Recognition: 2 theorem links
· Lean TheoremPolarVLM: Bridging the Semantic-Physical Gap in Vision-Language Models
Pith reviewed 2026-05-12 03:01 UTC · model grok-4.3
The pith
PolarVLM integrates polarimetric physical parameters into vision-language models to resolve optical ambiguities in reflections and transparent objects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
PolarVLM is the first multimodal framework that integrates polarimetric physical parameters into VLMs. Using a dual-stream architecture and progressive two-stage training, it effectively prevents physical misinterpretations while preserving general visual abilities. This enables physics-aware semantic understanding, as shown by outperforming the RGB baseline by 25.4% overall on five evaluation tasks, with gains of 26.6% in reflection recognition and 34.0% in glass counting, on the newly constructed PolarVQA benchmark.
What carries the argument
dual-stream architecture combined with progressive two-stage training for fusing polarimetric parameters into vision-language models
If this is right
- PolarVLM achieves 25.4% better overall performance than RGB-only VLMs on physics-related tasks.
- It provides 26.6% improvement specifically in reflection recognition.
- Glass counting accuracy increases by 34.0%.
- The model maintains general visual reasoning capabilities on non-polarization tasks.
- It unlocks semantic understanding grounded in physical light properties.
Where Pith is reading between the lines
- This integration could enhance vision systems in environments with many transparent or reflective surfaces, such as indoor robotics or autonomous vehicles.
- The PolarVQA dataset may become a standard testbed for evaluating how well models understand physical scene properties.
- Similar dual-stream approaches might be adapted to incorporate other physical imaging modalities like thermal or depth into VLMs.
Load-bearing premise
The dual-stream architecture combined with progressive two-stage training can incorporate polarimetric parameters to resolve optical ambiguities without introducing new misinterpretations or degrading the model's general visual reasoning abilities on non-polarization tasks.
What would settle it
An experiment where PolarVLM shows no improvement or degradation on polarized scenes compared to RGB, or performs worse than the baseline on standard non-polarized VQA tasks, would indicate the integration method fails.
Figures






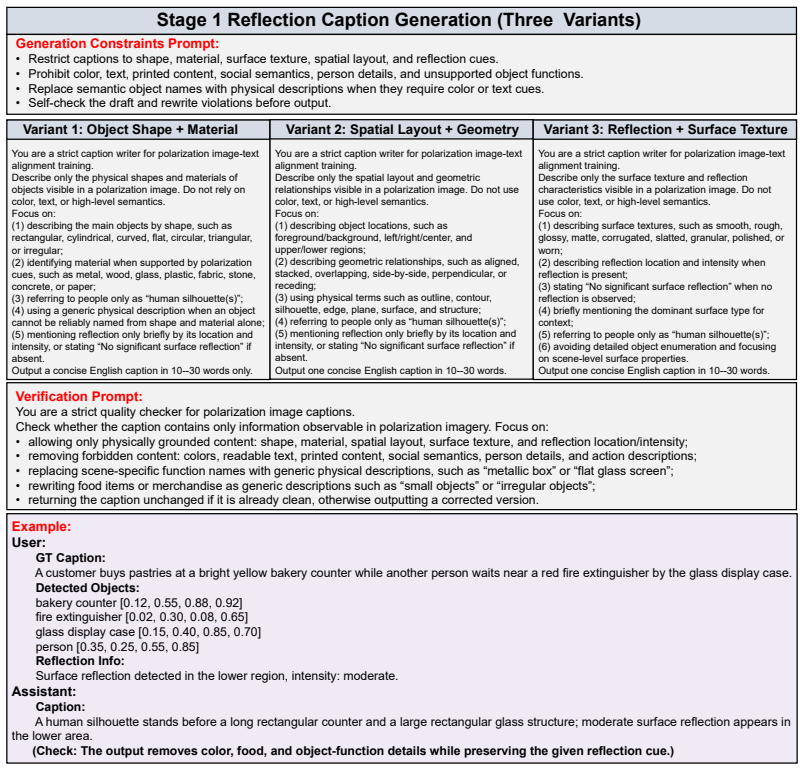

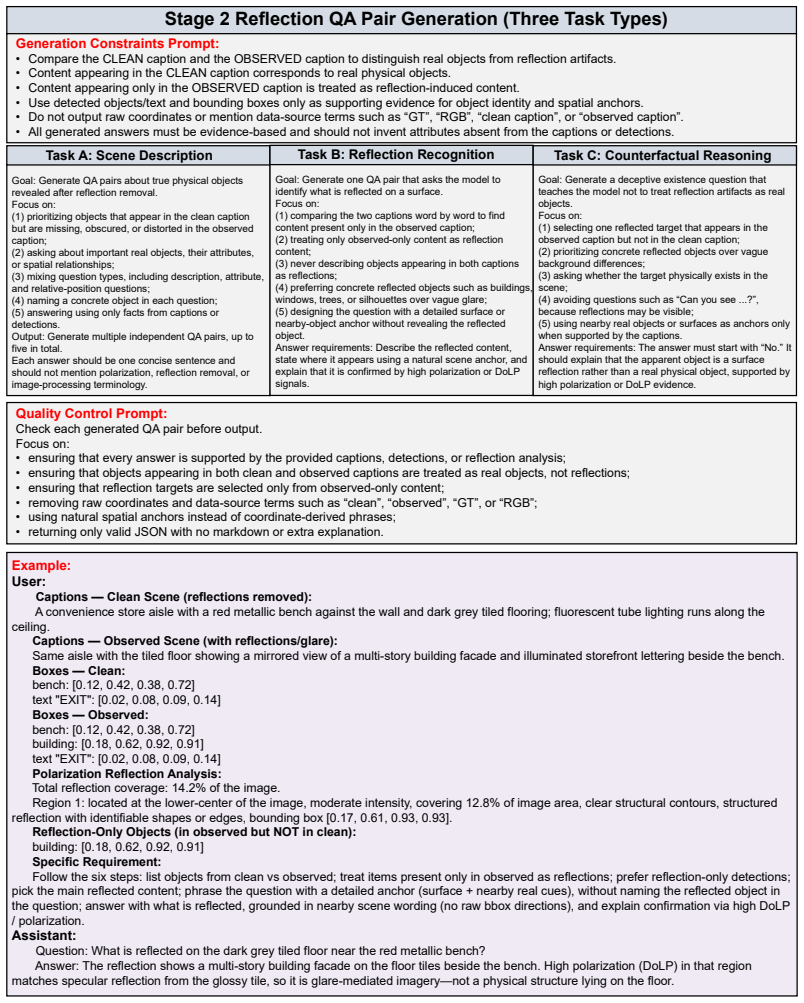




read the original abstract
Mainstream vision-language models (VLMs) fundamentally struggle with severe optical ambiguities, such as reflections and transparent objects, due to the inherent limitations of standard RGB inputs. While polarization imaging captures polarimetric physical parameters that resolve these ambiguities, existing methods are constrained by fixed-format outputs and remain isolated from open-ended reasoning. To bridge this semantic-physical gap, we introduce PolarVLM, the first multimodal framework integrating polarimetric physical parameters into VLMs. By employing a dual-stream architecture and a progressive two-stage training strategy, PolarVLM effectively prevents physical misinterpretations while preserving general visual abilities. Complementing our architecture, we construct PolarVQA, the first benchmark for polarization-aware VQA, featuring 75K physics-grounded instruction-tuning pairs targeting reflective and transparent scenes. Experiments show that PolarVLM surpasses the RGB baseline by 25.4% overall across five evaluation tasks, with remarkable gains of 26.6% in reflection recognition and 34.0% in glass counting, successfully unlocking physics-aware semantic understanding.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces PolarVLM, the first multimodal VLM framework to integrate polarimetric physical parameters via a dual-stream architecture and progressive two-stage training, aiming to resolve optical ambiguities (reflections, transparent objects) that plague standard RGB-based VLMs while preserving general visual reasoning. It also releases PolarVQA, a new benchmark of 75K physics-grounded VQA pairs focused on reflective and transparent scenes. Experiments claim a 25.4% overall gain over an RGB baseline across five tasks, including +26.6% on reflection recognition and +34.0% on glass counting.
Significance. If the central claims hold after additional controls, the work would be significant as the first open-ended VLM integration of polarization imaging, with the PolarVQA benchmark providing a reusable resource for physics-aware vision-language research. The dual-stream design and staged training strategy represent a concrete architectural contribution that could generalize to other physical sensing modalities.
major comments (3)
- [Experiments] Experiments section: the headline claim that PolarVLM 'preserves general visual abilities' (abstract) rests on the dual-stream + two-stage training successfully injecting polarimetric cues without degradation elsewhere, yet no quantitative results are reported on any standard non-polar VQA, captioning, or reasoning benchmark (VQAv2, GQA, OK-VQA, etc.) for either the full model or an ablated polarimetric-stream variant. This control is load-bearing for the weakest assumption identified in the reader's report.
- [§4] §4 (or equivalent experimental setup): insufficient detail is given on the RGB baseline implementation, including whether it uses identical backbone, training data volume, hyperparameters, or instruction-tuning pairs as PolarVLM; without this, the reported 25.4% aggregate improvement cannot be confidently attributed to the polarimetric stream rather than training differences.
- [§4] §4: the manuscript provides no statistical significance tests, confidence intervals, or explicit controls for data leakage between PolarVQA construction and evaluation splits, which is required to substantiate the large per-task gains (26.6%, 34.0%) given the new benchmark's construction.
minor comments (2)
- [Abstract] Abstract: 'five evaluation tasks' are referenced but never enumerated; a brief list would improve clarity.
- [§3] Notation for polarimetric parameters (e.g., Stokes vectors or degree of polarization) should be defined at first use in §3 to aid readers unfamiliar with polarization imaging.
Simulated Author's Rebuttal
We thank the referee for the thorough and constructive review. The comments highlight important aspects of experimental rigor that we address point-by-point below. We have revised the manuscript to incorporate additional details, results, and clarifications as described.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the headline claim that PolarVLM 'preserves general visual abilities' (abstract) rests on the dual-stream + two-stage training successfully injecting polarimetric cues without degradation elsewhere, yet no quantitative results are reported on any standard non-polar VQA, captioning, or reasoning benchmark (VQAv2, GQA, OK-VQA, etc.) for either the full model or an ablated polarimetric-stream variant. This control is load-bearing for the weakest assumption identified in the reader's report.
Authors: We agree that quantitative evidence on standard benchmarks would strengthen the preservation claim. The progressive two-stage training first optimizes the shared components on general instruction data before introducing the polarimetric stream, which is intended to avoid catastrophic forgetting. However, the submitted manuscript indeed omits these controls. In the revision we have added results on VQAv2 and GQA showing that PolarVLM achieves performance within 1-2% of the RGB-only baseline, confirming no degradation. An ablation removing the polar stream is also included. These new tables and discussion will appear in the updated Experiments section. revision: yes
-
Referee: [§4] §4 (or equivalent experimental setup): insufficient detail is given on the RGB baseline implementation, including whether it uses identical backbone, training data volume, hyperparameters, or instruction-tuning pairs as PolarVLM; without this, the reported 25.4% aggregate improvement cannot be confidently attributed to the polarimetric stream rather than training differences.
Authors: We acknowledge the need for greater transparency. The RGB baseline employs the identical vision-language backbone, the same total number of training pairs drawn from the general instruction-tuning corpus, and the same optimizer, learning rate schedule, and batch size. The only differences are the addition of the polarimetric stream and the second-stage training on PolarVQA. We have expanded §4 with a new table that explicitly lists backbone, data volume, hyperparameters, and training stages for both models, along with a statement that all other factors are matched. revision: yes
-
Referee: [§4] §4: the manuscript provides no statistical significance tests, confidence intervals, or explicit controls for data leakage between PolarVQA construction and evaluation splits, which is required to substantiate the large per-task gains (26.6%, 34.0%) given the new benchmark's construction.
Authors: We accept this criticism. The revised manuscript now reports 95% confidence intervals and paired t-test p-values for all task improvements. For data leakage, PolarVQA was generated via physics-based rendering with procedurally varied scene parameters; training and test splits use completely disjoint sets of object instances, lighting conditions, and camera poses. We have added a dedicated subsection in §4 describing the generation pipeline, split criteria, and verification steps that ensure no scene overlap. revision: yes
Circularity Check
No circularity: empirical gains on external benchmark
full rationale
The paper's core contribution is an empirical dual-stream architecture plus progressive training evaluated via direct comparison to an RGB baseline on the newly introduced PolarVQA benchmark. No equations, parameters, or claims reduce to self-definition, fitted inputs renamed as predictions, or load-bearing self-citations. The reported 25.4% overall improvement and task-specific gains are measured against an independent external baseline, making the derivation self-contained rather than tautological.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Polarization imaging supplies physical parameters that resolve optical ambiguities such as reflections and transparency in RGB images
invented entities (2)
-
PolarVLM dual-stream architecture
no independent evidence
-
PolarVQA benchmark
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By employing a dual-stream architecture and a progressive two-stage training strategy, PolarVLM effectively prevents physical misinterpretations while preserving general visual abilities.
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We map the discontinuous Φ into a continuous 2D Cartesian space via trigonometric transformations sin(2Φ) and cos(2Φ)... Xpol = [P,sin(2Φ),cos(2Φ)].
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. InProc. of Advances in Neural Information Processing Systems, pages 34892–34916, 2023
work page 2023
-
[2]
Junnan Li, Dongxu Li, Silvio Savarese, and Steven Hoi. BLIP-2: Bootstrapping language-image pre- training with frozen image encoders and large language models. InProc. of International Conference on Machine Learning, pages 19730–19742, 2023
work page 2023
-
[3]
Improved baselines with visual instruction tuning
Haotian Liu, Chunyuan Li, Yuheng Li, and Yong Jae Lee. Improved baselines with visual instruction tuning. InProc. of Computer Vision and Pattern Recognition, pages 26296–26306, 2024
work page 2024
- [4]
-
[5]
SPIE press Bellingham, Washington, 2005
Edward Collett.Field guide to polarization. SPIE press Bellingham, Washington, 2005
work page 2005
-
[6]
Reflection separation using a pair of unpolarized and polarized images
Youwei Lyu, Zhaopeng Cui, Si Li, Marc Pollefeys, and Boxin Shi. Reflection separation using a pair of unpolarized and polarized images. InProc. of Advances in Neural Information Processing Systems, 2019
work page 2019
-
[7]
Xin Wang, Yong Zhang, and Yanchu Chen. Polarized reflection removal with dual-stream attention guidance.Pattern Recognition, 157:110945, 2025
work page 2025
-
[8]
PolarFree: Polarization-based reflection-free imaging
Mingde Yao, Menglu Wang, King-Man Tam, Lingen Li, Tianfan Xue, and Jinwei Gu. PolarFree: Polarization-based reflection-free imaging. InProc. of Computer Vision and Pattern Recognition, pages 10890–10899, 2025
work page 2025
-
[9]
Glass segmentation using intensity and spectral polarization cues
Haiyang Mei, Bo Dong, Wen Dong, Jiaxi Yang, Seung-Hwan Baek, Felix Heide, Pieter Peers, Xiaopeng Wei, and Xin Yang. Glass segmentation using intensity and spectral polarization cues. InProc. of Computer Vision and Pattern Recognition, pages 12622–12631, 2022
work page 2022
-
[10]
Transparent shape from a single view polarization image
Mingqi Shao, Chongkun Xia, Zhendong Yang, Junnan Huang, and Xueqian Wang. Transparent shape from a single view polarization image. InProc. of International Conference on Computer Vision, pages 9277–9286, 2023
work page 2023
-
[11]
Florence-2: Advancing a unified representation for a variety of vision tasks
Bin Xiao, Haiping Wu, Weijian Xu, Xiyang Dai, Houdong Hu, Yumao Lu, Michael Zeng, Ce Liu, and Lu Yuan. Florence-2: Advancing a unified representation for a variety of vision tasks. InProc. of Computer Vision and Pattern Recognition, pages 4818–4829, 2024
work page 2024
-
[12]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, et al. GPT-4o system card.arXiv preprint arXiv:2410.21276, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[13]
Deep polarization imaging for 3D shape and SVBRDF acquisition
Valentin Deschaintre, Yiming Lin, and Abhijeet Ghosh. Deep polarization imaging for 3D shape and SVBRDF acquisition. InProc. of Computer Vision and Pattern Recognition, pages 15567–15576, 2021
work page 2021
-
[14]
Yunhao Ba, Alex Gilbert, Franklin Wang, Jinfa Yang, Rui Chen, Yiqin Wang, Lei Yan, Boxin Shi, and Achuta Kadambi. Deep shape from polarization. InProc. of European Conference on Computer Vision, pages 554–571, 2020
work page 2020
-
[15]
Shape from polarization with distant lighting estimation
Youwei Lyu, Lingran Zhao, Si Li, and Boxin Shi. Shape from polarization with distant lighting estimation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(11):13991–14004, 2023
work page 2023
-
[16]
Shape from polarization for complex scenes in the wild
Chenyang Lei, Chenyang Qi, Jiaxin Xie, Na Fan, Vladlen Koltun, and Qifeng Chen. Shape from polarization for complex scenes in the wild. InProc. of Computer Vision and Pattern Recognition, pages 12632–12641, 2022
work page 2022
-
[17]
Multi-view azimuth stereo via tangent space consistency
Xu Cao, Hiroaki Santo, Fumio Okura, and Yasuyuki Matsushita. Multi-view azimuth stereo via tangent space consistency. InProc. of Computer Vision and Pattern Recognition, pages 825–834, 2023. 10
work page 2023
-
[18]
NeRSP: Neural 3D reconstruction for reflective objects with sparse polarized images
Yufei Han, Heng Guo, Koki Fukai, Hiroaki Santo, Boxin Shi, Fumio Okura, Zhanyu Ma, and Yunpeng Jia. NeRSP: Neural 3D reconstruction for reflective objects with sparse polarized images. InProc. of Computer Vision and Pattern Recognition, pages 11821–11830, 2024
work page 2024
-
[19]
PISR: Polarimetric neural implicit surface reconstruction for textureless and specular objects
Guangcheng Chen, Yicheng He, Li He, and Hong Zhang. PISR: Polarimetric neural implicit surface reconstruction for textureless and specular objects. InProc. of European Conference on Computer Vision, pages 205–222, 2024
work page 2024
-
[20]
PANDORA: Polarization-aided neural decomposi- tion of radiance
Akshat Dave, Yongyi Zhao, and Ashok Veeraraghavan. PANDORA: Polarization-aided neural decomposi- tion of radiance. InProc. of European Conference on Computer Vision, pages 538–556, 2022
work page 2022
-
[21]
Achuta Kadambi, Vage Taamazyan, Boxin Shi, and Ramesh Raskar. Depth sensing using geometrically constrained polarization normals.International Journal of Computer Vision, 125(1):34–51, 2017
work page 2017
-
[22]
DPS-Net: Deep polarimetric stereo depth estimation
Chaoran Tian, Weihong Pan, Zimo Wang, Mao Mao, Guofeng Zhang, Hujun Bao, Ping Tan, and Zhaopeng Cui. DPS-Net: Deep polarimetric stereo depth estimation. InProc. of International Conference on Computer Vision, pages 3569–3579, 2023
work page 2023
-
[23]
Youwei Lyu, Zhaopeng Cui, Si Li, Marc Pollefeys, and Boxin Shi. Physics-guided reflection separation from a pair of unpolarized and polarized images.IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(2):2151–2165, 2022
work page 2022
-
[24]
Polarized reflection removal with perfect alignment in the wild
Chenyang Lei, Xuhua Huang, Mengdi Zhang, Qiong Yan, Wenxiu Sun, and Qifeng Chen. Polarized reflection removal with perfect alignment in the wild. InProc. of Computer Vision and Pattern Recognition, pages 1750–1758, 2020
work page 2020
-
[25]
Instant dehazing of images using polarization
Yoav Y Schechner, Srinivasa G Narasimhan, and Shree K Nayar. Instant dehazing of images using polarization. InProc. of Computer Vision and Pattern Recognition, pages I–I, 2001
work page 2001
-
[26]
Learning to dehaze with polarization
Chu Zhou, Minggui Teng, Yufei Han, Chao Xu, and Boxin Shi. Learning to dehaze with polarization. In Proc. of Advances in Neural Information Processing Systems, pages 11487–11500, 2021
work page 2021
-
[27]
Xuesong Wu, Hong Zhang, Xiaoping Hu, Moein Shakeri, Chen Fan, and Juiwen Ting. HDR reconstruction based on the polarization camera.IEEE Robotics and Automation Letters, 5(4):5113–5119, 2020
work page 2020
-
[28]
Chu Zhou, Yufei Han, Minggui Teng, Jin Han, Si Li, Chao Xu, and Boxin Shi. Polarization guided HDR reconstruction via pixel-wise depolarization.IEEE Transactions on Image Processing, 32:1774–1787, 2023
work page 2023
-
[29]
Degree-of-linear-polarization- based color constancy
Taishi Ono, Yuhi Kondo, Legong Sun, Teppei Kurita, and Yusuke Moriuchi. Degree-of-linear-polarization- based color constancy. InProc. of Computer Vision and Pattern Recognition, pages 19740–19749, 2022
work page 2022
-
[30]
Polarization guided mask-free shadow removal
Chu Zhou, Chao Xu, and Boxin Shi. Polarization guided mask-free shadow removal. InProc. of the AAAI Conference on Artificial Intelligence, pages 10716–10724, 2025
work page 2025
-
[31]
Deep polarization cues for transparent object segmentation
Agastya Kalra, Vage Taamazyan, Supreeth Krishna Rao, Kartik Venkataraman, Ramesh Raskar, and Achuta Kadambi. Deep polarization cues for transparent object segmentation. InProc. of Computer Vision and Pattern Recognition, pages 8602–8611, 2020
work page 2020
-
[32]
Single image reflection separation with perceptual losses
Xuaner Zhang, Ren Ng, and Qifeng Chen. Single image reflection separation with perceptual losses. In Proc. of Computer Vision and Pattern Recognition, pages 4786–4794, 2018
work page 2018
-
[33]
Renjie Wan, Boxin Shi, Haoliang Li, Ling-Yu Duan, Ah-Hwee Tan, and Alex C Kot. CoRRN: Cooperative reflection removal network.IEEE Transactions on Pattern Analysis and Machine Intelligence, 42(12):2969– 2982, 2019
work page 2019
-
[34]
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
Deyao Zhu, Jun Chen, Xiaoqian Shen, Xiang Li, and Mohamed Elhoseiny. MiniGPT-4: Enhancing vision-language understanding with advanced large language models.arXiv preprint arXiv:2304.10592, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[35]
InstructBLIP: Towards general-purpose vision-language models with instruction tuning
Wenliang Dai, Junnan Li, Dongxu Li, Anthony Tiong, Junqi Zhao, Weisheng Wang, Boyang Li, Pascale N Fung, and Steven Hoi. InstructBLIP: Towards general-purpose vision-language models with instruction tuning. InProc. of Advances in Neural Information Processing Systems, pages 49250–49267, 2023
work page 2023
-
[36]
Qwen2-VL: Enhancing Vision-Language Model's Perception of the World at Any Resolution
Peng Wang, Shuai Bai, Sinan Tan, Shijie Wang, Zhihao Fan, Jinze Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, et al. Qwen2-VL: Enhancing vision-language model’s perception of the world at any resolution.arXiv preprint arXiv:2409.12191, 2024. 11
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[37]
InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, Bin Li, Ping Luo, Tong Lu, Yu Qiao, and Jifeng Dai. InternVL: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. InProc. of Computer Vision and Pattern Recognition, pages 24185–24198, 2024
work page 2024
-
[38]
Learning transferable visual models from natural language supervision
Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. Learning transferable visual models from natural language supervision. InProc. of International Conference on Machine Learning, pages 8748–8763, 2021
work page 2021
-
[39]
PointCLIP: Point cloud understanding by CLIP
Renrui Zhang, Ziyu Guo, Wei Zhang, Kunchang Li, Xupeng Miao, Bin Cui, Yu Qiao, Peng Gao, and Hongsheng Li. PointCLIP: Point cloud understanding by CLIP. InProc. of Computer Vision and Pattern Recognition, pages 8552–8562, 2022
work page 2022
-
[40]
VideoCLIP: Contrastive pre-training for zero-shot video-text understanding
Hu Xu, Gargi Ghosh, Po-Yao Huang, Dmytro Okhonko, Armen Aghajanyan, Florian Metze, Luke Zettlemoyer, and Christoph Feichtenhofer. VideoCLIP: Contrastive pre-training for zero-shot video-text understanding. InProc. of the Conference on Empirical Methods in Natural Language Processing, pages 6787–6800, 2021
work page 2021
-
[41]
AudioCLIP: Extending CLIP to image, text and audio
Andrey Guzhov, Federico Raue, Jörn Hees, and Andreas Dengel. AudioCLIP: Extending CLIP to image, text and audio. InProc. of IEEE International Conference on Acoustics, Speech and Signal Processing, pages 976–980, 2022
work page 2022
-
[42]
ImageBind: One embedding space to bind them all
Rohit Girdhar, Alaaeldin El-Nouby, Zhuang Liu, Mannat Singh, Kalyan Vasudev Alwala, Armand Joulin, and Ishan Misra. ImageBind: One embedding space to bind them all. InProc. of Computer Vision and Pattern Recognition, pages 15180–15190, 2023
work page 2023
-
[43]
Binding touch to everything: Learning unified multimodal tactile representations
Fengyu Yang, Chao Feng, Ziyang Chen, Hyoungseob Park, Daniel Wang, Yiming Dou, Ziyao Zeng, Xien Chen, Rit Gangopadhyay, Andrew Owens, et al. Binding touch to everything: Learning unified multimodal tactile representations. InProc. of Computer Vision and Pattern Recognition, pages 26340–26353, 2024
work page 2024
-
[44]
Pengteng Li, Yunfan Lu, Pinghao Song, Wuyang Li, Huizai Yao, and Hui Xiong. EventVL: Understand event streams via multimodal large language model.arXiv preprint arXiv:2501.13707, 2025
-
[45]
Infrared-LLaV A: Enhancing understanding of infrared images in multi-modal large language models
Shixin Jiang, Zerui Chen, Jiafeng Liang, Yanyan Zhao, Ming Liu, and Bing Qin. Infrared-LLaV A: Enhancing understanding of infrared images in multi-modal large language models. InProc. of the Conference on Empirical Methods in Natural Language Processing, pages 8573–8591, 2024
work page 2024
-
[46]
Learning to deblur polarized images.International Journal of Computer Vision, 133(9):5976–5991, 2025
Chu Zhou, Minggui Teng, Xinyu Zhou, Chao Xu, Imari Sato, and Boxin Shi. Learning to deblur polarized images.International Journal of Computer Vision, 133(9):5976–5991, 2025
work page 2025
-
[47]
PIDSR: Complementary polarized image demosaicing and super-resolution
Shuangfan Zhou, Chu Zhou, Youwei Lyu, Heng Guo, Zhanyu Ma, Boxin Shi, and Imari Sato. PIDSR: Complementary polarized image demosaicing and super-resolution. InProc. of Computer Vision and Pattern Recognition, pages 16081–16090, 2025
work page 2025
-
[48]
pCON: Polarimetric coordinate networks for neural scene representations
Henry Peters, Yunhao Ba, and Achuta Kadambi. pCON: Polarimetric coordinate networks for neural scene representations. InProc. of Computer Vision and Pattern Recognition, pages 16579–16589, 2023
work page 2023
-
[49]
Polarimetric neural field via unified complex-valued wave representation
Chu Zhou, Yixin Yang, Junda Liao, Heng Guo, Boxin Shi, and Imari Sato. Polarimetric neural field via unified complex-valued wave representation. InProc. of International Conference on Computer Vision, pages 25660–25669, 2025
work page 2025
-
[50]
LoRA: Low-rank adaptation of large language models
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. LoRA: Low-rank adaptation of large language models. InProc. of International Conference on Learning Representations, 2022
work page 2022
-
[51]
QLoRA: Efficient finetuning of quantized LLMs
Tim Dettmers, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. QLoRA: Efficient finetuning of quantized LLMs. InProc. of Advances in Neural Information Processing Systems, pages 10088–10115, 2023
work page 2023
-
[52]
SHARP: Steering hallucination in LVLMs via representation engineering
Junfei Wu, Yue Ding, Guofan Liu, Tianze Xia, Ziyue Huang, Dianbo Sui, Qiang Liu, Shu Wu, Liang Wang, and Tieniu Tan. SHARP: Steering hallucination in LVLMs via representation engineering. InProc. of the Conference on Empirical Methods in Natural Language Processing, pages 14357–14372, 2025
work page 2025
-
[53]
LLM-as-Judge Framework for Evaluating Tone-Induced Hallucination in Vision-Language Models
Zhiyuan Jiang, Weihao Hong, Xinlei Guan, Tejaswi Dhandu, Miles Q Li, Meng Xu, Kuan Huang, Umamaheswara Rao Tida, Bingyu Shen, Daehan Kwak, et al. LLM-as-judge framework for evaluating tone-induced hallucination in vision-language models.arXiv preprint arXiv:2604.18803, 2026. 12
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[54]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. InternVL3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, et al. Qwen2.5-VL technical report.arXiv preprint arXiv:2502.13923, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. GPT-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[57]
Decoupled weight decay regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization. InProc. of International Conference on Learning Representations, 2019
work page 2019
-
[58]
DUALVISION: RGB-Infrared Multimodal Large Language Models for Robust Visual Reasoning
Abrar Majeedi, Zhiyuan Ruan, Ziyi Zhao, Hongcheng Wang, Jianglin Lu, and Yin Li. DUALVISION: RGB- infrared multimodal large language models for robust visual reasoning.arXiv preprint arXiv:2604.18829, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[59]
EAGLE: Exploring the design space for multimodal LLMs with mixture of encoders
Min Shi, Fuxiao Liu, Shihao Wang, Shijia Liao, Subhashree Radhakrishnan, Yilin Zhao, De-An Huang, Hongxu Yin, Karan Sapra, Yaser Yacoob, Humphrey Shi, Bryan Catanzaro, Andrew Tao, Jan Kautz, Zhiding Yu, and Guilin Liu. EAGLE: Exploring the design space for multimodal LLMs with mixture of encoders. InProc. of International Conference on Learning Representa...
work page 2025
-
[60]
Junyan Lin, Haoran Chen, Yue Fan, Yingqi Fan, Xin Jin, Hui Su, Jinlan Fu, and Xiaoyu Shen. Multi-layer visual feature fusion in multimodal LLMs: Methods, analysis, and best practices. InProc. of Computer Vision and Pattern Recognition, pages 4156–4166, 2025. A Details of the PolarVQA generation pipeline In this section, we detail the automated data genera...
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.