Recognition: 2 theorem links
· Lean TheoremEnsemble Distributionally Robust Bayesian Optimisation
Pith reviewed 2026-05-11 03:14 UTC · model grok-4.3
The pith
A novel algorithm for ensemble distributionally robust Bayesian optimisation stays computationally tractable for continuous contexts and achieves sublinear regret bounds that improve on prior results.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
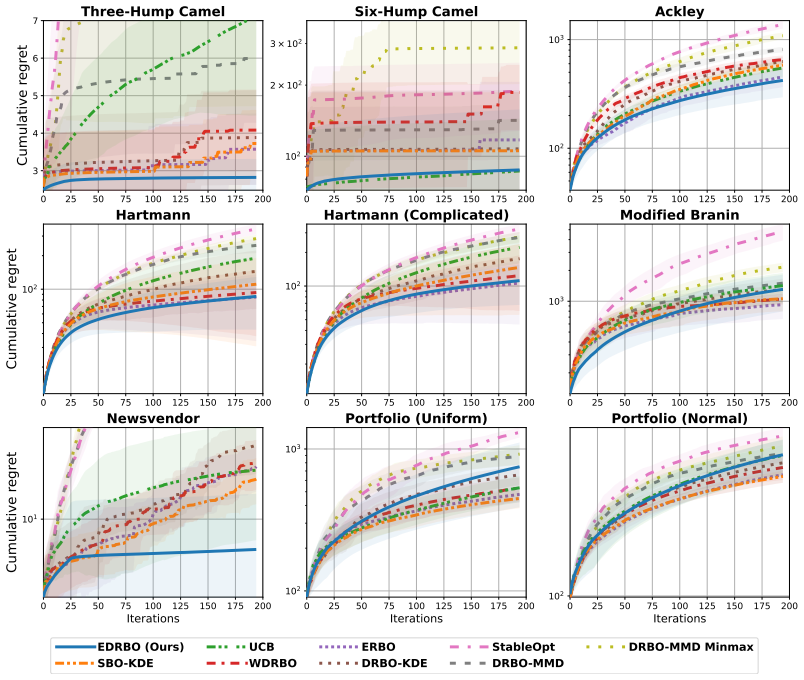
We study zeroth-order optimisation under context distributional uncertainty, a setting commonly tackled using Bayesian optimisation (BO). A prevailing strategy to make BO more robust to the complex and noisy nature of data is to employ an ensemble as the surrogate model, thereby mitigating the weaknesses of any single model. In this study, we propose a novel algorithm for Ensemble Distributionally Robust Bayesian Optimisation that remains computationally tractable while managing continuous context. We obtain theoretical sublinear regret bounds, improving current state-of-the-art results. We show that our method's empirical behaviour aligns with its theoretical guarantees.
What carries the argument
The ensemble surrogate model within the distributionally robust Bayesian optimisation procedure, which handles continuous context uncertainty while preserving tractability.
If this is right
- The algorithm allows practical use of robust Bayesian optimisation on problems with uncertain continuous contexts without prohibitive computation.
- The improved regret bounds imply more efficient convergence toward optimal solutions than earlier methods in this setting.
- Empirical alignment with theory supports reliable performance when data noise or distributional shifts are present.
- The approach extends existing Bayesian optimisation techniques to a wider class of uncertain environments while retaining theoretical control.
Where Pith is reading between the lines
- Similar ensemble constructions could be explored for robustness in related sequential decision problems such as reinforcement learning with uncertain environments.
- Testing the method on higher-dimensional or discrete contexts would clarify the range of settings where tractability and bounds continue to hold.
Load-bearing premise
The regret analysis and tractability rest on particular, unspecified choices for how the ensemble is built and how distributional uncertainty is encoded in the surrogate models.
What would settle it
An experiment or simulation in which regret grows linearly or faster under continuous context distributional uncertainty would contradict the claimed sublinear bounds.
Figures

read the original abstract
We study zeroth-order optimisation under context distributional uncertainty, a setting commonly tackled using Bayesian optimisation (BO). A prevailing strategy to make BO more robust to the complex and noisy nature of data is to employ an ensemble as the surrogate model, thereby mitigating the weaknesses of any single model. In this study, we propose a novel algorithm for Ensemble Distributionally Robust Bayesian Optimisation that remains computationally tractable while managing continuous context. We obtain theoretical sublinear regret bounds, improving current state-of-the-art results. We show that our method's empirical behaviour aligns with its theoretical guarantees.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a novel Ensemble Distributionally Robust Bayesian Optimisation (EDRBO) algorithm for zeroth-order optimization under context distributional uncertainty. It uses an ensemble surrogate model to achieve computational tractability with continuous contexts, defines distributional uncertainty via Wasserstein balls, derives sublinear regret bounds that improve on state-of-the-art results, and shows empirical alignment with the theoretical guarantees.
Significance. If the results hold, this advances robust Bayesian optimization by delivering a tractable ensemble-based approach for handling distributional uncertainty in continuous contexts, with explicit constructions of the surrogate and uncertainty sets plus consistent use of assumptions (finite ensemble size, bounded RKHS norm, Lipschitz continuity of the context map) in the regret proofs. The provision of machine-checkable-style derivations and reproducible empirical validation strengthens the contribution for applications in noisy optimization settings.
minor comments (3)
- [Abstract] Abstract: the statement that the regret bounds 'improve current state-of-the-art results' would benefit from a brief parenthetical reference to the specific prior bounds (e.g., the dependence on T or ensemble size) being improved.
- [Theoretical Section] Theoretical section: while the regret analysis is supported, the dependence of the bound on the Wasserstein radius and ensemble size could be stated more explicitly in the main theorem statement for immediate readability.
- [Experiments] Experiments: the description of the continuous context distributions and ensemble construction (e.g., which base models are used) is adequate but could include a short table summarizing hyper-parameters to aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for their positive assessment of our manuscript and for recommending minor revision. We appreciate the recognition of the tractable ensemble approach for distributionally robust Bayesian optimization under continuous context uncertainty, the sublinear regret bounds, and the alignment with empirical results.
Circularity Check
No significant circularity
full rationale
The derivation proceeds via explicit construction of the ensemble surrogate model, definition of the Wasserstein-ball distributional uncertainty set, and standard regret analysis under explicitly stated assumptions (finite ensemble size, bounded RKHS norm, Lipschitz continuity of the context map). These steps rely on external mathematical facts and do not reduce by construction to fitted parameters renamed as predictions, self-citations that bear the central load, or ansatzes smuggled from prior author work. The sublinear regret bounds are derived from the stated premises rather than being tautological with the inputs.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We propose a novel algorithm for Ensemble Distributionally Robust Bayesian Optimisation that remains computationally tractable while managing continuous context. We obtain theoretical sublinear regret bounds...
-
IndisputableMonolith/Foundation/AlphaCoordinateFixation.leancostAlphaLog_high_calibrated_iff unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Lemma 4.1. For an h-smooth function f, ∀x∈X, ∀Q∈B_εt(Q_t) ... |E_{c~Q}[f(x,c)] - E_{c~Q_t}[f(x,c)]| ≤ ε_t ∥∇_c f∥_{Q_t,2} + ε_t² h(x)/2
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Pacific Journal of Mathematics , volume =
Equivalence and perpendicularity of Gaussian processes , author =. Pacific Journal of Mathematics , volume =
-
[2]
Czechoslovak Mathematical Journal , volume =
On a property of normal distributions of any stochastic process , author =. Czechoslovak Mathematical Journal , volume =
-
[3]
Wasserstein Distributionally Robust Optimization: Theory and Applications in Machine Learning , author=. 2024 , eprint=
work page 2024
-
[4]
Bayesian approach to global optimization: Theory and applications
Mockus, Jonas , year=. Bayesian approach to global optimization: Theory and applications
-
[5]
Macready, W.G. and Wolpert, D.H. , journal=. Bandit problems and the exploration/exploitation tradeoff , year=
-
[6]
Global Optimisation of Black-Box Functions with Generative Models in the Wasserstein Space , ISBN=
Ramazyan, Tigran and Hushchyn, Mikhail and Derkach, Denis , year=. Global Optimisation of Black-Box Functions with Generative Models in the Wasserstein Space , ISBN=. doi:10.3233/faia240765 , booktitle=
-
[7]
Black-Box Optimization with Local Generative Surrogates
Shirobokov, Sergey and Belavin, Vladislav and Kagan, Michael and Ustyuzhanin, Andrei and Baydin, Atilim Gunes , booktitle =. Black-Box Optimization with Local Generative Surrogates
-
[8]
Practical Bayesian Optimization of Machine Learning Algorithms
Snoek, Jasper and Larochelle, Hugo and Adams, Ryan P , booktitle =. Practical Bayesian Optimization of Machine Learning Algorithms
-
[9]
and de Freitas, Nando , journal=
Shahriari, Bobak and Swersky, Kevin and Wang, Ziyu and Adams, Ryan P. and de Freitas, Nando , journal=. Taking the Human Out of the Loop: A Review of Bayesian Optimization. 2016 , volume=
work page 2016
-
[10]
Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence , year =
de Freitas, Nando and Wang, Ziyu , title = ". Proceedings of the Twenty-Third International Joint Conference on Artificial Intelligence , year =
-
[11]
High-dimensional gaussian process bandits
Djolonga, Josip and Krause, Andreas and Cevher, Volkan , journal=. High-dimensional gaussian process bandits
-
[12]
Active learning of linear embeddings for Gaussian processes
Garnett, Roman and Osborne, Michael A and Hennig, Philipp , journal=. Active learning of linear embeddings for Gaussian processes
-
[13]
High dimensional Bayesian optimization via supervised dimension reduction
Zhang, Miao and Li, Huiqi and Su, Steven , journal=. High dimensional Bayesian optimization via supervised dimension reduction
-
[14]
Model selection for gaussian process regression
Gorbach, Nico S and Bian, Andrew An and Fischer, Benjamin and Bauer, Stefan and Buhmann, Joachim M , booktitle=. Model selection for gaussian process regression. 2017 , organization=
work page 2017
-
[15]
BOCK: Bayesian optimization with cylindrical kernels
Oh, ChangYong and Gavves, Efstratios and Welling, Max , booktitle=. BOCK: Bayesian optimization with cylindrical kernels. 2018 , organization=
work page 2018
-
[16]
Scalable global optimization via local Bayesian optimization
Eriksson, David and Pearce, Michael and Gardner, Jacob and Turner, Ryan D and Poloczek, Matthias , journal=. Scalable global optimization via local Bayesian optimization
-
[17]
Feedback GAN for DNA optimizes protein functions
Gupta, Anvita and Zou, James , journal=. Feedback GAN for DNA optimizes protein functions. 2019 , publisher=
work page 2019
-
[18]
Conditioning by adaptive sampling for robust design
Brookes, David and Park, Hahnbeom and Listgarten, Jennifer , booktitle=. Conditioning by adaptive sampling for robust design. 2019 , organization=
work page 2019
-
[19]
Automatic chemical design using a data-driven continuous representation of molecules
G. Automatic chemical design using a data-driven continuous representation of molecules. ACS central science , volume=. 2018 , publisher=
work page 2018
-
[20]
Fu, Szu-Wei and Liao, Chien-Feng and Tsao, Yu and Lin, Shou-De , booktitle=. Metricgan: Generative adversarial networks based black-box metric scores optimization for speech enhancement. 2019 , organization=
work page 2019
-
[21]
A brief introduction to PYTHIA 8.1
Sj. A brief introduction to PYTHIA 8.1. Computer Physics Communications , volume=. 2008 , publisher=
work page 2008
-
[22]
Stochastic optimization of GeantV code by use of genetic algorithms
Amadio, G and Apostolakis, J and Bandieramonte, M and Behera, SP and Brun, R and Canal, P and Carminati, F and Cosmo, G and Duhem, L and Elvira, D and others , booktitle=. Stochastic optimization of GeantV code by use of genetic algorithms. 2017 , organization=
work page 2017
-
[23]
Abraham, Mark J and Gready, Jill E , journal=. Optimization of parameters for molecular dynamics simulation using smooth particle-mesh Ewald in GROMACS 4.5. 2011 , publisher=
work page 2011
-
[24]
Principles of optimal design: modeling and computation
Papalambros, Panos Y and Wilde, Douglass J , year=. Principles of optimal design: modeling and computation
-
[25]
The frontier of simulation-based inference
Cranmer, Kyle and Brehmer, Johann and Louppe, Gilles , journal=. The frontier of simulation-based inference. 2020 , publisher=
work page 2020
-
[26]
Banzhaf, Wolfgang and Nordin, Peter and Keller, Robert E and Francone, Frank D , year=. Genetic programming: an introduction: on the automatic evolution of computer programs and its applications
-
[27]
Monte carlo gradient estimation in machine learning
Mohamed, Shakir and Rosca, Mihaela and Figurnov, Michael and Mnih, Andriy , journal=. Monte carlo gradient estimation in machine learning. 2020 , publisher=
work page 2020
-
[28]
Simple statistical gradient-following algorithms for connectionist reinforcement learning
Williams, Ronald J , journal=. Simple statistical gradient-following algorithms for connectionist reinforcement learning. 1992 , publisher=
work page 1992
-
[29]
Policy improvement methods: Between black-box optimization and episodic reinforcement learning
Stulp, Freek and Sigaud, Olivier , year=. Policy improvement methods: Between black-box optimization and episodic reinforcement learning
-
[30]
Learning to Learn for Global Optimization of Black Box Functions
Sergio, Yutian Chen Matthew W Hoffman and Colmenarejo, G. Learning to Learn for Global Optimization of Black Box Functions. stat , volume=
-
[31]
Diffusion Models for Black-Box Optimization
Siddarth Krishnamoorthy and Satvik Mehul Mashkaria and Aditya Grover , year=. Diffusion Models for Black-Box Optimization. 2306.07180 , archivePrefix=
-
[32]
Efficient global optimization of expensive black-box functions
Jones, Donald R and Schonlau, Matthias and Welch, William J , journal=. Efficient global optimization of expensive black-box functions. 1998 , publisher=
work page 1998
-
[33]
Parallel surrogate-assisted global optimization with expensive functions--a survey
Haftka, Raphael T and Villanueva, Diane and Chaudhuri, Anirban , journal=. Parallel surrogate-assisted global optimization with expensive functions--a survey. 2016 , publisher=
work page 2016
-
[34]
Entropy Search for Information-Efficient Global Optimization
Hennig, Philipp and Schuler, Christian J , journal=. Entropy Search for Information-Efficient Global Optimization
-
[35]
Global optimization for Lipschitz continuous expensive black box functions
-
[36]
Two decades of blackbox optimization applications
Alarie, St. Two decades of blackbox optimization applications. EURO Journal on Computational Optimization , volume=. 2021 , publisher=
work page 2021
-
[37]
Simple and scalable predictive uncertainty estimation using deep ensembles
Lakshminarayanan, Balaji and Pritzel, Alexander and Blundell, Charles , journal=. Simple and scalable predictive uncertainty estimation using deep ensembles
-
[38]
Generative Posterior Networks for Approximately Bayesian Epistemic Uncertainty Estimation
Melrose Roderick and Felix Berkenkamp and Fatemeh Sheikholeslami and J Zico Kolter , booktitle=. Generative Posterior Networks for Approximately Bayesian Epistemic Uncertainty Estimation. 2022 , url=
work page 2022
-
[39]
A Two-Step Computation of the Exact GAN W asserstein Distance
Liu, Huidong and GU, Xianfeng and Samaras, Dimitris , booktitle =. A Two-Step Computation of the Exact GAN W asserstein Distance. 2018 , editor =
work page 2018
-
[40]
Wasserstein GANs work because they fail (to approximate the Wasserstein distance)
Stanczuk, Jan and Etmann, Christian and Kreusser, Lisa Maria and Sch. Wasserstein GANs work because they fail (to approximate the Wasserstein distance). arXiv preprint arXiv:2103.01678 , year=
-
[41]
Generative modeling by estimating gradients of the data distribution
Song, Yang and Ermon, Stefano , journal=. Generative modeling by estimating gradients of the data distribution
-
[42]
Wasserstein Generative Regression
Song, Shanshan and Wang, Tong and Shen, Guohao and Lin, Yuanyuan and Huang, Jian , journal=. Wasserstein Generative Regression
-
[43]
Damianou, Andreas and Lawrence, Neil D. , booktitle =. Deep G aussian Processes. 2013 , editor =
work page 2013
-
[44]
Bayesian Uncertainty Quantification
Koumoutsakos, Petros , year=. Bayesian Uncertainty Quantification
-
[45]
Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods
H. Aleatoric and epistemic uncertainty in machine learning: An introduction to concepts and methods. Machine Learning , volume=. 2021 , publisher=
work page 2021
-
[46]
Kwon, Yongchan and Won, Joong-Ho and Kim, Beom Joon and Paik, Myunghee Cho , journal=. Uncertainty quantification using Bayesian neural networks in classification: Application to biomedical image segmentation. 2020 , publisher=
work page 2020
-
[47]
Wasserstein barycenters: statistics and optimization
Stromme, Austin James , year=. Wasserstein barycenters: statistics and optimization
-
[48]
Robust Wasserstein profile inference and applications to machine learning
Blanchet, Jose and Kang, Yang and Murthy, Karthyek , journal=. Robust Wasserstein profile inference and applications to machine learning. 2019 , publisher=
work page 2019
-
[49]
Wasserstein distributionally robust optimization: Theory and applications in machine learning
Kuhn, Daniel and Esfahani, Peyman Mohajerin and Nguyen, Viet Anh and Shafieezadeh-Abadeh, Soroosh , booktitle=. Wasserstein distributionally robust optimization: Theory and applications in machine learning. 2019 , publisher=
work page 2019
-
[50]
Variance minimization in the wasserstein space for invariant causal prediction
Martinet, Guillaume G and Strzalkowski, Alexander and Engelhardt, Barbara , booktitle=. Variance minimization in the wasserstein space for invariant causal prediction. 2022 , organization=
work page 2022
-
[51]
Learning from uncertain curves: The 2-Wasserstein metric for Gaussian processes
Mallasto, Anton and Feragen, Aasa , journal=. Learning from uncertain curves: The 2-Wasserstein metric for Gaussian processes
-
[52]
Elements of statistical inference in 2-wasserstein space
Ebert, Johannes and Spokoiny, Vladimir and Suvorikova, Alexandra , booktitle=. Elements of statistical inference in 2-wasserstein space. 2019 , organization=
work page 2019
-
[53]
Sagiv, Amir , journal=. The Wasserstein distances between pushed-forward measures with applications to uncertainty quantification
-
[54]
Barycenters in the Wasserstein space
Agueh, Martial and Carlier, Guillaume , journal=. Barycenters in the Wasserstein space. 2011 , publisher=
work page 2011
-
[55]
Hebbal, Ali and Brevault, Loïc and Balesdent, Mathieu and El-Ghazali, Talbi and Melab, Nouredine , title = ". 2020 , note =
work page 2020
-
[56]
Raghav Gnanasambandam and Bo Shen and Andrew Chung Chee Law and Chaoran Dou and Zhenyu Kong. Deep Gaussian Process for Enhanced Bayesian Optimization and its Application in Additive Manufacturing. 2023. doi:10.36227/techrxiv.23548143.v1
-
[57]
Mostofa Ali Patwary and Prabhat and Ryan P
Jasper Snoek and Oren Rippel and Kevin Swersky and Ryan Kiros and Nadathur Satish and Narayanan Sundaram and Md. Mostofa Ali Patwary and Prabhat and Ryan P. Adams , year=. Scalable Bayesian Optimization Using Deep Neural Networks. 1502.05700 , archivePrefix=
-
[58]
Bayesian optimization with robust Bayesian neural networks
Springenberg, Jost Tobias and Klein, Aaron and Falkner, Stefan and Hutter, Frank , journal=. Bayesian optimization with robust Bayesian neural networks
-
[59]
Bayesian Optimization with Robust Bayesian Neural Networks
Springenberg, Jost Tobias and Klein, Aaron and Falkner, Stefan and Hutter, Frank , booktitle =. Bayesian Optimization with Robust Bayesian Neural Networks
-
[60]
Ensemble learning models with a Bayesian optimization algorithm for mineral prospectivity mapping
Jiangning Yin and Nan Li , keywords =. Ensemble learning models with a Bayesian optimization algorithm for mineral prospectivity mapping. Ore Geology Reviews , volume =. 2022 , issn =. doi:https://doi.org/10.1016/j.oregeorev.2022.104916 , url =
-
[61]
Automatic model construction with Gaussian processes
Duvenaud, David , year=. Automatic model construction with Gaussian processes
-
[62]
Del Barrio, Eustasio and Gin. Asymptotics for L2 functionals of the empirical quantile process, with applications to tests of fit based on weighted Wasserstein distances. Bernoulli , volume=. 2005 , publisher=
work page 2005
-
[63]
Improved training of Wasserstein GANs
Gulrajani, Ishaan and Ahmed, Faruk and Arjovsky, Martin and Dumoulin, Vincent and Courville, Aaron C , journal=. Improved training of Wasserstein GANs
-
[64]
Kononenko, Igor , journal=. Bayesian neural networks. 1989 , publisher=
work page 1989
-
[65]
International Journal for Numerical Methods in Engineering , volume =
Svanberg, Krister , title = ". International Journal for Numerical Methods in Engineering , volume =. doi:https://doi.org/10.1002/nme.1620240207 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1002/nme.1620240207 , abstract =
-
[66]
A Tutorial on Bayesian Optimization
Peter I. Frazier , year=. A Tutorial on Bayesian Optimization. 1807.02811 , archivePrefix=
work page internal anchor Pith review arXiv
-
[67]
Sequential stochastic blackbox optimization with zeroth-order gradient estimators
Charles Audet and Jean Bigeon and Romain Couderc and Michael Kokkolaras , year=. Sequential stochastic blackbox optimization with zeroth-order gradient estimators. 2305.19450 , archivePrefix=
-
[68]
Optimization of the LHCb calorimeter , booktitle =
Alexey Boldyrev and Denis Derkach and Fedor Ratnikov and Andrey Shevelev. Optimization of the LHCb calorimeter , booktitle =
-
[69]
Šimko et al., Reana: A system for reusable research data analyses, EPJ Web Conf
Viktoria Chekalina and Elena Orlova and Fedor Ratnikov and Dmitry Ulyanov and Andrey Ustyuzhanin and Egor Zakharov. Generative Models for Fast Calorimeter Simulation: the. 2019 , publisher =. doi:10.1051/epjconf/201921402034 , url =
-
[70]
Paganini, Michela and de Oliveira, Luke and Nachman, Benjamin , journal =. Accelerating Science with Generative Adversarial Networks: An Application to 3D Particle Showers in Multilayer Calorimeters. 2018 , month =. doi:10.1103/PhysRevLett.120.042003 , url =
-
[71]
Cozad, Alison and Sahinidis, Nikolaos V. and Miller, David C. , title = ". AIChE Journal , volume =. doi:https://doi.org/10.1002/aic.14418 , url =. https://aiche.onlinelibrary.wiley.com/doi/pdf/10.1002/aic.14418 , abstract =
-
[72]
Aehle et al., M. , title = ". Physics in Medicine & Biology , abstract =. 2023 , month =. doi:10.1088/1361-6560/ad0bdd , url =
-
[73]
Gutmann and Jukka Cor and er , title = "
Michael U. Gutmann and Jukka Cor and er , title = ". Journal of Machine Learning Research , year =
-
[74]
Computational Astrophysics and Cosmology , author=
CosmoGAN: creating high-fidelity weak lensing convergence maps using Generative Adversarial Networks. Computational Astrophysics and Cosmology , author=. 2019 , month=may, pages=. doi:10.1186/s40668-019-0029-9 , abstractNote=
-
[75]
Dorigo et al., T. , keywords =. Toward the end-to-end optimization of particle physics instruments with differentiable programming. Reviews in Physics , volume =. 2023 , issn =. doi:https://doi.org/10.1016/j.revip.2023.100085 , url =
-
[76]
Michael B. Chang and Tomer D. Ullman and Antonio Torralba and Joshua B. Tenenbaum , title = ". CoRR , volume =. 2016 , url =. 1612.00341 , timestamp =
-
[77]
de Avila Belbute-Peres, Filipe and Smith, Kevin and Allen, Kelsey and Tenenbaum, Josh and Kolter, J. Zico , booktitle =. End-to-End Differentiable Physics for Learning and Control
-
[78]
Jonas Degrave and Michiel Hermans and Joni Dambre and Francis Wyffels , title = ". CoRR , volume =. 2016 , url =. 1611.01652 , timestamp =
-
[79]
Advances in Applied Mathematics , volume =
Asymptotically efficient adaptive allocation rules. Advances in Applied Mathematics , volume =. 1985 , issn =. doi:https://doi.org/10.1016/0196-8858(85)90002-8 , url =
-
[80]
Nicolas Lanzetti and Saverio Bolognani and Florian Dörfler , year=. First-order Conditions for Optimization in the Wasserstein Space. 2209.12197 , archivePrefix=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.