Recognition: 2 theorem links
· Lean TheoremDRIP-R: A Benchmark for Decision-Making and Reasoning Under Real-World Policy Ambiguity in the Retail Domain
Pith reviewed 2026-05-11 02:36 UTC · model grok-4.3
The pith
Frontier LLMs fundamentally disagree on identical policy-ambiguous retail scenarios, showing ambiguity as a systematic challenge to their decision-making.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper establishes that frontier models fundamentally disagree on how to resolve identical policy-ambiguous scenarios in retail returns. By constructing DRIP-R with curated scenarios that admit no single correct resolution, realistic customer personas, full-duplex conversational simulation with tool-calling, and multi-judge evaluation across policy adherence, dialogue quality, behavioral alignment, and resolution quality, the work shows that ambiguity poses a genuine and systematic challenge to LLM decision-making.
What carries the argument
DRIP-R benchmark that systematically exploits real-world retail policy ambiguities to build scenarios with no single correct resolution, paired with customer personas, full-duplex conversational simulation including tool-calling, and a multi-judge evaluation framework covering policy adherence, dialogue quality, behavioral alignment, and resolution quality.
If this is right
- LLM agents deployed in retail will exhibit inconsistent behavior on the same customer queries under ambiguous policies.
- Benchmarks for agent decision-making must incorporate ambiguity rather than assume unique correct answers.
- Retail LLM applications require additional mechanisms beyond standard training to manage multiple valid policy interpretations.
- Disagreement among models indicates that current architectures lack reliable ways to detect or navigate policy ambiguity.
Where Pith is reading between the lines
- Extending the benchmark to other domains such as healthcare or legal services could reveal whether ambiguity challenges are domain-specific or general.
- Agent systems may benefit from explicit modules that surface multiple interpretations before committing to a response.
- Training data that includes many examples of ambiguous cases might reduce but not eliminate the observed disagreements.
- The multi-judge approach suggests that single-metric leaderboards will understate real-world reliability problems.
Load-bearing premise
The selected scenarios truly admit no single correct resolution and the multi-judge evaluation framework accurately measures real-world policy adherence and behavioral alignment without introducing its own biases.
What would settle it
A result in which all frontier models produce identical decisions and receive matching high scores from the multi-judge framework across every ambiguous scenario would falsify the claim of fundamental and systematic disagreement.
Figures


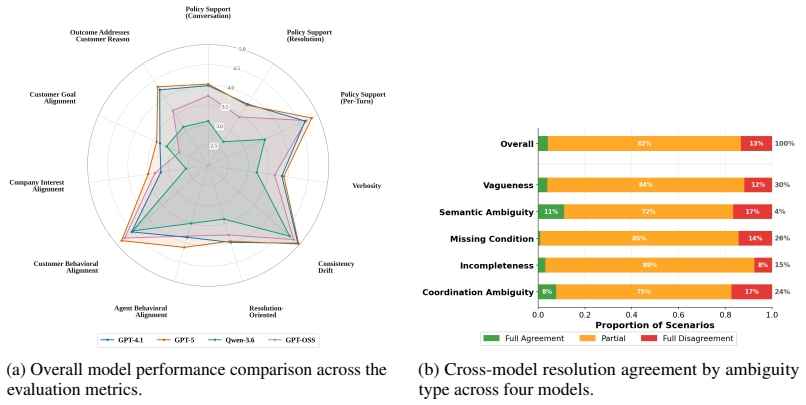
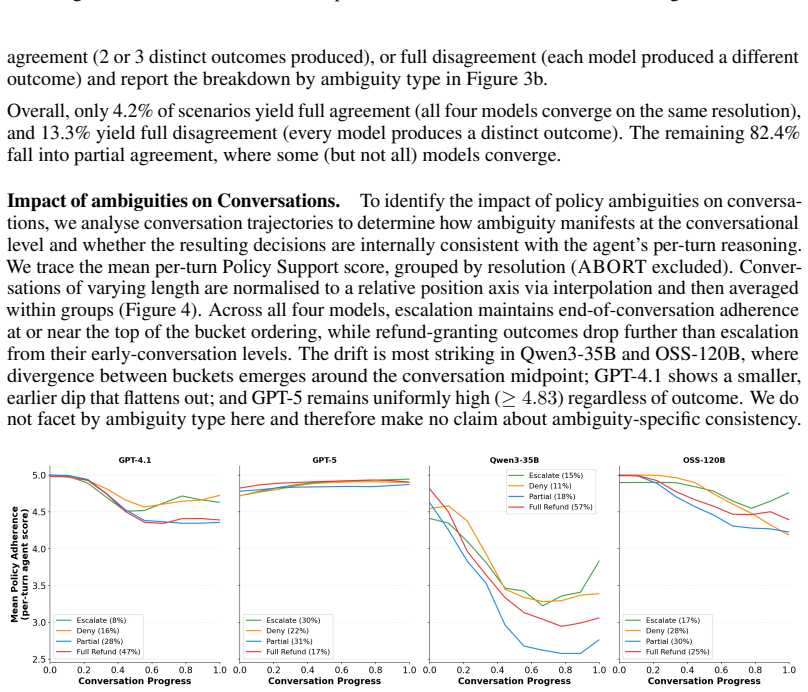

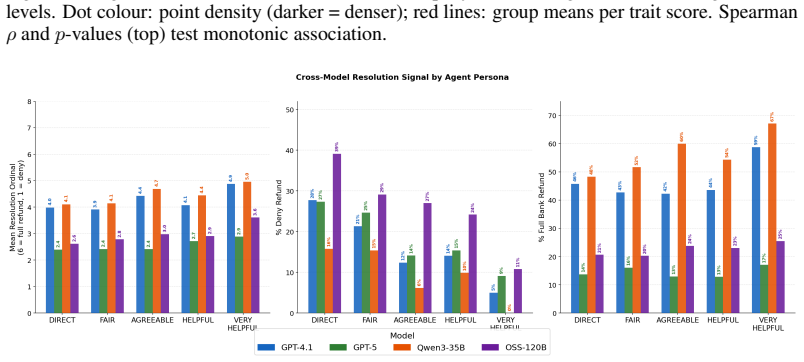



read the original abstract
LLM-based agents are increasingly deployed for routine but consequential tasks in real-world domains, where their behavior is governed by inherently ambiguous domain policies that admit multiple valid interpretations. Despite the prevalence of such ambiguities in practice, existing agent benchmarks largely assume unambiguous, well-specified policies, leaving a critical evaluation gap. We introduce DRIP-R, a benchmark that systematically exploits real-world retail policy ambiguities to construct scenarios in which no single correct resolution exists. DRIP-R comprises a curated set of policy-ambiguous return scenarios paired with a realistic customer personas, a full-duplex conversational simulation with tool-calling capabilities and a multi-judge evaluation framework covering policy adherence, dialogue quality, behavioral alignment, and resolution quality. Our experiments show that frontier models fundamentally disagree on identical policy-ambiguous scenarios, confirming that ambiguity poses a genuine and systematic challenge to LLM decision-making.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces DRIP-R, a benchmark for LLM-based agents handling decision-making under real-world policy ambiguity in retail return scenarios. It consists of curated policy-ambiguous scenarios paired with customer personas, a full-duplex conversational simulation with tool-calling, and a multi-judge evaluation framework assessing policy adherence, dialogue quality, behavioral alignment, and resolution quality. Experiments demonstrate that frontier models produce fundamentally inconsistent decisions on identical ambiguous scenarios.
Significance. If the scenarios are shown to be verifiably ambiguous, the benchmark would address a notable gap in agent evaluation, which typically assumes clear policies, and provide a realistic testbed in the retail domain. The conversational setup and multi-dimensional judging add practical value for assessing agent robustness to policy interpretation. The work could inform development of LLMs better suited to ambiguous real-world constraints.
major comments (2)
- [Abstract and §3 (DRIP-R construction)] Abstract and benchmark construction section: The central claim that scenarios 'admit no single correct resolution' and that model disagreement confirms ambiguity as a 'genuine and systematic challenge' is load-bearing, yet the manuscript provides no quantitative validation of ambiguity (e.g., inter-rater agreement metrics such as Fleiss' kappa from independent retail experts or hold-out validation by domain managers). Without this, disagreement could stem from prompt sensitivity or model priors rather than policy ambiguity per se.
- [Experiments] Experiments section: The abstract reports model disagreement but lacks details on the number of scenarios, statistical tests for disagreement significance, controls for prompt variations, or analysis of whether disagreement correlates with specific ambiguity types; this weakens support for the headline result.
minor comments (1)
- [Abstract] The abstract would benefit from including at least one key quantitative result (e.g., disagreement rate across models) to better convey the empirical findings.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. We address each major comment point-by-point below and have revised the paper to incorporate the suggested improvements where feasible.
read point-by-point responses
-
Referee: [Abstract and §3 (DRIP-R construction)] Abstract and benchmark construction section: The central claim that scenarios 'admit no single correct resolution' and that model disagreement confirms ambiguity as a 'genuine and systematic challenge' is load-bearing, yet the manuscript provides no quantitative validation of ambiguity (e.g., inter-rater agreement metrics such as Fleiss' kappa from independent retail experts or hold-out validation by domain managers). Without this, disagreement could stem from prompt sensitivity or model priors rather than policy ambiguity per se.
Authors: We agree that explicit quantitative validation of scenario ambiguity strengthens the central claim and helps rule out alternative explanations such as prompt sensitivity. The original construction process relied on curation from real retail return policies that are documented in practice as open to multiple valid interpretations. In the revised manuscript we have added a dedicated validation subsection to §3 describing a study with independent retail experts who rated the scenarios for ambiguity, along with inter-rater agreement metrics. We have also incorporated additional prompt-variation controls in the experiments to further isolate the effect of policy ambiguity. revision: yes
-
Referee: [Experiments] Experiments section: The abstract reports model disagreement but lacks details on the number of scenarios, statistical tests for disagreement significance, controls for prompt variations, or analysis of whether disagreement correlates with specific ambiguity types; this weakens support for the headline result.
Authors: We acknowledge that the experimental reporting can be made more rigorous. The revised Experiments section now explicitly states the total number of scenarios, reports statistical tests assessing the significance of observed model disagreements, describes controls that evaluate multiple prompt templates to test robustness, and includes a breakdown of disagreement rates by the different ambiguity categories defined during benchmark construction. revision: yes
Circularity Check
No circularity: benchmark curation and empirical disagreement are independent observations.
full rationale
The paper constructs DRIP-R by curating policy-ambiguous retail scenarios and reports experimental results showing model disagreement. This is an empirical finding on an externally motivated domain, not a derivation that reduces to its inputs by construction, fitted parameters renamed as predictions, or self-citation chains. No equations, ansatzes, or uniqueness theorems are invoked that loop back to the paper's own definitions. The central claim remains falsifiable via external retail experts or additional validation sets.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce DRIP-R, a benchmark that systematically exploits real-world retail policy ambiguities to construct scenarios in which no single correct resolution exists.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Policy adherence … behavioral alignment … resolution quality … multi-judge evaluation framework
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Large Language Model Agent: A Survey on Methodology, Applications and Challenges
Large language model agent: A survey on methodology, applications and challenges , author=. arXiv preprint arXiv:2503.21460 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Asaf Yehudai and Lilach Eden and Alan Li and Guy Uziel and Yilun Zhao and Roy Bar-Haim and Arman Cohan and Michal Shmueli-Scheuer , title=. CoRR , volume=. 2025 , month=
work page 2025
-
[3]
Scaling synthetic data creation with 1,000,000,000 personas.arXiv:2406.20094, 2024
Scaling synthetic data creation with 1,000,000,000 personas , author=. arXiv preprint arXiv:2406.20094 , year=
-
[4]
McCrae, Robert R. and John, Oliver P. , title =. Journal of Personality , volume =. doi:https://doi.org/10.1111/j.1467-6494.1992.tb00970.x , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1111/j.1467-6494.1992.tb00970.x , abstract =
-
[5]
A Cultural Approach to Interpersonal Communication: Essential Readings , pages=
Put Down That Paper and Talk To Me: Rapport-Talk and Report-Talk , author=. A Cultural Approach to Interpersonal Communication: Essential Readings , pages=
-
[6]
Martin Joss, The Five Clocks (Book Review) , author=. Arch. 1966 , publisher=
work page 1966
-
[7]
Encyclopedia of Public Policy , pages=
Ambiguity in Public Policy , author=. Encyclopedia of Public Policy , pages=. 2023 , publisher=
work page 2023
-
[8]
Public Performance & Management Review , volume=
Exploring the risk of goal displacement in regulatory enforcement agencies: A goal-ambiguity approach , author=. Public Performance & Management Review , volume=. 2021 , publisher=
work page 2021
-
[9]
Barres, Victor and Dong, Honghua and Ray, Soham and Si, Xujie and Narasimhan, Karthik , journal=
-
[10]
Victor Barres and Honghua Dong and Soham Ray and Xujie Si and Karthik Narasimhan , title=. CoRR , volume=. 2025 , month=
work page 2025
-
[11]
Ray, Soham and Dhandhania, Keshav and Barres, Victor and Narasimhan, Karthik , journal=
-
[12]
arXiv preprint arXiv:2410.06703 , year=
St-webagentbench: A benchmark for evaluating safety and trustworthiness in web agents , author=. arXiv preprint arXiv:2410.06703 , year=
-
[13]
Agent-SafetyBench: Evaluating the Safety of LLM Agents
Agent-safetybench: Evaluating the safety of llm agents , author=. arXiv preprint arXiv:2412.14470 , year=
work page internal anchor Pith review arXiv
-
[14]
arXiv preprint arXiv:2504.14064 , year=
Doomarena: A framework for testing ai agents against evolving security threats , author=. arXiv preprint arXiv:2504.14064 , year=
-
[15]
How should policy actors respond to buzzwords? Three ways to deal with policy ambiguity , author=. Policy Sciences , pages=. 2025 , publisher=
work page 2025
-
[16]
Operationalizing Responsible AI Policies with LLMs: an End-to-End Monitoring Prototype , year =
Zieli\'. Operationalizing Responsible AI Policies with LLMs: an End-to-End Monitoring Prototype , year =. Proceedings of the Extended Abstracts of the 2026 CHI Conference on Human Factors in Computing Systems , articleno =. doi:10.1145/3772363.3799675 , abstract =
-
[17]
Journal of public administration research and theory , volume=
Synthesizing the implementation literature: The ambiguity-conflict model of policy implementation , author=. Journal of public administration research and theory , volume=. 1995 , publisher=
work page 1995
-
[18]
Health & Social Care in the Community , volume =
Bhaskar, Le-Tien and Mulvale, Gillian and Underdown, Vivien and Des Jardins, Mike , title =. Health & Social Care in the Community , volume =. doi:https://doi.org/10.1155/hsc/9390387 , url =. https://onlinelibrary.wiley.com/doi/pdf/10.1155/hsc/9390387 , abstract =
-
[19]
Public Administration , volume=
Strategies for dealing with policy ambiguities , author=. Public Administration , volume=. 2023 , publisher=
work page 2023
-
[20]
Theories of the policy process , pages=
The multiple streams framework: Foundations, refinements, and empirical applications , author=. Theories of the policy process , pages=. 2023 , publisher=
work page 2023
-
[21]
International Review of Public Policy , volume=
Ambiguity, uncertainty and implementation , author=. International Review of Public Policy , volume=. 2021 , publisher=
work page 2021
-
[22]
Administration & Society , volume=
Policy learning, policy failure, and the mitigation of policy risks: Re-thinking the lessons of policy success and failure , author=. Administration & Society , volume=. 2022 , publisher=
work page 2022
-
[23]
Towards Enforcing Company Policy Adherence in Agentic Workflows , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
work page 2025
-
[24]
American political science review , volume=
A grammar of institutions , author=. American political science review , volume=. 1995 , publisher=
work page 1995
-
[25]
Delphic oracles: Ambiguity, institutions, and multiple streams , author=. Policy Sciences , volume=. 2016 , publisher=
work page 2016
-
[26]
Instajudge: Aligning judgment bias of llm-as-judge with humans in industry applications , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing: Industry Track , pages=
work page 2025
-
[27]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
G-eval: NLG evaluation using gpt-4 with better human alignment , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
work page 2023
-
[28]
Judgebench: A benchmark for evaluating llm-based judges,
Judgebench: A benchmark for evaluating llm-based judges , author=. arXiv preprint arXiv:2410.12784 , year=
-
[29]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
MULTIVOX: A Benchmark for Evaluating Voice Assistants for Multimodal Interactions , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2025
-
[30]
Massey, Aaron K. and Rutledge, Richard L. and Antón, Annie I. and Swire, Peter P. , booktitle=. Identifying and classifying ambiguity for regulatory requirements , year=
-
[31]
Demystifying Evals for AI Agents , author =. Anthropic , publisher =. 2026 , month =
work page 2026
-
[32]
Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
Toolsandbox: A stateful, conversational, interactive evaluation benchmark for llm tool use capabilities , author=. Findings of the Association for Computational Linguistics: NAACL 2025 , pages=
work page 2025
-
[33]
Trajectory2Task: Training Robust Tool-Calling Agents with Synthesized Yet Verifiable Data for Complex User Intents , author=. arXiv preprint arXiv:2601.20144 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[34]
Findings of the Association for Computational Linguistics: EMNLP , volume=
ACEBench: A comprehensive evaluation of LLM tool usage , author=. Findings of the Association for Computational Linguistics: EMNLP , volume=
-
[35]
Ambibench: Benchmarking mobile gui agents beyond one-shot instructions in the wild,
Ambibench: Benchmarking mobile gui agents beyond one-shot instructions in the wild , author=. arXiv preprint arXiv:2602.11750 , year=
-
[36]
Probing the multi-turn planning capabilities of LLMs via 20 question games , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[37]
Frontiers in Public Health , volume=
Toward a framework of ambiguity: a qualitative understanding of healthcare policy design and governance mechanism in China , author=. Frontiers in Public Health , volume=. 2025 , publisher=
work page 2025
-
[38]
Ambiguity and clarity in China's adaptive policy communication , author=. The China Quarterly , volume=. 2024 , publisher=
work page 2024
-
[39]
Online readings in Psychology and Culture , volume=
An overview of the Schwartz theory of basic values , author=. Online readings in Psychology and Culture , volume=
- [40]
-
[41]
Ambiguity in requirements engineering: Towards a unifying framework , author=. From Software Engineering to Formal Methods and Tools, and Back: Essays Dedicated to Stefania Gnesi on the Occasion of Her 65th Birthday , pages=. 2019 , publisher=
work page 2019
-
[42]
Alex Cuadron Lafuente and Pengfei Yu and Yang Liu and Arpit Gupta , title =. Unknown , url =
-
[43]
Problems, politics, and policy streams in policy implementation , author=. Governance , volume=. 2019 , publisher=
work page 2019
-
[44]
Four Essays on Liberty , author=
-
[45]
Street Level Bureaucracy: Dilemmas of the Individual in Public Services , urldate =
Lipsky, Michael , publisher =. Street Level Bureaucracy: Dilemmas of the Individual in Public Services , urldate =
-
[46]
International journal of social welfare , volume=
Meeting (or not) at the street level? A literature review on street-level research in public management, social policy and social work , author=. International journal of social welfare , volume=. 2018 , publisher=
work page 2018
-
[47]
Beyond IVR: Benchmarking Customer Support LLM Agents for Business-Adherence , author=. Proceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 5: Industry Track) , pages=
-
[48]
In: Proceedings of the 29th Symposium on Operating Systems Principles
Kwon, Woosuk and Li, Zhuohan and Zhuang, Siyuan and Sheng, Ying and Zheng, Lianmin and Yu, Cody Hao and Gonzalez, Joseph and Zhang, Hao and Stoica, Ion , title =. Proceedings of the 29th Symposium on Operating Systems Principles , pages =. 2023 , isbn =. doi:10.1145/3600006.3613165 , abstract =
-
[49]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Ambignlg: Addressing task ambiguity in instruction for nlg , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
work page 2024
-
[50]
Proceedings of the 31st International Conference on Computational Linguistics , pages=
Making Task-Oriented Dialogue Datasets More Natural by Synthetically Generating Indirect User Requests , author=. Proceedings of the 31st International Conference on Computational Linguistics , pages=
-
[51]
Maxim Tkachenko and Mikhail Malyuk and Andrey Holmanyuk and Nikolai Liubimov , year=
-
[52]
Derivation of new readability formulas (automated readability index, fog count and flesch reading ease formula) for navy enlisted personnel , author=
-
[53]
Aggregate vs. Personalized Judges in Business Idea Evaluation: Evidence from Expert Disagreement
Aggregate vs. Personalized Judges in Business Idea Evaluation: Evidence from Expert Disagreement , author=. arXiv preprint arXiv:2604.22517 , year=
work page internal anchor Pith review Pith/arXiv arXiv
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.