Recognition: 2 theorem links
· Lean TheoremIs She Even Relevant? When BERT Ignores Explicit Gender Cues
Pith reviewed 2026-05-11 02:09 UTC · model grok-4.3
The pith
Dutch BERT fails to update gender representations when explicit cues contradict stereotypes in short sentences.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
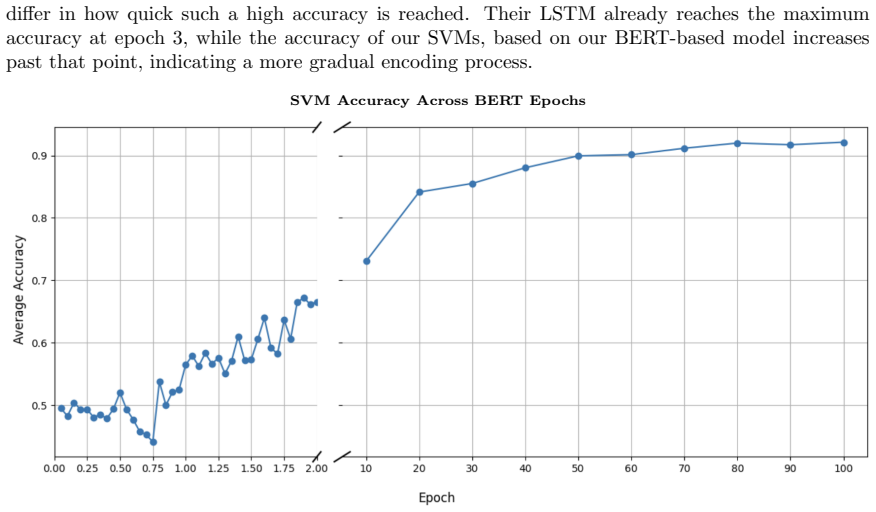
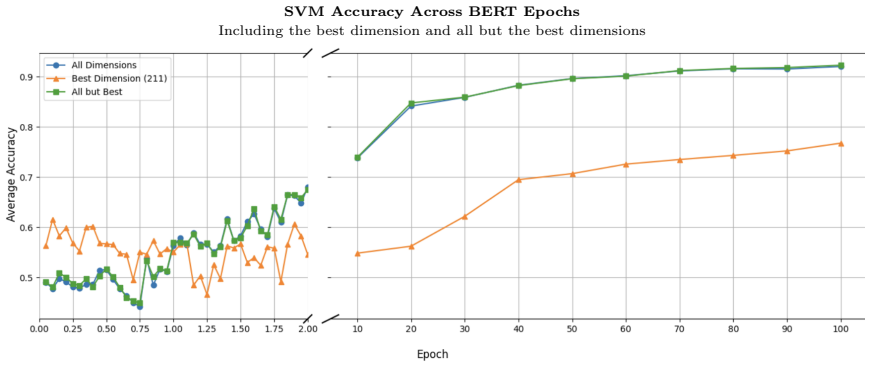
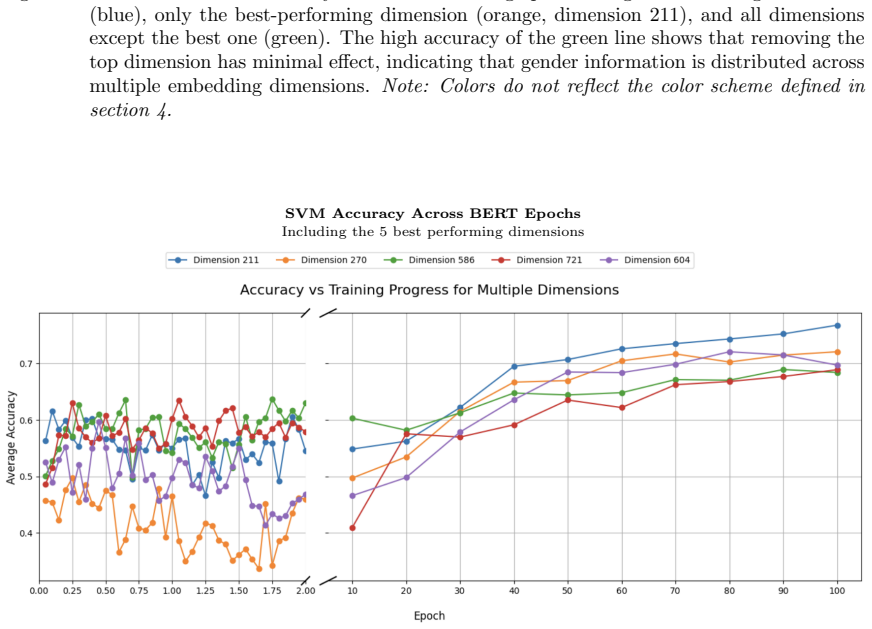
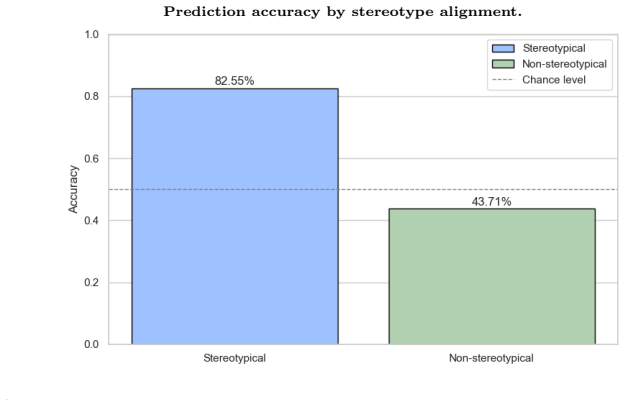
Although gender becomes clearly linearly separable around epoch 20 and is distributed across multiple embedding dimensions, the model struggles to update its internal gender representation in light of explicit contextual cues in short sentence templates. Stereotypical gender-profession pairings are predicted far more accurately than anti-stereotypical ones, and generic forms in Dutch systematically default to a male interpretation, even when the context explicitly denotes a female referent.
What carries the argument
Dynamic gender subspaces built with linear SVMs on contextual embeddings extracted at each training checkpoint, paired with controlled sentence templates that contrast explicit gender cues against learned statistical associations.
If this is right
- Gender information becomes linearly encoded during training but does not translate into flexible use of that information in context.
- Explicit female cues in anti-stereotypical contexts fail to shift the model's profession-gender predictions reliably.
- Generic masculine forms continue to trigger male-default interpretations despite surrounding female referents.
- Contextualization along the probed gender direction remains insufficiently dynamic throughout training.
Where Pith is reading between the lines
- The same limited contextual flexibility may appear in other morphologically gendered languages when tested with comparable short templates.
- Training procedures that emphasize longer contexts could reduce the observed male-default persistence.
- Debiasing efforts might need to target how subspaces evolve during training rather than only post-training adjustments.
Load-bearing premise
Short controlled sentence templates provide a sufficient test of whether the model can integrate explicit contextual cues to override statistical gender associations.
What would settle it
The model correctly representing anti-stereotypical gender cues when the same professions appear in longer, more natural sentences instead of the short templates.
Figures








read the original abstract
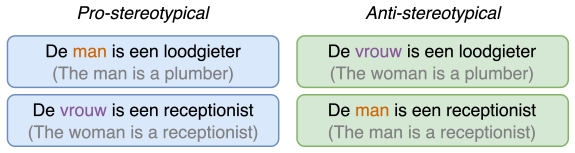
Gender bias in large language models has primarily been investigated for English, while languages with grammatical or morphological gender remain comparatively understudied. This paper investigates how and when gender information emerges in a Dutch BERT model trained from scratch, offering one of the first checkpoint-level analyses of bias formation in a Transformer architecture for a language combining overt morphological gender marking and generic forms. By extracting contextual embeddings throughout training, we construct dynamic gender subspaces using linear SVMs to trace when gender becomes linearly encoded and how this encoding evolves over time. Contextual embeddings are often assumed to integrate contextual cues robustly, allowing models to adjust the representation of a word depending on its more local usage. We therefore test whether explicit gender cues in controlled sentence templates (e.g., Zij is een loodgieter ('She is a plumber')) can override learned statistical associations (plumber -> male). Our findings challenge this assumption: although gender becomes clearly linearly separable around epoch 20 and is distributed across multiple embedding dimensions, the model struggles to update its internal gender representation in light of explicit contextual cues in short sentence templates. Stereotypical gender-profession pairings are predicted far more accurately than anti-stereotypical ones, and generic forms in Dutch systematically default to a male interpretation, even when the context explicitly denotes a female referent. Together, our results seem to indicate that contextualization in the representations learned by our Dutch BERT model is not sufficiently dynamic along the probed gender direction: explicit gender cues in anti-stereotypical contexts are not reliably reflected in the resulting representations, resulting in persistent male-default behaviour.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes the emergence and contextual integration of gender bias in a Dutch BERT model trained from scratch. It extracts contextual embeddings at training checkpoints and uses linear SVMs to construct dynamic gender subspaces, tracking when gender information becomes linearly separable (around epoch 20). It then tests integration of explicit gender cues via short controlled sentence templates (e.g., 'Zij is een loodgieter' for anti-stereotypical professions), finding that stereotypical associations dominate predictions, generic masculine forms default to male interpretations, and explicit female cues fail to reliably shift representations away from male defaults.
Significance. If the results hold under more varied conditions, the work provides one of the first checkpoint-level views of bias formation in a Transformer for a language with overt morphological gender marking. The SVM-based probing of evolving subspaces is a clear methodological strength, offering traceable metrics for linear encoding of gender. The findings challenge assumptions about robust contextualization in embeddings and have implications for debiasing in multilingual models, though the scope is limited to Dutch and short templates.
major comments (2)
- [§4] §4 (template-based evaluation) and abstract: the central claim that 'contextualization ... is not sufficiently dynamic' and that explicit cues 'are not reliably reflected' rests on short hand-crafted templates without any reported comparisons to longer natural sentences or varied syntactic frames. If richer contexts allow the model to override training-data statistics, the observed male-default behavior and anti-stereotypical prediction gaps could be template-specific rather than a general property of the learned representations.
- [Results] Results section and abstract: the claim that 'stereotypical gender-profession pairings are predicted far more accurately than anti-stereotypical ones' lacks reported effect sizes, statistical significance tests, or baselines (e.g., majority-class predictor or non-contextual embeddings). Without these, the magnitude and robustness of the bias cannot be fully assessed, weakening verification of the persistent male-default conclusion.
minor comments (2)
- [§3] The description of SVM probe construction (likely §3) would benefit from explicit reporting of hyperparameter choices and cross-validation details to ensure reproducibility of the gender subspace tracing.
- [Figures] Figure captions and axis labels for the checkpoint-level separability plots should include error bars or confidence intervals to clarify variability across runs.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point by point below, providing the strongest honest defense of our work while acknowledging limitations where they exist. Revisions have been made to strengthen the paper accordingly.
read point-by-point responses
-
Referee: [§4] §4 (template-based evaluation) and abstract: the central claim that 'contextualization ... is not sufficiently dynamic' and that explicit cues 'are not reliably reflected' rests on short hand-crafted templates without any reported comparisons to longer natural sentences or varied syntactic frames. If richer contexts allow the model to override training-data statistics, the observed male-default behavior and anti-stereotypical prediction gaps could be template-specific rather than a general property of the learned representations.
Authors: We agree that the evaluation is restricted to short, hand-crafted templates and that this constitutes a genuine limitation for generalizing the claims about contextualization to richer or longer natural sentences. Our design choice was intentional: short templates provide the minimal context in which explicit gender cues (e.g., 'Zij') should most easily override stereotypical associations if dynamic integration were robust. Failure to do so in these controlled settings is therefore informative about the model's limitations. Nevertheless, we have revised the Discussion section to explicitly acknowledge this scope restriction, to discuss the possibility that longer contexts might yield different behavior, and to outline future experiments with varied syntactic frames and natural corpora. No new experiments on longer sentences were feasible within the current study, but the added discussion addresses the referee's concern directly. revision: partial
-
Referee: [Results] Results section and abstract: the claim that 'stereotypical gender-profession pairings are predicted far more accurately than anti-stereotypical ones' lacks reported effect sizes, statistical significance tests, or baselines (e.g., majority-class predictor or non-contextual embeddings). Without these, the magnitude and robustness of the bias cannot be fully assessed, weakening verification of the persistent male-default conclusion.
Authors: We accept this criticism as valid. The original manuscript did not include effect sizes, formal significance tests, or explicit baselines for the accuracy gap between stereotypical and anti-stereotypical conditions. In the revised version we have added: (1) effect sizes (Cohen's h for proportion differences), (2) McNemar's tests for paired accuracy comparisons, and (3) two baselines—a majority-class predictor derived from profession gender frequencies in the training data and a non-contextual static embedding baseline. These additions are now reported in the Results section and confirm that the observed gaps are both statistically significant and substantially larger than the baselines, thereby strengthening the evidence for persistent male-default behavior. revision: yes
Circularity Check
No circularity: empirical probing of trained embeddings
full rationale
The paper conducts an empirical study by training a Dutch BERT model from scratch, extracting contextual embeddings at training checkpoints, constructing gender subspaces via linear SVMs, and evaluating them on controlled sentence templates. No derivation, equation, or prediction is presented that reduces the measured gender direction or contextualization behavior to a fitted parameter or self-citation defined by the target result itself. All claims rest on direct observations from the trained model and template tests, rendering the work self-contained against external benchmarks with no load-bearing circular steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Gender can be treated as a linearly separable direction in contextual embedding space that an SVM can reliably extract at different training stages.
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearwe construct dynamic gender subspaces using linear SVMs to trace when gender becomes linearly encoded... project profession terms within controlled sentence templates... onto the learned gender subspace
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearStereotypical gender–profession pairings are predicted far more accurately than anti-stereotypical ones
Reference graph
Works this paper leans on
-
[1]
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin and Ming. CoRR , volume =. 2018 , url =. 1810.04805 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[2]
Peters, Matthew E. and Neumann, Mark and Iyyer, Mohit and Gardner, Matt and Clark, Christopher and Lee, Kenton and Zettlemoyer, Luke. Deep Contextualized Word Representations. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers). 2018. doi:10...
-
[3]
Yi Chern Tan and L. Elisa Celis , title =. CoRR , volume =. 2019 , url =. 1911.01485 , timestamp =
-
[4]
URL https://doi.org/10.1145/ 3442188.3445922
Bender, Emily M. and Gebru, Timnit and McMillan-Major, Angelina and Shmitchell, Shmargaret , title =. Proceedings of the 2021 ACM Conference on Fairness, Accountability, and Transparency , pages =. 2021 , isbn =. doi:10.1145/3442188.3445922 , abstract =
-
[5]
Getting Gender Right in Neural Machine Translation
Vanmassenhove, Eva and Hardmeier, Christian and Way, Andy. Getting Gender Right in Neural Machine Translation. Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018. doi:10.18653/v1/D18-1334
-
[6]
Reducing Gender Bias in Neural Machine Translation as a Domain Adaptation Problem
Saunders, Danielle and Byrne, Bill. Reducing Gender Bias in Neural Machine Translation as a Domain Adaptation Problem. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.690
-
[7]
Patrick Wilhelm, Thorsten Wittkopp, and Odej Kao
Smarter, Better, Faster, Longer: A Modern Bidirectional Encoder for Fast, Memory Efficient, and Long Context Finetuning and Inference , author =. arXiv preprint arXiv:2412.13663 , year =
-
[8]
arXiv preprint arXiv:2503.05500 , year =
EuroBERT: Scaling Multilingual Encoders for European Languages , author =. arXiv preprint arXiv:2503.05500 , year =
-
[9]
Transactions on Machine Learning Research , year =
NeoBERT: A Next-Generation BERT , author =. Transactions on Machine Learning Research , year =
-
[10]
The Risk of Racial Bias in Hate Speech Detection
Sap, Maarten and Card, Dallas and Gabriel, Saadia and Choi, Yejin and Smith, Noah A. The Risk of Racial Bias in Hate Speech Detection. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1163
-
[11]
F air P rism: Evaluating Fairness-Related Harms in Text Generation
Fleisig, Eve and Amstutz, Aubrie and Atalla, Chad and Blodgett, Su Lin and Daum \'e III, Hal and Olteanu, Alexandra and Sheng, Emily and Vann, Dan and Wallach, Hanna. F air P rism: Evaluating Fairness-Related Harms in Text Generation. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2023. doi...
-
[12]
The woman worked as a babysitter: On biases in language generation
Sheng, Emily and Chang, Kai-Wei and Natarajan, Premkumar and Peng, Nanyun. The Woman Worked as a Babysitter: On Biases in Language Generation. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 2019. doi:10.18653/v1/D19-1339
-
[13]
Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings , journal =
Tolga Bolukbasi and Kai. Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings , journal =. 2016 , url =. 1607.06520 , timestamp =
-
[14]
Ravfogel, Shauli and Elazar, Yanai and Gonen, Hila and Twiton, Michael and Goldberg, Yoav. Null It Out: Guarding Protected Attributes by Iterative Nullspace Projection. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.647
-
[15]
The Birth of Bias: A case study on the evolution of gender bias in an English language model , author=. 2022 , eprint=
work page 2022
-
[16]
Bryson and Arvind Narayanan , title =
Aylin Caliskan Islam and Joanna J. Bryson and Arvind Narayanan , title =. CoRR , volume =. 2016 , url =. 1608.07187 , timestamp =
-
[17]
Semantics derived automatically from language corpora contain human-like biases , author=. Science , volume=. 2017 , publisher=
work page 2017
-
[18]
May, Chandler and Wang, Alex and Bordia, Shikha and Bowman, Samuel R. and Rudinger, Rachel. On Measuring Social Biases in Sentence Encoders. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1063
-
[19]
Gender bias in coreference resolution: Evaluation and debiasing methods
Zhao, Jieyu and Wang, Tianlu and Yatskar, Mark and Ordonez, Vicente and Chang, Kai-Wei. Gender Bias in Coreference Resolution: Evaluation and Debiasing Methods. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). 2018. doi:10.18653/v1/N18-2003
-
[20]
Rudinger, Rachel and Naradowsky, Jason and Leonard, Brian and Van Durme, Benjamin. Gender Bias in Coreference Resolution. Proceedings of the 2018 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers). 2018. doi:10.18653/v1/N18-2002
-
[21]
Unmasking Contextual Stereotypes: Measuring and Mitigating BERT `s Gender Bias
Bartl, Marion and Nissim, Malvina and Gatt, Albert. Unmasking Contextual Stereotypes: Measuring and Mitigating BERT `s Gender Bias. Proceedings of the Second Workshop on Gender Bias in Natural Language Processing. 2020
work page 2020
-
[22]
Measuring Bias in Contextualized Word Representations
Kurita, Keita and Vyas, Nidhi and Pareek, Ayush and Black, Alan W and Tsvetkov, Yulia. Measuring Bias in Contextualized Word Representations. Proceedings of the First Workshop on Gender Bias in Natural Language Processing. 2019. doi:10.18653/v1/W19-3823
-
[23]
C row S -Pairs: A Challenge Dataset for Measuring Social Biases in Masked Language Models
Nangia, Nikita and Vania, Clara and Bhalerao, Rasika and Bowman, Samuel R. C row S -Pairs: A Challenge Dataset for Measuring Social Biases in Masked Language Models. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020. doi:10.18653/v1/2020.emnlp-main.154
-
[24]
S tereo S et: Measuring stereotypical bias in pretrained language models
Nadeem, Moin and Bethke, Anna and Reddy, Siva. S tereo S et: Measuring stereotypical bias in pretrained language models. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers). 2021. doi:10.18653/v1/2021.acl-long.416
-
[25]
Salazar, Julian and Liang, Davis and Nguyen, Toan Q. and Kirchhoff, Katrin. Masked Language Model Scoring. Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020. doi:10.18653/v1/2020.acl-main.240
-
[26]
How Does Grammatical Gender Affect Noun Representations in Gender-Marking Languages?
Gonen, Hila and Kementchedjhieva, Yova and Goldberg, Yoav. How Does Grammatical Gender Affect Noun Representations in Gender-Marking Languages?. Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL). 2019. doi:10.18653/v1/K19-1043
-
[27]
Evaluating Bias In D utch Word Embeddings
Ch \'a vez Mulsa, Rodrigo Alejandro and Spanakis, Gerasimos. Evaluating Bias In D utch Word Embeddings. Proceedings of the Second Workshop on Gender Bias in Natural Language Processing. 2020
work page 2020
-
[28]
Examining Gender Bias in Languages with Grammatical Gender
Zhou, Pei and Shi, Weijia and Zhao, Jieyu and Huang, Kuan-Hao and Chen, Muhao and Cotterell, Ryan and Chang, Kai-Wei. Examining Gender Bias in Languages with Grammatical Gender. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP). 20...
-
[29]
N. F rench C row S -Pairs: Extending a challenge dataset for measuring social bias in masked language models to a language other than E nglish. Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2022. doi:10.18653/v1/2022.acl-long.583
-
[30]
Debiasing Pre-trained Contextualised Embeddings
Kaneko, Masahiro and Bollegala, Danushka. Debiasing Pre-trained Contextualised Embeddings. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. 2021. doi:10.18653/v1/2021.eacl-main.107
-
[31]
SoNaR-corpus (Version 1.2.1) , year =
-
[32]
Arps, David and Kallmeyer, Laura and Samih, Younes and Sajjad, Hassan. Multilingual Nonce Dependency Treebanks: Understanding how Language Models Represent and Process Syntactic Structure. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers). ...
-
[33]
Manna, Chiara and Alishahi, Afra and Blain, Fr \'e d \'e ric and Vanmassenhove, Eva. Are We Paying Attention to Her? Investigating Gender Disambiguation and Attention in Machine Translation. Proceedings of the 3rd Workshop on Gender-Inclusive Translation Technologies (GITT 2025). 2025
work page 2025
-
[34]
A Structural Probe for Finding Syntax in Word Representations
Hewitt, John and Manning, Christopher D. A Structural Probe for Finding Syntax in Word Representations. Proceedings of the 2019 Conference of the North A merican Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers). 2019. doi:10.18653/v1/N19-1419
-
[35]
A Survey on Bias and Fairness in Natural Language Processing , author=. 2022 , eprint=
work page 2022
-
[36]
Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit , author =. 2009 , publisher =
work page 2009
-
[37]
Scikit-learn: machine learning in Python
Fabian Pedregosa and Ga. Scikit-learn: Machine Learning in Python , journal =. 2012 , url =. 1201.0490 , timestamp =
-
[38]
Ashish Vaswani and Noam Shazeer and Niki Parmar and Jakob Uszkoreit and Llion Jones and Aidan N. Gomez and Lukasz Kaiser and Illia Polosukhin , title =. CoRR , volume =. 2017 , url =. 1706.03762 , timestamp =
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
Cortes, Corinna and Vapnik, Vladimir , title =. Mach. Learn. , month = sep, pages =. 1995 , issue_date =. doi:10.1023/A:1022627411411 , abstract =
-
[40]
PyTorch: An Imperative Style, High-Performance Deep Learning Library , url =
Paszke, Adam and Gross, Sam and Massa, Francisco and Lerer, Adam and Bradbury, James and Chanan, Gregory and Killeen, Trevor and Lin, Zeming and Gimelshein, Natalia and Antiga, Luca and Desmaison, Alban and Kopf, Andreas and Yang, Edward and DeVito, Zachary and Raison, Martin and Tejani, Alykhan and Chilamkurthy, Sasank and Steiner, Benoit and Fang, Lu an...
-
[41]
Charles R. Harris and K. Jarrod Millman and St. Array programming with. 2020 , month = sep, journal =. doi:10.1038/s41586-020-2649-2 , publisher =
-
[42]
Hunter, J. D. , Title =. Computing in Science & Engineering , Volume =
- [43]
-
[44]
Jumelet, Jaap and Zuidema, Willem and Hupkes, Dieuwke. Analysing Neural Language Models: Contextual Decomposition Reveals Default Reasoning in Number and Gender Assignment. Proceedings of the 23rd Conference on Computational Natural Language Learning (CoNLL). 2019. doi:10.18653/v1/K19-1001
-
[45]
How to pretrain a BERT model from scratch , year = 2021, url =
work page 2021
-
[46]
LLM Course - Chapter 7.6: Training from Scratch , year = 2023, url =
work page 2023
-
[47]
Arnab Bhattacharya , title =
-
[48]
Essential Speech and Language Technology for Dutch: Results by the STEVIN-programme , pages=
The Construction of a 500-Million-Word Reference Corpus of Contemporary Written Dutch , author=. Essential Speech and Language Technology for Dutch: Results by the STEVIN-programme , pages=. 2013 , publisher=
work page 2013
-
[49]
Nog eens functie-en rolbenamingen in het Nederlands vanuit contastief perspectief , author=
Zij is een powerfeministe. Nog eens functie-en rolbenamingen in het Nederlands vanuit contastief perspectief , author=. Tijdschrift voor genderstudies , volume=
-
[50]
Gender Across Languages: The linguistic representation of women and men , volume=
Towards a more gender-fair usage in Netherlands Dutch , author=. Gender Across Languages: The linguistic representation of women and men , volume=. 2002 , publisher=
work page 2002
- [51]
- [52]
-
[53]
Losing our Tail, Again: (Un)Natural Selection & Multilingual LLMs
Losing our Tail--Again: On (Un) Natural Selection And Multilingual Large Language Models , author=. arXiv preprint arXiv:2507.03933 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[54]
Proceedings of Machine Translation Summit XVII: Research Track , pages=
Lost in Translation: Loss and Decay of Linguistic Richness in Machine Translation , author=. Proceedings of Machine Translation Summit XVII: Research Track , pages=
-
[55]
Machine Translationese: Effects of Algorithmic Bias on Linguistic Complexity in Machine Translation , author=. Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume , pages=
-
[56]
Thomas McCoy and Shunyu Yao and Dan Friedman and Matthew Hardy and Thomas L
Embers of autoregression: Understanding large language models through the problem they are trained to solve , author=. arXiv preprint arXiv:2309.13638 , year=
-
[57]
A decade of gender bias in machine translation , author=. Patterns , volume=. 2025 , publisher=
work page 2025
-
[58]
Journal of Vocational Behavior , volume=
Changing (S) expectations: How gender fair job descriptions impact children's perceptions and interest regarding traditionally male occupations , author=. Journal of Vocational Behavior , volume=. 2013 , publisher=
work page 2013
-
[59]
Yes i can!Effects of gender fair job descriptions on children’s perceptions of job status, job difficulty, and vocational self-efficacy , author=. Social Psychology , year=
-
[60]
RoBERTa: A Robustly Optimized BERT Pretraining Approach
Roberta: A robustly optimized bert pretraining approach , author=. arXiv preprint arXiv:1907.11692 , year=
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[61]
Gender-inclusive language in Dutch , author=. Gender-Inclusive Language. Findings from 14 Languages and Open Research Questions , pages=. 2026 , publisher=
work page 2026
-
[62]
Hoe automatische vertaling de genderbias van AI (Artificial Intelligence) verraadt , author=. 2021 , publisher=
work page 2021
-
[63]
Fort, Karen and Alonso Alemany, Laura and Benotti, Luciana and Bezan c on, Julien and Borg, Claudia and Borg, Marthese and Chen, Yongjian and Ducel, Fanny and Dupont, Yoann and Ivetta, Guido and Li, Zhijian and Mieskes, Margot and Naguib, Marco and Qian, Yuyan and Radaelli, Matteo and Schmeisser-Nieto, Wolfgang S. and Raimundo Schulz, Emma and Saci, Thizi...
work page 2024
-
[64]
Monolingual and Multilingual Reduction of Gender Bias in Contextualized Representations
Liang, Sheng and Dufter, Philipp and Sch. Monolingual and Multilingual Reduction of Gender Bias in Contextualized Representations. Proceedings of the 28th International Conference on Computational Linguistics. 2020. doi:10.18653/v1/2020.coling-main.446
-
[65]
Jawahar, Ganesh and Sagot, Beno \^i t and Seddah, Djam \'e. What Does BERT Learn about the Structure of Language?. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1356
-
[66]
BERT Rediscovers the Classical NLP Pipeline
Tenney, Ian and Das, Dipanjan and Pavlick, Ellie. BERT Rediscovers the Classical NLP Pipeline. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1452
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.