Recognition: 2 theorem links
· Lean TheoremTracing the Arrow of Time: Diagnosing Temporal Information Flow in Video-LLMs
Pith reviewed 2026-05-11 03:01 UTC · model grok-4.3
The pith
Video-LLMs lose temporal signals in the projector, not the encoder, and fixing the projector enables superhuman accuracy on video direction tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that temporal reasoning in Video-LLMs demands both effective temporal encoding inside the vision backbone and reliable transfer of that information through the projector to the LLM. Video-centric encoders supply clear temporal signals, but common projectors such as the Q-Former create a bottleneck that erases them. Replacing the projector with a time-preserved MLP restores the signals, and adding explicit Arrow of Time supervision produces a model that exceeds human performance on AoT_PPB at 98.1 percent accuracy while lifting results on VITATECS-Direction by up to 6 points and on TVBench by 1.3 points.
What carries the argument
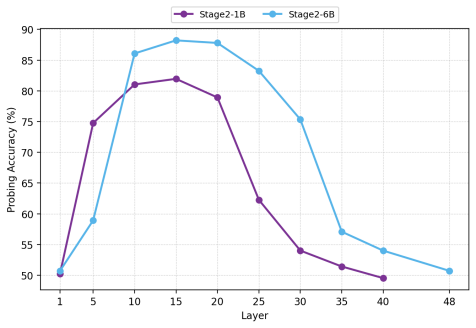
Layer-wise tracing of temporal signals from encoder through projector to LLM, with the time-preserved MLP acting as the component that maintains order information during transfer.
If this is right
- Video-centric encoders with explicit temporal modeling are required to generate usable time signals.
- Projector choice controls whether those signals reach the language model intact.
- Explicit Arrow of Time supervision can refine the model's use of the transferred information.
- Gains from restored information flow extend to other temporal benchmarks such as direction judgment and video understanding tasks.
Where Pith is reading between the lines
- Projectors that preserve order may help other multimodal models retain causal or spatial signals that standard connectors currently dilute.
- The same tracing approach could diagnose bottlenecks in longer video sequences or multi-step temporal reasoning.
- Layer-wise temporal dynamics observed in encoders suggest targeted improvements to early or late layers for specific time scales.
Load-bearing premise
That observed performance drops with standard projectors and gains with time-preserved MLPs stem specifically from changes in temporal information flow rather than from other uncontrolled differences in training or architecture.
What would settle it
Train the improved Video-LLM with the time-preserved MLP but replace its temporal features with shuffled frame order and measure whether accuracy on AoT_PPB falls back near chance levels.
Figures






read the original abstract
The Arrow-of-Time (AoT) task, determining whether a video plays forward or backward by recognizing temporal irreversibility, is one humans solve with near-perfect accuracy, yet frontier Video Large Language Models (Video-LLMs) perform only modestly above chance. This gap raises a key question: do visual backbones fail to encode temporal information, or does information bottleneck lie elsewhere in the Video-LLM architecture? We address this question by isolating the vision encoder from the Video-LLM and tracing temporal information across the encoder, projector, and LLM. We find that video-centric encoders with explicit temporal modeling encode strong temporal signals, whereas frame-centric encoders do not. However, when video-centric representations are passed through a standard Video-LLM architecture, performance often collapses, revealing a bottleneck of temporal information flow. We identify projector design as a key factor: Q-Former disrupts temporal information, while a time-preserved MLP projection substantially improves the LLM's access to such information. Our layer-wise analysis further shows temporal representation dynamics across encoder layers. Guided by these findings, we build a Video-LLM with temporal-aware video-centric encoder, time-preserved projector, and AoT supervision, surpassing human performance on AoT$_{PPB}$ with 98.1\% accuracy, and improving broader temporal reasoning tasks by up to 6.0 points on VITATECS-Direction and 1.3 points on TVBench. Our results show that temporal reasoning in Video-LLMs requires both effective temporal encoding and reliable transfer of this information to the LLM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that Video-LLMs underperform on Arrow-of-Time (AoT) tasks because video-centric encoders encode strong temporal signals but standard projectors (e.g., Q-Former) create an information bottleneck that prevents reliable transfer to the LLM; a time-preserved MLP projector mitigates this. By tracing information flow across encoder, projector, and LLM components and adding AoT supervision, the authors construct a Video-LLM that reaches 98.1% accuracy on AoT_PPB (surpassing humans) and improves other temporal reasoning benchmarks by up to 6.0 points.
Significance. If the causal isolation of temporal flow holds, the work supplies a concrete diagnostic method for locating architectural bottlenecks in Video-LLMs and demonstrates that modest, targeted changes to the projector and supervision can yield large gains on temporal tasks. The use of external benchmarks (VITATECS-Direction, TVBench) provides independent grounding beyond the AoT_PPB metric, and the reported 98.1% accuracy constitutes a strong empirical result if the controls are sufficient.
major comments (1)
- [projector ablation and component-isolation experiments] The projector ablation (described in the abstract and the component-isolation experiments) attributes performance collapse with Q-Former and recovery with the time-preserved MLP specifically to disruption versus preservation of temporal information. However, Q-Former and MLP differ in parameter count, sequence handling, attention mechanisms, and training dynamics; no parameter-matched MLP baseline, identical optimizer schedules, or direct temporal probes (e.g., linear classifiers on pre- versus post-projector features for frame-order discrimination) are reported. This leaves open the possibility that observed differences arise from capacity or optimization factors rather than temporal flow per se, weakening the central diagnostic claim.
minor comments (2)
- [Abstract and results] The abstract and results sections report concrete accuracy numbers without visible error bars, standard deviations, or statistical significance tests; adding these would strengthen verifiability of the reported gains.
- [Methods] Methods details on training schedules, exact hyper-parameters for the time-preserved MLP, and full layer-probe protocols are not fully visible in the provided summary; expanding the methods section would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address the major comment below and outline the revisions we will make to strengthen the diagnostic claims.
read point-by-point responses
-
Referee: [projector ablation and component-isolation experiments] The projector ablation (described in the abstract and the component-isolation experiments) attributes performance collapse with Q-Former and recovery with the time-preserved MLP specifically to disruption versus preservation of temporal information. However, Q-Former and MLP differ in parameter count, sequence handling, attention mechanisms, and training dynamics; no parameter-matched MLP baseline, identical optimizer schedules, or direct temporal probes (e.g., linear classifiers on pre- versus post-projector features for frame-order discrimination) are reported. This leaves open the possibility that observed differences arise from capacity or optimization factors rather than temporal flow per se, weakening the central diagnostic claim.
Authors: We agree that the current ablations leave room for alternative explanations based on capacity or optimization differences. Our component-isolation experiments trace temporal signals from the video-centric encoder (which retains strong frame-order information) through the projector to the LLM, with clear collapse after the Q-Former but recovery with the time-preserved MLP. The MLP is explicitly constructed to process frames without cross-frame attention mixing, unlike the Q-Former. However, we did not report a parameter-matched MLP baseline, identical optimizer schedules, or direct linear probes on pre- versus post-projector features. In the revision we will add (i) linear classifier probes trained on frozen pre- and post-projector features to measure frame-order discrimination accuracy and (ii) a capacity-controlled MLP variant matched in parameter count to the Q-Former. These additions will more rigorously isolate the contribution of temporal preservation. revision: partial
Circularity Check
No significant circularity; empirical isolation and external benchmarks provide independent grounding
full rationale
The paper's derivation traces temporal information flow via explicit experiments that isolate the vision encoder, projector, and LLM components, measuring performance collapse and recovery on held-out benchmarks such as AoT_PPB, VITATECS-Direction, and TVBench. These results are not obtained by fitting parameters to the target metric and then relabeling the fit as a prediction, nor do any equations or self-citations reduce the claimed bottlenecks to definitional tautologies. The final model is constructed from the diagnostic observations but evaluated on independent tasks, yielding accuracies that exceed human baselines without circular reduction. Minor self-citations to prior Video-LLM architectures exist but are not load-bearing for the central claims.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard assumptions in deep learning hold for Video-LLM training and evaluation on the cited benchmarks.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/ArrowOfTime.leanarrow_from_z unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We identify projector design as a key factor: Q-Former disrupts temporal information, while a time-preserved MLP projection substantially improves the LLM's access to such information.
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
video-centric encoders with explicit temporal modeling encode strong temporal signals
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
V-JEPA 2: Self-Supervised Video Models Enable Understanding, Prediction and Planning
Mido Assran, Adrien Bardes, David Fan, Quentin Garrido, Russell Howes, Matthew Muckley, Ammar Rizvi, Claire Roberts, Koustuv Sinha, Artem Zholus, et al. V-jepa 2: Self-supervised video models enable understanding, prediction and planning.arXiv preprint arXiv:2506.09985, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2...
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
Frozen in time: A joint video and image encoder for end-to-end retrieval
Max Bain, Arsha Nagrani, Gül Varol, and Andrew Zisserman. Frozen in time: A joint video and image encoder for end-to-end retrieval. InIEEE International Conference on Computer Vision, 2021
work page 2021
-
[4]
Revisiting Feature Prediction for Learning Visual Representations from Video
Adrien Bardes, Quentin Garrido, Jean Ponce, Michael Rabbat, Yann LeCun, Mahmoud Assran, and Nicolas Ballas. Revisiting feature prediction for learning visual representations from video.arXiv:2404.08471, 2024
work page internal anchor Pith review arXiv 2024
-
[5]
Perception encoder: The best visual embeddings are not at the output of the network
Daniel Bolya, Po-Yao Huang, Peize Sun, Jang Hyun Cho, Andrea Madotto, Chen Wei, Tengyu Ma, Jiale Zhi, Jathushan Rajasegaran, Hanoona Abdul Rasheed, Junke Wang, Marco Monteiro, Hu Xu, Shiyu Dong, Nikhila Ravi, Shang-Wen Li, Piotr Dollar, and Christoph Feichtenhofer. Perception encoder: The best visual embeddings are not at the output of the network. InThe ...
work page 2026
-
[6]
Intphys 2: Benchmarking intuitive physics understanding in complex synthetic environments, 2025
Florian Bordes, Quentin Garrido, Justine T Kao, Adina Williams, Michael Rabbat, and Emmanuel Dupoux. Intphys 2: Benchmarking intuitive physics understanding in complex synthetic environments.arXiv preprint arXiv:2506.09849, 2025
-
[7]
Revisiting the" video" in video-language understanding
Shyamal Buch, Cristóbal Eyzaguirre, Adrien Gaidon, Jiajun Wu, Li Fei-Fei, and Juan Carlos Niebles. Revisiting the" video" in video-language understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 2917–2927, 2022
work page 2022
-
[8]
Activitynet: A large-scale video benchmark for human activity understanding
Fabian Caba Heilbron, Victor Escorcia, Bernard Ghanem, and Juan Carlos Niebles. Activitynet: A large-scale video benchmark for human activity understanding. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2015
work page 2015
-
[9]
Honeybee: Locality-enhanced projector for multimodal llm
Junbum Cha, Wooyoung Kang, Jonghwan Mun, and Byungseok Roh. Honeybee: Locality-enhanced projector for multimodal llm. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
work page 2024
-
[10]
Vl-jepa: Joint em- bedding predictive architecture for vision-language,
Delong Chen, Mustafa Shukor, Theo Moutakanni, Willy Chung, Jade Yu, Tejaswi Kasarla, Yejin Bang, Allen Bolourchi, Yann LeCun, and Pascale Fung. Vl-jepa: Joint embedding predictive architecture for vision-language.arXiv preprint arXiv:2512.10942, 2025
-
[11]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185–24198, 2024
work page 2024
-
[12]
VideoLLaMA 2: Advancing Spatial-Temporal Modeling and Audio Understanding in Video-LLMs
Zesen Cheng, Sicong Leng, Hang Zhang, Yifei Xin, Xin Li, Guanzheng Chen, Yongxin Zhu, Wenqi Zhang, Ziyang Luo, Deli Zhao, et al. Videollama 2: Advancing spatial-temporal modeling and audio understanding in video-llms.arXiv preprint arXiv:2406.07476, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Physbench: Benchmarking and enhancing vision-language models for physical world understanding
Wei Chow, Jiageng Mao, Boyi Li, Daniel Seita, Vitor Guizilini, and Yue Wang. Physbench: Benchmarking and enhancing vision-language models for physical world understanding.arXiv preprint arXiv:2501.16411, 2025
-
[14]
Lost in time: A new temporal benchmark for videollms.arXiv preprint arXiv:2410.07752,
Daniel Cores, Michael Dorkenwald, Manuel Mucientes, Cees GM Snoek, and Yuki M Asano. Lost in time: A new temporal benchmark for videollms.arXiv preprint arXiv:2410.07752, 2024. 10
-
[15]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025
work page 2025
-
[16]
Do vision-language models have internal world models? towards an atomic evaluation
Qiyue Gao, Xinyu Pi, Kevin Liu, Junrong Chen, Ruolan Yang, Xinqi Huang, Xinyu Fang, Lu Sun, Gautham Kishore, Bo Ai, Stone Tao, Mengyang Liu, Jiaxi Yang, Chao-Jung Lai, Chuanyang Jin, Jiannan Xiang, Benhao Huang, Zeming Chen, David Danks, Hao Su, Tianmin Shu, Ziqiao Ma, Lianhui Qin, and Zhiting Hu. Do vision-language models have internal world models? towa...
-
[17]
Raghav Goyal, Samira Ebrahimi Kahou, Vincent Michalski, Joanna Materzynska, Susanne Westphal, Heuna Kim, Valentin Haenel, Ingo Fruend, Peter Yianilos, Moritz Mueller-Freitag, et al. The" something something" video database for learning and evaluating visual common sense. InProceedings of the IEEE international conference on computer vision, pages 5842–5850, 2017
work page 2017
-
[18]
Nao Hanyu, Kei Watanabe, and Shigeru Kitazawa. Ready to detect a reversal of time’s arrow: a psy- chophysical study using short video clips in daily scenes.Royal Society open science, 10(4):230036, 2023
work page 2023
-
[19]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
work page 2022
-
[20]
Peng Jin, Ryuichi Takanobu, Wancai Zhang, Xiaochun Cao, and Li Yuan. Chat-univi: Unified visual representation empowers large language models with image and video understanding. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 13700–13710, 2024
work page 2024
-
[21]
Interpreting physics in video world models.arXiv preprint arXiv:2602.07050, 2026
Sonia Joseph, Quentin Garrido, Randall Balestriero, Matthew Kowal, Thomas Fel, Shahab Bakhtiari, Blake Richards, and Mike Rabbat. Interpreting physics in video world models.arXiv preprint arXiv:2602.07050, 2026
-
[22]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, et al. The kinetics human action video dataset.arXiv preprint arXiv:1705.06950, 2017
work page internal anchor Pith review arXiv 2017
-
[23]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. Blip-2: Bootstrapping language-image pre-training with frozen image encoders and large language models. InInternational conference on machine learning, pages 19730–19742. PMLR, 2023
work page 2023
-
[24]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195–22206, 2024
work page 2024
-
[25]
Videochat: Chat-centric video understanding.Science China Information Sciences, 68(10): 200102, 2025
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding.Science China Information Sciences, 68(10): 200102, 2025
work page 2025
-
[26]
Temporal reasoning transfer from text to video.arXiv preprint arXiv:2410.06166, 2024a
Lei Li, Yuanxin Liu, Linli Yao, Peiyuan Zhang, Chenxin An, Lean Wang, Xu Sun, Lingpeng Kong, and Qi Liu. Temporal reasoning transfer from text to video.arXiv preprint arXiv:2410.06166, 2024
-
[27]
Vitatecs: A diagnostic dataset for temporal concept understanding of video-language models
Shicheng Li, Lei Li, Yi Liu, Shuhuai Ren, Yuanxin Liu, Rundong Gao, Xu Sun, and Lu Hou. Vitatecs: A diagnostic dataset for temporal concept understanding of video-language models. InEuropean Conference on Computer Vision, pages 331–348. Springer, 2024
work page 2024
-
[28]
Junyan Lin, Haoran Chen, Dawei Zhu, and Xiaoyu Shen. To preserve or to compress: An in-depth study of connector selection in multimodal large language models. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 5666–5680, Miami, Florida, USA, November 2...
-
[29]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014. 11
work page 2014
-
[30]
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Khan. Videogpt+: Integrating image and video encoders for enhanced video understanding.arXiv preprint arXiv:2406.09418, 2024
-
[31]
Video-chatgpt: Towards detailed video understanding via large vision and language models
Muhammad Maaz, Hanoona Rasheed, Salman Khan, and Fahad Shahbaz Khan. Video-chatgpt: Towards detailed video understanding via large vision and language models. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL 2024), 2024
work page 2024
-
[32]
Karttikeya Mangalam, Raiymbek Akshulakov, and Jitendra Malik. Egoschema: A diagnostic benchmark for very long-form video language understanding.Advances in Neural Information Processing Systems, 36:46212–46244, 2023
work page 2023
-
[33]
Which Way Does Time Flow? A Psychophysics-Grounded Evaluation for Vision-Language Models
Shiho Matta, Lis Kanashiro Pereira, Peitao Han, Fei Cheng, and Shigeru Kitazawa. Which way does time flow? a psychophysics-grounded evaluation for vision-language models.arXiv preprint arXiv:2510.26241, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[34]
Mathew Monfort, Alex Andonian, Bolei Zhou, Kandan Ramakrishnan, Sarah Adel Bargal, Tom Yan, Lisa Brown, Quanfu Fan, Dan Gutfreund, Carl V ondrick, et al. Moments in time dataset: one million videos for event understanding.IEEE transactions on pattern analysis and machine intelligence, 42(2):502–508, 2019
work page 2019
-
[35]
DINOv2: Learning Robust Visual Features without Supervision
Maxime Oquab, Timothée Darcet, Théo Moutakanni, Huy V o, Marc Szafraniec, Vasil Khalidov, Pierre Fernandez, Daniel Haziza, Francisco Massa, Alaaeldin El-Nouby, et al. Dinov2: Learning robust visual features without supervision.arXiv preprint arXiv:2304.07193, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Lyndsey C Pickup, Zheng Pan, Donglai Wei, YiChang Shih, Changshui Zhang, Andrew Zisserman, Bernhard Scholkopf, and William T Freeman. Seeing the arrow of time. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2035–2042, 2014
work page 2035
-
[37]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProceedings of the 38th International Conference on Machine Learning, volume 139 ofProceedings of ...
work page 2021
-
[38]
Enhancing temporal understanding in video-LLMs through stacked temporal attention in vision encoders
Ali Rasekh, Erfan Bagheri Soula, Omid Daliran, Simon Gottschalk, and Mohsen Fayyaz. Enhancing temporal understanding in video-LLMs through stacked temporal attention in vision encoders. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems, 2026. URL https:// openreview.net/forum?id=2EJrs3gUO6
work page 2026
-
[39]
Michael S. Ryoo, Honglu Zhou, Shrikant Kendre, Can Qin, Le Xue, Manli Shu, Jongwoo Park, Kanchana Ranasinghe, Silvio Savarese, Ran Xu, Caiming Xiong, and Juan Carlos Niebles. xgen-mm-vid (blip-3- video): You only need 32 tokens to represent a video even in vlms, 2025. URL https://arxiv.org/ abs/2410.16267
-
[40]
Causality matters: How temporal information emerges in video language models
Yumeng Shi, Quanyu Long, Yin Wu, and Wenya Wang. Causality matters: How temporal information emerges in video language models. InProceedings of the AAAI Conference on Artificial Intelligence, pages 9006–9014, 2026
work page 2026
-
[41]
VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training
Zhan Tong, Yibing Song, Jue Wang, and Limin Wang. VideoMAE: Masked autoencoders are data-efficient learners for self-supervised video pre-training. InAdvances in Neural Information Processing Systems, 2022
work page 2022
-
[42]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-vl: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[43]
Internvid: A large-scale video-text dataset for multimodal understanding and generation
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, et al. Internvid: A large-scale video-text dataset for multimodal understanding and generation. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[44]
Internvideo2: Scaling foundation models for multimodal video understanding
Yi Wang, Kunchang Li, Xinhao Li, Jiashuo Yu, Yinan He, Guo Chen, Baoqi Pei, Rongkun Zheng, Zun Wang, Yansong Shi, et al. Internvideo2: Scaling foundation models for multimodal video understanding. InEuropean conference on computer vision, pages 396–416. Springer, 2024
work page 2024
-
[45]
Learning and using the arrow of time
Donglai Wei, Joseph J Lim, Andrew Zisserman, and William T Freeman. Learning and using the arrow of time. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 8052–8060, 2018. 12
work page 2018
-
[46]
Longvlm: Efficient long video understanding via large language models
Yuetian Weng, Mingfei Han, Haoyu He, Xiaojun Chang, and Bohan Zhuang. Longvlm: Efficient long video understanding via large language models. InEuropean Conference on Computer Vision, pages 453–470. Springer, 2024
work page 2024
-
[47]
Next-qa: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9777–9786, 2021
work page 2021
-
[48]
Seeing the arrow of time in large multimodal models
Zihui Xue, Mi Luo, and Kristen Grauman. Seeing the arrow of time in large multimodal models. In The Thirty-ninth Annual Conference on Neural Information Processing Systems, 2025. URL https: //openreview.net/forum?id=OYciB30Z4n
work page 2025
-
[49]
Linli Yao, Lei Li, Shuhuai Ren, Lean Wang, Yuanxin Liu, Xu Sun, and Lu Hou. Deco: Decoupling token compression from semantic abstraction in multimodal large language models.arXiv preprint arXiv:2405.20985, 2024
-
[50]
Clevrer: Collision events for video representation and reasoning
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B Tenenbaum. Clevrer: Collision events for video representation and reasoning.arXiv preprint arXiv:1910.01442, 2019
-
[51]
Video-llama: An instruction-tuned audio-visual language model for video understanding
Hang Zhang, Xin Li, and Lidong Bing. Video-llama: An instruction-tuned audio-visual language model for video understanding. InProceedings of the 2023 conference on empirical methods in natural language processing: system demonstrations, pages 543–553, 2023. A InternVideo2 Details InternVideo2stage1: Vision Encoder Pre-training.InternVideo2 stage1 [44] is ...
work page 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.