Recognition: 2 theorem links
· Lean TheoremVaporizer: Breaking Watermarking Schemes for Large Language Model Outputs
Pith reviewed 2026-05-11 01:47 UTC · model grok-4.3
The pith
Watermarking schemes for large language model outputs can be broken by semantic-preserving text modifications.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Through an extensive set of modified text attacks involving lexical alterations, machine translation, and neural paraphrasing, the watermark can be removed from LLM outputs while preserving semantic content, as confirmed by BERT scores, Flesch indices, and other measures. This holds across different watermarking models, showing a common vulnerability.
What carries the argument
The Vaporizer attack framework, which applies multiple text modification strategies to evade watermark detection while preserving content.
Load-bearing premise
The semantic preservation metrics employed, including BERT scores and readability measures, accurately reflect that the modified text maintains its original meaning and practical utility.
What would settle it
Observing a watermarking scheme where none of the attacks succeed in removing the watermark while all modified texts score highly on semantic similarity metrics.
Figures









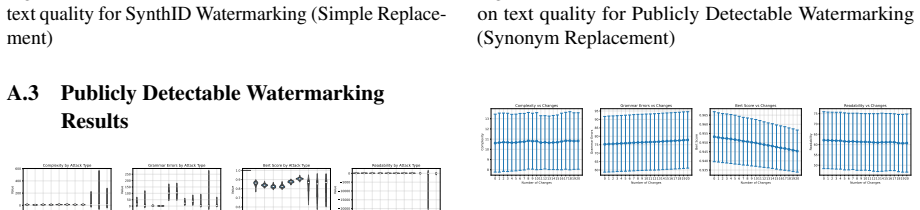
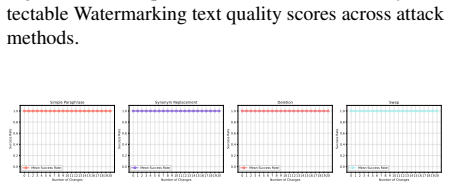

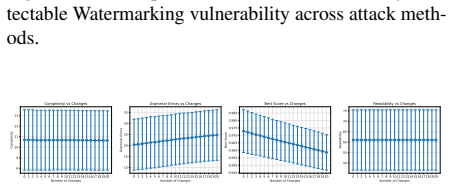
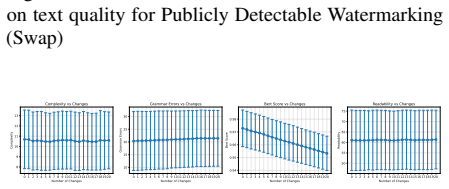
read the original abstract
In this paper, we investigate the recent state-of-the-art schemes for watermarking large language models (LLMs) outputs. These techniques are claimed to be robust, scalable and production-grade, aimed at promoting responsible usage of LLMs. We analyse the effectiveness of these watermarking techniques against an extensive collection of modified text attacks, which perform targeted semantic changes without altering the general meaning of the text content. Our approach encompasses multiple attack strategies, which include lexical alterations, machine translation, and even neural paraphrasing. The attack efficacy is measured with two target criteria - successful removal of the watermark and preservation of semantic content. We evaluate semantic preservation through BERT scores, text complexity measures, grammatical errors, and Flesch Reading Ease indices. The experimental results reveal varying levels of effectiveness among different watermarking models, with the same underlying result that it is possible to remove the watermark with reasonable effort. This study sheds light on the strengths and weaknesses of existing LLM watermarking systems, suggesting how they should be constructed to improve security of available schemes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims to break state-of-the-art LLM watermarking schemes by applying attacks such as lexical alterations, machine translation, and neural paraphrasing. These attacks are said to remove the watermark successfully while preserving the semantic content of the original text, as verified through metrics including BERT scores, text complexity measures, grammatical error counts, and Flesch Reading Ease indices. The experimental results show varying robustness among the tested watermarking models, leading to the conclusion that current schemes can be defeated with reasonable effort and offering suggestions for more secure constructions.
Significance. If the results hold under stronger validation, this work is significant because it supplies concrete empirical evidence of vulnerabilities in LLM watermarking techniques proposed for responsible AI deployment and content provenance. The multi-attack evaluation across lexical, translation, and paraphrase vectors usefully exposes relative weaknesses among schemes. The purely empirical character with direct measurements (no circular derivations) is a strength, but the preservation side of the two-criterion success definition rests on automated proxies whose limitations are well-documented in the NLP literature.
major comments (1)
- [Experimental Evaluation] The central claim requires both watermark removal and semantic/utility preservation. The evaluation (described in the abstract and experimental sections) relies on BERTScore, Flesch indices, complexity measures, and grammar counts to assert preservation. These proxies are known to remain high even when paraphrasing or translation alters implications, factual emphasis, or downstream utility; no human equivalence ratings, adversarial-meaning examples, or task-specific utility checks (e.g., QA accuracy on the modified text) are reported. This directly undermines the two-criterion success definition and is load-bearing for the paper's conclusions.
minor comments (1)
- [Abstract] The abstract would be strengthened by including at least summary quantitative results (e.g., average watermark detection rates or metric deltas per scheme and attack) rather than qualitative statements alone.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We agree that the experimental validation of semantic preservation merits strengthening and will revise the manuscript to address this directly.
read point-by-point responses
-
Referee: The central claim requires both watermark removal and semantic/utility preservation. The evaluation (described in the abstract and experimental sections) relies on BERTScore, Flesch indices, complexity measures, and grammar counts to assert preservation. These proxies are known to remain high even when paraphrasing or translation alters implications, factual emphasis, or downstream utility; no human equivalence ratings, adversarial-meaning examples, or task-specific utility checks (e.g., QA accuracy on the modified text) are reported. This directly undermines the two-criterion success definition and is load-bearing for the paper's conclusions.
Authors: We acknowledge that automated metrics such as BERTScore, while standard in the NLP literature for assessing semantic similarity, have documented limitations and may not fully capture changes in factual emphasis, implications, or downstream task utility. Our original evaluation combined multiple complementary proxies (BERTScore for semantic overlap, Flesch and complexity measures for readability, and grammar counts for surface quality) to provide a multi-faceted view, but we agree this falls short of definitive proof for the preservation criterion. In the revised version we will add a human evaluation component: a small-scale study with annotators rating semantic equivalence and meaning preservation on a subset of attacked outputs, along with qualitative examples illustrating preserved versus altered implications. We will also note the absence of task-specific utility tests as a limitation and suggest it as future work. These additions will directly bolster the two-criterion success definition without altering the core empirical findings on watermark removal. revision: yes
Circularity Check
No circularity: purely empirical attack evaluation with direct measurements
full rationale
The paper is an empirical study that applies attacks (lexical change, MT, neural paraphrase) to existing watermarking schemes and reports success rates plus semantic-preservation scores from BERT, Flesch, grammar counts, etc. No derivations, equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described methodology. All claims rest on observable experimental outcomes rather than any reduction to prior inputs by construction, so none of the enumerated circularity patterns apply.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Our approach encompasses multiple attack strategies, which include lexical alterations, machine translation, and even neural paraphrasing... evaluated through BERT scores, text complexity measures, grammatical errors, and Flesch Reading Ease indices.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Pegasus Paraphrase achieved the highest success rate (23%) with the lowest mean Z-score (0.93)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Figueredo, A. J. and Wolf, P. S. A. , title =. Human Nature , volume =. 2009 , doi=
work page 2009
-
[2]
Hao, Z. and AghaKouchak, A. and Nakhjiri, N. and Farahmand, A , year =. Global integrated drought monitoring and prediction system (
-
[3]
Provable Robust Watermarking for
Xuandong Zhao and Prabhanjan Vijendra Ananth and Lei Li and Yu-Xiang Wang , booktitle=. Provable Robust Watermarking for. 2024 , url=
work page 2024
-
[4]
doi:10.62056/ahmpdkp10 , author=
Publicly-Detectable Watermarking for Language Models , journal=. doi:10.62056/ahmpdkp10 , author=
-
[5]
Scalable Watermarking for Identifying Large Language Model Outputs , author =. 2024 , month = oct, journal =
work page 2024
-
[6]
What Are Large Language Models (LLMs)? , year = 2023, url =
work page 2023
-
[7]
The Secret Language of AI Watermarks for GenAI Text , year = 2023, url =
work page 2023
-
[8]
Aiwei Liu and Leyi Pan and Yijian Lu and Jingjing Li and Xuming Hu and Xi Zhang and Lijie Wen and Irwin King and Hui Xiong and Philip S. Yu , title =. ACM Computing Surveys , volume =. 2024 , doi =
work page 2024
-
[9]
Abe Bohan Hou and Jingyu Zhang and Tianxing He and Yichen Wang and Yung-Sung Chuang and Hongwei Wang and Lingfeng Shen and Benjamin Van Durme and Daniel Khashabi and Yulia Tsvetkov , title =. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers...
work page 2024
-
[10]
A watermark for large language models.arXiv preprint arXiv:2301.10226, 2023a
A Watermark for Large Language Models , author=. arXiv preprint arXiv:2301.10226 , year=
- [11]
-
[12]
Vaswani, Ashish and Shazeer, Noam and Parmar, Niki and Uszkoreit, Jakob and Jones, Llion and Gomez, Aidan N and ukasz Kaiser,. Attention Is. Advances in. 2017 , volume =
work page 2017
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.