Recognition: no theorem link
Stencil Computations on Tenstorrent Wormhole
Pith reviewed 2026-05-11 02:07 UTC · model grok-4.3
The pith
Stencil computations map to the Tenstorrent Wormhole with kernel times matching CPU but full runs slowed by transfers and setup.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
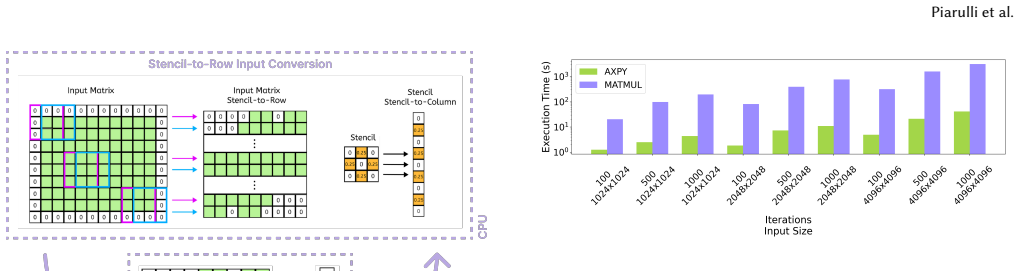
We investigate the mapping of 2D 5-point stencil computations onto the Tenstorrent Wormhole, a RISC-V AI dataflow accelerator. We develop two heterogeneous implementations: Axpy, which decomposes the stencil into element-wise submatrix operations, and MatMul, which reformulates it as a matrix multiplication. While the CPU baseline remains 3x faster end-to-end, profiling reveals that the isolated Wormhole kernel is competitive with CPU execution, with the gap driven by PCIe transfers, device initialization, and host-side preprocessing. Despite slower runtime, Axpy achieves lower energy consumption than the CPU baseline for large inputs.
What carries the argument
The Axpy and MatMul heterogeneous implementations that adapt the five-point stencil to the Wormhole RISC-V dataflow architecture.
If this is right
- Reducing PCIe, initialization, and host preprocessing costs would make the Wormhole kernel competitive end-to-end for stencil workloads.
- Energy advantages in the Axpy mapping could favor the accelerator for large problems even if runtime is not yet superior.
- Detailed profiling of data-movement and setup overheads supplies concrete targets for hardware and software changes.
- The same decomposition techniques could extend to other grid-based scientific kernels on similar accelerators.
Where Pith is reading between the lines
- The overhead pattern observed here would likely appear in other AI accelerators unless they integrate memory more tightly with the host.
- Testing the same mappings on larger grids or three-dimensional stencils would show whether the competitiveness holds at scale.
- If the main limiter is data movement, on-device memory or direct host integration would close most of the end-to-end gap.
Load-bearing premise
That the Axpy and MatMul versions are efficient and fair mappings of the stencil and that the chosen CPU baseline and measurement method permit direct comparison.
What would settle it
A side-by-side run of the identical stencil on Wormhole and CPU where data already resides in accelerator memory with no PCIe transfers or host preprocessing, measuring only kernel time and energy.
Figures





read the original abstract
As investment in AI-focused accelerators grows and their deployment in supercomputing facilities expands, understanding whether these architectures can efficiently support traditional scientific kernels is critical for the future of High-Performance Computing. We investigate the mapping of 2D 5-point stencil computations onto the Tenstorrent Wormhole, a RISC-V AI dataflow accelerator. We develop two heterogeneous implementations: Axpy, which decomposes the stencil into element-wise submatrix operations, and MatMul, which reformulates it as a matrix multiplication. While the CPU baseline remains 3x faster end-to-end, profiling reveals that the isolated Wormhole kernel is competitive with CPU execution, with the gap driven by PCIe transfers, device initialization, and host-side preprocessing. Despite slower runtime, Axpy achieves lower energy consumption than the CPU baseline for large inputs. Through detailed profiling and theoretical analysis, we identify key architectural and software limitations of the current platform and outline concrete hardware and software directions that could make AI accelerators competitive for HPC workloads.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper maps 2D 5-point stencil computations to the Tenstorrent Wormhole RISC-V AI accelerator via two heterogeneous implementations: Axpy (decomposing into element-wise submatrix operations) and MatMul (reformulating as matrix multiplication). It reports that a CPU baseline remains 3x faster end-to-end, but the isolated Wormhole kernel is competitive, with the gap driven by PCIe transfers, device initialization, and host-side preprocessing. Axpy achieves lower energy consumption than the CPU baseline for large inputs, supported by profiling and theoretical analysis that identify architectural and software limitations and suggest hardware/software directions for competitiveness in HPC workloads.
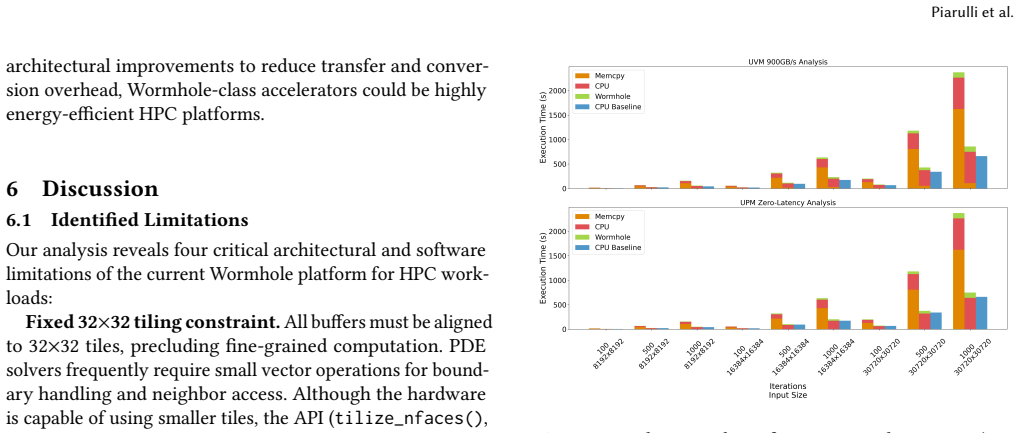
Significance. If the performance attribution and energy results hold, the work contributes empirical evidence on adapting AI dataflow accelerators to traditional scientific kernels, with the separation of kernel vs. overhead times and the theoretical analysis providing concrete guidance for future platform improvements. The reproducible profiling approach and focus on energy efficiency for large inputs are strengths that could inform supercomputing deployments.
major comments (2)
- [Abstract] Abstract: The central claim that 'Axpy achieves lower energy consumption than the CPU baseline for large inputs' is load-bearing for the efficiency argument, yet the text does not specify the energy measurement methodology (e.g., device-only sensors/APIs for Wormhole vs. full-system or package-level tools such as RAPL for CPU) or confirm that host-side preprocessing and PCIe costs are accounted equivalently on both platforms. This risks the reported advantage being an artifact of inconsistent accounting rather than architectural merit.
- [Abstract] The manuscript's soundness assessment notes the absence of full methods, error bars, or raw data, which directly impacts verification of the performance gap attribution (PCIe, initialization, host preprocessing) and the competitiveness of the isolated kernel. Without these, the claim that the Wormhole kernel is competitive cannot be fully evaluated against the CPU baseline.
minor comments (2)
- The abstract and profiling description would benefit from explicit cross-references to the sections detailing the Axpy and MatMul implementations, including any pseudocode or kernel launch parameters.
- Clarify the stencil size, grid dimensions, and input scales used for the 'large inputs' energy comparison to allow direct reproduction.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments correctly identify areas where greater methodological transparency is needed to support the claims. We address each point below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that 'Axpy achieves lower energy consumption than the CPU baseline for large inputs' is load-bearing for the efficiency argument, yet the text does not specify the energy measurement methodology (e.g., device-only sensors/APIs for Wormhole vs. full-system or package-level tools such as RAPL for CPU) or confirm that host-side preprocessing and PCIe costs are accounted equivalently on both platforms. This risks the reported advantage being an artifact of inconsistent accounting rather than architectural merit.
Authors: We agree that the abstract does not explicitly describe the energy measurement methodology, which is necessary for proper interpretation. In the full manuscript, Wormhole energy is obtained from on-device power sensors and APIs, while CPU energy is measured at the package level using RAPL. Both platforms incorporate host-side preprocessing, PCIe transfers, and initialization costs into the reported energy figures by capturing the full end-to-end execution. To eliminate any ambiguity, we will revise the abstract to state the measurement approach concisely and add a dedicated methods subsection that details the tools, equivalence of accounting, and any platform-specific adjustments. revision: yes
-
Referee: [Abstract] The manuscript's soundness assessment notes the absence of full methods, error bars, or raw data, which directly impacts verification of the performance gap attribution (PCIe, initialization, host preprocessing) and the competitiveness of the isolated kernel. Without these, the claim that the Wormhole kernel is competitive cannot be fully evaluated against the CPU baseline.
Authors: We accept that the current manuscript lacks sufficient detail on experimental methods, error bars, and public raw data, which hinders independent verification of the overhead attributions and kernel competitiveness. The profiling breakdowns and theoretical analysis are present, but we will expand the methods section with complete hardware/software configurations, add error bars (standard deviation across repeated runs) to all performance and energy plots, and release the raw measurement data together with analysis scripts in a public repository upon acceptance. These changes will enable full evaluation of the reported results. revision: yes
Circularity Check
Purely empirical performance study with no derivations or self-referential claims
full rationale
The paper reports direct measurements of runtime, energy consumption, and profiling data for two heterogeneous stencil implementations (Axpy and MatMul) on the Wormhole accelerator, compared against an external CPU baseline. No equations, predictions, fitted parameters, or first-principles derivations are presented that could reduce to their own inputs. The abstract and description reference theoretical analysis only in the context of identifying architectural limitations from observed data, not as load-bearing self-referential logic. Energy claims rest on reported measurements rather than any constructed equivalence. This is a standard empirical HPC benchmarking study with no circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
2025. Dissecting the Tenstorrent Blackhole Architecture via Mi- crobenchmarking.https://asplos.dev/wordpress/wp-content/uploads/ 2025/09/TT_bench-1.pdf. Accessed: 2025-11-01
work page 2025
-
[2]
Giorgio Amati, Matteo Turisini, Andrea Monterubbiano, Mattia Pal- adino, Elisabetta Boella, Daniele Gregori, and Danilo Croce. 2025. Ac- celerating Gravitational N-Body Simulations Using the RISC-V-Based Tenstorrent Wormhole. InProceedings of the SC’25 Workshops of the International Conference for High Performance Computing, Networking, Storage and Analys...
-
[3]
AMD Corporation. 2023. AMD Instinct MI300A APU Product Overview.https://www.amd.com/en/products/accelerators/instinct/ mi300a.html. Accessed: 2025-10-05
work page 2023
-
[4]
Nick Brown and Ryan Barton. 2024. Accelerating Stencils on the Tenstorrent Grayskull RISC-V Accelerator. InSC24-W: Workshops of the International Conference for High Performance Computing, Networking, Storage and Analysis. IEEE, 1690–1700. doi:10.1109/SCW63240.2024. 00211
- [5]
- [6]
-
[7]
Yuetao Chen, Kun Li, Yuhao Wang, Donglin Bai, Lei Wang, Lingxiao Ma, Liang Yuan, Yunquan Zhang, Ting Cao, and Mao Yang. 2024. ConvStencil: Transform Stencil Computation to Matrix Multiplication on Tensor Cores. InProceedings of the 29th ACM SIGPLAN Annual Symposium on Principles and Practice of Parallel Programming (PPoPP ’24). ACM, 333–347
work page 2024
-
[8]
corsix. 2024. Community Highlight: Tenstorrent Wormhole Series Part 2: Which disabled rows? Tenstorrent News- room.https://tenstorrent.com/newsroom/community-highlight- tenstorrent-wormhole-series-part-2-which-disabled-rowsAccessed: 2024-11-18
work page 2024
-
[9]
P. Giannozzi, O. Baseggio, P. Bonfà, D. Brunato, R. Car, I. Carnimeo, C. Cavazzoni, S. De Gironcoli, P. Delugas, F. Ferrari Ruffino, et al. 2020. Quantum ESPRESSO Toward the Exascale.The Journal of Chemical Physics152, 15 (2020)
work page 2020
-
[10]
NVIDIA Corporation. 2023. NVIDIA GH200 Grace Hopper Su- perchip.https://www.nvidia.com/en-us/data-center/grace-hopper- superchip/. Accessed: 2025-10-05
work page 2023
-
[11]
J. Schmidhuber. 2015. Deep Learning in Neural Networks: An Overview.Neural Networks61 (2015), 85–117
work page 2015
-
[12]
Bartosz Taudul. 2024. Tracy Profiler.https://github.com/wolfpld/ tracy
work page 2024
-
[13]
Tenstorrent. 2025. Blackhole Accelerator Specifications.https://docs. tenstorrent.com/aibs/blackhole/specifications.html. Accessed: 2025- 11-01
work page 2025
-
[14]
Tenstorrent. 2025. Wormhole Accelerator Specifications.https:// docs.tenstorrent.com/aibs/wormhole/specifications.html. Accessed: 2025-09-11
work page 2025
-
[15]
2024.Tensix Neo: RISC-V-based AI IP For Extraordinary AI Performance
Tenstorrent Inc. 2024.Tensix Neo: RISC-V-based AI IP For Extraordinary AI Performance. Tenstorrent.https://tenstorrent.com/ip/tensix-neo Accessed: 2024-11-18
work page 2024
-
[16]
Jasmina Vasiljevic and Davor Capalija. 2024. Blackhole & TT- Metalium: The Standalone AI Computer and Its Programming Model. InHot Chips 36
work page 2024
-
[17]
A. Zeni, G. Guidi, M. Ellis, N. Ding, M. D. Santambrogio, S. Hofmeyr, A. Buluç, L. Oliker, and K. Yelick. 2020. Logan: High-Performance GPU-Based X-Drop Long-Read Alignment. In2020 IEEE International Parallel and Distributed Processing Symposium (IPDPS). IEEE, 462–471
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.