Recognition: no theorem link
TraceAV-Bench: Benchmarking Multi-Hop Trajectory Reasoning over Long Audio-Visual Videos
Pith reviewed 2026-05-11 01:49 UTC · model grok-4.3
The pith
TraceAV-Bench shows that top AI models still struggle to chain evidence across long audio-visual videos.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
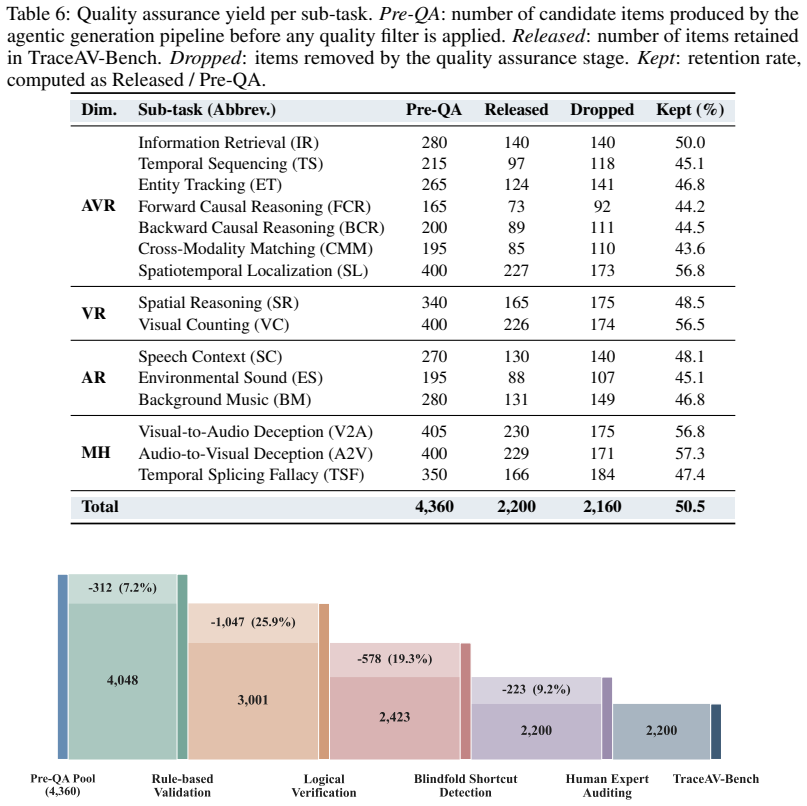
TraceAV-Bench is the first benchmark to jointly evaluate multi-hop reasoning over long audio-visual trajectories and multimodal hallucination robustness. It comprises 2,200 rigorously validated multiple-choice questions over 578 long videos totaling 339.5 hours, with each question grounded in an explicit reasoning chain averaging 3.68 hops across a 15.1-minute temporal span. The dataset was built via a three-step semi-automated pipeline followed by strict quality assurance. Evaluation across representative OmniLLMs reveals persistent challenge, with Gemini 3.1 Pro reaching 68.29 percent on general tasks and Ming-Flash-Omni-2.0 reaching 51.70 percent, leaving substantial headroom, while also
What carries the argument
The benchmark dataset itself, built from long videos and explicit multi-hop reasoning chains that span both visual and auditory streams across 4 dimensions and 15 sub-tasks.
If this is right
- Current OmniLLMs cannot reliably chain temporally dispersed evidence across audio and visual streams in videos longer than a few minutes.
- Robustness to multimodal hallucination must be measured separately from general multimodal reasoning performance.
- Progress on long-form audio-visual understanding will require new training or architectural approaches that handle sparse, cross-modal trajectories.
- Benchmarks limited to short clips or isolated modalities will continue to overestimate real-world capability.
Where Pith is reading between the lines
- Applications such as video surveillance or educational content analysis will remain limited until models close the gap shown here.
- The observed decoupling between hallucination resistance and reasoning performance suggests separate fine-tuning objectives could be effective.
- Similar multi-hop benchmarks may be needed for other long-form multimodal domains such as audio-only or text-video mixtures.
Load-bearing premise
The created questions genuinely demand multi-hop cross-modal evidence chaining and contain no solvable shortcuts or validation errors.
What would settle it
A concrete falsifier would be finding that state-of-the-art models achieve over 90 percent accuracy on TraceAV-Bench while still failing on independent long-video tasks that require the same chaining ability.
Figures






























read the original abstract
Real-world audio-visual understanding requires chaining evidence that is sparse, temporally dispersed, and split across the visual and auditory streams, whereas existing benchmarks largely fail to evaluate this capability. They restrict videos to short clips, isolate modalities, or reduce questions to one-hop perception. We introduce TraceAV-Bench, the first benchmark to jointly evaluate multi-hop reasoning over long audio-visual trajectories and multimodal hallucination robustness. TraceAV-Bench comprises 2,200 rigorously validated multiple-choice questions over 578 long videos, totaling 339.5 hours, spanning 4 evaluation dimensions and 15 sub-tasks. Each question is grounded in an explicit reasoning chain that averages 3.68 hops across a 15.1-minute temporal span. The dataset is built by a three-step semi-automated pipeline followed by a strict quality assurance process. Evaluation of multiple representative OmniLLMs on TraceAV-Bench reveals that the benchmark poses a persistent challenge across all models, with the strongest closed-source model (Gemini 3.1 Pro) reaching only 68.29% on general tasks, and the best open-source model (Ming-Flash-Omni-2.0) reaching 51.70%, leaving substantial headroom. Moreover, we find that robustness to multimodal hallucination is largely decoupled from general multimodal reasoning performance. We anticipate that TraceAV-Bench will stimulate further research toward OmniLLMs that can reason coherently and faithfully over long-form audio-visual content.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces TraceAV-Bench, a benchmark of 2,200 multiple-choice questions over 578 long audio-visual videos (339.5 hours total). It targets multi-hop trajectory reasoning across audio-visual streams in long temporal contexts (average 15.1 min span, 3.68-hop explicit chains), plus multimodal hallucination robustness. The dataset spans 4 dimensions and 15 sub-tasks, constructed via a three-step semi-automated pipeline with strict quality assurance. Evaluations on OmniLLMs show persistent challenges, with Gemini 3.1 Pro at 68.29% on general tasks and the best open-source model at 51.70%, plus decoupling between hallucination robustness and general reasoning.
Significance. If the questions genuinely isolate multi-hop cross-modal chaining, TraceAV-Bench would fill an important gap left by short-clip or single-hop benchmarks. The scale, explicit hop counts, long durations, and concrete model gaps (including the decoupling finding) are strengths that could drive progress in coherent long-form audio-visual reasoning. The semi-automated pipeline with QA is a positive methodological contribution.
major comments (3)
- [§3] §3 (Construction Pipeline): The manuscript describes the three-step semi-automated pipeline and states that each question is tied to an explicit 3.68-hop chain, but reports no hop-ablation, modality-ablation, or shortcut-detection experiments (e.g., providing only partial evidence or single-modality input). This is load-bearing for the central claim that the benchmark evaluates multi-hop trajectory reasoning rather than solvable shortcuts.
- [§3.3] §3.3 (Quality Assurance): The strict QA process is mentioned, yet no quantitative validation statistics—rejection rates, inter-annotator agreement, or error analysis—are provided. This weakens support for benchmark quality and the absence of data leaks or validation errors, directly affecting interpretation of the reported model scores.
- [§4] §4 (Experiments): While concrete scores are given (e.g., Gemini 3.1 Pro at 68.29%), the evaluation section does not analyze whether accuracy correlates with hop count or temporal span, leaving the multi-hop difficulty claim without direct empirical support.
minor comments (2)
- [Table 2] Table 2 (model results): Adding per-sub-task breakdowns or confidence intervals would improve clarity of the performance gaps.
- [§2] §2 (Related Work): A few additional citations to recent long-video QA benchmarks would strengthen the novelty positioning.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We agree that additional analyses are needed to more rigorously substantiate the multi-hop and cross-modal claims, and we will incorporate the suggested revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: §3 (Construction Pipeline): The manuscript describes the three-step semi-automated pipeline and states that each question is tied to an explicit 3.68-hop chain, but reports no hop-ablation, modality-ablation, or shortcut-detection experiments (e.g., providing only partial evidence or single-modality input). This is load-bearing for the central claim that the benchmark evaluates multi-hop trajectory reasoning rather than solvable shortcuts.
Authors: We agree that ablation experiments are necessary to empirically confirm that the benchmark requires multi-hop cross-modal chaining rather than permitting shortcuts. In the revised manuscript, we will add modality-ablation results (audio-only and visual-only inputs) and partial-evidence ablations (providing only subsets of the hop chain) to Section 4. These will demonstrate performance degradation without full chains. While the pipeline explicitly constructs and validates the 3.68-hop chains with long temporal spans, the new experiments will directly address this concern. revision: yes
-
Referee: §3.3 (Quality Assurance): The strict QA process is mentioned, yet no quantitative validation statistics—rejection rates, inter-annotator agreement, or error analysis—are provided. This weakens support for benchmark quality and the absence of data leaks or validation errors, directly affecting interpretation of the reported model scores.
Authors: We concur that quantitative QA metrics are essential for validating benchmark quality. We will revise §3.3 to include rejection rates during the QA process, inter-annotator agreement statistics (e.g., Fleiss' kappa), and a summary of error analysis categories. These metrics were collected during dataset construction but not reported in the original submission; they will now be added to provide stronger evidence against data leaks or annotation errors. revision: yes
-
Referee: §4 (Experiments): While concrete scores are given (e.g., Gemini 3.1 Pro at 68.29%), the evaluation section does not analyze whether accuracy correlates with hop count or temporal span, leaving the multi-hop difficulty claim without direct empirical support.
Authors: We thank the referee for highlighting this gap. To provide direct empirical support for the multi-hop difficulty claim, we will expand §4 with new analyses: model accuracy broken down by hop count (e.g., 2-hop vs. 4-hop) and by temporal span bins, along with correlation coefficients between accuracy and these factors. This will be presented in tables and figures to show the expected increase in difficulty with more hops and longer spans. revision: yes
Circularity Check
No circularity in benchmark construction or claims
full rationale
The paper constructs TraceAV-Bench through an external-video-based three-step semi-automated pipeline plus independent QA, with questions tied to explicitly authored reasoning chains. No equations, fitted parameters, self-citations, or uniqueness theorems are invoked to derive the core claims about multi-hop requirements or model headroom. Evaluations use separate models on the resulting dataset, keeping creation and measurement distinct. No step reduces a claimed result to its own inputs by construction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The semi-automated three-step pipeline followed by human QA produces questions that genuinely require and test multi-hop cross-modal reasoning chains
Reference graph
Works this paper leans on
-
[1]
Shuai Bai, Yuxuan Cai, Ruizhe Chen, Keqin Chen, Xionghui Chen, Zesen Cheng, Lianghao Deng, Wei Ding, Chang Gao, Chunjiang Ge, et al. Qwen3-vl technical report.arXiv preprint arXiv:2511.21631, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
MiniCPM-V: A GPT-4V Level MLLM on Your Phone
Yuan Yao, Tianyu Yu, Ao Zhang, Chongyi Wang, Junbo Cui, Hongji Zhu, Tianchi Cai, Haoyu Li, Weilin Zhao, Zhihui He, et al. Minicpm-v: A gpt-4v level mllm on your phone.arXiv preprint arXiv:2408.01800, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[3]
A survey on multimodal large language models.National Science Review, 11(12):nwae403, 2024
Shukang Yin, Chaoyou Fu, Sirui Zhao, Ke Li, Xing Sun, Tong Xu, and Enhong Chen. A survey on multimodal large language models.National Science Review, 11(12):nwae403, 2024
work page 2024
-
[4]
Kimi Team, Angang Du, Bohong Yin, Bowei Xing, Bowen Qu, Bowen Wang, Cheng Chen, Chenlin Zhang, Chenzhuang Du, Chu Wei, et al. Kimi-vl technical report.arXiv preprint arXiv:2504.07491, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
Tianyi Bai, Hao Liang, Binwang Wan, Yanran Xu, Xi Li, Shiyu Li, Ling Yang, Bozhou Li, Yifan Wang, Bin Cui, et al. A survey of multimodal large language model from a data-centric perspective.arXiv preprint arXiv:2405.16640, 2024
-
[6]
Hao Liang, Xiaochen Ma, Zhou Liu, Zhen Hao Wong, Zhengyang Zhao, Zimo Meng, Runming He, Chengyu Shen, Qifeng Cai, Zhaoyang Han, et al. Dataflow: An llm-driven framework for unified data preparation and workflow automation in the era of data-centric ai.arXiv preprint arXiv:2512.16676, 2025
-
[7]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Jinguo Zhu, Weiyun Wang, Zhe Chen, Zhaoyang Liu, Shenglong Ye, Lixin Gu, Hao Tian, Yuchen Duan, Weijie Su, Jie Shao, et al. Internvl3: Exploring advanced training and test-time recipes for open-source multimodal models.arXiv preprint arXiv:2504.10479, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[8]
PaliGemma 2: A Family of Versatile VLMs for Transfer
Andreas Steiner, André Susano Pinto, Michael Tschannen, Daniel Keysers, Xiao Wang, Yonatan Bitton, Alexey Gritsenko, Matthias Minderer, Anthony Sherbondy, Shangbang Long, et al. Paligemma 2: A family of versatile vlms for transfer.arXiv preprint arXiv:2412.03555, 2024
work page internal anchor Pith review arXiv 2024
- [9]
-
[10]
Xian Shi, Xiong Wang, Zhifang Guo, Yongqi Wang, Pei Zhang, Xinyu Zhang, Zishan Guo, Hongkun Hao, Yu Xi, Baosong Yang, Jin Xu, Jingren Zhou, and Junyang Lin. Qwen3-asr technical report, 2026. URLhttps://arxiv.org/abs/2601.21337
work page internal anchor Pith review arXiv 2026
-
[11]
Qwen Team. Qwen3. 5-omni technical report.arXiv preprint arXiv:2604.15804, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[12]
Inclusion AI, Bowen Ma, Cheng Zou, Canxiang Yan, Chunxiang Jin, Chunjie Shen, Chenyu Lian, Dandan Zheng, Fudong Wang, Furong Xu, et al. Ming-flash-omni: A sparse, unified architecture for multimodal perception and generation.arXiv preprint arXiv:2510.24821, 2025
-
[13]
Humanomni: A large vision-speech language model for human-centric video understanding,
Jiaxing Zhao, Qize Yang, Yixing Peng, Detao Bai, Shimin Yao, Boyuan Sun, Xiang Chen, Shenghao Fu, Xihan Wei, Liefeng Bo, et al. Humanomni: A large vision-speech language model for human-centric video understanding.arXiv preprint arXiv:2501.15111, 2025
-
[14]
Longcat-flash-omni technical report.ArXiv, abs/2511.00279,
Meituan LongCat Team, Bairui Wang, Bin Xiao, Bo Zhang, Bolin Rong, Borun Chen, Chang Wan, Chao Zhang, Chen Huang, Chen Chen, et al. Longcat-flash-omni technical report.arXiv preprint arXiv:2511.00279, 2025
-
[15]
Changli Tang, Yixuan Li, Yudong Yang, Jimin Zhuang, Guangzhi Sun, Wei Li, Zejun Ma, and Chao Zhang. video-salmonn 2: Caption-enhanced audio-visual large language models.arXiv preprint arXiv:2506.15220, 2025. 10
-
[16]
Baichuan-omni technical report.arXiv preprint arXiv:2410.08565, 2024
Yadong Li, Haoze Sun, Mingan Lin, Tianpeng Li, Guosheng Dong, Tao Zhang, Bowen Ding, Wei Song, Zhenglin Cheng, Yuqi Huo, et al. Baichuan-omni technical report.arXiv preprint arXiv:2410.08565, 2024
-
[17]
Gheorghe Comanici, Eric Bieber, Mike Schaekermann, Ice Pasupat, Noveen Sachdeva, Inderjit Dhillon, Marcel Blistein, Ori Ram, Dan Zhang, Evan Rosen, et al. Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities.arXiv preprint arXiv:2507.06261, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
Onellm: One framework to align all modalities with language
Jiaming Han, Kaixiong Gong, Yiyuan Zhang, Jiaqi Wang, Kaipeng Zhang, Dahua Lin, Yu Qiao, Peng Gao, and Xiangyu Yue. Onellm: One framework to align all modalities with language. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 26584–26595, 2024
work page 2024
-
[19]
Omn- immi: A comprehensive multi-modal interaction benchmark in streaming video contexts
Yuxuan Wang, Yueqian Wang, Bo Chen, Tong Wu, Dongyan Zhao, and Zilong Zheng. Omn- immi: A comprehensive multi-modal interaction benchmark in streaming video contexts. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 18925–18935, 2025
work page 2025
-
[20]
Omnigaia: Towards native omni-modal ai agents, 2026
Xiaoxi Li, Wenxiang Jiao, Jiarui Jin, Shijian Wang, Guanting Dong, Jiajie Jin, Hao Wang, Yinuo Wang, Ji-Rong Wen, Yuan Lu, et al. Omnigaia: Towards native omni-modal ai agents. arXiv preprint arXiv:2602.22897, 2026
-
[21]
Lvomnibench: Pioneering long audio-video understanding evaluation for omnimodal llms
Keda Tao, Yuhua Zheng, Jia Xu, Wenjie Du, Kele Shao, Hesong Wang, Xueyi Chen, Xin Jin, Junhan Zhu, Bohan Yu, et al. Lvomnibench: Pioneering long audio-video understanding evaluation for omnimodal llms.arXiv preprint arXiv:2603.19217, 2026
-
[22]
Lvbench: An extreme long video understanding benchmark
Weihan Wang, Zehai He, Wenyi Hong, Yean Cheng, Xiaohan Zhang, Ji Qi, Ming Ding, Xiaotao Gu, Shiyu Huang, Bin Xu, et al. Lvbench: An extreme long video understanding benchmark. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 22958– 22967, 2025
work page 2025
-
[23]
Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis
Chaoyou Fu, Yuhan Dai, Yongdong Luo, Lei Li, Shuhuai Ren, Renrui Zhang, Zihan Wang, Chenyu Zhou, Yunhang Shen, Mengdan Zhang, et al. Video-mme: The first-ever comprehensive evaluation benchmark of multi-modal llms in video analysis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24108–24118, 2025
work page 2025
-
[24]
Qian Chen, Jinlan Fu, Changsong Li, See-Kiong Ng, and Xipeng Qiu. Futureomni: Eval- uating future forecasting from omni-modal context for multimodal llms.arXiv preprint arXiv:2601.13836, 2026
-
[25]
Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities, 2025
Ziwei Zhou, Rui Wang, Zuxuan Wu, and Yu-Gang Jiang. Daily-omni: Towards audio-visual reasoning with temporal alignment across modalities.arXiv preprint arXiv:2505.17862, 2025
-
[26]
Omnivideobench: Towards audio-visual understanding evaluation for omni mllms, 2025
Caorui Li, Yu Chen, Yiyan Ji, Jin Xu, Zhenyu Cui, Shihao Li, Yuanxing Zhang, Wentao Wang, Zhenghao Song, Dingling Zhang, et al. Omnivideobench: Towards audio-visual understanding evaluation for omni mllms.arXiv preprint arXiv:2510.10689, 2025
-
[27]
Hallucination of Multimodal Large Language Models: A Survey
Zechen Bai, Pichao Wang, Tianjun Xiao, Tong He, Zongbo Han, Zheng Zhang, and Mike Zheng Shou. Hallucination of multimodal large language models: A survey.arXiv preprint arXiv:2404.18930, 2024
work page internal anchor Pith review arXiv 2024
-
[28]
Kim Sung-Bin, Oh Hyun-Bin, JungMok Lee, Arda Senocak, Joon Son Chung, and Tae-Hyun Oh. Avhbench: A cross-modal hallucination benchmark for audio-visual large language models. arXiv preprint arXiv:2410.18325, 2024
-
[29]
Wenbin Xing, Quanxing Zha, Lizheng Zu, Mengran Li, Ming Li, and Junchi Yan. Learning to decode against compositional hallucination in video multimodal large language models.arXiv preprint arXiv:2602.00559, 2026
-
[30]
Omnibench: Towards the future of universal omni-language models, 2025
Yizhi Li, Yinghao Ma, Ge Zhang, Ruibin Yuan, Kang Zhu, Hangyu Guo, Yiming Liang, Jiaheng Liu, Zekun Wang, Jian Yang, et al. Omnibench: Towards the future of universal omni-language models.arXiv preprint arXiv:2409.15272, 2024. 11
-
[31]
Av-odyssey bench: Can your multimodal llms really understand audio-visual information?, 2024
Kaixiong Gong, Kaituo Feng, Bohao Li, Yibing Wang, Mofan Cheng, Shijia Yang, Jiaming Han, Benyou Wang, Yutong Bai, Zhuoran Yang, et al. Av-odyssey bench: Can your multimodal llms really understand audio-visual information?arXiv preprint arXiv:2412.02611, 2024
-
[32]
Avqa: A dataset for audio-visual question answering on videos
Pinci Yang, Xin Wang, Xuguang Duan, Hong Chen, Runze Hou, Cong Jin, and Wenwu Zhu. Avqa: A dataset for audio-visual question answering on videos. InProceedings of the 30th ACM international conference on multimedia, pages 3480–3491, 2022
work page 2022
-
[33]
Learning to answer questions in dynamic audio-visual scenarios
Guangyao Li, Yake Wei, Yapeng Tian, Chenliang Xu, Ji-Rong Wen, and Di Hu. Learning to answer questions in dynamic audio-visual scenarios. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19108–19118, 2022
work page 2022
-
[34]
Avtrustbench: Assessing and enhancing reliability and robustness in audio-visual llms
Sanjoy Chowdhury, Sayan Nag, Subhrajyoti Dasgupta, Yaoting Wang, Mohamed Elhoseiny, Ruohan Gao, and Dinesh Manocha. Avtrustbench: Assessing and enhancing reliability and robustness in audio-visual llms. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 1590–1601, 2025
work page 2025
-
[35]
arXiv preprint arXiv:2502.04326 (2025)
Jack Hong, Shilin Yan, Jiayin Cai, Xiaolong Jiang, Yao Hu, and Weidi Xie. Worldsense: Evaluat- ing real-world omnimodal understanding for multimodal llms.arXiv preprint arXiv:2502.04326, 2025
-
[36]
Jianghan Chao, Jianzhang Gao, Wenhui Tan, Yuchong Sun, Ruihua Song, and Liyun Ru. Jointavbench: A benchmark for joint audio-visual reasoning evaluation.arXiv preprint arXiv:2512.12772, 2025
work page internal anchor Pith review arXiv 2025
-
[37]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency
Weiyun Wang, Zhangwei Gao, Lixin Gu, Hengjun Pu, Long Cui, Xingguang Wei, Zhaoyang Liu, Linglin Jing, Shenglong Ye, Jie Shao, et al. Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency.arXiv preprint arXiv:2508.18265, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[38]
SmolVLM: Redefining small and efficient multimodal models
Andrés Marafioti, Orr Zohar, Miquel Farré, Merve Noyan, Elie Bakouch, Pedro Cuenca, Cyril Zakka, Loubna Ben Allal, Anton Lozhkov, Nouamane Tazi, et al. Smolvlm: Redefining small and efficient multimodal models.arXiv preprint arXiv:2504.05299, 2025
work page internal anchor Pith review arXiv 2025
-
[39]
Dong Guo, Faming Wu, Feida Zhu, Fuxing Leng, Guang Shi, Haobin Chen, Haoqi Fan, Jian Wang, Jianyu Jiang, Jiawei Wang, et al. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062, 2025
work page internal anchor Pith review arXiv 2025
-
[40]
Nvila: Efficient frontier visual language models
Zhijian Liu, Ligeng Zhu, Baifeng Shi, Zhuoyang Zhang, Yuming Lou, Shang Yang, Haocheng Xi, Shiyi Cao, Yuxian Gu, Dacheng Li, et al. Nvila: Efficient frontier visual language models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4122–4134, 2025
work page 2025
-
[41]
Mimo-vl technical report.arXiv preprint arXiv:2506.03569, 2025
LCT Xiaomi and Core Team. Mimo-vl technical report.arXiv preprint arXiv:2506.03569, 1(2): 5, 2025
-
[42]
Taste: Text-aligned speech tokenization and embedding for spoken language modeling,
Liang-Hsuan Tseng, Yi-Chang Chen, Kuan-Yi Lee, Da-Shan Shiu, and Hung-yi Lee. Taste: Text-aligned speech tokenization and embedding for spoken language modeling.arXiv preprint arXiv:2504.07053, 2025
-
[43]
Ding Ding, Zeqian Ju, Yichong Leng, Songxiang Liu, Tong Liu, Zeyu Shang, Kai Shen, Wei Song, Xu Tan, Heyi Tang, et al. Kimi-audio technical report.arXiv preprint arXiv:2504.18425, 2025
work page internal anchor Pith review arXiv 2025
-
[44]
Sreyan Ghosh, Zhifeng Kong, Sonal Kumar, S Sakshi, Jaehyeon Kim, Wei Ping, Rafael Valle, Dinesh Manocha, and Bryan Catanzaro. Audio flamingo 2: An audio-language model with long-audio understanding and expert reasoning abilities.arXiv preprint arXiv:2503.03983, 2025
-
[45]
Yunfei Chu, Jin Xu, Qian Yang, Haojie Wei, Xipin Wei, Zhifang Guo, Yichong Leng, Yuan- jun Lv, Jinzheng He, Junyang Lin, et al. Qwen2-audio technical report.arXiv preprint arXiv:2407.10759, 2024. 12
work page internal anchor Pith review arXiv 2024
-
[46]
On The Landscape of Spoken Language Models: A Comprehensive Survey
Siddhant Arora, Kai-Wei Chang, Chung-Ming Chien, Yifan Peng, Haibin Wu, Yossi Adi, Emmanuel Dupoux, Hung-Yi Lee, Karen Livescu, and Shinji Watanabe. On the landscape of spoken language models: A comprehensive survey.arXiv preprint arXiv:2504.08528, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[47]
Ola: Pushing the frontiers of omni-modal language model.arXiv preprint arXiv:2502.04328, 2025
Zuyan Liu, Yuhao Dong, Jiahui Wang, Ziwei Liu, Winston Hu, Jiwen Lu, and Yongming Rao. Ola: Pushing the frontiers of omni-modal language model.arXiv preprint arXiv:2502.04328, 2025
-
[48]
Run Luo, Xiaobo Xia, Lu Wang, Longze Chen, Renke Shan, Jing Luo, Min Yang, and Tat- Seng Chua. Next-omni: Towards any-to-any omnimodal foundation models with discrete flow matching.arXiv preprint arXiv:2510.13721, 2025
-
[49]
Vita: Towards open-source interactive omni multimodal llm
Chaoyou Fu, Haojia Lin, Zuwei Long, Yunhang Shen, Yuhang Dai, Meng Zhao, Yi-Fan Zhang, Shaoqi Dong, Yangze Li, Xiong Wang, et al. Vita: Towards open-source interactive omni multimodal llm.arXiv preprint arXiv:2408.05211, 2024
-
[50]
Qingpei Guo, Kaiyou Song, Zipeng Feng, Ziping Ma, Qinglong Zhang, Sirui Gao, Xuzheng Yu, Yunxiao Sun, Tai-Wei Chang, Jingdong Chen, et al. M2-omni: Advancing omni-mllm for com- prehensive modality support with competitive performance.arXiv preprint arXiv:2502.18778, 2025
-
[51]
Emoomni: Bridging emotional understanding and expression in omni-modal llms, 2026
Wenjie Tian, Zhixian Zhao, Jingbin Hu, Huakang Chen, Haohe Liu, Binshen Mu, and Lei Xie. Emoomni: Bridging emotional understanding and expression in omni-modal llms.arXiv preprint arXiv:2602.21900, 2026
-
[52]
Yue Ding, Yiyan Ji, Jungang Li, Xuyang Liu, Xinlong Chen, Junfei Wu, Bozhou Li, Bohan Zeng, Yang Shi, Yushuo Guan, et al. Omnisift: Modality-asymmetric token compression for efficient omni-modal large language models.arXiv preprint arXiv:2602.04804, 2026
work page internal anchor Pith review arXiv 2026
-
[53]
Hanrong Ye, Chao-Han Huck Yang, Arushi Goel, Wei Huang, Ligeng Zhu, Yuanhang Su, Sean Lin, An-Chieh Cheng, Zhen Wan, Jinchuan Tian, et al. Omnivinci: Enhancing architecture and data for omni-modal understanding llm.arXiv preprint arXiv:2510.15870, 2025
-
[54]
Jin Xu, Zhifang Guo, Hangrui Hu, Yunfei Chu, Xiong Wang, Jinzheng He, Yuxuan Wang, Xian Shi, Ting He, Xinfa Zhu, et al. Qwen3-omni technical report.arXiv preprint arXiv:2509.17765, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[55]
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report, 2025. URLhttps://arxiv.org/abs/2503.20215
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[56]
Yuan Liu, Haodong Duan, Yuanhan Zhang, Bo Li, Songyang Zhang, Wangbo Zhao, Yike Yuan, Jiaqi Wang, Conghui He, Ziwei Liu, et al. Mmbench: Is your multi-modal model an all-around player? InEuropean conference on computer vision, pages 216–233. Springer, 2024
work page 2024
-
[57]
Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi
Xiang Yue, Yuansheng Ni, Kai Zhang, Tianyu Zheng, Ruoqi Liu, Ge Zhang, Samuel Stevens, Dongfu Jiang, Weiming Ren, Yuxuan Sun, et al. Mmmu: A massive multi-discipline multimodal understanding and reasoning benchmark for expert agi. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 9556–9567, 2024
work page 2024
-
[58]
MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities
Weihao Yu, Zhengyuan Yang, Linjie Li, Jianfeng Wang, Kevin Lin, Zicheng Liu, Xinchao Wang, and Lijuan Wang. Mm-vet: Evaluating large multimodal models for integrated capabilities. arXiv preprint arXiv:2308.02490, 2023
work page internal anchor Pith review arXiv 2023
-
[59]
MMAU: A Massive Multi-Task Audio Understanding and Reasoning Benchmark
Sakshi Sakshi, Utkarsh Tyagi, Sonal Kumar, Ashish Seth, Ramaneswaran Selvakumar, Oriol Nieto, Ramani Duraiswami, Sreyan Ghosh, and Dinesh Manocha. Mmau: A massive multi-task audio understanding and reasoning benchmark.arXiv preprint arXiv:2410.19168, 2024
work page internal anchor Pith review arXiv 2024
-
[60]
Audiobench: A universal benchmark for audio large language models
Bin Wang, Xunlong Zou, Geyu Lin, Shuo Sun, Zhuohan Liu, Wenyu Zhang, Zhengyuan Liu, AiTi Aw, and Nancy Chen. Audiobench: A universal benchmark for audio large language models. InProceedings of the 2025 Conference of the Nations of the Americas Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), pa...
work page 2025
-
[61]
Towards understanding chain-of-thought prompting: An empirical study of what matters
Dingdong Wang, Junan Li, Jincenzi Wu, Dongchao Yang, Xueyuan Chen, Tianhua Zhang, and Helen Meng. Mmsu: A massive multi-task spoken language understanding and reasoning benchmark.arXiv preprint arXiv:2506.04779, 2025
-
[62]
What are they doing? joint audio-speech co-reasoning
Yingzhi Wang, Pooneh Mousavi, Artem Ploujnikov, and Mirco Ravanelli. What are they doing? joint audio-speech co-reasoning. InICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), pages 1–5. IEEE, 2025
work page 2025
-
[63]
Dhruba Ghosh, Yuhui Zhang, and Ludwig Schmidt. Understanding the fine-grained knowledge capabilities of vision-language models.arXiv preprint arXiv:2602.17871, 2026
-
[64]
Ver-bench: Evaluating mllms on reasoning with fine-grained visual evidence
Chenhui Qiang, Zhaoyang Wei, Xumeng Han, Zipeng Wang, Siyao Li, Xiangyuan Lan, Jianbin Jiao, and Zhenjun Han. Ver-bench: Evaluating mllms on reasoning with fine-grained visual evidence. InProceedings of the 33rd ACM International Conference on Multimedia, pages 12698–12705, 2025
work page 2025
-
[65]
Tengjin Weng, Wenhao Jiang, Jingyi Wang, Ming Li, Lin Ma, and Zhong Ming. Oddgridbench: Exposing the lack of fine-grained visual discrepancy sensitivity in multimodal large language models.arXiv preprint arXiv:2603.09326, 2026
-
[66]
Brace: A benchmark for robust audio caption quality evaluation, 2025
Tianyu Guo, Hongyu Chen, Hao Liang, Meiyi Qiang, Bohan Zeng, Linzhuang Sun, Bin Cui, and Wentao Zhang. Brace: A benchmark for robust audio caption quality evaluation.arXiv preprint arXiv:2512.10403, 2025
-
[67]
Kaining Ying, Fanqing Meng, Jin Wang, Zhiqian Li, Han Lin, Yue Yang, Hao Zhang, Wenbo Zhang, Yuqi Lin, Shuo Liu, et al. Mmt-bench: A comprehensive multimodal benchmark for eval- uating large vision-language models towards multitask agi.arXiv preprint arXiv:2404.16006, 2024
-
[68]
Mmreason: An open-ended multi- modal multi-step reasoning benchmark for mllms toward agi
Huanjin Yao, Jiaxing Huang, Yawen Qiu, Michael K Chen, Wenzheng Liu, Wei Zhang, Wenjie Zeng, Xikun Zhang, Jingyi Zhang, Yuxin Song, et al. Mmreason: An open-ended multi- modal multi-step reasoning benchmark for mllms toward agi. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 273–283, 2025
work page 2025
-
[69]
From easy to hard: The mir benchmark for progressive interleaved multi-image reasoning
Hang Du, Jiayang Zhang, Guoshun Nan, Wendi Deng, Zhenyan Chen, Chenyang Zhang, Wang Xiao, Shan Huang, Yuqi Pan, Tao Qi, et al. From easy to hard: The mir benchmark for progressive interleaved multi-image reasoning. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 859–869, 2025
work page 2025
-
[70]
Jiachun Li, Shaoping Huang, Zhuoran Jin, Chenlong Zhang, Pengfei Cao, Yubo Chen, Kang Liu, and Jun Zhao. Mmr-life: Piecing together real-life scenes for multimodal multi-image reasoning.arXiv preprint arXiv:2603.02024, 2026
-
[71]
Yusu Qian, Cheng Wan, Chao Jia, Yinfei Yang, Qingyu Zhao, and Zhe Gan. Prism- bench: A benchmark of puzzle-based visual tasks with cot error detection.arXiv preprint arXiv:2510.23594, 2025
-
[72]
Video-MME-v2: Towards the Next Stage in Benchmarks for Comprehensive Video Understanding
Chaoyou Fu, Haozhi Yuan, Yuhao Dong, Yi-Fan Zhang, Yunhang Shen, Xiaoxing Hu, Xueying Li, Jinsen Su, Chengwu Long, Xiaoyao Xie, et al. Video-mme-v2: Towards the next stage in benchmarks for comprehensive video understanding.arXiv preprint arXiv:2604.05015, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[73]
Ruchit Rawal, Khalid Saifullah, Miquel Farré, Ronen Basri, David Jacobs, Gowthami Somepalli, and Tom Goldstein. Cinepile: A long video question answering dataset and benchmark.arXiv preprint arXiv:2405.08813, 2024
-
[74]
Linzhuang Sun, Hao Liang, Jingxuan Wei, Bihui Yu, Tianpeng Li, Fan Yang, Zenan Zhou, and Wentao Zhang. Mm-verify: Enhancing multimodal reasoning with chain-of-thought verification. arXiv preprint arXiv:2502.13383, 2025
-
[75]
Minxuan Zhou, Hao Liang, Tianpeng Li, Zhiyu Wu, Mingan Lin, Linzhuang Sun, Yaqi Zhou, Yan Zhang, Xiaoqin Huang, Yicong Chen, et al. Mathscape: Evaluating mllms in multimodal math scenarios through a hierarchical benchmark.arXiv preprint arXiv:2408.07543, 2024. 14
-
[76]
Llms are noisy oracles! llm-based noise-aware graph active learning for node classification
Zeang Sheng, Weiyang Guo, Yingxia Shao, Wentao Zhang, and Bin Cui. Llms are noisy oracles! llm-based noise-aware graph active learning for node classification. InProceedings of the 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V .2, KDD ’25, page 2526–2537, New York, NY , USA, 2025. Association for Computing Machinery. ISBN 97984007145...
-
[77]
Video-holmes: Can MLLM think like holmes for complex video reasoning?CoRR, abs/2505.21374, 2025
Junhao Cheng, Yuying Ge, Teng Wang, Yixiao Ge, Jing Liao, and Ying Shan. Video-holmes: Can mllm think like holmes for complex video reasoning?arXiv preprint arXiv:2505.21374, 2025
-
[78]
Chen Chen, ZeYang Hu, Fengjiao Chen, Liya Ma, Jiaxing Liu, Xiaoyu Li, Ziwen Wang, Xuezhi Cao, and Xunliang Cai. Uno-bench: A unified benchmark for exploring the compositional law between uni-modal and omni-modal in omni models.arXiv preprint arXiv:2510.18915, 2025
-
[79]
Yiman Zhang, Ziheng Luo, Qiangyu Yan, Wei He, Borui Jiang, Xinghao Chen, and Kai Han. Omnieval: A benchmark for evaluating omni-modal models with visual, auditory, and textual inputs.arXiv preprint arXiv:2506.20960, 2025
-
[80]
ZhaoYang Han, Qihan Lin, Hao Liang, Bowen Chen, Zhou Liu, and Wentao Zhang. Longin- sightbench: A comprehensive benchmark for evaluating omni-modal models on human-centric long-video understanding.arXiv preprint arXiv:2510.17305, 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.