Recognition: 2 theorem links
· Lean TheoremLARAG: Link-Aware Retrieval Strategy for RAG Systems in Hyperlinked Technical Documentation
Pith reviewed 2026-05-11 02:12 UTC · model grok-4.3
The pith
Encoding hyperlinks as metadata in RAG enables implicit graph-like retrieval that improves answer quality on technical documentation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
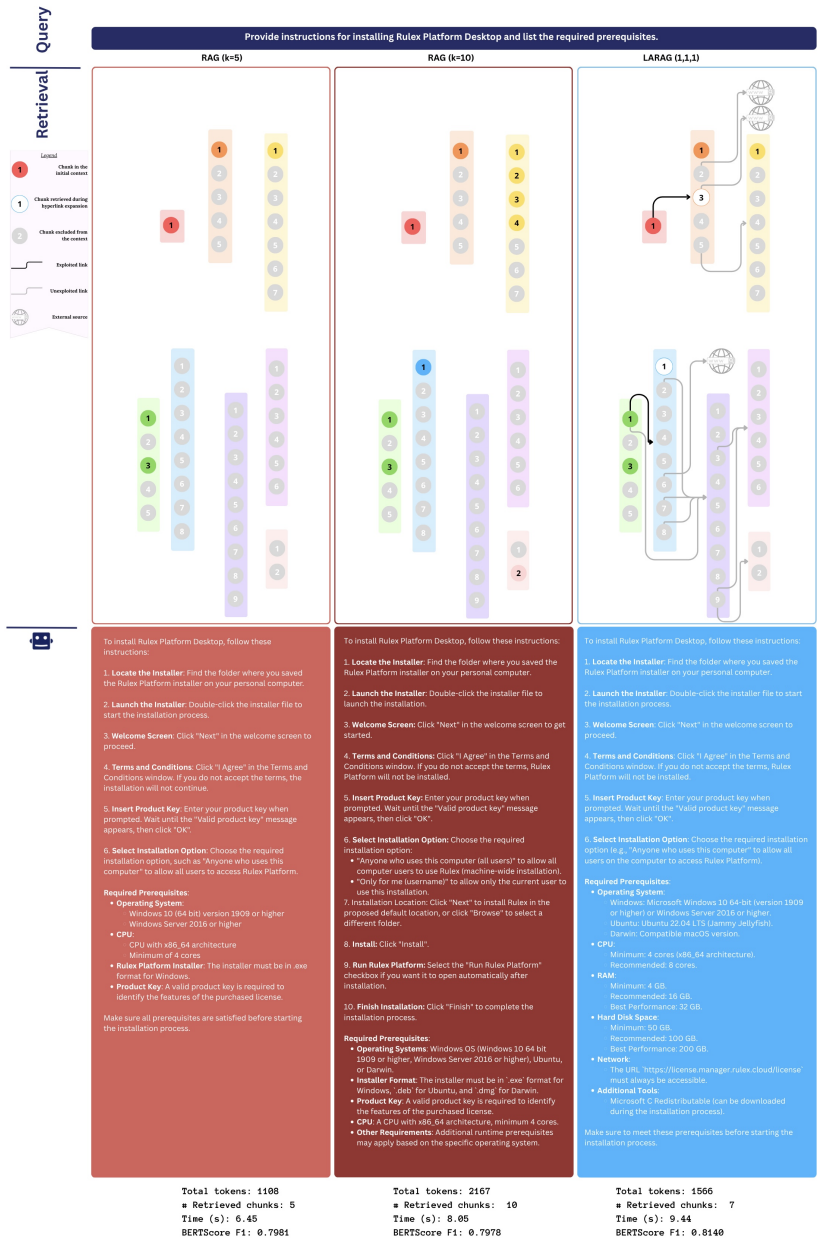
LARAG is a lightweight link-aware retrieval strategy that leverages the author-defined hyperlink structure already present in HTML documentation by encoding hyperlink relations as metadata and exploiting them to retrieve locally relevant content, yielding more faithful and efficient RAG pipelines.
What carries the argument
The encoding of hyperlink relations as metadata in chunk representations, enabling implicit graph-like retrieval without explicit graph construction or inference.
Load-bearing premise
That the existing hyperlink topology in HTML documentation encodes locally relevant content missed by standard embedding retrievers.
What would settle it
A direct comparison where a standard embedding-based RAG achieves equal or superior BERTScore F1 scores while retrieving a similar or smaller number of chunks on the same set of queries.
Figures





read the original abstract
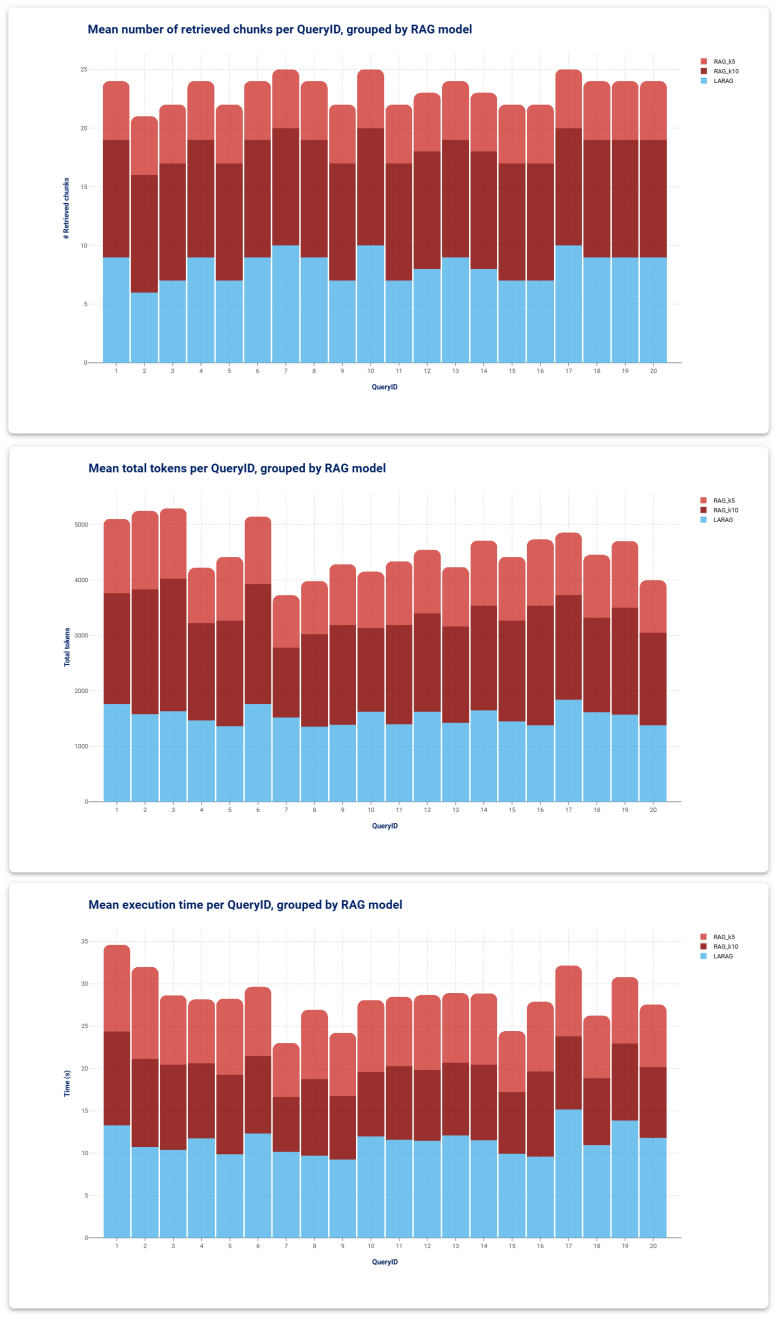
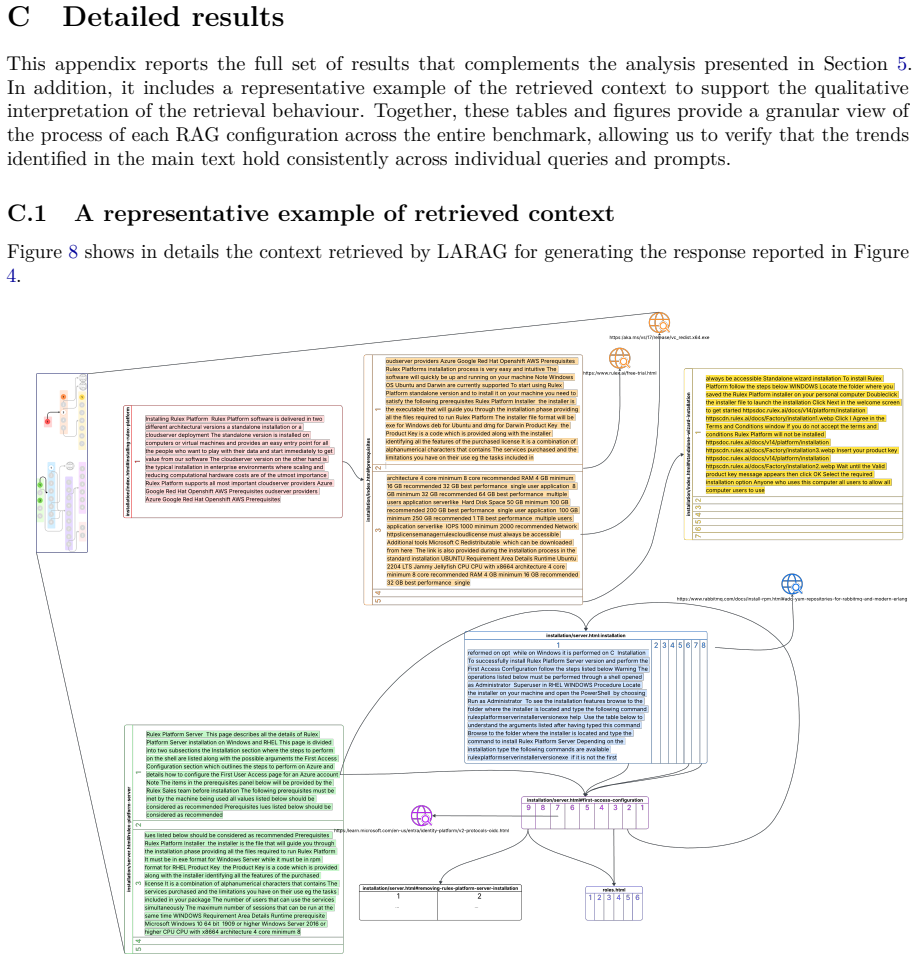
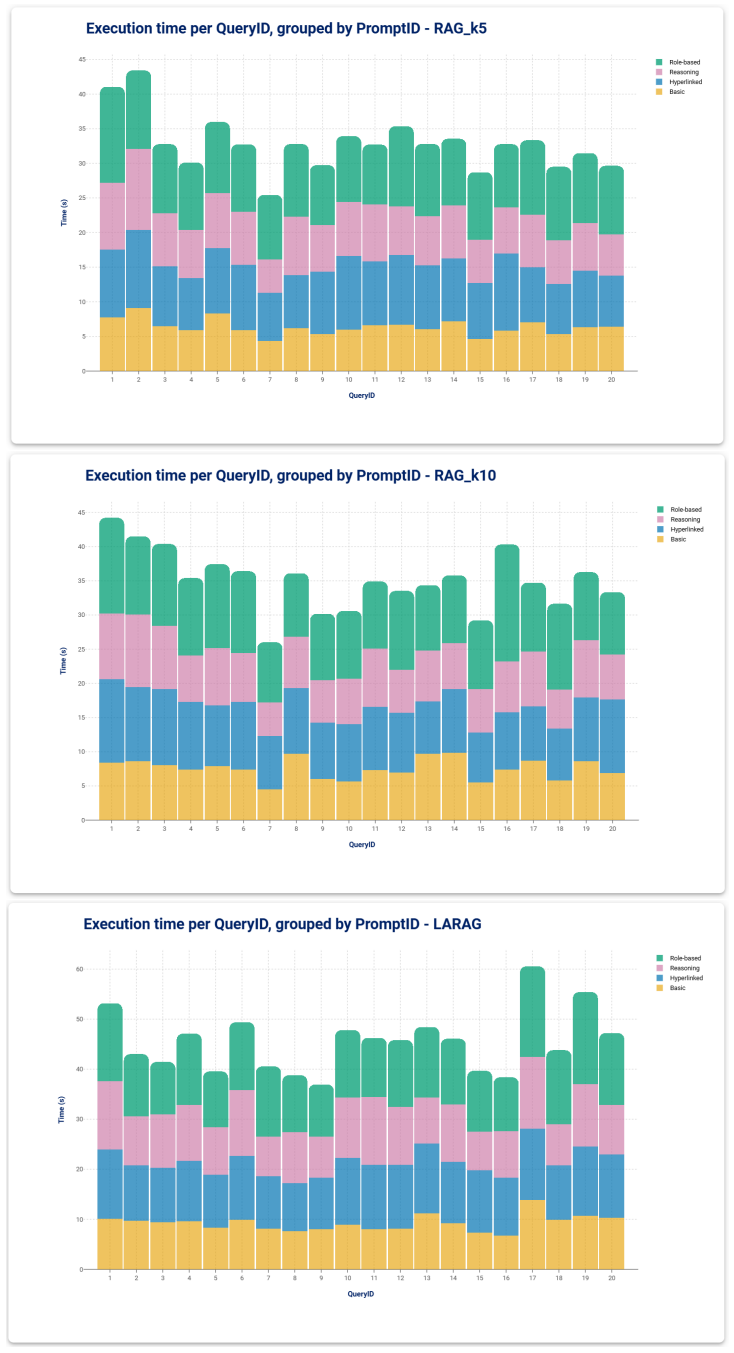
Retrieval-Augmented Generation (RAG) enhances the factual grounding of Large Language Models by conditioning their outputs on external documents. However, standard embedding-based retrievers treat naturally structured corpora, such as technical manuals, as flat collections of passages, thereby overlooking the hyperlink topology that users rely on when navigating such content. We introduce LARAG (Link-Aware RAG): a lightweight, link-aware retrieval strategy that leverages the author-defined hyperlink structure already present in HTML documentation, encoding hyperlink relations as metadata in the chunk representations and exploiting them to perform a form of graph-like retrieval of locally relevant content. In a benchmark of twenty expert-designed queries over Rulex Platform technical documentation and four prompting strategies, LARAG consistently improves answer quality, achieving the highest BERTScore F1, while retrieving fewer chunks and generating fewer tokens than a baseline RAG architecture used for comparison. These results show that directly leveraging the existing hyperlink topology of technical documentation, even without explicit graph construction or inference, enables an implicit form of graph-like retrieval that yields a more faithful and efficient RAG pipeline, providing better grounding at lower cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LARAG, a lightweight link-aware retrieval strategy for RAG that encodes author-defined hyperlink relations from HTML technical documentation as metadata in chunk representations to enable implicit graph-like retrieval of locally relevant content. It evaluates the approach on a benchmark of 20 expert-designed queries over Rulex Platform technical documentation using four prompting strategies, claiming consistent improvements in answer quality via highest BERTScore F1, along with efficiency gains of retrieving fewer chunks and generating fewer tokens compared to a standard baseline RAG system.
Significance. If the empirical results hold under more rigorous testing, the work shows that directly exploiting pre-existing hyperlink topology in structured technical corpora can yield better-grounded and lower-cost RAG pipelines without requiring explicit graph construction, inference, or additional training. This provides a practical, low-overhead technique for improving retrieval in domain-specific documentation where users naturally navigate via links, highlighting an underused signal in embedding-based retrievers.
major comments (2)
- [Evaluation] Evaluation (abstract and results): The central claim of 'consistent' improvement in BERTScore F1 and efficiency rests on a single run over 20 queries with no per-query scores, standard deviations, confidence intervals, or paired statistical significance tests (e.g., Wilcoxon signed-rank) reported against the baseline. This makes it impossible to assess whether observed gains are robust or could arise from query selection bias, as expert-designed queries may preferentially align with hyperlink navigation paths.
- [Methodology] Methodology: The description of hyperlink encoding as metadata, the precise chunking strategy applied to the HTML corpus, the baseline RAG implementation details (embedding model, retrieval parameters, any reranking), and how the four prompting strategies are applied are insufficiently specified. Without these, reproduction is not possible and potential confounds in the head-to-head comparison cannot be ruled out.
minor comments (2)
- [Abstract] Abstract: The four prompting strategies are referenced but not named or briefly described, leaving unclear how they interact with the link-aware retrieval versus the baseline.
- [Introduction] Introduction/Related Work: The distinction between 'implicit graph-like retrieval' via metadata and actual graph algorithms or traversals could be clarified to avoid overstatement, as the method appears to augment standard retrieval rather than perform explicit graph operations.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment below and commit to revisions that improve the manuscript's rigor and reproducibility.
read point-by-point responses
-
Referee: [Evaluation] The central claim of 'consistent' improvement in BERTScore F1 and efficiency rests on a single run over 20 queries with no per-query scores, standard deviations, confidence intervals, or paired statistical significance tests (e.g., Wilcoxon signed-rank) reported against the baseline. This makes it impossible to assess whether observed gains are robust or could arise from query selection bias, as expert-designed queries may preferentially align with hyperlink navigation paths.
Authors: We acknowledge that aggregate-only reporting limits assessment of robustness. In the revision we will add per-query BERTScore F1 tables for LARAG and baseline to show consistency across all 20 queries. We will also report results of a Wilcoxon signed-rank test on the paired per-query scores. We will expand the discussion to address potential query selection bias, noting that the queries were designed by experts to mirror typical technical-documentation navigation tasks while acknowledging this as a limitation. Because the evaluation used a single run, we cannot supply standard deviations or confidence intervals from repeated trials. revision: partial
-
Referee: [Methodology] The description of hyperlink encoding as metadata, the precise chunking strategy applied to the HTML corpus, the baseline RAG implementation details (embedding model, retrieval parameters, any reranking), and how the four prompting strategies are applied are insufficiently specified. Without these, reproduction is not possible and potential confounds in the head-to-head comparison cannot be ruled out.
Authors: We agree that the current description is insufficient for reproduction. We will revise the Methodology section to specify: (i) the exact procedure for extracting author-defined hyperlinks and encoding them as metadata within chunks; (ii) the chunking strategy, including HTML-aware splitting rules, chunk size, and overlap; (iii) baseline RAG details such as the embedding model, top-k retrieval parameter, and any reranking steps; and (iv) the four prompting strategies with their exact templates and application to retrieved contexts. These additions will enable reproduction and eliminate potential confounds. revision: yes
- Reporting standard deviations or confidence intervals derived from multiple experimental runs, as only single-run results are currently available.
Circularity Check
No circularity: empirical benchmark is self-contained
full rationale
The paper introduces LARAG as a lightweight retrieval strategy that encodes existing hyperlink metadata and evaluates it via direct head-to-head comparison against a baseline RAG on 20 expert-designed queries over Rulex documentation. Metrics (BERTScore F1, chunk count, token count) are reported as observed outcomes of this fixed experimental setup. No equations, parameter fitting, self-citations, or derivations appear in the provided text; the central claim reduces only to measured differences on held-out queries and does not collapse to any input by construction. This is the standard case of an independent empirical result.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Author-defined hyperlinks in technical documentation encode locally relevant content that standard embedding retrievers overlook.
Lean theorems connected to this paper
-
IndisputableMonolith.Cost.FunctionalEquationwashburn_uniqueness_aczel unclearLARAG ... consistently improves answer quality, achieving the highest BERTScore F1, while retrieving fewer chunks and generating fewer tokens
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b & gpt-oss-20b Model Card
Agarwal, S., Ahmad, L., Ai, J., Altman, S., Applebaum, A., Arbus, E., Arora, R. K., Bai, Y., Baker, B., Bao, H., et al.gpt-oss-120b & gpt-oss-20b model card.arXiv preprint arXiv:2508.10925(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Alkouz, A., Al-Saleh, M. I., Alarabeyyat, A., and Bouchahma, M.Ukrag: A unified knowledge graph to enhance retrieval augmented generation performance. InIntelligent Computing Systems(Cham, 2025), A. Safi, A. Martin-Gonzalez, C. Brito-Loeza, and V. Castañeda-Zeman, Eds., Springer Nature Switzerland, pp. 1–19
work page 2025
-
[3]
InThe Twelfth International Conference on Learning Representations(2023)
Asai, A., Wu, Z., W ang, Y., Sil, A., and Hajishirzi, H.Self-rag: Learning to retrieve, generate, and critique through self-reflection. InThe Twelfth International Conference on Learning Representations(2023)
work page 2023
-
[4]
Bolognesi, G.Graph-Based Retrieval Strategy for RAG Systems in Hyperlinked Technical Doc- umentation. Master’s thesis, University of Genova, Department of Informatics, Bioengineering, Robotics and Systems Engineering, Genova, Italy, 2025. Supervisors: Prof. Luca Oneto, Dr. Claudio Muselli
work page 2025
-
[5]
InAdvances in Neural Information Processing Systems(2020), H
Brown, T., et al.Language models are few-shot learners. InAdvances in Neural Information Processing Systems(2020), H. Larochelle, M. Ranzato, R. Hadsell, M. Balcan, and H. Lin, Eds., vol. 33, Curran Associates, Inc., pp. 1877–1901
work page 2020
-
[6]
Cosson, R., Massoulié, L., and Viennot, L.Efficient collaborative tree exploration with breadth-first depth-next. InInternational Symposium on Distributed Computing (DISC 2023)(2023), Schloss Dagstuhl–Leibniz-Zentrum für Informatik
work page 2023
-
[7]
arXiv:2405.18414 [cs.CL] https://arxiv.org/abs/2405.18414
Dong, J., F atemi, B., Perozzi, B., Yang, L. F., and Tsitsulin, A.Don’t forget to connect! improving rag with graph-based reranking.arXiv preprint arXiv:2405.18414(2024)
-
[8]
From Local to Global: A Graph RAG Approach to Query-Focused Summarization
Edge, D., Trinh, H., Cheng, N., Bradley, J., Chao, A., Mody, A., Truitt, S., Metropoli- tansky, D., Ness, R. O., and Larson, J.From local to global: A graph rag approach to query-focused summarization.arXiv preprint arXiv:2404.16130(2024)
work page internal anchor Pith review arXiv 2024
- [9]
-
[10]
Floridi, L., and Chiriatti, M.Gpt-3: Its nature, scope, limits, and consequences.Minds and Machines 30, 4 (2020), 681–694
work page 2020
-
[11]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Guo, D., Yang, D., Zhang, H., Song, J., Zhang, R., Xu, R., Zhu, Q., Ma, S., W ang, P., Bi, X., et al.Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning. arXiv preprint arXiv:2501.12948(2025)
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[12]
U., Al-Tashi, Q., Qureshi, R., Shah, A., Muneer, A., Irfan, M., Zafar, A., Shaikh, M
Hadi, M. U., Al-Tashi, Q., Qureshi, R., Shah, A., Muneer, A., Irfan, M., Zafar, A., Shaikh, M. B., Akhtar, N., Wu, J., and Mirjalili, S.Large language models: A comprehensive survey of its applications, challenges, limitations, and future prospects, 2023. Preprint
work page 2023
-
[13]
ACM Transactions on Computing for Healthcare (HEALTH), 3(1):1–23
Han, H., W ang, Y., Shomer, H., Guo, K., Ding, J., Lei, Y., Halappanavar, M., Rossi, R. A., Mukherjee, S., Tang, X., et al.Retrieval-augmented generation with graphs (graphrag). arXiv preprint arXiv:2501.00309(2024). 20
-
[14]
Hang, C.-N., Yu, P.-D., Morabito, R., and Tan, C.-W.Large language models meet next-generation networking technologies: A review.Future Internet 16, 10 (2024)
work page 2024
-
[15]
Hong, K., Troynikov, A., and Huber, J.Context rot: How increasing input tokens impacts llm performance. Tech. rep., Chroma, July 2025
work page 2025
-
[16]
Hu, E. J., yelong shen, W allis, P., Allen-Zhu, Z., Li, Y., W ang, S., W ang, L., and Chen, W.LoRA: Low-rank adaptation of large language models. InInternational Conference on Learning Representations(2022)
work page 2022
-
[17]
Hu, Y., Lei, Z., Zhang, Z., Pan, B., Ling, C., and Zhao, L.GRAG: Graph retrieval- augmented generation. InFindings of the Association for Computational Linguistics: NAACL 2025 (Albuquerque, New Mexico, Apr. 2025), L. Chiruzzo, A. Ritter, and L. Wang, Eds., Association for Computational Linguistics, pp. 4145–4157
work page 2025
-
[18]
Huang, L., Yu, W., Ma, W., Zhong, W., Feng, Z., W ang, H., Chen, Q., Peng, W., Feng, X., Qin, B., and Liu, T.A survey on hallucination in large language models: Principles, taxonomy, challenges, and open questions.ACM Transactions on Information Systems 43, 2 (Jan. 2025), 1–55
work page 2025
-
[19]
Incitti, F., Urli, F., and Snidaro, L.Beyond word embeddings: A survey.Information Fusion 89(2023), 418–436
work page 2023
-
[20]
Ismaeel, A. Z., and Zebari, I. M.Comparing traversal strategies: Depth-first search vs. breadth- first search in complex networks.Asian Journal of Research in Computer Science 18, 2 (2025), 60–73
work page 2025
-
[21]
Knollmeyer, S., Caymazer, O., and Grossmann, D.Document graphrag: knowledge graph enhanced retrieval augmented generation for document question answering within the manufacturing domain.Electronics 14, 11 (2025), 2102
work page 2025
-
[22]
Kraišniković, C., Harb, R., Plass, M., Al Zoughbi, W., Holzinger, A., and Müller, H.Fine-tuning language model embeddings to reveal domain knowledge: An explainable artificial intelligence perspective on medical decision making.Engineering Applications of Artificial Intelligence 139(2025), 109561
work page 2025
-
[23]
LangChain. Graph rag retriever. https://docs.langchain.com/oss/python/integrations/ retrievers/graph_rag. Accessed: 2026-03-02
work page 2026
- [24]
-
[25]
InProceedings of the 2021 conference on empirical methods in natural language processing (2021), pp
Lester, B., Al-Rfou, R., and Constant, N.The power of scale for parameter-efficient prompt tuning. InProceedings of the 2021 conference on empirical methods in natural language processing (2021), pp. 3045–3059
work page 2021
-
[26]
Lewis, P., Perez, E., Piktus, A., Petroni, F., Karpukhin, V., Goyal, N., Küttler, H., Lewis, M., Yih, W.-t., Rocktäschel, T., et al.Retrieval-augmented generation for knowledge- intensive nlp tasks.Advances in neural information processing systems 33(2020), 9459–9474
work page 2020
-
[27]
L., and Liang, P.Prefix-tuning: Optimizing continuous prompts for generation
Li, X. L., and Liang, P.Prefix-tuning: Optimizing continuous prompts for generation. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)(2021), pp. 4582–4597
work page 2021
-
[28]
Li, Y., Chen, H., Li, Y., Li, L., Yu, P. S., and Xu, G.Reinforcement learning based path exploration for sequential explainable recommendation.IEEE Transactions on Knowledge and Data Engineering 35, 11 (2023), 11801–11814
work page 2023
- [29]
-
[30]
Liu, A., Feng, B., Xue, B., W ang, B., Wu, B., Lu, C., Zhao, C., Deng, C., Zhang, C., Ruan, C., et al.Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[31]
Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., and Liang, P.Lost in the middle: How language models use long contexts.Transactions of the Association for Computational Linguistics 12(2024), 157–173
work page 2024
-
[32]
Meta AI. The Llama 3 Herd of Models. https://ai.meta.com/research/publications/ the-llama-3-herd-of-models/, 2024
work page 2024
-
[33]
Microsoft Research. Welcome to graphrag. https://microsoft.github.io/graphrag/, 2024. Accessed: 2026-03-02. [34]OpenAI. Gpt-4 technical report, 2024
work page 2024
-
[34]
Peng, B., Zhu, Y., Liu, Y., Bo, X., Shi, H., Hong, C., Zhang, Y., and Tang, S.Graph retrieval-augmented generation: A survey.ACM Trans. Inf. Syst. 44, 2 (Dec. 2025)
work page 2025
-
[35]
J.Exploring the limits of transfer learning with a unified text-to-text transformer
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y., Li, W., and Liu, P. J.Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of machine learning research 21, 140 (2020), 1–67
work page 2020
-
[36]
rajeh et al.Quality & Quantity 57, 2 (2023), 1273–1302
Rajeh, S., Savonnet, M., Leclercq, E., and Cherifi, H.Comparative evaluation of community- aware centrality measures: S. rajeh et al.Quality & Quantity 57, 2 (2023), 1273–1302. [38]RuleX.Rulex Platform Documentation, Version 1.4.x, 2025
work page 2023
-
[37]
A., and Dernon- court, F.PDFTriage: Question answering over long, structured documents
Saad-F alcon, J., Barrow, J., Siu, A., Nenkova, A., Yoon, S., Rossi, R. A., and Dernon- court, F.PDFTriage: Question answering over long, structured documents. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: Industry Track(Miami, Florida, US, Nov. 2024), F. Dernoncourt, D. Preoţiuc-Pietro, and A. Shimorina, Eds., ...
work page 2024
-
[38]
DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models
Shao, Z., W ang, P., Zhu, Q., Xu, R., Song, J., Bi, X., Zhang, H., Zhang, M., Li, Y., Wu, Y., et al.Deepseekmath: Pushing the limits of mathematical reasoning in open language models. arXiv preprint arXiv:2402.03300(2024)
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[39]
Tan, Y., Zhou, Z., L v, H., Liu, W., and Yang, C.Walklm: A uniform language model fine-tuning framework for attributed graph embedding.Advances in neural information processing systems 36(2023), 13308–13325
work page 2023
-
[40]
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M.-A., Lacroix, T., Rozière, B., Goyal, N., Hambro, E., Azhar, F., and et al.Llama: Open and efficient foundation language models.arXiv preprint arXiv:2302.13971(2023)
work page internal anchor Pith review Pith/arXiv arXiv 2023
- [41]
-
[42]
Xiao, T., and Zhu, J.Natural Language Processing: Neural Networks and Large Language Models. NiuTrans, 2025
work page 2025
- [43]
-
[44]
Zhou, Z., Tarzanagh, D. A., Didari, S., Hu, W., Gutow, B., Verkholyak, O., F araki, M., Hao, H., Moon, H., and Min, S.Query-aware flow diffusion for graph-based rag with retrieval guarantees. InThe Fourteenth International Conference on Learning Representations. 22 A Prompt templates This appendix reports the full text of the four prompt templates used in...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.