Recognition: 2 theorem links
· Lean TheoremSARC: A Governance-by-Architecture Framework for Agentic AI Systems
Pith reviewed 2026-05-11 02:07 UTC · model grok-4.3
The pith
SARC embeds constraints as first-class objects in the agent loop to enforce them before execution occurs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
SARC treats constraints as specification objects alongside state and action space, compiling them into a Pre-Action Gate, Action-Time Monitor, Post-Action Auditor, and Escalation Router that together maintain specification-trace correspondence. Under exact predicates the architecture records zero hard violations; its declared PAA throttling response reduces soft overages by 89.5 percent compared with policy-as-code-only. Predicate-noise and enforcement-failure sweeps indicate that any remaining hard violations scale with enforcement-stack error rather than environmental opportunity. The framework also shows that finite reward penalties do not generally substitute for hard runtime constraints
What carries the argument
The SARC specification object, which encodes each constraint's source, class, predicate, verification point, response protocol, and operating point for direct compilation into the four enforcement sites of the agent loop.
If this is right
- Multi-agent workflows inherit constraints through propagation and authority intersection while preserving attribution in trace trees.
- Residual hard violations under SARC scale directly with enforcement-stack error rather than with environmental violation opportunity.
- Finite reward penalties cannot serve as a general substitute for hard runtime constraints.
- Specification-trace correspondence invariants must hold for the architecture to deliver its reported enforcement guarantees.
Where Pith is reading between the lines
- The same predicate-and-verification-point structure could be applied to other tool-using domains where obligations must bind before external services are called.
- Integration of governance at the architectural level may reduce reliance on extensive post-deployment audits once enforcement sites are verified.
- Synthetic procurement results leave open whether the 89.5 percent soft-overage reduction holds when predicate evaluation itself carries non-negligible latency.
Load-bearing premise
Constraints can be written as precise, verifiable predicates whose evaluation points line up with the agent loop without introducing new failure modes or requiring perfect enforcement reliability.
What would settle it
A reproduction of the 50-seed procurement evaluation that uses exact predicates yet records any hard-constraint violation not traceable to an enforcement-stack error would falsify the zero-violation result.
Figures


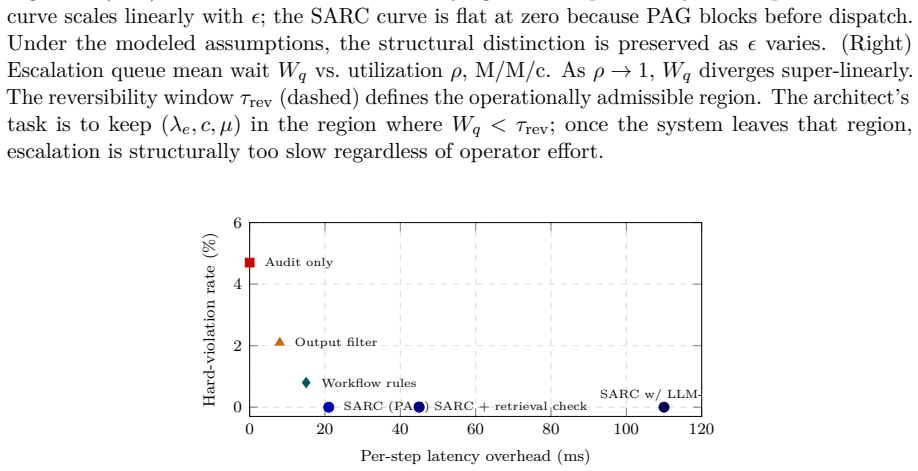
read the original abstract
Agentic AI systems increasingly act through tools, sub-agents, and external services, but governance controls are still commonly attached to prompts, dashboards, or post-hoc documentation. This creates a structural mismatch in regulated settings: obligations that must constrain execution are often evaluated only after execution has occurred. We introduce SARC, a runtime governance architecture for tool-using agents that treats constraints as first-class specification objects alongside state, action space, and reward. A SARC specification declares each constraint's source, class, predicate, verification point, response protocol, and operating point, and compiles these into four enforcement sites in the agent loop: a Pre-Action Gate, an Action-Time Monitor, a Post-Action Auditor, and an Escalation Router. We formalize the minimal invariants required for specification-trace correspondence, show why finite reward penalties do not generally substitute for hard runtime constraints, and extend the architecture to multi-agent workflows through constraint propagation, authority intersection, and attribution-preserving trace trees. We implement a prototype audit checker and report a reproducible synthetic evaluation over 50 seeds comparing SARC against post-hoc audit, output filtering, workflow rules, and policy-as-code-only baselines on a procurement task. SARC executes zero hard-constraint violations under exact predicates; its declared PAA throttling response reduces soft-window overages by 89.5% relative to policy-as-code-only. Predicate-noise and enforcement-failure sweeps are consistent with the claim that residual hard violations under SARC scale with enforcement-stack error rather than environmental violation opportunity. SARC provides the architectural substrate through which obligations can be made executable, inspectable, and auditable at runtime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SARC, a runtime governance architecture for tool-using agentic AI systems. It treats constraints as first-class specification objects (with source, class, predicate, verification point, response protocol, and operating point) that compile into four enforcement sites in the agent loop: Pre-Action Gate, Action-Time Monitor, Post-Action Auditor, and Escalation Router. The paper formalizes minimal invariants for specification-trace correspondence, argues that finite reward penalties do not substitute for hard runtime constraints, extends the approach to multi-agent workflows via constraint propagation and authority intersection, and reports a reproducible synthetic evaluation on a procurement task over 50 seeds. The evaluation claims zero hard-constraint violations under exact predicates and an 89.5% reduction in soft-window overages relative to policy-as-code baselines, with sweeps suggesting residuals scale with enforcement-stack error.
Significance. If the central claims hold, SARC provides an architectural substrate for making obligations executable, inspectable, and auditable at runtime in regulated agentic settings, addressing the mismatch between post-hoc controls and execution-time constraints. Strengths include the formalization of invariants, the extension to multi-agent trace trees, and the reproducible synthetic evaluation over 50 seeds with explicit baseline comparisons. The work could serve as a foundation for governance in tool-using agents if enforcement completeness is demonstrated.
major comments (3)
- [Abstract and Evaluation section] Abstract and Evaluation section: The claim that SARC executes zero hard-constraint violations under exact predicates is load-bearing for the paper's contribution but rests on the unproven assumption that all actions, tool calls, and sub-agent invocations are forced through the four enforcement sites. The synthetic procurement-task evaluation (50 seeds) and enforcement-failure sweeps provide no evidence that the prototype prevents architectural bypass paths (e.g., direct external invocations or sub-agent calls that skip the Pre-Action Gate or Action-Time Monitor). Without such evidence, the zero-violation result may be an artifact of the controlled test harness rather than a property of the framework.
- [Evaluation section] Evaluation section: The reported 89.5% reduction in soft-window overages and the scaling of residual hard violations with enforcement-stack error are presented without details on predicate implementation, baseline configurations, or statistical significance testing. This makes it difficult to assess whether the performance numbers are robust or sensitive to the specific synthetic task and harness.
- [Multi-agent extension section] Multi-agent extension section: The architecture is extended to multi-agent workflows through constraint propagation, authority intersection, and attribution-preserving trace trees, yet the evaluation remains limited to a single-agent procurement task. No results are reported for multi-agent scenarios, which limits support for the broader applicability claim.
minor comments (2)
- The abstract states that the evaluation is 'reproducible' but provides no code, data, or artifact availability statement; this should be added to support the reproducibility claim.
- [Evaluation section] The paper mentions 'predicate-noise and enforcement-failure sweeps' but does not specify the noise models or error injection mechanisms in sufficient detail for independent replication.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed feedback on our manuscript. The comments highlight valid points regarding the scope of our empirical claims and the need for greater transparency. We address each major comment below with specific plans for revision.
read point-by-point responses
-
Referee: [Abstract and Evaluation section] The claim that SARC executes zero hard-constraint violations under exact predicates is load-bearing for the paper's contribution but rests on the unproven assumption that all actions, tool calls, and sub-agent invocations are forced through the four enforcement sites. The synthetic procurement-task evaluation (50 seeds) and enforcement-failure sweeps provide no evidence that the prototype prevents architectural bypass paths (e.g., direct external invocations or sub-agent calls that skip the Pre-Action Gate or Action-Time Monitor). Without such evidence, the zero-violation result may be an artifact of the controlled test harness rather than a property of the framework.
Authors: We agree that the zero-violation result holds only under the assumption that the agent runtime routes every action through the four SARC enforcement sites, as required by the specification-trace correspondence invariants formalized in the paper. The synthetic evaluation uses a controlled prototype harness that enforces this routing by design, which demonstrates the mechanisms but does not test resistance to bypasses in arbitrary deployments. In the revised manuscript we will add a new subsection titled 'Integration Requirements and Bypass Considerations' that explicitly states the architectural prerequisites for the zero-violation guarantee, discusses realistic bypass vectors, and recommends mitigation approaches such as capability-based tool access and runtime attestation. We will also qualify the abstract and evaluation claims accordingly. This revision clarifies the scope without requiring additional experiments. revision: partial
-
Referee: [Evaluation section] The reported 89.5% reduction in soft-window overages and the scaling of residual hard violations with enforcement-stack error are presented without details on predicate implementation, baseline configurations, or statistical significance testing. This makes it difficult to assess whether the performance numbers are robust or sensitive to the specific synthetic task and harness.
Authors: The referee is correct that additional implementation and statistical details are needed for proper assessment. We will expand the Evaluation section with: (i) explicit descriptions and example code for the procurement-task predicates, (ii) complete configuration parameters and rule sets for each baseline (post-hoc audit, output filtering, workflow rules, and policy-as-code), and (iii) statistical significance results including means, standard deviations, and paired statistical tests across the 50 seeds for the 89.5% reduction. We will also include a brief sensitivity analysis to task parameters. These additions will be incorporated in the next version to improve reproducibility and robustness evaluation. revision: yes
-
Referee: [Multi-agent extension section] The architecture is extended to multi-agent workflows through constraint propagation, authority intersection, and attribution-preserving trace trees, yet the evaluation remains limited to a single-agent procurement task. No results are reported for multi-agent scenarios, which limits support for the broader applicability claim.
Authors: We acknowledge that the quantitative evaluation is limited to the single-agent procurement task while the multi-agent support is developed at the architectural level. The single-agent results validate the core compilation, enforcement sites, and invariants that the multi-agent extension builds upon. In revision we will augment the Multi-agent extension section with a concrete two-agent illustrative example executed in the existing prototype, demonstrating constraint propagation, authority intersection, and trace attribution. We will also add an explicit limitations paragraph noting that full-scale multi-agent quantitative benchmarks remain future work. This provides concrete support for the extension while accurately scoping the current empirical contribution. revision: partial
Circularity Check
No circularity; claims rest on synthetic evaluation outputs rather than self-referential definitions or fitted parameters
full rationale
The paper defines SARC as an architecture compiling constraints into four enforcement sites, formalizes specification-trace invariants, and reports empirical results from a reproducible synthetic evaluation (50 seeds) on a procurement task. Zero hard-violation and 89.5% soft-overage reduction figures are presented as direct measurements against baselines, not quantities derived by construction from fitted parameters or prior self-citations. No equations, ansatzes, or uniqueness theorems are invoked that reduce the central claims to inputs by definition. The evaluation harness is acknowledged as controlled, but this does not create circularity in the reported derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agent execution can be decomposed into pre-action, action-time, post-action phases with verifiable states at each point.
invented entities (2)
-
SARC specification object
no independent evidence
-
Pre-Action Gate, Action-Time Monitor, Post-Action Auditor, Escalation Router
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
SARC specification declares each constraint's source, class, predicate, verification point, response protocol, and operating point, and compiles these into four enforcement sites... invariants I1–I8... specification-trace correspondence
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
C = Ch ∪ Cs ∪ Ce... hard constraints at PAG... reference monitor properties mapped to I6,I7,I8
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Held, D., Tamar, A., & Abbeel, P. (2017). Constrained policy optimization.ICML, 22–31
work page 2017
-
[2]
(1999).Constrained Markov Decision Processes
Altman, E. (1999).Constrained Markov Decision Processes. Chapman & Hall/CRC
work page 1999
-
[3]
S., Edwards, A., Nosal, S., Hauser, D., Mauer, E., & Kaushal, R
Ancker, J. S., Edwards, A., Nosal, S., Hauser, D., Mauer, E., & Kaushal, R. (2017). Effects of workload, work complexity, and repeated alerts on alert fatigue in a clinical decision support system. BMC Medical Informatics and Decision Making, 17(36)
work page 2017
-
[4]
Baier, A., Ferraiolo, D., Gavrila, S., & Mell, P. (2022). Towards an architecture-independent authorization framework for the policy machine.NIST Internal Report 8360. 41
work page 2022
-
[5]
European Union. (2024). Regulation (EU) 2024/1689 (Artificial Intelligence Act).Official Journal of the European Union
work page 2024
-
[6]
Fournet, C., & Gordon, A. D. (2003). Stack inspection: Theory and variants.ACM Transactions on Programming Languages and Systems, 25(3), 360–399
work page 2003
-
[7]
García, J., & Fernández, F. (2015). A comprehensive survey on safe reinforcement learning.JMLR, 16, 1437–1480
work page 2015
-
[8]
Open Policy Agent contributors. (2017–present). Open Policy Agent: Policy-as-code for cloud-native systems. CNCF documentation; see also Sandall, T. et al., “OPA: Open Policy Agent,” SREcon, 2018
work page 2017
-
[9]
Kaelbling, L. P., Littman, M. L., & Cassandra, A. R. (1998). Planning and acting in partially observable stochastic domains.Artificial Intelligence, 101(1–2), 99–134
work page 1998
-
[10]
Krakovna, V., Uesato, J., Mikulik, V., et al. (2020). Specification gaming: the flip side of AI ingenuity. DeepMind Research Blog
work page 2020
-
[11]
Malgieri, G., & Pasquale, F. (2024). Licensing high-risk AI: Toward ex ante justification for a disruptive technology.Computer Law & Security Review, 52, 105899
work page 2024
-
[12]
Manheim, D., & Garrabrant, S. (2019). Categorizing variants of Goodhart’s Law.arXiv:1803.04585
work page Pith review arXiv 2019
-
[13]
(2023).AI Risk Management Framework (AI RMF 1.0)
National Institute of Standards and Technology. (2023).AI Risk Management Framework (AI RMF 1.0). NIST AI 100-1
work page 2023
-
[14]
Parasuraman, R., & Riley, V. (1997). Humans and automation: Use, misuse, disuse, abuse.Human Factors, 39(2), 230–253
work page 1997
-
[15]
Park, J. S., O’Brien, J. C., Cai, C. J., et al. (2023). Generative agents: Interactive simulacra of human behavior.UIST
work page 2023
-
[16]
G., Zhang, T., Wang, X., & Gonzalez, J
Patil, S. G., Zhang, T., Wang, X., & Gonzalez, J. E. (2024). Gorilla: Large language model connected with massive APIs.NeurIPS
work page 2024
-
[17]
Puterman, M. L. (1994).Markov Decision Processes: Discrete Stochastic Dynamic Programming. Wiley
work page 1994
-
[18]
Ray, A., Achiam, J., & Amodei, D. (2019). Benchmarking safe exploration in deep reinforcement learning.OpenAI Technical Report
work page 2019
-
[19]
Schick, T., Dwivedi-Yu, J., Dessì, R., et al. (2023). Toolformer: Language models can teach themselves to use tools.NeurIPS
work page 2023
-
[20]
Schneider, F. B. (2000). Enforceable security policies.ACM Transactions on Information and System Security, 3(1), 30–50
work page 2000
-
[21]
Sandhu, R., Coyne, E. J., Feinstein, H. L., & Youman, C. E. (1996). Role-based access control models.IEEE Computer, 29(2), 38–47
work page 1996
-
[22]
Shinn, N., Cassano, F., Gopinath, A., Narasimhan, K., & Yao, S. (2023). Reflexion: Language agents with verbal reinforcement learning.NeurIPS
work page 2023
-
[23]
Skalse, J., Howe, N. H. R., Krasheninnikov, D., & Krueger, D. (2022). Defining and characterizing reward hacking.NeurIPS
work page 2022
-
[24]
Smuha, N. A. (2021). From a “race to AI” to a “race to AI regulation”: Regulatory competition for artificial intelligence.Law, Innovation and Technology, 13(1), 57–84
work page 2021
-
[25]
Stooke, A., Achiam, J., & Abbeel, P. (2020). Responsive safety in reinforcement learning by PID Lagrangian methods.ICML
work page 2020
-
[26]
Sutton, R. S., & Barto, A. G. (2018).Reinforcement Learning: An Introduction(2nd ed.). MIT Press
work page 2018
-
[27]
Veale, M., & Borgesius, F. Z. (2021). Demystifying the Draft EU Artificial Intelligence Act.Computer Law Review International, 22(4), 97–112. 42
work page 2021
-
[28]
Wang, G., Xie, Y., Jiang, Y., et al. (2024). Voyager: An open-ended embodied agent with large language models.TMLR
work page 2024
-
[29]
Wu, Q., Bansal, G., Zhang, J., et al. (2023). AutoGen: Enabling next-gen LLM applications via multi-agent conversation.arXiv:2308.08155
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[30]
Hong, S., Zhuge, M., Chen, J., et al. (2024). MetaGPT: Meta programming for a multi-agent collaborative framework.ICLR
work page 2024
-
[31]
Liu, X., Yu, H., Zhang, H., et al. (2024). AgentBench: Evaluating LLMs as agents.ICLR
work page 2024
-
[32]
Li, J., Zhang, S., Liu, Y., et al. (2024). Multi-agent LLM systems with auction-based task allocation. NeurIPS Workshop on LLM Agents
work page 2024
-
[33]
Greshake, K., Abdelnabi, S., Mishra, S., Endres, C., Holz, T., & Fritz, M. (2023). Not what you’ve signed up for: Compromising real-world LLM-integrated applications with indirect prompt injection. ACM AISec
work page 2023
-
[34]
Debenedetti, E., Zhang, J., Balunović, M., Beurer-Kellner, L., Fischer, M., & Tramèr, F. (2024). AgentDojo: A dynamic environment to evaluate prompt injection attacks and defenses for LLM agents.NeurIPS
work page 2024
-
[35]
Yang, Q., Simão, T. D., Tindemans, S. H., & Spaan, M. T. J. (2021). WCSAC: Worst-case soft actor critic for safety-constrained reinforcement learning.AAAI
work page 2021
-
[36]
Yao, S., Zhao, J., Yu, D., et al. (2023). ReAct: Synergizing reasoning and acting in language models. ICLR
work page 2023
-
[37]
Mitchell, M., Wu, S., Zaldivar, A., et al. (2019). Model cards for model reporting.ACM FAccT, 220–229
work page 2019
-
[38]
Gebru, T., Morgenstern, J., Vecchione, B., et al. (2021). Datasheets for datasets.Communications of the ACM, 64(12), 86–92
work page 2021
-
[39]
Raji, I. D., Smart, A., White, R. N., et al. (2020). Closing the AI accountability gap: Defining an end-to-end framework for internal algorithmic auditing.ACM FAccT, 33–44
work page 2020
-
[40]
D., Xu, P., Honigsberg, C., & Ho, D
Raji, I. D., Xu, P., Honigsberg, C., & Ho, D. (2022). Outsider oversight: Designing a third-party audit ecosystem for AI governance.AAAI/ACM AIES
work page 2022
-
[41]
Kazhamiakin, R., Pistore, M., & Zengin, A. (2009). Cross-layer adaptation and monitoring of service-based applications.Engineering Service-Oriented Applications, Springer
work page 2009
-
[42]
Leucker, M., & Schallhart, C. (2009). A brief account of runtime verification.Journal of Logic and Algebraic Programming, 78(5), 293–303
work page 2009
-
[43]
Falcone, Y., Krstić, S., Reger, G., & Traytel, D. (2021). A taxonomy for classifying runtime verification tools.International Journal on Software Tools for Technology Transfer, 23, 255–284
work page 2021
-
[44]
Laurent, A., & Nyrup, R. (2024). Conformity assessment under the EU AI Act: A critical review of the high-risk regime.European Journal of Risk Regulation, 15(2), 318–340
work page 2024
-
[45]
Novelli, C., Casolari, F., Rotolo, A., Taddeo, M., & Floridi, L. (2024). AI risk assessment: A scenario-based, proportional methodology for the AI Act.Digital Society, 3(1), 13
work page 2024
-
[46]
Anderson, J. P. (1972).Computer Security Technology Planning Study. ESD-TR-73-51, Electronic Systems Division, U.S. Air Force
work page 1972
-
[47]
Lampson, B. W. (1971). Protection.Proceedings of the Fifth Princeton Symposium on Information Sciences and Systems, 437–443. Reprinted inACM Operating Systems Review, 8(1), 18–24
work page 1971
-
[48]
Burns, B., Grant, B., Oppenheimer, D., Brewer, E., & Wilkes, J. (2016). Borg, Omega, and Kubernetes.Communications of the ACM, 59(5), 50–57
work page 2016
-
[49]
Sigelman, B. H., Barroso, L. A., Burrows, M., et al. (2010). Dapper, a large-scale distributed systems tracing infrastructure.Google Technical Report
work page 2010
-
[50]
R., Shafer, I., Mace, J., Sigelman, B
Sambasivan, R. R., Shafer, I., Mace, J., Sigelman, B. H., Fonseca, R., & Ganger, G. R. (2016). Principled workflow-centric tracing of distributed systems.ACM Symposium on Cloud Computing (SoCC), 401–414. 43
work page 2016
-
[51]
Amodei, D., Olah, C., Steinhardt, J., Christiano, P., Schulman, J., & Mané, D. (2016). Concrete problems in AI safety.arXiv:1606.06565
work page internal anchor Pith review arXiv 2016
- [52]
- [53]
-
[54]
Bartocci, E., Falcone, Y., Francalanza, A., & Reger, G. (2018). Introduction to runtime verification. InLectures on Runtime Verification(pp. 1–33), Springer LNCS 10457
work page 2018
-
[55]
Åström, K. J., & Murray, R. M. (2008).Feedback Systems: An Introduction for Scientists and Engineers. Princeton University Press
work page 2008
-
[56]
UK AI Security Institute (2025).Frontier AI Trends Report. Published December 18, 2025. Available ataisi.gov.uk/frontier-ai-trends-report
work page 2025
-
[57]
Task-completion time horizons of frontier AI models
METR (2025). Task-completion time horizons of frontier AI models. Technical report. Available at metr.org/time-horizons
work page 2025
-
[58]
Technical report, November 2025
Anthropic (2025).Claude Opus 4.5 System Card. Technical report, November 2025
work page 2025
- [59]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.