Recognition: 2 theorem links
· Lean TheoremSAM 3D Animal: Promptable Animal 3D Reconstruction from Images in the Wild
Pith reviewed 2026-05-11 02:06 UTC · model grok-4.3
The pith
SAM 3D Animal reconstructs multiple animals in 3D from a single wild image using keypoints or mask prompts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
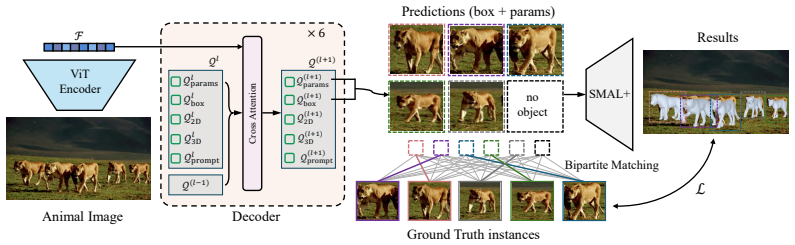
We present SAM 3D Animal, the first promptable framework for multi-animal 3D reconstruction from a single image. Built on the SMAL+ parametric animal model, our method jointly reconstructs multiple instances and supports flexible prompts in the form of keypoints and masks which enable more reliable disambiguation in crowded and occluded scenes. To train such a model, we further introduce Herd3D, a multi-animal 3D dataset containing over 5K images, designed to increase diversity in species, interactions, and occlusion patterns.
What carries the argument
A promptable multi-instance reconstruction pipeline that conditions the SMAL+ parametric model on user keypoints or masks to separate and optimize several animals at once.
If this is right
- Multi-animal scenes with heavy occlusion become tractable without manual separation.
- User prompts improve accuracy in ambiguous cases where automatic methods alone fail.
- A single model can handle diverse species instead of requiring separate networks per animal type.
- The approach scales reconstruction to group interactions that single-animal pipelines ignore.
Where Pith is reading between the lines
- The same prompting idea could be applied to video to track 3D animal motion across frames.
- Automatic prompt generators from other vision models might remove the need for manual input.
- Wildlife researchers could use the output 3D poses to measure social distances or feeding patterns.
- The Herd3D dataset itself may serve as a benchmark for future multi-animal pose estimation work.
Load-bearing premise
The SMAL+ parametric animal model is expressive enough to capture the shapes, poses, and interactions of many different species seen in wild scenes.
What would settle it
A test image of animals whose body proportions or joint angles lie far outside the SMAL+ parameter range, accompanied by accurate 3D ground truth, where the framework produces visibly incorrect shapes.
Figures









read the original abstract
3D animal reconstruction in the wild remains challenging due to large species variation, frequent occlusions, and the prevalence of multi-animal scenes, while existing methods predominantly focus on single-animal settings. We present SAM 3D Animal, the first promptable framework for multi-animal 3D reconstruction from a single image. Built on the SMAL+ parametric animal model, our method jointly reconstructs multiple instances and supports flexible prompts in the form of keypoints and masks which enable more reliable disambiguation in crowded and occluded scenes. To train such a model, we further introduce Herd3D, a multi-animal 3D dataset containing over 5K images, designed to increase diversity in species, interactions, and occlusion patterns. Experiments on the Animal3D, APTv2, and Animal Kingdom datasets show that our framework achieves state-of-the-art results over both existing model-based and model-free methods, demonstrating a scalable and effective solution for prompt-driven animal 3D reconstruction in the wild.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces SAM 3D Animal, the first promptable framework for multi-animal 3D reconstruction from a single image in the wild. It builds on the SMAL+ parametric model to jointly reconstruct multiple instances, supports flexible prompts (keypoints and masks) for disambiguation in occluded scenes, introduces the Herd3D dataset (>5K images emphasizing species diversity, interactions, and occlusions), and reports state-of-the-art results on Animal3D, APTv2, and Animal Kingdom against both model-based and model-free baselines.
Significance. If the quantitative claims hold, the work provides a practical advance for prompt-driven 3D animal reconstruction in complex wild scenes, with potential downstream value in ecology and animation. The Herd3D dataset is a concrete contribution that increases coverage of multi-animal interactions. However, the significance is tempered by the unverified assumption that SMAL+ spans the required shape/pose variation; without evidence that this parametric backbone is not the limiting factor, the SOTA numbers may reflect dataset-specific fitting rather than a general solution.
major comments (2)
- [§3 and §4] §3 (Method) and §4 (Experiments): The central claim of reliable multi-animal reconstruction in the wild rests on SMAL+ being sufficiently expressive for the species, body proportions, and interaction-induced deformations in Herd3D and the test sets. No explicit ablation or residual analysis of SMAL+ fitting error on these new species is reported, which is load-bearing because systematic under-expressiveness would cause joint reconstruction and prompt-based disambiguation to fail independently of the SAM prompting or training procedure.
- [§4.2] §4.2 (Quantitative results): The abstract and results claim SOTA over model-based and model-free methods, yet the provided text gives no numerical values, error bars, or per-species breakdowns. This makes it impossible to assess whether gains are consistent across the claimed diversity or driven by easier subsets, directly affecting the strength of the multi-animal claim.
minor comments (2)
- [Abstract] The abstract states SOTA results without any quantitative support; moving at least one key table or metric summary into the abstract would improve readability.
- [§3.1] Notation for prompt inputs (keypoints vs. masks) and how they are fused into the SMAL+ optimization should be clarified with a small diagram or equation in §3.1.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We address each major comment point-by-point below and have made revisions to strengthen the manuscript where the concerns are valid.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Method) and §4 (Experiments): The central claim of reliable multi-animal reconstruction in the wild rests on SMAL+ being sufficiently expressive for the species, body proportions, and interaction-induced deformations in Herd3D and the test sets. No explicit ablation or residual analysis of SMAL+ fitting error on these new species is reported, which is load-bearing because systematic under-expressiveness would cause joint reconstruction and prompt-based disambiguation to fail independently of the SAM prompting or training procedure.
Authors: We agree that an explicit analysis of SMAL+ expressiveness on the new data is necessary to support the claims. In the revised manuscript we have added a dedicated ablation subsection (now §4.3) that reports SMAL+ fitting residuals on Herd3D and the three test sets. The analysis includes per-species mean per-vertex error, pose and shape parameter statistics, and qualitative examples of residual deformations. We also discuss the implications for multi-animal scenes and note that while SMAL+ is the most expressive publicly available parametric model, it remains a modeling choice; our prompt-based joint optimization still yields measurable gains over single-instance baselines even on species where SMAL+ residuals are higher. revision: yes
-
Referee: [§4.2] §4.2 (Quantitative results): The abstract and results claim SOTA over model-based and model-free methods, yet the provided text gives no numerical values, error bars, or per-species breakdowns. This makes it impossible to assess whether gains are consistent across the claimed diversity or driven by easier subsets, directly affecting the strength of the multi-animal claim.
Authors: We apologize for the lack of explicit numerical values in the running text of §4.2. The full quantitative results, including all numerical values, standard deviations (error bars), and per-species breakdowns, are already present in Tables 1–3. In the revision we have (i) inserted direct references and key numerical excerpts from these tables into the main text of §4.2, (ii) added a short paragraph summarizing consistency across species and multi-animal subsets, and (iii) included a supplementary per-species error plot. These changes make the SOTA claims directly verifiable from the text without requiring the reader to consult the tables for every claim. revision: yes
Circularity Check
No circularity: framework builds on external SMAL+ model and new dataset with independent benchmark evaluations
full rationale
The paper's derivation chain consists of adopting the pre-existing SMAL+ parametric model as a fixed base, introducing a new multi-animal dataset (Herd3D) for training, and then reporting experimental performance on separate benchmark datasets (Animal3D, APTv2, Animal Kingdom). These steps do not reduce to self-definitional loops, fitted inputs renamed as predictions, or load-bearing self-citations that justify the central claims by construction. The prompt-based joint reconstruction procedure is trained and evaluated externally rather than being equivalent to its inputs by definition. No uniqueness theorems, ansatzes, or renamings of known results are invoked in a circular manner within the provided text.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearBuilt on the SMAL+ parametric animal model... supports flexible prompts in the form of keypoints and masks... set-prediction paradigm... DETR-style bipartite matching
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearExperiments on the Animal3D, APTv2, and Animal Kingdom datasets show that our framework achieves state-of-the-art results
Reference graph
Works this paper leans on
-
[1]
Liang An, Jin Lyu, Li Lin, Pujin Cheng, Yebin Liu, and Xiaoying Tang. Animer+: Unified pose and shape estimation across mammalia and aves via family-aware transformer.IEEE Transactions on Pattern Analysis and Machine Intelligence, 48(3):3233–3249, 2026
work page 2026
-
[2]
Saor: Single-view articulated object reconstruction
Mehmet Aygun and Oisin Mac Aodha. Saor: Single-view articulated object reconstruction. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10382–10391, 2024
work page 2024
-
[3]
A novel dataset for keypoint detection of quadruped animals from images, 2021
Prianka Banik, Lin Li, and Xishuang Dong. A novel dataset for keypoint detection of quadruped animals from images, 2021
work page 2021
-
[4]
Multi-hmr: Multi-person whole-body human mesh recovery in a single shot
Fabien Baradel, Matthieu Armando, Salma Galaaoui, Romain Brégier, Philippe Weinzaepfel, Grégory Rogez, and Thomas Lucas. Multi-hmr: Multi-person whole-body human mesh recovery in a single shot. InEuropean Conference on Computer Vision, pages 202–218. Springer, 2024
work page 2024
-
[5]
Who left the dogs out? 3d animal reconstruction with expectation maximization in the loop
Benjamin Biggs, Oliver Boyne, James Charles, Andrew Fitzgibbon, and Roberto Cipolla. Who left the dogs out? 3d animal reconstruction with expectation maximization in the loop. In European Conference on Computer Vision, pages 195–211. Springer, 2020
work page 2020
-
[6]
Creatures great and smal: Recovering the shape and motion of animals from video
Benjamin Biggs, Thomas Roddick, Andrew Fitzgibbon, and Roberto Cipolla. Creatures great and smal: Recovering the shape and motion of animals from video. InAsian Conference on Computer Vision, pages 3–19. Springer, 2018
work page 2018
-
[7]
Smal-pets: Smal based avatars of pets from single image.arXiv preprint arXiv:2603.17131, 2026
Piotr Borycki, Yizhe Zhu, Yongqiang Gao, Przemys´L Spurek, et al. Smal-pets: Smal based avatars of pets from single image.arXiv preprint arXiv:2603.17131, 2026
-
[8]
Cross- domain adaptation for animal pose estimation
Jinkun Cao, Hongyang Tang, Hao-Shu Fang, Xiaoyong Shen, Cewu Lu, and Yu-Wing Tai. Cross- domain adaptation for animal pose estimation. InProceedings of the IEEE/CVF international conference on computer vision, pages 9498–9507, 2019
work page 2019
-
[9]
Sam 3: Segment anything with concepts, 2026
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, Jie Lei, Tengyu Ma, Baishan Guo, Arpit Kalla, Markus Marks, Joseph Greer, Meng Wang, Peize Sun, Roman Rädle, Triantafyllos Afouras, Effrosyni Mavroudi, Katherine Xu, Tsung-Han Wu, Yu Zhou, Liliane ...
work page 2026
-
[10]
End-to-end object detection with transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, and Sergey Zagoruyko. End-to-end object detection with transformers. InEuropean conference on computer vision, pages 213–229. Springer, 2020
work page 2020
-
[11]
Thomas J Cashman and Andrew W Fitzgibbon. What shape are dolphins? building 3d morphable models from 2d images.IEEE transactions on pattern analysis and machine intelligence, 35(1):232–244, 2012
work page 2012
-
[12]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Alexey Dosovitskiy. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[13]
Mingqi Gao, Yunqi Miao, and Jungong Han. Sam-body4d: Training-free 4d human body mesh recovery from videos.arXiv preprint arXiv:2512.08406, 2025
-
[14]
Shape and viewpoint without keypoints
Shubham Goel, Angjoo Kanazawa, and Jitendra Malik. Shape and viewpoint without keypoints. InEuropean Conference on Computer Vision, pages 88–104. Springer, 2020
work page 2020
-
[15]
Humans in 4d: Reconstructing and tracking humans with transformers
Shubham Goel, Georgios Pavlakos, Jathushan Rajasegaran, Angjoo Kanazawa, and Jitendra Malik. Humans in 4d: Reconstructing and tracking humans with transformers. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14783–14794, 2023
work page 2023
-
[16]
Farm3d: Learning articulated 3d animals by distilling 2d diffusion
Tomas Jakab, Ruining Li, Shangzhe Wu, Christian Rupprecht, and Andrea Vedaldi. Farm3d: Learning articulated 3d animals by distilling 2d diffusion. In2024 International Conference on 3D Vision (3DV), pages 852–861. IEEE, 2024. 10
work page 2024
-
[17]
Monocular mesh recovery and body measurement of female saanen goats
Bo Jin, Jin Lyu, Bin Zhang, Tao Yu, Liang An, Yebin Liu, Meili Wang, et al. Monocular mesh recovery and body measurement of female saanen goats. InProceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 38670–38678, 2026
work page 2026
-
[18]
End-to-end recovery of human shape and pose
Angjoo Kanazawa, Michael J Black, David W Jacobs, and Jitendra Malik. End-to-end recovery of human shape and pose. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 7122–7131, 2018
work page 2018
-
[19]
Harold W Kuhn. The hungarian method for the assignment problem.Naval research logistics quarterly, 2(1-2):83–97, 1955
work page 1955
-
[20]
Reconstructing animals and the wild
Peter Kulits, Michael J Black, and Silvia Zuffi. Reconstructing animals and the wild. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 16565–16577, 2025
work page 2025
-
[21]
Ci Li, Nima Ghorbani, Sofia Broomé, Maheen Rashid, Michael J Black, Elin Hernlund, Hedvig Kjellström, and Silvia Zuffi. hsmal: Detailed horse shape and pose reconstruction for motion pattern recognition.arXiv preprint arXiv:2106.10102, 2021
-
[22]
Dn-detr: Accelerate detr training by introducing query denoising
Feng Li, Hao Zhang, Shilong Liu, Jian Guo, Lionel M Ni, and Lei Zhang. Dn-detr: Accelerate detr training by introducing query denoising. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 13619–13627, 2022
work page 2022
-
[23]
AnyLift: Scaling Motion Reconstruction from Internet Videos via 2D Diffusion
Hongjie Li, Heng Yu, Jiaman Li, Hong-Xing Yu, Ehsan Adeli, C Karen Liu, and Jiajun Wu. Anylift: Scaling motion reconstruction from internet videos via 2d diffusion.arXiv preprint arXiv:2604.17818, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[24]
Learning the 3d fauna of the web
Zizhang Li, Dor Litvak, Ruining Li, Yunzhi Zhang, Tomas Jakab, Christian Rupprecht, Shangzhe Wu, Andrea Vedaldi, and Jiajun Wu. Learning the 3d fauna of the web. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9752–9762, 2024
work page 2024
-
[25]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
work page 2014
-
[26]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[27]
Jin Lyu, Liang An, Pujin Cheng, Yebin Liu, and Xiaoying Tang. 4dequine: Disentangling motion and appearance for 4d equine reconstruction from monocular video.Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2026
work page 2026
-
[28]
Animer: Animal pose and shape estimation using family aware transformer
Jin Lyu, Tianyi Zhu, Yi Gu, Li Lin, Pujin Cheng, Yebin Liu, Xiaoying Tang, and Liang An. Animer: Animal pose and shape estimation using family aware transformer. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 17486–17496, 2025
work page 2025
-
[29]
Animal kingdom: A large and diverse dataset for animal behavior understanding
Xun Long Ng, Kian Eng Ong, Qichen Zheng, Yun Ni, Si Yong Yeo, and Jun Liu. Animal kingdom: A large and diverse dataset for animal behavior understanding. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 19023–19034, 2022
work page 2022
-
[30]
Tomasz Niewiadomski, Anastasios Yiannakidis, Hanz Cuevas-Velasquez, Soubhik Sanyal, Michael J Black, Silvia Zuffi, and Peter Kulits. Generative zoo. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 8492–8502, 2025
work page 2025
-
[31]
Generalized intersection over union: A metric and a loss for bounding box regression
Hamid Rezatofighi, Nathan Tsoi, JunYoung Gwak, Amir Sadeghian, Ian Reid, and Silvio Savarese. Generalized intersection over union: A metric and a loss for bounding box regression. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 658–666, 2019
work page 2019
-
[32]
Barc: Learning to regress 3d dog shape from images by exploiting breed information
Nadine Rueegg, Silvia Zuffi, Konrad Schindler, and Michael J Black. Barc: Learning to regress 3d dog shape from images by exploiting breed information. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 3876–3884, 2022. 11
work page 2022
-
[33]
Sat-hmr: Real-time multi-person 3d mesh estimation via scale-adaptive tokens
Chi Su, Xiaoxuan Ma, Jiajun Su, and Yizhou Wang. Sat-hmr: Real-time multi-person 3d mesh estimation via scale-adaptive tokens. InProceedings of the Computer Vision and Pattern Recognition Conference (CVPR), pages 16796–16806, June 2025
work page 2025
- [34]
-
[35]
Prompthmr: Promptable human mesh recovery
Yufu Wang, Yu Sun, Priyanka Patel, Kostas Daniilidis, Michael J Black, and Muhammed Kocabas. Prompthmr: Promptable human mesh recovery. InProceedings of the computer vision and pattern recognition conference, pages 1148–1159, 2025
work page 2025
-
[36]
Tram: Global trajectory and motion of 3d humans from in-the-wild videos
Yufu Wang, Ziyun Wang, Lingjie Liu, and Kostas Daniilidis. Tram: Global trajectory and motion of 3d humans from in-the-wild videos. InEuropean Conference on Computer Vision, pages 467–487. Springer, 2024
work page 2024
-
[37]
Qwen-image technical report, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun...
work page 2025
-
[38]
Shangzhe Wu, Tomas Jakab, Christian Rupprecht, and Andrea Vedaldi. Dove: Learn- ing deformable 3d objects by watching videos.International Journal of Computer Vision, 131(10):2623–2634, 2023
work page 2023
-
[39]
Magicpony: Learning articulated 3d animals in the wild
Shangzhe Wu, Ruining Li, Tomas Jakab, Christian Rupprecht, and Andrea Vedaldi. Magicpony: Learning articulated 3d animals in the wild. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8792–8802, 2023
work page 2023
-
[40]
De-rendering the world’s revolutionary artefacts
Shangzhe Wu, Ameesh Makadia, Jiajun Wu, Noah Snavely, Richard Tucker, and Angjoo Kanazawa. De-rendering the world’s revolutionary artefacts. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6338–6347, 2021
work page 2021
-
[41]
Animal3d: A comprehensive dataset of 3d animal pose and shape
Jiacong Xu, Yi Zhang, Jiawei Peng, Wufei Ma, Artur Jesslen, Pengliang Ji, Qixin Hu, Jiehua Zhang, Qihao Liu, Jiahao Wang, et al. Animal3d: A comprehensive dataset of 3d animal pose and shape. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9099–9109, 2023
work page 2023
-
[42]
Yufei Xu, Jing Zhang, Qiming Zhang, and Dacheng Tao. Vitpose: Simple vision transformer baselines for human pose estimation.Advances in neural information processing systems, 35:38571–38584, 2022
work page 2022
-
[43]
Viser: Video-specific surface embeddings for articulated 3d shape reconstruction
Gengshan Yang, Deqing Sun, Varun Jampani, Daniel Vlasic, Forrester Cole, Ce Liu, and Deva Ramanan. Viser: Video-specific surface embeddings for articulated 3d shape reconstruction. Advances in Neural Information Processing Systems, 34:19326–19338, 2021
work page 2021
-
[44]
Sam 3d body: Robust full-body human mesh recovery, 2026
Xitong Yang, Devansh Kukreja, Don Pinkus, Anushka Sagar, Taosha Fan, Jinhyung Park, Soyong Shin, Jinkun Cao, Jiawei Liu, Nicolas Ugrinovic, Matt Feiszli, Jitendra Malik, Piotr Dollar, and Kris Kitani. Sam 3d body: Robust full-body human mesh recovery, 2026
work page 2026
-
[45]
Aptv2: Benchmarking animal pose estimation and tracking with a large-scale dataset and beyond, 2023
Yuxiang Yang, Yingqi Deng, Yufei Xu, and Jing Zhang. Aptv2: Benchmarking animal pose estimation and tracking with a large-scale dataset and beyond, 2023
work page 2023
-
[46]
Yuxiang Yang, Junjie Yang, Yufei Xu, Jing Zhang, Long Lan, and Dacheng Tao. Apt-36k: A large-scale benchmark for animal pose estimation and tracking.Advances in Neural Information Processing Systems, 35:17301–17313, 2022
work page 2022
-
[47]
Chun-Han Yao, Wei-Chih Hung, Yuanzhen Li, Michael Rubinstein, Ming-Hsuan Yang, and Varun Jampani. Lassie: Learning articulated shapes from sparse image ensemble via 3d part discovery.Advances in Neural Information Processing Systems, 35:15296–15308, 2022
work page 2022
-
[48]
Pymaf-x: Towards well-aligned full-body model regression from monocular images
Hongwen Zhang, Yating Tian, Yuxiang Zhang, Mengcheng Li, Liang An, Zhenan Sun, and Yebin Liu. Pymaf-x: Towards well-aligned full-body model regression from monocular images. IEEE Transactions on Pattern Analysis and Machine Intelligence, 45(10):12287–12303, 2023. 12
work page 2023
-
[49]
Pymaf: 3d human pose and shape regression with pyramidal mesh alignment feedback loop
Hongwen Zhang, Yating Tian, Xinchi Zhou, Wanli Ouyang, Yebin Liu, Limin Wang, and Zhenan Sun. Pymaf: 3d human pose and shape regression with pyramidal mesh alignment feedback loop. InProceedings of the IEEE/CVF international conference on computer vision, pages 11446–11456, 2021
work page 2021
-
[50]
Awol: Analysis without synthesis using language
Silvia Zuffi and Michael J Black. Awol: Analysis without synthesis using language. InEuropean Conference on Computer Vision, pages 1–19. Springer, 2024
work page 2024
-
[51]
Lions and tigers and bears: Capturing non- rigid, 3d, articulated shape from images
Silvia Zuffi, Angjoo Kanazawa, and Michael J Black. Lions and tigers and bears: Capturing non- rigid, 3d, articulated shape from images. InProceedings of the IEEE conference on Computer Vision and Pattern Recognition, pages 3955–3963, 2018
work page 2018
-
[52]
3d menagerie: Modeling the 3d shape and pose of animals
Silvia Zuffi, Angjoo Kanazawa, David W Jacobs, and Michael J Black. 3d menagerie: Modeling the 3d shape and pose of animals. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 6365–6373, 2017
work page 2017
-
[53]
Varen: Very accurate and realistic equine network
Silvia Zuffi, Ylva Mellbin, Ci Li, Markus Hoeschle, Hedvig Kjellström, Senya Polikovsky, Elin Hernlund, and Michael J Black. Varen: Very accurate and realistic equine network. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5374–5383, 2024. 13 A Bipartite Matching Details We formulate the assignment between the ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.