Recognition: 2 theorem links
· Lean TheoremLearning to Communicate Locally for Large-Scale Multi-Agent Pathfinding
Pith reviewed 2026-05-13 07:37 UTC · model grok-4.3
The pith
A learnable local communication module improves coordination among agents in large-scale multi-agent pathfinding without reducing scalability.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
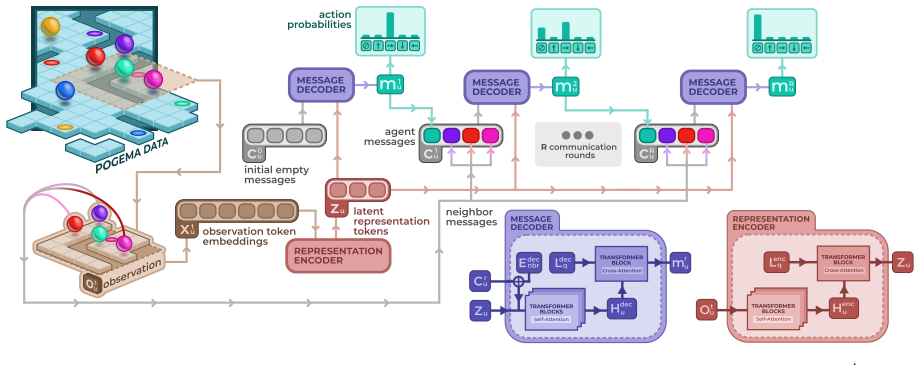
The authors claim that a generalizable pre-trained model called LC-MAPF, built by inserting a learnable multi-round communication module between neighboring agents, produces higher-quality paths than prior learning-based MAPF solvers while preserving the computational efficiency required for large environments.
What carries the argument
The local communication module that performs multi-round feature sharing among neighboring agents inside the Dec-POMDP formulation of MAPF.
If this is right
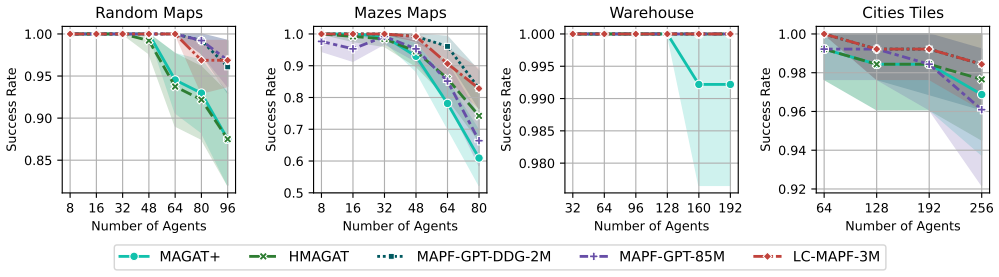
- LC-MAPF produces higher success rates and better path quality than existing imitation-learning and reinforcement-learning MAPF solvers on diverse unseen scenarios.
- The added communication rounds leave overall runtime and memory use comparable to non-communicating baselines even as the number of agents grows.
- A single pre-trained model works across varying map sizes and agent densities without retraining.
- Local-only feature exchange avoids the scalability bottlenecks reported for global or dense communication schemes.
Where Pith is reading between the lines
- The same local-exchange pattern could be tested on other decentralized multi-agent tasks such as dynamic task allocation or formation control.
- In physical robot deployments the approach might reduce reliance on centralized planners when environments change faster than global replanning allows.
- One could measure whether increasing the number of communication rounds yields diminishing returns beyond a small fixed number.
- The method suggests examining whether similar lightweight modules improve sample efficiency in related multi-agent reinforcement learning domains.
Load-bearing premise
The pre-trained model incorporating the local communication module will generalize to deliver performance gains and maintain scalability across diverse unseen large-scale test scenarios.
What would settle it
A controlled test on a previously unseen map with several thousand agents in which LC-MAPF records a lower success rate or higher per-agent runtime than the strongest baseline learning method.
Figures








read the original abstract
Multi-agent pathfinding (MAPF) is a widely used abstraction for multi-robot trajectory planning problems, where multiple homogeneous agents move simultaneously within a shared environment. Although solving MAPF optimally is NP-hard, scalable and efficient solvers are critical for real-world applications such as logistics and search-and-rescue. To this end, the research community has proposed various decentralized suboptimal MAPF solvers that leverage machine learning. Such methods frame MAPF (from a single agent perspective) as a Dec-POMDP where at each time step an agent has to decide an action based on the local observation and typically solve the problem via reinforcement learning or imitation learning. We follow the same approach but additionally introduce a learnable communication module tailored to enhance cooperation between agents via efficient feature sharing. We present the Local Communication for Multi-agent Pathfinding (LC-MAPF), a generalizable pre-trained model that applies multi-round communication between neighboring agents to exchange information and improve their coordination. Our experiments show that the introduced method outperforms the existing learning-based MAPF solvers, including IL and RL-based approaches, across diverse metrics in a diverse range of (unseen) test scenarios. Remarkably, the introduced communication mechanism does not compromise LC-MAPF's scalability, a common bottleneck for communication-based MAPF solvers.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LC-MAPF, a pre-trained decentralized solver for large-scale multi-agent pathfinding framed as a Dec-POMDP. Agents use local observations plus a learnable multi-round communication module to exchange features with neighbors, with the goal of improving coordination over standard IL/RL baselines while preserving scalability.
Significance. If the performance and scalability claims are substantiated, the work would demonstrate that lightweight local communication can be added to learning-based MAPF without the usual scalability penalty, which is relevant for robotics applications involving dozens to hundreds of agents.
major comments (3)
- [Experiments] The central claim of outperformance and generalization to diverse unseen large-scale scenarios (abstract) rests on experimental evidence whose setup is not described: no information is given on training scenario generation, map sizes, obstacle densities, agent counts, distribution shift metrics between train and test sets, or the number of independent runs. This directly affects the load-bearing assertion that gains transfer beyond in-distribution cases.
- [Experiments] The scalability claim (abstract) that the communication module does not compromise performance at large scale is not supported by any reported timing, memory, or success-rate curves versus number of agents or map size; without these, it is impossible to verify the contrast with prior communication-based solvers.
- [Method] The method section provides no concrete specification of the communication module (number of rounds, message size, aggregation function, or how messages are integrated into the policy network), making it impossible to assess whether the added component is parameter-efficient or reproducible.
minor comments (2)
- [Preliminaries] Notation for the Dec-POMDP components (observation, action, reward) is introduced without an explicit equation or table, forcing the reader to infer standard definitions.
- [Abstract] The abstract states results are shown 'across diverse metrics' but never enumerates those metrics (e.g., success rate, makespan, flowtime).
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback. We have revised the manuscript to provide the missing experimental details, scalability analysis, and method specifications requested. Our point-by-point responses follow.
read point-by-point responses
-
Referee: [Experiments] The central claim of outperformance and generalization to diverse unseen large-scale scenarios (abstract) rests on experimental evidence whose setup is not described: no information is given on training scenario generation, map sizes, obstacle densities, agent counts, distribution shift metrics between train and test sets, or the number of independent runs. This directly affects the load-bearing assertion that gains transfer beyond in-distribution cases.
Authors: We agree that the experimental setup requires more explicit documentation to support the generalization claims. The original manuscript described the setup at a high level in Section 4 but omitted several key parameters. In the revised version we have expanded Section 4.1 with the following details: training maps are procedurally generated with sizes 32×32 to 64×64, obstacle densities 0–30 %, and 10–100 agents; test scenarios use larger unseen maps (up to 128×128) and up to 200 agents to create distribution shift, quantified by differences in agent density and map scale. All quantitative results are now reported as means over five independent runs with standard deviations. revision: yes
-
Referee: [Experiments] The scalability claim (abstract) that the communication module does not compromise performance at large scale is not supported by any reported timing, memory, or success-rate curves versus number of agents or map size; without these, it is impossible to verify the contrast with prior communication-based solvers.
Authors: We acknowledge that explicit scalability curves were absent from the original submission. Although the local-communication design implies constant per-agent overhead, we have added a new subsection (4.3) and Figure 6 that plot success rate, per-timestep runtime, and peak memory usage against agent count (50–500) on fixed-size maps and against map size at constant density. The curves confirm that LC-MAPF retains high success rates and linear scaling, in contrast to global-communication baselines. revision: yes
-
Referee: [Method] The method section provides no concrete specification of the communication module (number of rounds, message size, aggregation function, or how messages are integrated into the policy network), making it impossible to assess whether the added component is parameter-efficient or reproducible.
Authors: We apologize for the lack of concrete specification. Section 3.2 has been revised to state that the module performs exactly three rounds of communication, each agent transmits a 128-dimensional feature vector, aggregation uses a learnable attention mechanism over the four-neighbor grid, and the aggregated message is concatenated to the local observation embedding before the policy LSTM. The added module contributes approximately 50 k parameters. Pseudocode is now provided as Algorithm 1. revision: yes
Circularity Check
No circularity in LC-MAPF derivation chain
full rationale
The paper follows the established Dec-POMDP framing for single-agent MAPF decisions and augments it with an additive learnable communication module trained via standard RL or IL pipelines. All performance and scalability claims are presented as empirical outcomes from experiments on unseen test scenarios rather than as quantities derived by construction from fitted parameters or self-referential definitions. No load-bearing self-citations, uniqueness theorems imported from prior author work, or ansatzes smuggled via citation appear in the abstract or described method. The derivation remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- neural network weights for policy and communication modules
axioms (1)
- domain assumption MAPF can be framed as a Dec-POMDP from each agent's local perspective
invented entities (1)
-
learnable communication module
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We present the Local Communication for Multi-agent Pathfinding (LC-MAPF), a generalizable pre-trained model that applies multi-round communication between neighboring agents to exchange information and improve their coordination.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
A reduction of imitation learning and structured prediction to no-regret online learning , author=. Proceedings of the fourteenth international conference on artificial intelligence and statistics , pages=. 2011 , organization=
work page 2011
- [2]
-
[3]
Projection onto the probability simplex: An efficient algorithm with a simple proof, and an application , author=. 2013 , eprint=
work page 2013
- [4]
-
[5]
HybridNorm: Towards Stable and Efficient Transformer Training via Hybrid Normalization , author=. 2025 , eprint=
work page 2025
- [6]
- [7]
-
[8]
Perceiver IO: A General Architecture for Structured Inputs & Outputs , author=. 2022 , eprint=
work page 2022
-
[9]
2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
Ensembling prioritized hybrid policies for multi-agent pathfinding , author=. 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2024 , organization=
work page 2024
-
[10]
arXiv preprint arXiv:2409.14491 , year=
Work Smarter Not Harder: Simple Imitation Learning with CS-PIBT Outperforms Large Scale Imitation Learning for MAPF , author=. arXiv preprint arXiv:2409.14491 , year=
-
[11]
Multi-agent systems and foundation models enable autonomous supply chains: Opportunities and challenges , author=. IFAC-PapersOnLine , volume=. 2024 , publisher=
work page 2024
-
[12]
The International Journal of Robotics Research , publisher=
Foundation models in robotics: Applications, challenges, and the future , author=. The International Journal of Robotics Research , publisher=
-
[13]
Octo: An Open-Source Generalist Robot Policy
Octo: An open-source generalist robot policy , author=. arXiv preprint arXiv:2405.12213 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[14]
Moo Jin Kim and Karl Pertsch and Siddharth Karamcheti and Ted Xiao and Ashwin Balakrishna and Suraj Nair and Rafael Rafailov and Ethan P Foster and Pannag R Sanketi and Quan Vuong and Thomas Kollar and Benjamin Burchfiel and Russ Tedrake and Dorsa Sadigh and Sergey Levine and Percy Liang and Chelsea Finn , booktitle=. Open
-
[15]
Foun- dation models for decision making: Problems, meth- ods, and opportunities
Foundation models for decision making: Problems, methods, and opportunities , author=. arXiv preprint arXiv:2303.04129 , year=
-
[16]
On the Opportunities and Risks of Foundation Models
On the opportunities and risks of foundation models , author=. arXiv preprint arXiv:2108.07258 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
arXiv preprint arXiv:2403.14783 , year=
Multi-Agent VQA: Exploring Multi-Agent Foundation Models in Zero-Shot Visual Question Answering , author=. arXiv preprint arXiv:2403.14783 , year=
-
[18]
arXiv preprint arXiv:2411.04468 , year=
Magentic-one: A generalist multi-agent system for solving complex tasks , author=. arXiv preprint arXiv:2411.04468 , year=
-
[19]
Computers & Operations Research , volume=
Branch-and-cut-and-price for multi-agent path finding , author=. Computers & Operations Research , volume=. 2022 , publisher=
work page 2022
-
[20]
Artificial intelligence , volume=
Conflict-based search for optimal multi-agent pathfinding , author=. Artificial intelligence , volume=. 2015 , publisher=
work page 2015
-
[21]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
MAPF-LNS2: Fast repairing for multi-agent path finding via large neighborhood search , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[22]
IEEE Robotics and Automation Letters , volume=
Learning selective communication for multi-agent path finding , author=. IEEE Robotics and Automation Letters , volume=. 2021 , publisher=
work page 2021
-
[23]
Skrynnik, Alexey and Andreychuk, Anton and Borzilov, Anatolii and Chernyavskiy, Alexander and Yakovlev, Konstantin and Panov, Aleksandr , year=
-
[24]
Proceedings of the 38th AAAI Conference on Artificial Intelligence (
Learn to Follow: Decentralized Lifelong Multi-agent Pathfinding via Planning and Learning , author=. Proceedings of the 38th AAAI Conference on Artificial Intelligence (
-
[25]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Decentralized Monte Carlo Tree Search for Partially Observable Multi-Agent Pathfinding , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[26]
IEEE Robotics and Automation Letters , volume=
PRIMAL \_2 : Pathfinding via reinforcement and imitation multi-agent learning-lifelong , author=. IEEE Robotics and Automation Letters , volume=. 2021 , publisher=
work page 2021
-
[27]
IEEE Robotics and Automation Letters , volume=
Primal: Pathfinding via reinforcement and imitation multi-agent learning , author=. IEEE Robotics and Automation Letters , volume=. 2019 , publisher=
work page 2019
-
[28]
2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
SCRIMP: Scalable communication for reinforcement-and imitation-learning-based multi-agent pathfinding , author=. 2023 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2023 , organization=
work page 2023
-
[29]
The Twelfth International Conference on Learning Representations , year=
FlashAttention-2: Faster Attention with Better Parallelism and Work Partitioning , author=. The Twelfth International Conference on Learning Representations , year=
-
[30]
International Conference on Learning Representations , year=
Decoupled Weight Decay Regularization , author=. International Conference on Learning Representations , year=
- [31]
-
[32]
2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=
Multi-agent imitation learning for driving simulation , author=. 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS) , pages=. 2018 , organization=
work page 2018
-
[33]
2023 IEEE Intelligent Vehicles Symposium (IV) , pages=
Multi-agent Decision-making at Unsignalized Intersections with Reinforcement Learning from Demonstrations , author=. 2023 IEEE Intelligent Vehicles Symposium (IV) , pages=. 2023 , organization=
work page 2023
-
[34]
Mastering the game of Go with deep neural networks and tree search , author=. nature , volume=. 2016 , publisher=
work page 2016
-
[35]
The StarCraft Multi-Agent Challenge , author=. Proceedings of the 18th International Conference on Autonomous Agents and MultiAgent Systems , pages=
-
[36]
2018 21st international conference on intelligent transportation systems (ITSC) , pages=
Microscopic traffic simulation using sumo , author=. 2018 21st international conference on intelligent transportation systems (ITSC) , pages=. 2018 , organization=
work page 2018
-
[37]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Multi-Agent Imitation Learning: Value is Easy, Regret is Hard , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[38]
Advances in Neural Information Processing Systems , volume=
Learning multi-agent behaviors from distributed and streaming demonstrations , author=. Advances in Neural Information Processing Systems , volume=
-
[39]
Advances in Neural Information Processing Systems , volume=
Bayesian multi-type mean field multi-agent imitation learning , author=. Advances in Neural Information Processing Systems , volume=
-
[40]
Advances in neural information processing systems , volume=
Multi-agent generative adversarial imitation learning , author=. Advances in neural information processing systems , volume=
-
[41]
IEEE Transactions on Games , year=
GAILPG: Multi-Agent Policy Gradient with Generative Adversarial Imitation Learning , author=. IEEE Transactions on Games , year=
-
[42]
Machine Learning and Knowledge Discovery in Databases
Multi-agent imitation learning with copulas , author=. Machine Learning and Knowledge Discovery in Databases. Research Track: European Conference, ECML PKDD 2021, Bilbao, Spain, September 13--17, 2021, Proceedings, Part I 21 , pages=. 2021 , organization=
work page 2021
-
[43]
International Conference on Machine Learning , pages=
Coordinated multi-agent imitation learning , author=. International Conference on Machine Learning , pages=. 2017 , organization=
work page 2017
-
[44]
2022 17th ACM/IEEE International Conference on Human-Robot Interaction (HRI) , pages=
Conditional imitation learning for multi-agent games , author=. 2022 17th ACM/IEEE International Conference on Human-Robot Interaction (HRI) , pages=. 2022 , organization=
work page 2022
-
[45]
Machine Intelligence Research , volume=
Offline pre-trained multi-agent decision transformer , author=. Machine Intelligence Research , volume=. 2023 , publisher=
work page 2023
-
[46]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Lacam: Search-based algorithm for quick multi-agent pathfinding , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[47]
Engineering LaCAM*: Towards Real-time, Large-scale, and Near-optimal Multi-agent Pathfinding , author=. Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems , pages=
-
[48]
Offline Reinforcement Learning: Tutorial, Review, and Perspectives on Open Problems
Offline reinforcement learning: Tutorial, review, and perspectives on open problems , author=. arXiv preprint arXiv:2005.01643 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2005
-
[49]
Advances in Neural Information Processing Systems , volume=
Conservative q-learning for offline reinforcement learning , author=. Advances in Neural Information Processing Systems , volume=
-
[50]
International Conference on Learning Representations , year=
Offline Reinforcement Learning with Implicit Q-Learning , author=. International Conference on Learning Representations , year=
-
[51]
Advances in neural information processing systems , volume=
A minimalist approach to offline reinforcement learning , author=. Advances in neural information processing systems , volume=
-
[52]
Grandmaster level in StarCraft II using multi-agent reinforcement learning , author=. nature , volume=. 2019 , publisher=
work page 2019
-
[53]
Advances in Neural Information Processing Systems , volume=
Amortized planning with large-scale transformers: A case study on chess , author=. Advances in Neural Information Processing Systems , volume=
-
[54]
Advances in Neural Information Processing Systems , volume=
Video pretraining (vpt): Learning to act by watching unlabeled online videos , author=. Advances in Neural Information Processing Systems , volume=
-
[55]
Mastering the game of go without human knowledge , author=. nature , volume=. 2017 , publisher=
work page 2017
-
[56]
Proceedings of the 24th AAAI Conference on Artificial Intelligence (
An optimization variant of multi-robot path planning is intractable , author=. Proceedings of the 24th AAAI Conference on Artificial Intelligence (
-
[57]
Proceedings of the 12th Annual Symposium on Combinatorial Search (
Multi-agent pathfinding: Definitions, variants, and benchmarks , author=. Proceedings of the 12th Annual Symposium on Combinatorial Search (
-
[58]
Proceedings of the 35th AAAI Conference on Artificial Intelligence (
Lifelong multi-agent path finding in large-scale warehouses , author=. Proceedings of the 35th AAAI Conference on Artificial Intelligence (
- [59]
-
[60]
A Comprehensive Review on Leveraging Machine Learning for Multi-Agent Path Finding , author=. IEEE Access , year=
-
[61]
Language Models are Few-Shot Learners , url =
Brown, Tom and Mann, Benjamin and Ryder, Nick and Subbiah, Melanie and Kaplan, Jared D and Dhariwal, Prafulla and Neelakantan, Arvind and Shyam, Pranav and Sastry, Girish and Askell, Amanda and Agarwal, Sandhini and Herbert-Voss, Ariel and Krueger, Gretchen and Henighan, Tom and Child, Rewon and Ramesh, Aditya and Ziegler, Daniel and Wu, Jeffrey and Winte...
-
[62]
Advances in neural information processing systems , volume=
Decision transformer: Reinforcement learning via sequence modeling , author=. Advances in neural information processing systems , volume=
-
[63]
Proceedings of Robotics: Science and Systems (RSS) , year=
Diffusion Policy: Visuomotor Policy Learning via Action Diffusion , author=. Proceedings of Robotics: Science and Systems (RSS) , year=
-
[64]
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[65]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[66]
The Twelfth International Conference on Learning Representations , year=
MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models , author=. The Twelfth International Conference on Learning Representations , year=
-
[67]
Advances in neural information processing systems , volume=
Attention is all you need , author=. Advances in neural information processing systems , volume=
-
[68]
Language Models are Unsupervised Multitask Learners , author=. 2019 , journal=
work page 2019
-
[69]
Artificial intelligence , volume=
The increasing cost tree search for optimal multi-agent pathfinding , author=. Artificial intelligence , volume=. 2013 , publisher=
work page 2013
-
[70]
Glenn Wagner and Howie Choset , title =. Proceedings of The 2011
work page 2011
-
[71]
Proceedings of the 22nd European Conference on Artificial Intelligence (
Efficient SAT approach to multi-agent path finding under the sum of costs objective , author=. Proceedings of the 22nd European Conference on Artificial Intelligence (. 2016 , organization=
work page 2016
-
[72]
Multi-agent path planning and network flow , author=. Algorithmic Foundations of Robotics X: Proceedings of the Tenth Workshop on the Algorithmic Foundations of Robotics , pages=. 2013 , organization=
work page 2013
-
[73]
Proceedings of the 36th International Conference on Neural Information Processing Systems , pages=
Training compute-optimal large language models , author=. Proceedings of the 36th International Conference on Neural Information Processing Systems , pages=
-
[74]
Hybrid policy learning for multi-agent pathfinding , author=. IEEE Access , volume=. 2021 , publisher=
work page 2021
-
[75]
Artificial Intelligence and Decision Making , pages=
STRL-Robotics: intelligent control for robotic platform in human-oriented environment , author=. Artificial Intelligence and Decision Making , pages=
-
[76]
Proceedings of the AAAI conference on artificial intelligence , volume=
Searching with consistent prioritization for multi-agent path finding , author=. Proceedings of the AAAI conference on artificial intelligence , volume=
-
[77]
IEEE Transactions on Neural Networks and Learning Systems , year=
When to switch: planning and learning for partially observable multi-agent pathfinding , author=. IEEE Transactions on Neural Networks and Learning Systems , year=
-
[78]
Proceedings of the 37th AAAI Conference on Artificial Intelligence (
Intersection coordination with priority-based search for autonomous vehicles , author=. Proceedings of the 37th AAAI Conference on Artificial Intelligence (
-
[79]
Andreychuk, Anton and Yakovlev, Konstantin and Panov, Aleksandr and Skrynnik, Alexey , booktitle=
-
[80]
arXiv preprint arXiv:2412.06685 , year=
Policy agnostic rl: Offline rl and online rl fine-tuning of any class and backbone , author=. arXiv preprint arXiv:2412.06685 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.