Recognition: 2 theorem links
· Lean TheoremBreaking QAOA's Fixed Target Hamiltonian Barrier: A Fully Connected Quantum Boltzmann Machine via Bilevel Optimization
Pith reviewed 2026-05-11 01:47 UTC · model grok-4.3
The pith
Bilevel optimization on QAOA circuits creates a fully connected quantum Boltzmann machine that reaches target states with one layer and resists noise.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
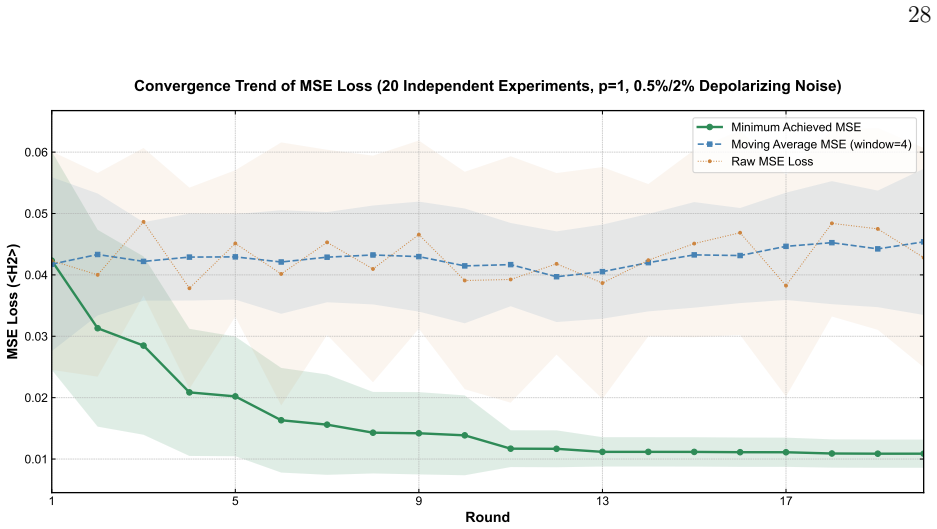
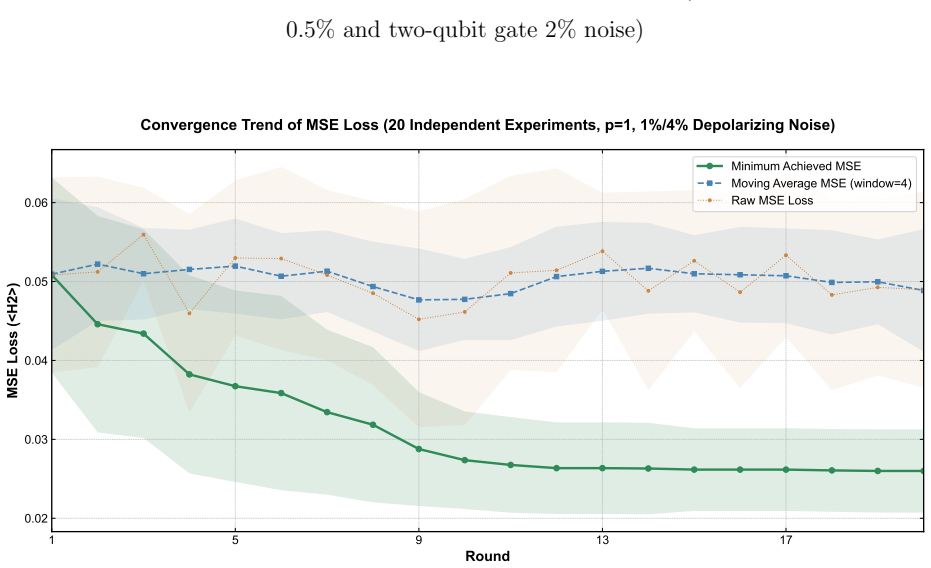
By extending the QAOA circuit into a bilevel optimization architecture, the inner loop simulates positive-phase energy minimization through the conventional QAOA process while the outer loop optimizes the structural parameters of the target Hamiltonian to simulate negative-phase contrastive divergence learning, resulting in a fully connected QBM that exhibits superior performance at p=1 with 0.9559 average target-state probability in the noiseless case, retains 0.6047 and 0.3859 probabilities under typical and doubled noise, and generates the target qubit-grid image consistently with only ten shots per block regardless of noise.
What carries the argument
Bilevel optimization architecture on the QAOA circuit, where the inner loop performs positive-phase energy minimization and the outer loop tunes target-Hamiltonian structural parameters to enable negative-phase learning.
If this is right
- Only a single QAOA layer suffices for high-fidelity target-state preparation, lowering required circuit depth.
- The target state retains the highest measurement probability by a large margin even when noise intensity doubles.
- Block-by-block training with ten shots per block produces the desired qubit-grid image under both typical and elevated noise.
- The architecture removes the fixed-target-Hamiltonian restriction of standard QAOA while preserving variational training.
Where Pith is reading between the lines
- The separation of positive and negative phases may let similar bilevel structures improve other variational quantum algorithms that currently suffer from limited expressivity.
- If the outer-loop optimization scales classically, larger fully connected QBMs could be trained without deepening the quantum circuit.
- The demonstrated image-generation stability under low-shot noisy conditions suggests the method could support early hybrid quantum-classical generative tasks on near-term devices.
- The noise-robust ranking of the target state implies that post-selection or simple thresholding on measurement outcomes could further improve output quality without extra hardware.
Load-bearing premise
That the outer-loop adjustment of the target Hamiltonian's structural parameters successfully replicates negative-phase contrastive divergence without hidden restrictions imposed by the QAOA ansatz mapping.
What would settle it
Executing the trained model on hardware at doubled noise intensity and finding that any non-target state overtakes the target in measurement probability, or that the target probability falls below 0.3 while losing its clear lead, would disprove the robustness claim.
Figures






read the original abstract
To overcome the limitations of classical partially connected Boltzmann machines and mainstream quantum Boltzmann machines (QBMs), this work extends the conventional circuit of the quantum approximate optimization algorithm (QAOA) to a bilevel optimization architecture and proposes a fully connected QBM. The inner-loop training simulates positive phase energy minimization based on the computational process of the conventional QAOA circuit, whereas the outer-loop training simulates negative phase contrastive divergence learning by optimizing the structural parameters of the target Hamiltonian. It is found that, first, the model exhibits superior performance using only a single layer (p=1) in the QAOA circuit, with an average probability of 0.9559 in measuring the target quantum state under noiseless conditions. Second, the model exhibits notable noise robustness. Under the typical noise level of current mainstream commercial quantum computing devices, the average probability of measuring the target quantum state reaches 0.6047; when the noise rises to a more stringent level with doubled intensity, this probability remains at 0.3859. In both scenarios, the target quantum state maintains the highest measurement probability among all detected states, with a value several times higher than that of the second-ranked state. This indicates that the model retains strong robustness even when noise meets or exceeds the upper limit of current mainstream commercial quantum computing devices. Third, under a block-by-block learning strategy with p=1 and only 10 measurement shots, the model consistently generates the target "qubit" grid image regardless of noise interference, demonstrating strong robustness in image generation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes extending the QAOA circuit into a bilevel optimization architecture to train a fully connected quantum Boltzmann machine (QBM). The inner loop performs positive-phase energy minimization using standard QAOA, while the outer loop optimizes the structural parameters of the target Hamiltonian to simulate negative-phase contrastive divergence. The authors claim that with only p=1 QAOA layers the model achieves average target-state measurement probabilities of 0.9559 (noiseless), 0.6047 (typical noise), and 0.3859 (doubled noise intensity), maintains the target state as the highest-probability outcome, and generates target qubit-grid images robustly under noise using a block-by-block strategy with only 10 shots.
Significance. If the bilevel construction can be shown to implement proper contrastive-divergence updates for a fully connected QBM (rather than reducing to direct state preparation), the result would be significant for quantum generative modeling: it would remove the fixed-target-Hamiltonian restriction of conventional QAOA and enable scalable training of dense models on NISQ hardware. The reported single-layer performance and noise tolerance would constitute a practical advance if accompanied by rigorous baselines and sampling analysis.
major comments (3)
- [Bilevel optimization architecture] Bilevel optimization description: the claim that outer-loop tuning of target-Hamiltonian structural parameters implements negative-phase contrastive divergence is not supported by explicit update equations or pseudocode showing how model expectations (obtained from QAOA samples) are subtracted from data expectations. Without these, the procedure risks reducing to direct parameter fitting of the target state rather than enforcing partition-function normalization or hidden-unit marginals required for a true QBM.
- [QAOA circuit and sampling] Inner-loop QAOA usage: QAOA returns a variational approximation to the ground state of the problem Hamiltonian, not thermal samples from the Boltzmann distribution. The manuscript must clarify how this low-energy eigenstate is converted into the negative-phase expectations for a fully connected model; the current description leaves open whether the learned couplings simply drive the circuit toward the target state without correct thermal averaging.
- [Results and performance evaluation] Results section: the numerical performance claims (probabilities 0.9559/0.6047/0.3859 and image-generation success) are presented without specifying qubit count, exact Hamiltonian form, training dataset size, number of independent runs, or comparisons against standard QBM training or other QAOA variants. This prevents assessment of whether the results demonstrate generative modeling or optimized state preparation.
minor comments (2)
- [Abstract and methods] The term 'block-by-block learning strategy' is used in the abstract and results without a prior definition or reference to its implementation details; this should be introduced explicitly in the methods with pseudocode or a diagram.
- [Notation and preliminaries] Notation for the target Hamiltonian structural parameters and the bilevel objective function should be introduced with explicit equations early in the paper to improve readability.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. We address each major comment below, indicating revisions that will strengthen the manuscript's clarity and rigor without altering its core claims.
read point-by-point responses
-
Referee: [Bilevel optimization architecture] Bilevel optimization description: the claim that outer-loop tuning of target-Hamiltonian structural parameters implements negative-phase contrastive divergence is not supported by explicit update equations or pseudocode showing how model expectations (obtained from QAOA samples) are subtracted from data expectations. Without these, the procedure risks reducing to direct parameter fitting of the target state rather than enforcing partition-function normalization or hidden-unit marginals required for a true QBM.
Authors: We agree that explicit mathematical details are needed to distinguish the bilevel procedure from direct state preparation. The revised manuscript will include the full bilevel update equations, showing the inner-loop QAOA minimization of the positive-phase energy and the outer-loop gradient updates on the target Hamiltonian parameters that approximate the negative-phase term via contrastive divergence. Pseudocode will be added to Algorithm 1 to illustrate the subtraction of model expectations (from QAOA samples) from data expectations, along with a brief derivation confirming the partition-function normalization is implicitly handled through the outer optimization. revision: yes
-
Referee: [QAOA circuit and sampling] Inner-loop QAOA usage: QAOA returns a variational approximation to the ground state of the problem Hamiltonian, not thermal samples from the Boltzmann distribution. The manuscript must clarify how this low-energy eigenstate is converted into the negative-phase expectations for a fully connected model; the current description leaves open whether the learned couplings simply drive the circuit toward the target state without correct thermal averaging.
Authors: The referee correctly identifies that QAOA provides a variational ground-state approximation rather than exact thermal sampling. In our architecture the inner loop uses this approximation to realize the positive-phase energy minimization for the fully connected QBM, while the outer loop adjusts Hamiltonian structural parameters to enforce the negative-phase contrast. The revised text will add a dedicated paragraph explaining this approximation, its relation to low-temperature limits of the Boltzmann distribution, and why the bilevel structure still yields generative behavior distinct from pure state preparation. We note that full thermal sampling on NISQ hardware remains challenging and our method offers a practical surrogate. revision: partial
-
Referee: [Results and performance evaluation] Results section: the numerical performance claims (probabilities 0.9559/0.6047/0.3859 and image-generation success) are presented without specifying qubit count, exact Hamiltonian form, training dataset size, number of independent runs, or comparisons against standard QBM training or other QAOA variants. This prevents assessment of whether the results demonstrate generative modeling or optimized state preparation.
Authors: We acknowledge the need for these experimental details to allow proper evaluation. The revised results section will explicitly state the qubit count used for the grid-image experiments, the precise form of the fully connected target Hamiltonian, the training dataset size, the number of independent runs with statistical error bars, and direct comparisons against classical QBM training (via contrastive divergence) and standard QAOA state-preparation baselines. These additions will clarify that the reported probabilities reflect generative performance under the bilevel scheme rather than mere state preparation. revision: yes
Circularity Check
Outer-loop optimization of target Hamiltonian parameters renames direct fitting as negative-phase CD simulation
specific steps
-
fitted input called prediction
[Abstract]
"the inner-loop training simulates positive phase energy minimization based on the computational process of the conventional QAOA circuit, whereas the outer-loop training simulates negative phase contrastive divergence learning by optimizing the structural parameters of the target Hamiltonian. It is found that, first, the model exhibits superior performance using only a single layer (p=1) in the QAOA circuit, with an average probability of 0.9559 in measuring the target quantum state under noiseless conditions."
The outer loop directly varies the structural parameters of the target Hamiltonian (the model's defining object). Labeling this variation 'negative phase contrastive divergence learning' converts the act of fitting those parameters to produce high target-state probability into a claimed CD step. The 0.9559 probability is therefore the direct output of the fitting procedure rather than a prediction generated by a trained QBM whose negative-phase expectations were independently computed.
full rationale
The paper's bilevel architecture defines the QBM via the target Hamiltonian whose structural parameters are directly tuned in the outer loop. This tuning is presented as simulating negative-phase contrastive divergence, but the reported performance metrics (high target-state probabilities) follow immediately from the fitting process itself rather than from an independent generative training procedure that computes model expectations via sampling. The inner QAOA loop approximates energy minimization, but without explicit conversion to thermal Boltzmann samples or partition-function terms, the overall construction reduces the claimed QBM learning to parameter optimization for state preparation.
Axiom & Free-Parameter Ledger
free parameters (1)
- structural parameters of the target Hamiltonian
axioms (2)
- domain assumption Inner-loop QAOA circuit simulates positive-phase energy minimization
- domain assumption Outer-loop optimization of Hamiltonian structure simulates negative-phase contrastive divergence
invented entities (1)
-
bilevel optimization architecture for fully connected QBM
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
inner-loop training simulates positive phase energy minimization based on the computational process of the conventional QAOA circuit, whereas the outer-loop training simulates negative phase contrastive divergence learning by optimizing the structural parameters of the target Hamiltonian
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanLogicNat recovery and J-cost orbit unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
E(s;Θ) = sum b_i x_i + sum w_ij x_i x_j ; P(s;Θ) = 1/Z exp(-E)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
D. H. Ackley, G. E. Hinton, and T. J. Sejnowski. A learning algorithm for Boltzmann machines. Cognitive Science, 9(1):147–169, 1985. doi:10.1207/s15516709cog0901˙7
-
[2]
N. Le Roux and Y. Bengio. Representational power of restricted Boltzmann machines and deep belief networks.Neural Computation, 20(6):1631–1649, 2008. doi:10.1162/neco.2008.04- 07-510
- [3]
- [4]
-
[5]
G. E. Hinton. Training products of experts by minimizing contrastive divergence.Neural Computation, 14(8):1771–1800, 2002. doi:10.1162/089976602760128018
-
[6]
G. E. Hinton, S. Osindero, and Y. W. Teh. A fast learning algorithm for deep belief nets. Neural Computation, 18(7):1527–1554, 2006. doi:10.1162/neco.2006.18.7.1527
-
[7]
R. Salakhutdinov and G. E. Hinton. Deep Boltzmann machines. InProceedings of the In- ternational Conference on Artificial Intelligence and Statistics (AISTATS), pages 448–455, 2009
work page 2009
-
[8]
R. Salakhutdinov and G. E. Hinton. An efficient learning procedure for deep Boltzmann machines.Neural Computation, 24(8):1967–2006, 2012. doi:10.1162/NECO˙a˙00311. 33
-
[9]
G. Mont´ ufar et al. On the number of linear regions of deep neural networks. InAdvances in Neural Information Processing Systems (NeurIPS), pages 2924–2932, 2014
work page 2014
-
[10]
H. Deng et al. The interaction bottleneck of deep neural networks: discovery, proof, and modulation, 2025. URLhttps://arxiv.org/abs/2512.18607
-
[11]
G. E. Hinton. What kind of a graphical model is the brain? InInternational Joint Conference on Artificial Intelligence (IJCAI), pages 1765–1775, 2005
work page 2005
-
[12]
D. Koller and N. Friedman.Probabilistic Graphical Models: Principles and Techniques. MIT Press, 2009. ISBN 9780262013192
work page 2009
-
[13]
N. Wiebe et al. Quantum deep learning. 2014. URLhttps://arxiv.org/abs/1412.3489
-
[14]
N. Wiebe and L. Wossnig. Generative training of quantum Boltzmann machines with hidden units, 2019. URLhttps://arxiv.org/abs/1905.09902
-
[15]
S. Srivastava and V. Sundararaghavan. Generative and discriminative training of Boltz- mann machine through quantum annealing.Scientific Reports, 13(1):12456, 2023. doi: 10.1038/s41598-023-34652-4
- [16]
-
[17]
L. Coopmans and M. Benedetti. On the sample complexity of quantum Boltzmann machine learning.Communications Physics, 7:274, 2024. doi:10.1038/s42005-024-01763-x
-
[18]
D. Patel et al. Quantum Boltzmann machine learning of ground-state energies, 2024. URL https://arxiv.org/abs/2410.12935
-
[19]
M. Demidik et al. Expressive equivalence of classical and quantum restricted Boltzmann machines, 2025. URLhttps://arxiv.org/abs/2502.17562
-
[20]
T. Kimura, K. Kato, and M. Hayashi. Structured quantum learning via em algorithm for Boltzmann machines (Note: The lowercase “em” in the title is as per the original paper; standard abbreviation is EM (expectation-maximization).), 2025. URLhttps://arxiv.org/ abs/2507.21569
-
[21]
E. Rule and E. Rrapaj. Exact block encoding of imaginary time evolution with uni- versal quantum neural networks.Physical Review Research, 7(1):013306, 2025. doi: 10.1103/PhysRevResearch.7.013306
-
[22]
Quantum Computation by Adiabatic Evolution
E. Farhi et al. Quantum computation by adiabatic evolution, 2000. URLhttps://arxiv. org/abs/quant-ph/0001106. 34
work page Pith review arXiv 2000
- [23]
-
[24]
URLhttps://arxiv.org/abs/1411.4028
work page internal anchor Pith review Pith/arXiv arXiv
-
[25]
K. Mitarai et al. Quantum circuit learning.Physical Review A, 98(3):032309, 2018. doi: 10.1103/PhysRevA.98.032309
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.