02823 , year=
Haoran Sun, Lixin Liu, Junjie Li, Fengyu Wang, Baohua Dong, Ran Lin, and Ruohui Huang. Conifer: Improving complex constrained instruction-following ability of large language models. arXiv preprint arXiv:2404.02823, 2024
-
[31]
Qwq-32b: Embracing the power of reinforcement learning, 2025
Qwen Team. Qwq-32b: Embracing the power of reinforcement learning, 2025
work page 2025
-
[32]
Chenyang Wang, Liang Wen, Shousheng Jia, Xiangzheng Zhang, and Liang Xu. Light-if: En- dowing llms with generalizable reasoning via preview and self-checking for complex instruction following. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 33422–33430, 2026
work page 2026
-
[33]
Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks
Yizhong Wang, Swaroop Mishra, Pegah Alipoormolabashi, Yeganeh Kordi, Amirreza Mirzaei, Atharva Naik, Arjun Ashok, Arut Selvan Dhanasekaran, Anjana Arunkumar, David Stap, et al. Super-naturalinstructions: Generalization via declarative instructions on 1600+ nlp tasks. In Proceedings of the 2022 conference on empirical methods in natural language processing...
work page 2022
-
[34]
Self-instruct: Aligning language models with self-generated instruc- tions
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A Smith, Daniel Khashabi, and Hannaneh Hajishirzi. Self-instruct: Aligning language models with self-generated instruc- tions. InProceedings of the 61st annual meeting of the association for computational linguistics (volume 1: long papers), pages 13484–13508, 2023
work page 2023
-
[35]
Yubo Wang, Xueguang Ma, Ge Zhang, Yuansheng Ni, Abhranil Chandra, Shiguang Guo, Weiming Ren, Aaran Arulraj, Xuan He, Ziyan Jiang, et al. Mmlu-pro: A more robust and challenging multi-task language understanding benchmark.Advances in Neural Information Processing Systems, 37:95266–95290, 2024
work page 2024
-
[36]
Followir: Evaluating and teaching information retrieval models to follow instructions
Orion Weller, Benjamin Chang, Sean MacAvaney, Kyle Lo, Arman Cohan, Benjamin Van Durme, Dawn Lawrie, and Luca Soldaini. Followir: Evaluating and teaching information retrieval models to follow instructions. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technolog...
work page 2025
-
[37]
IF-RewardBench: Benchmarking Judge Models for Instruction-Following Evaluation
Bosi Wen, Yilin Niu, Cunxiang Wang, Xiaoying Ling, Ying Zhang, Pei Ke, Hongning Wang, and Minlie Huang. If-rewardbench: Benchmarking judge models for instruction-following evaluation.arXiv preprint arXiv:2603.04738, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[38]
Meta-rewarding language models: Self-improving alignment with llm-as-a-meta-judge
Tianhao Wu, Weizhe Yuan, Olga Golovneva, Jing Xu, Yuandong Tian, Jiantao Jiao, Jason E Weston, and Sainbayar Sukhbaatar. Meta-rewarding language models: Self-improving alignment with llm-as-a-meta-judge. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 11548–11565, 2025
work page 2025
-
[39]
Writingbench: A comprehensive benchmark for generative writing.CoRR, abs/2503.05244,
Yuning Wu, Jiahao Mei, Ming Yan, Chenliang Li, Shaopeng Lai, Yuran Ren, Zijia Wang, Ji Zhang, Mengyue Wu, Qin Jin, et al. Writingbench: A comprehensive benchmark for generative writing.arXiv preprint arXiv:2503.05244, 2025
-
[40]
Easytool: Enhancing llm-based agents with concise tool instruction
Siyu Yuan, Kaitao Song, Jiangjie Chen, Xu Tan, Yongliang Shen, Kan Ren, Dongsheng Li, and Deqing Yang. Easytool: Enhancing llm-based agents with concise tool instruction. In Proceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pages ...
work page 2025
-
[41]
Self-Rewarding Language Models
Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Xian Li, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. Self-rewarding language models.arXiv preprint arXiv:2401.10020, 2024
work page internal anchor Pith review arXiv 2024
-
[42]
Following length constraints in instructions
Weizhe Yuan, Ilia Kulikov, Ping Yu, Kyunghyun Cho, Sainbayar Sukhbaatar, Jason E Weston, and Jing Xu. Following length constraints in instructions. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, pages 24243–24254, 2025. 12
work page 2025
-
[43]
Junjie Zhang, Ruobing Xie, Yupeng Hou, Wayne Xin Zhao, Leyu Lin, and Ji-Rong Wen. Recommendation as instruction following: A large language model empowered recommendation approach.ACM Transactions on Information Systems, 43(5):1–37, 2026
work page 2026
-
[44]
Cfbench: A comprehensive constraints- following benchmark for llms
Tao Zhang, Chenglin Zhu, Yanjun Shen, Wenjing Luo, Yan Zhang, Hao Liang, Fan Yang, Mingan Lin, Yujing Qiao, Weipeng Chen, et al. Cfbench: A comprehensive constraints- following benchmark for llms. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 32926–32944, 2025
work page 2025
-
[45]
Iopo: Empowering llms with complex instruction following via input-output preference optimization
Xinghua Zhang, Haiyang Yu, Cheng Fu, Fei Huang, and Yongbin Li. Iopo: Empowering llms with complex instruction following via input-output preference optimization. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 22185–22200, 2025
work page 2025
-
[46]
Absolute Zero: Reinforced Self-play Reasoning with Zero Data
Andrew Zhao, Yiran Wu, Yang Yue, Tong Wu, Quentin Xu, Matthieu Lin, Shenzhi Wang, Qingyun Wu, Zilong Zheng, and Gao Huang. Absolute zero: Reinforced self-play reasoning with zero data.arXiv preprint arXiv:2505.03335, 2025
work page internal anchor Pith review arXiv 2025
-
[47]
Llamafactory: Unified efficient fine-tuning of 100+ language models
Yaowei Zheng, Richong Zhang, Junhao Zhang, Yanhan Ye, and Zheyan Luo. Llamafactory: Unified efficient fine-tuning of 100+ language models. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 3: system demonstrations), pages 400–410, 2024
work page 2024
-
[48]
EasyR1: An efficient, scalable, multi-modality rl training framework, 2025
Yaowei Zheng, Junting Lu, Shenzhi Wang, Zhangchi Feng, Dongdong Kuang, Yuwen Xiong, and Richong Zhang. EasyR1: An efficient, scalable, multi-modality rl training framework, 2025. URLhttps://github.com/hiyouga/EasyR1
work page 2025
-
[49]
Instruction-Following Evaluation for Large Language Models
Jeffrey Zhou, Tianjian Lu, Swaroop Mishra, Siddhartha Brahma, Sujoy Basu, Yi Luan, Denny Zhou, and Le Hou. Instruction-following evaluation for large language models.arXiv preprint arXiv:2311.07911, 2023. 13 Appendix A Training Data Construction A.1 Pipeline For theInstructor, the input is a seed instruction, and the model output is a more complex instruc...
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[50]
I currently have a seed question, but the seed question is relatively simple. To make the instruction more complex, I want you to identify and return atomic constraints that can be added to the seed question
-
[51]
I will provide[Seed Question]and[Constraint References]. You may use these references to propose constraints that increase the difficulty of the seed question. 3.[Constraint References]are only suggestions. You may choose one or more constraints from the list, or propose new constraints if needed
-
[52]
Your task is only to generate additional constraints that can be added to it
Do not modify, rewrite, or answer the seed question. Your task is only to generate additional constraints that can be added to it
-
[53]
Avoid vague, redundant, or overlapping constraints
Each added constraint should be atomic, specific, and verifiable. Avoid vague, redundant, or overlapping constraints
-
[54]
Return the added constraints in the following JSON format: json { "c1": "<first constraint>", "c2": "<second constraint>", . . . }
-
[55]
No explanation, no reformulated question, no analysis—only the JSON structure
Do not return anything else. No explanation, no reformulated question, no analysis—only the JSON structure. [Constraint Type References]
-
[56]
Lexical content constraint: {Definition} {Example}
-
[57]
Rule Constraint: {Definition} {Example} [Seed Question] {raw_question} Table 8: GRPO training hyperparameters. Hyperparameter Value Training Framework EasyR1 [48] Global Batch Size 96 Micro Batch Size Per Device For Update 4 Micro Batch Size Per Device For Experience 8 Use KL Loss True Rollout Batch Size 384 Rollout n 5 Max Prompt Length 2048 Max Response...
work page 2048
-
[58]
Word Count: at least20 words
-
[59]
Highlight thenameand thenearby lo- cationusing markdown emphasis. Information coverage Word count Format/highlight T2 (N= 3) [1] Include thename,type of food,cus- tomer rating, andnearby restaurant in a single sentence
-
[60]
Word Count: at least25 words
-
[61]
Highlight thenameand thenearby restaurantusing bold markdown. Information coverage Higher word count Format/bold T3 (N= 5) [1] Use specific adjectives to describe the restaurant’sambianceandservice qual- ity
-
[62]
Limit the sentence to30 words
-
[63]
Mention the nearby restaurant‘Café Rouge’in the sentence
-
[64]
Write the sentence in thepast tenseto reflect historical customer experiences
-
[65]
Include a clause about the type ofIn- dian cuisineoffered. Descriptive specificity Word limit Lexical content Tense constraint Cuisine clause Analysis:T1 requires basic field coverage and markdown emphasis; T2 raises the minimum word count and changes the highlighted entity from nearby location to nearby restaurant with bold format- ting; T3 adds descript...
-
[66]
Highlight theenvironmental impact andcost benefitsof electric vehicles using markdown emphasis
-
[67]
Your answer must contain[electricity], [battery], and[range]as placehold- ers, and be written entirely inEnglish, avoidingALL CAPS. Sentence count Topic coverage Markdown emphasis Placeholder inclusion English language Case restriction T2 (N= 3) [1] The response should include exactly3 bullet pointsusing markdown bullets
-
[68]
The response must contain at least2 highlighted spans
-
[69]
Your answer must be inEnglish, and in all lowercase letters; no capital letters allowed. Bullet count Markdown bullets Highlighted spans English language Lowercase restriction T3 (N= 5) [1] Mandatory use of the terms‘sustain- ability’,‘reduction’, and‘emissions’ in the conversation
-
[70]
Limit the conversation tothree sen- tences per person
-
[71]
Write the conversation inMarkdown format, including headers for each speaker’s lines
-
[72]
Ensure the conversation reflects aprag- matic context, focusing on the benefits and concerns of electric vehicles
-
[73]
Emulate the style of atechnology blog- gerdiscussing the latest trends in eco- friendly transportation. Mandatory terms Sentence limit Markdown format Speaker headers Pragmatic context Style imitation Analysis:T1 requires a multi-sentence English conversation covering both advantages and disadvan- tages of electric vehicles, with markdown emphasis and req...
-
[74]
Response must contain the word‘Ital- ian’at leasttwice
-
[75]
Response should not use the word ‘bad’. Sentence count Lexical frequency Forbidden word T2 (N= 3) [1] Response should contain exactly2 sen- tences
-
[76]
Response should include the word‘ex- pensive’at least once
-
[77]
Sentence count Lexical content Format/bold T3 (N= 5) [1] Useall of the informationprovided
Highlight the restaurant name using bold markdown. Sentence count Lexical content Format/bold T3 (N= 5) [1] Useall of the informationprovided
-
[78]
Write in anencyclopedic style
-
[79]
Limit totwo sentences
-
[80]
Write with apolite tone
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.