Recognition: 2 theorem links
· Lean TheoremReliable Chain-of-Thought via Prefix Consistency
Pith reviewed 2026-05-11 02:20 UTC · model grok-4.3
The pith
Prefix consistency from how often answers reappear after truncating CoT traces weights votes to match full majority voting accuracy with far fewer tokens.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
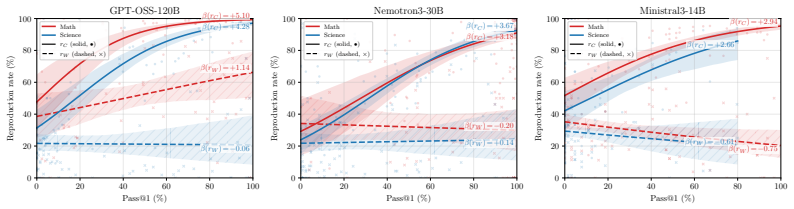
Truncating a CoT trace partway through and regenerating the remainder shows that traces ending in the correct answer reproduce that answer more frequently than traces ending in a wrong answer. This difference, called prefix consistency, is used to weight each candidate answer when performing majority voting over sampled traces, yielding more reliable aggregation than uniform voting.
What carries the argument
Prefix consistency: the rate at which a candidate answer reappears when its original CoT trace is truncated at a random point and the suffix is regenerated.
If this is right
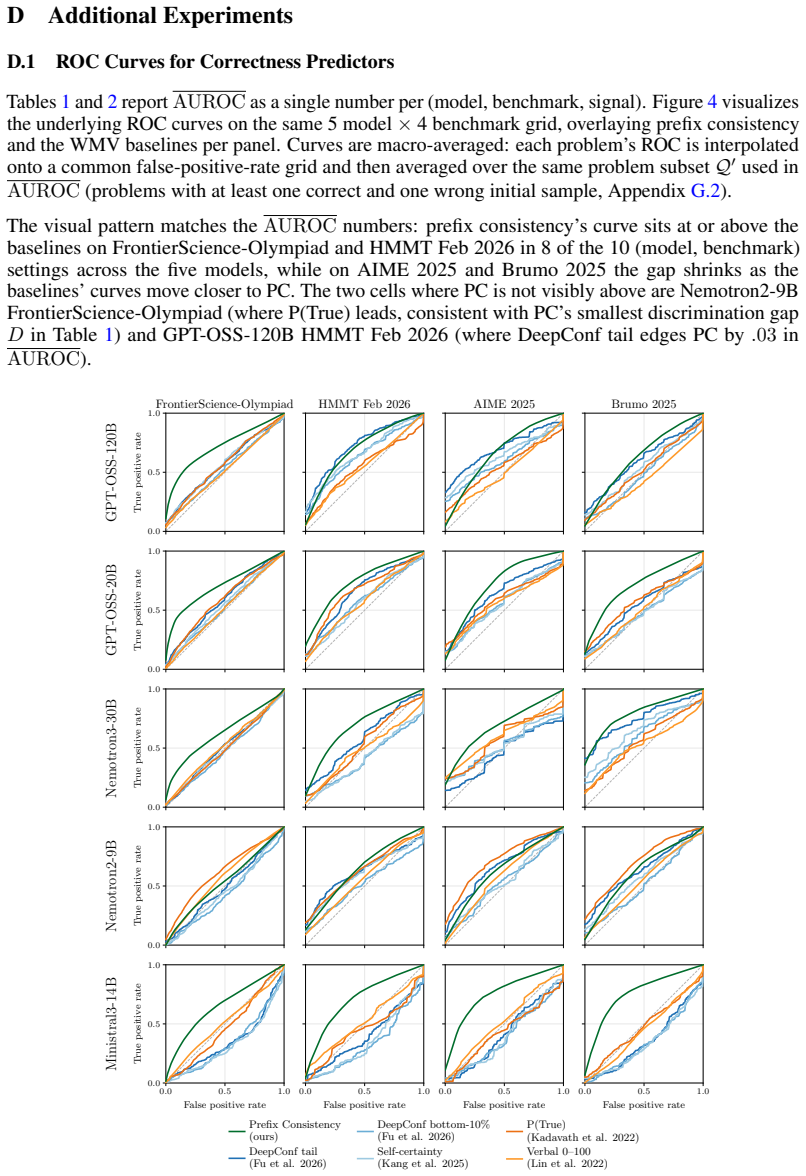
- Prefix consistency predicts correctness better than compared baselines in most settings.
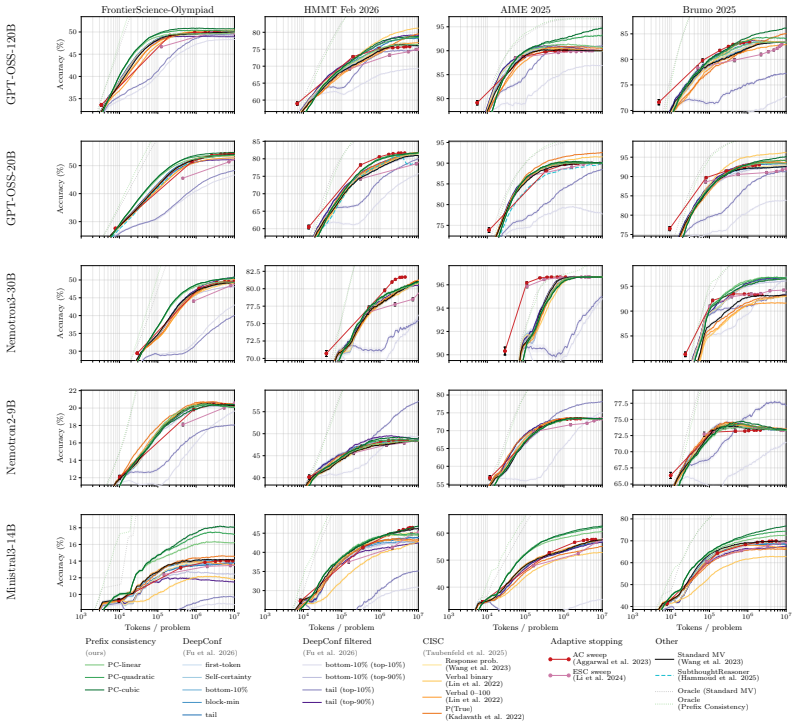
- Reweighting votes by prefix consistency reaches standard majority-voting accuracy with up to 21 times fewer tokens, median 4.6 times fewer.
- The method needs no access to token log-probabilities or extra self-rating prompts.
- It applies across five reasoning models and four math and science benchmarks.
- Savings arise because fewer complete traces suffice to reach the same performance plateau.
Where Pith is reading between the lines
- Prefix consistency may capture structural differences in how models generate correct versus incorrect reasoning paths.
- The signal could be used during training to upweight or filter traces that show high internal consistency.
- Combining prefix consistency with other low-cost signals might yield even larger token reductions in ensemble reasoning.
- The approach suggests that partial-trace stability could generalize to other test-time inference techniques beyond voting.
Load-bearing premise
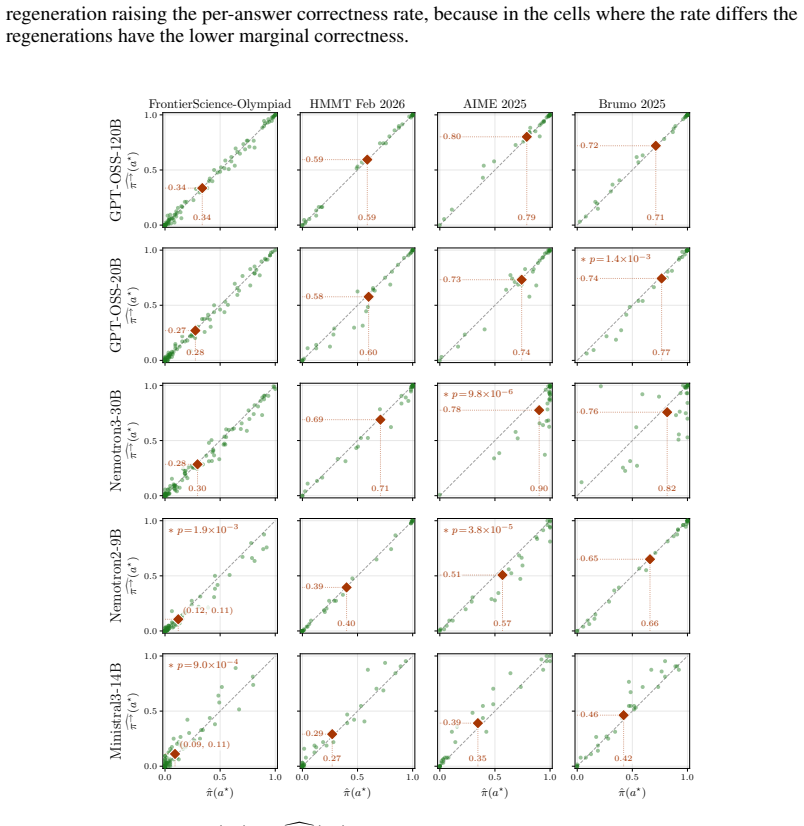
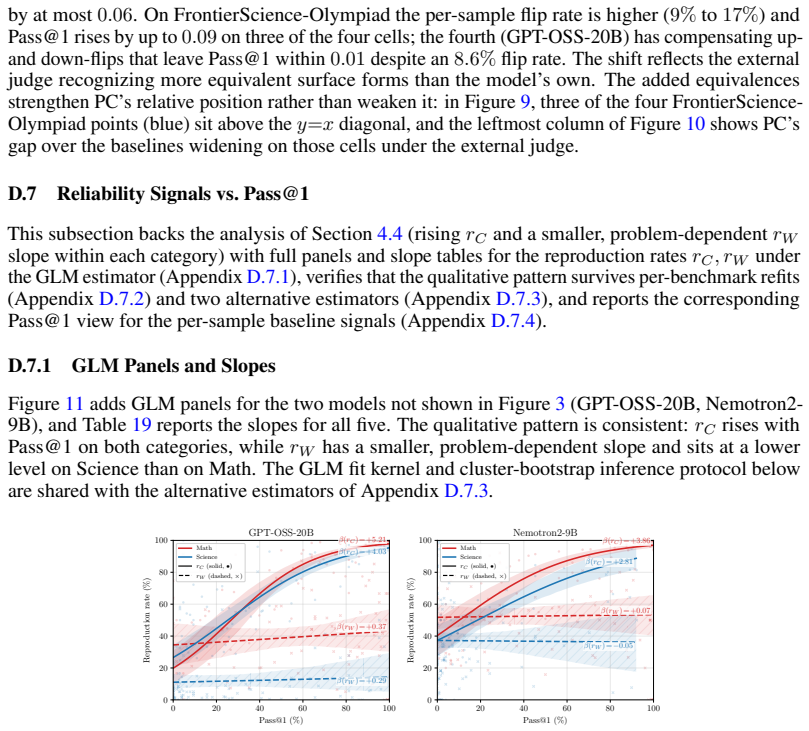
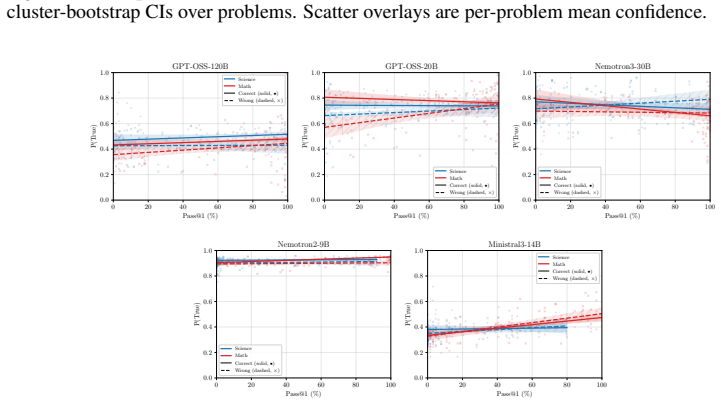
The observed difference in answer reproduction rates between correct and incorrect traces is stable enough across models, tasks, and truncation points to serve as a reliable weighting signal.
What would settle it
Observing no meaningful difference in reproduction rates between correct and incorrect traces on a new model or benchmark would falsify the reliability of the weighting signal.
Figures










read the original abstract
Large Language Models often improve accuracy on reasoning tasks by sampling multiple Chain-of-Thought (CoT) traces and aggregating them with majority voting (MV), a test-time technique called self-consistency. When we truncate a CoT partway through and regenerate the remainder, we observe that traces with correct answers reproduce their original answer more often than traces with wrong answers. We use this difference as a reliability signal, prefix consistency, that weights each candidate answer by how often it reappears under regeneration. It requires no access to token log-probabilities or self-rating prompts. Across five reasoning models and four math and science benchmarks, prefix consistency is the best correctness predictor in most settings, and reweighting votes by it reaches Standard MV plateau accuracy at up to 21x fewer tokens (median 4.6x). Our code is available at https://github.com/naoto-iwase/prefix-consistency.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes prefix consistency as a reliability signal for Chain-of-Thought (CoT) reasoning: truncate a sampled trace partway through and regenerate the suffix multiple times; weight each candidate answer by the fraction of regenerations that reproduce the original answer. This weighting is applied to self-consistency (majority voting) and is shown to outperform uniform voting as a correctness predictor. Across five models and four math/science benchmarks, the method reaches the accuracy plateau of standard majority voting at up to 21x fewer tokens (median 4.6x). The approach requires no token log-probabilities or self-rating prompts; code is released.
Significance. If the efficiency claims survive scrutiny of total token accounting, the work supplies a practical, zero-parameter, model-agnostic improvement to test-time scaling for reasoning tasks. It introduces a new, observable reliability signal grounded directly in regeneration behavior and demonstrates consistent gains over standard self-consistency without additional model access. The public code release supports reproducibility and further experimentation.
major comments (2)
- [Results section] Results section (token-efficiency claims): the headline result that prefix consistency reaches standard MV plateau accuracy at up to 21x fewer tokens (median 4.6x) is load-bearing for the central value proposition. The manuscript must explicitly state whether the reported token budgets include the full regeneration overhead (multiple suffix samples per original trace) required to compute the consistency scores. If only initial full traces are counted, the net savings are not demonstrated and the accuracy-per-token claim cannot be evaluated.
- [Experimental setup and §4] Experimental setup and §4 (truncation and regeneration protocol): the difference in answer reproduction rates between correct and incorrect traces is treated as a stable weighting signal, yet no details are provided on truncation length distribution, number of regenerations per trace, or controls for prompt sensitivity and temperature. Without these, it is impossible to verify that the observed reliability gap is robust enough to support the reported gains across models and tasks.
minor comments (2)
- [Abstract and Methods] The abstract and methods should list the exact five models (including sizes) and four benchmarks with their full names and versions for immediate clarity.
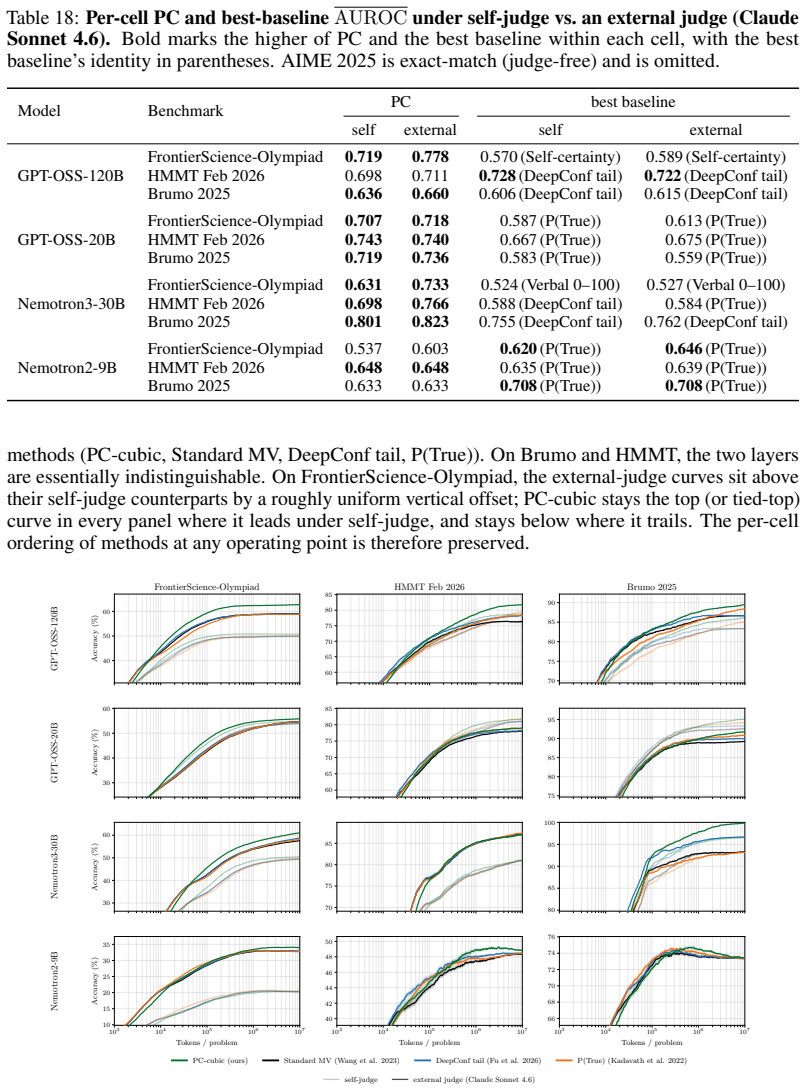
- [Figures] Figure captions and axis labels in the efficiency plots should explicitly note whether token counts are per-question averages or totals and whether they are normalized to the MV baseline.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The two major comments raise important points about token accounting and experimental details that we address below. We will revise the manuscript to improve clarity on both issues.
read point-by-point responses
-
Referee: [Results section] Results section (token-efficiency claims): the headline result that prefix consistency reaches standard MV plateau accuracy at up to 21x fewer tokens (median 4.6x) is load-bearing for the central value proposition. The manuscript must explicitly state whether the reported token budgets include the full regeneration overhead (multiple suffix samples per original trace) required to compute the consistency scores. If only initial full traces are counted, the net savings are not demonstrated and the accuracy-per-token claim cannot be evaluated.
Authors: We thank the referee for this observation. The reported token budgets for prefix consistency explicitly include the full regeneration overhead: for each initial trace, the total token count encompasses the k suffix regenerations performed to compute the consistency weight. This net accounting is what enables the comparison showing that prefix consistency reaches the standard MV accuracy plateau with substantially fewer total tokens (up to 21x, median 4.6x). We will add an explicit statement and, if space permits, a short breakdown of token components in the Results section to remove any ambiguity. revision: yes
-
Referee: [Experimental setup and §4] Experimental setup and §4 (truncation and regeneration protocol): the difference in answer reproduction rates between correct and incorrect traces is treated as a stable weighting signal, yet no details are provided on truncation length distribution, number of regenerations per trace, or controls for prompt sensitivity and temperature. Without these, it is impossible to verify that the observed reliability gap is robust enough to support the reported gains across models and tasks.
Authors: We agree that these protocol details should be stated more explicitly for reproducibility. In the revised §4 we will add: (i) truncation lengths are sampled uniformly from the interval [30%, 70%] of each trace length; (ii) we use 10 regenerations per trace in the main experiments (with ablation on 5 and 20); (iii) all sampling (initial and regeneration) uses the identical prompt template and temperature (0.7) with no additional self-rating or modified instructions. We will also note that prompt sensitivity was not exhaustively varied beyond the standard settings used for all baselines. revision: yes
Circularity Check
No significant circularity
full rationale
The paper defines prefix consistency directly from measured reproduction rates of truncated CoT traces, using the empirical difference between correct and incorrect answers as a weighting signal. No equations or steps reduce the method to its own inputs by construction, no parameters are fitted and then relabeled as predictions, and the provided text contains no load-bearing self-citations or imported uniqueness results. The efficiency claims are presented as experimental outcomes rather than tautological derivations, making the chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe truncate each sample’s CoT at a specified fraction and regenerate continuations from the prefix... prefix consistency score of a in group i by c(τ)i(a) := |{a′ ∈ A(τ)i : a′ = a}| / 2
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearTheorem 1 (PC-WMV strictly improves over Standard MV when rC(τ) > rW(τ))
Reference graph
Works this paper leans on
-
[1]
10 Yichao Fu, Xuewei Wang, Hao Zhang, Yuandong Tian, and Jiawei Zhao
URLhttps://openreview.net/forum?id=yf1icZHC-l9. 10 Yichao Fu, Xuewei Wang, Hao Zhang, Yuandong Tian, and Jiawei Zhao. Deep Think with Confidence. InThe Fourteenth International Conference on Learning Representations, 2026. URL https: //openreview.net/forum?id=8LqHs0KIM7. Zeyu Gan, Yun Liao, and Yong Liu. Rethinking External Slow-Thinking: From Snowball Er...
work page 2026
-
[2]
Hasan Abed Al Kader Hammoud, Hani Itani, and Bernard Ghanem
URLhttps://openreview.net/forum?id=lAjj22UxZy. Hasan Abed Al Kader Hammoud, Hani Itani, and Bernard Ghanem. Beyond the Last Answer: Your Reasoning Trace Uncovers More than You Think.arXiv preprint arXiv:2504.20708, 2025. URL https://arxiv.org/abs/2504.20708. Enyi Jiang, Changming Xu, Nischay Singh, Tian Qiu, and Gagandeep Singh. Robust Answers, Fragile Lo...
-
[3]
Ishan Jindal, Sai Prashanth Akuthota, Jayant Taneja, and SACHIN DEV SHARMA
URLhttps://arxiv.org/abs/2505.17406. Ishan Jindal, Sai Prashanth Akuthota, Jayant Taneja, and SACHIN DEV SHARMA. THE PATH OF LEAST RESISTANCE: GUIDING LLM REASONING TRAJECTORIES WITH PREFIX CONSENSUS. InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=hrnSqERgPn. Saurav Kadavath, Tom Conerly, Am...
-
[4]
12 Alexander von Recum, Leander Girrbach, and Zeynep Akata
URLhttps://aclanthology.org/2023.acl-long.557/. 12 Alexander von Recum, Leander Girrbach, and Zeynep Akata. Are Reasoning LLMs Robust to Interventions on Their Chain-of-Thought? InThe Fourteenth International Conference on Learning Representations, 2026. URLhttps://openreview.net/forum?id=aQZIpELFwp. Keheng Wang, Feiyu Duan, Sirui Wang, Peiguang Li, Yunse...
-
[5]
studied whether LLMs can express uncertainty and found that verbalized confidence is often poorly calibrated. Scalena et al. [2025] used per-token entropy to allocate compute adaptively during generation, a token-level compute-allocation complement to our sample-level reliability estimation. All of these signals rely on the model’s own log-probabilities o...
work page 2025
-
[6]
found that reasoning models can be brittle to minor perturbations in the input. von Recum et al. [2026] systematically evaluated seven intervention types on open-weight reasoning LLMs and found that robustness degrades more when interventions occur early in the CoT. Jiang et al. [2025] showed that correct answers persist even when reasoning logic is pertu...
work page 2026
-
[7]
Pr ci(a) = 1 2 . Substituting the above probabilities, we obtain Φw(a) =w(1)π(a)T(a→a) +w( 1 2) π(a) +π →(a)−2π(a)T(a→a) . Rearranging terms gives Φw(a) =w( 1 2) π(a) +π →(a) + w(1)−2w( 1 2) π(a)T(a→a), which is exactly Eq. (17). C.2 Asymptotic Convergence of PC-WMV Throughout this subsection we assume the i.i.d. setup of Proposition 1. By Proposition 2, ...
-
[8]
= 0, then Assumption 2 is unnecessary: Assumption 1 alone implies ˆaPC N →a ⋆ almost surely. Proof. Fix any wrong a̸=a ⋆. By Assumption 1, the self-reproduction bracket of Eq. (18) is strictly positive, so the self-reproduction term is nonnegative and is strictly positive wheneverλ w >0. 19 For part (a), Assumption 2 makes the pooled-mass bracket of Eq. (...
-
[9]
Hence a⋆ is the unique maximizer ofΦ w, and Proposition 1 yieldsˆaPC N →a ⋆ almost surely
is strictly positive, so Φw(a⋆)>Φ w(a) for every wrong a. Hence a⋆ is the unique maximizer ofΦ w, and Proposition 1 yieldsˆaPC N →a ⋆ almost surely. For part (b), if w( 1
-
[10]
Thus ˆaPC N →a ⋆ almost surely without Assumption 2
= 0 the pooled-mass term vanishes identically and λw =w(1)>0 , so the strict positivity of the self-reproduction term suffices to giveΦw(a⋆)>Φ w(a) for every wrong a. Thus ˆaPC N →a ⋆ almost surely without Assumption 2. C.3 Proof of Theorem 1 Theorem 1 follows from Theorem 2 by specializing to the binary case A={a ⋆, a′}, where a⋆ is the correct answer an...
- [11]
-
[12]
times the bracket: Φw(a⋆)−Φ w(a′) =w(1) π(a⋆)T(a ⋆ →a ⋆)−(1−π(a ⋆))T(a ′ →a ′) .(22) The choice ofwthus enters only throughw(1). Proof.By Eq. (22) andw(1)>0,Φ w(a⋆)>Φ w(a′)if and only if π(a⋆)T(a ⋆ →a ⋆)>(1−π(a ⋆))T(a ′ →a ′). By Proposition 1, this is equivalent to ˆaPC N →a ⋆ almost surely. Identifying rC :=T(a ⋆ →a ⋆) and rW :=T(a ′ →a ′)via Eq. (13) r...
-
[13]
Hence PC-WMV converges where Standard MV does not on the interval rW /(rC +r W )< π(a ⋆)≤ 1 2, which has positive length if and only ifr C > r W . 20 C.4 Empirical Verification of Assumptions Table 5 verifies that Assumption 1 (A1) and Assumption 2 (A2) hold empirically on Q′ :={q∈ Q: 0< π q(a⋆ q)<1} , the subset of problems on which the verification is n...
work page 2026
-
[14]
on the self-reproduction term π(a)T(a→a) (the joint probability that a is both the initial and the regenerated answer) takes values 0, 1 2, 3 4 for PC-linear, PC-quadratic, PC-cubic respectively, so largern upweights self-reproducing candidates more strongly. The exception is Nemotron2-9B, whose FrontierScience-Olympiad discrimination gap is the smallest ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.