Recognition: no theorem link
Accelerating Precise End-to-End Simulation: Latency-Sensitive Many-core System Modeling
Pith reviewed 2026-05-11 02:07 UTC · model grok-4.3
The pith
A simulation model for latency-sensitive many-core systems with scratchpad memory tracks RTL accuracy within 7% while running up to 115 times faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The authors present an end-to-end modeling approach for latency-sensitive many-core architectures that captures the timing behavior of SPM accesses across multiple interconnect scales by abstracting non-essential hardware details, achieving less than 7% error relative to cycle-accurate RTL simulation and up to 115x faster execution.
What carries the argument
The latency-sensitive system model that preserves timing for scratchpad memory accesses while abstracting other details.
If this is right
- Software developers can use detailed profiling to optimize data movement and synchronization in parallel workloads.
- Hardware designers can explore NoC configurations like router remapping to balance traffic and boost throughput.
- The approach supports iterative design of algorithms such as FlashAttention-2 to minimize interconnect stalls.
- Large-scale systems with 1024 cores and shared L1 SPM become feasible to simulate for end-to-end performance estimation.
Where Pith is reading between the lines
- Such models could shorten the design cycle for future many-core AI accelerators by allowing faster what-if analyses.
- The abstraction technique might extend to modeling other shared-memory many-core setups beyond the specific TeraNoC example.
- Integration with higher-level tools could enable automated optimization loops for both code and architecture.
Load-bearing premise
Abstracting non-essential hardware details does not significantly distort the timing behavior of latency-sensitive SPM accesses across multiple interconnect scales.
What would settle it
Comparing the model's predicted execution times and stall counts for a new set of benchmarks against actual RTL simulation on the same hardware configuration; discrepancies larger than 7% would indicate the abstraction fails to preserve necessary timing fidelity.
Figures



read the original abstract
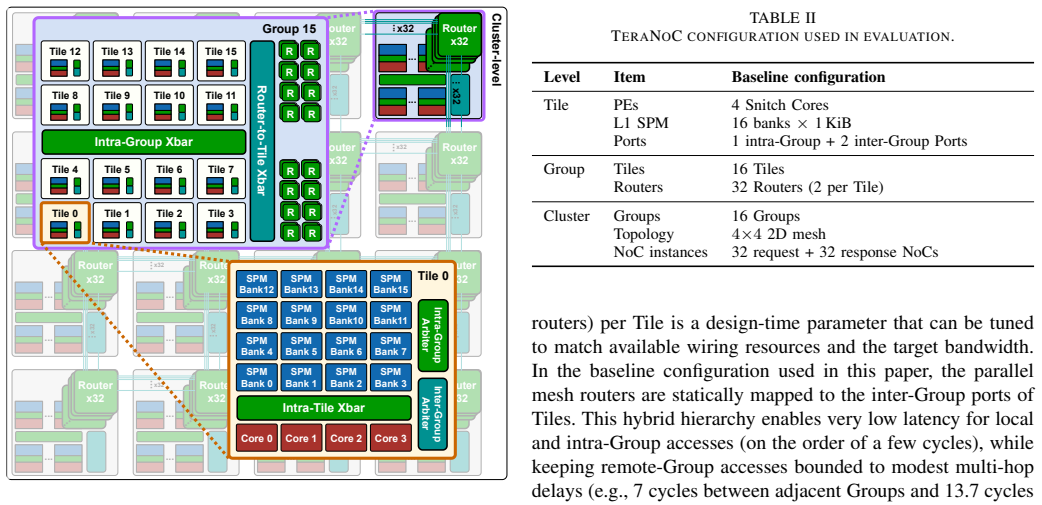
Modern large language model workloads put increasing demands on parallel compute capability and on-chip memory capacity, while also stressing fine-grained data movement and synchronization. These trends motivate exploring and designing many-core accelerators with tightly coupled scratchpad memory (SPM) for scalable compute and predictable, explicitly managed data access. However, this architectural shift raises two challenges: cycle-accurate register-transfer level (RTL) simulation becomes prohibitively slow as system complexity grows, and performance estimation requires precise modeling of latency-sensitive interconnect behavior. This paper presents a fast yet accurate end-to-end modeling approach for latency-sensitive many-core architectures, targeting large-scale instances such as TeraNoC with 1024 cores and a 4MiB globally shared L1 SPM. The approach captures timing behavior of latency-sensitive SPM accesses across multiple interconnect scales, while abstracting non-essential hardware details. Across diverse benchmarks, the model tracks a cycle-accurate RTL golden model with errors below 7%, while delivering up to 115x faster simulation. The framework also provides detailed profiling across processing elements and interconnect, enabling efficient end-to-end software development and hardware design exploration. Two case studies demonstrate its practicality: profiling-guided optimization of FlashAttention-2 to reduce interconnect stalls and synchronization overhead, and design space exploration of network-on-chip (NoC) router remapping to alleviate traffic imbalance and improve throughput.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper presents a fast yet accurate end-to-end modeling framework for latency-sensitive many-core architectures with tightly coupled scratchpad memory (SPM), targeting large instances such as TeraNoC (1024 cores, 4 MiB globally shared L1 SPM). It abstracts non-essential hardware details while capturing timing behavior of SPM accesses across interconnect scales, claims to track a cycle-accurate RTL golden model with errors below 7% on diverse benchmarks, and achieves up to 115x faster simulation. The framework includes detailed profiling across PEs and interconnects, with two case studies on FlashAttention-2 optimization (reducing stalls and synchronization) and NoC router remapping for traffic balance.
Significance. If the accuracy and speedup claims are substantiated with full methodological details and scale-appropriate validation, the work would be significant for computer architecture research on AI accelerators. It directly addresses the prohibitive cost of RTL simulation for complex many-core designs under LLM-driven demands for parallel compute and explicit data movement, enabling faster end-to-end software development and hardware exploration. Strengths include the focus on latency-sensitive SPM modeling without apparent free parameters and the practical case studies demonstrating utility beyond micro-benchmarks.
major comments (2)
- [Validation/results section (and model description)] The central accuracy claim (<7% error vs. RTL golden model) is load-bearing for the paper's contribution yet rests on validation whose details are not provided: the abstract and results summary omit model construction steps, exact abstraction rules for non-essential hardware, benchmark selection criteria, error distribution across access types or scales, and the core/interconnect sizes used in the RTL comparisons. Without these, it is impossible to assess whether per-access errors remain bounded when extrapolating to 1024 cores and multi-hop contention patterns that only appear at full TeraNoC scale.
- [Methodology and large-scale extrapolation discussion] The weakest assumption—that abstracting non-essential details preserves timing fidelity for latency-sensitive SPM accesses even as interconnect scale grows to 1024 cores and 4 MiB shared L1—is not directly tested. Because full RTL simulation of the target is infeasible, the manuscript must show that any modeling error does not accumulate through multi-hop traffic, contention, or synchronization; the current high-level description leaves this unverified and therefore undermines the reliability of both the error bound and the two case studies.
minor comments (2)
- [Abstract] Abstract: '4MiB' should be formatted as '4 MiB' and '115x' as '115×' for typographic consistency with the rest of the manuscript.
- [Results] The manuscript would benefit from an explicit table or figure summarizing the benchmark set, their core counts, and per-benchmark error statistics to make the 'diverse benchmarks' claim concrete.
Simulated Author's Rebuttal
We thank the referee for the careful reading and the detailed feedback on validation and extrapolation. We address each major comment below and will revise the manuscript to incorporate additional methodological details and discussion while preserving the core claims.
read point-by-point responses
-
Referee: The central accuracy claim (<7% error vs. RTL golden model) is load-bearing for the paper's contribution yet rests on validation whose details are not provided: the abstract and results summary omit model construction steps, exact abstraction rules for non-essential hardware, benchmark selection criteria, error distribution across access types or scales, and the core/interconnect sizes used in the RTL comparisons. Without these, it is impossible to assess whether per-access errors remain bounded when extrapolating to 1024 cores and multi-hop contention patterns that only appear at full TeraNoC scale.
Authors: We agree that the validation details are essential for assessing the claims. The current manuscript provides high-level descriptions of the modeling approach and aggregate error bounds but does not include the requested granular information. In the revised version we will add a dedicated subsection (likely in Section 4 or a new Appendix) that explicitly lists: (1) model construction steps, including how timing parameters for SPM accesses and interconnect hops were derived from RTL; (2) the exact abstraction rules applied to non-essential hardware components; (3) benchmark selection criteria and the full set of workloads used; (4) error distributions broken down by access type, hop count, and scale; and (5) the precise core counts and interconnect configurations used in the RTL comparisons (currently performed on smaller instances up to several hundred cores). These additions will allow readers to evaluate bounded per-access errors and the validity of extrapolation. revision: yes
-
Referee: The weakest assumption—that abstracting non-essential details preserves timing fidelity for latency-sensitive SPM accesses even as interconnect scale grows to 1024 cores and 4 MiB shared L1—is not directly tested. Because full RTL simulation of the target is infeasible, the manuscript must show that any modeling error does not accumulate through multi-hop traffic, contention, or synchronization; the current high-level description leaves this unverified and therefore undermines the reliability of both the error bound and the two case studies.
Authors: We acknowledge that direct RTL testing at the full 1024-core scale is impossible and that the manuscript currently offers only a high-level argument for fidelity preservation. We will strengthen the revised manuscript by adding a new subsection on large-scale extrapolation. This will include: (a) sensitivity analysis showing how modeling error behaves with increasing core count and hop distance on the validated smaller configurations; (b) explicit discussion of why per-hop latency modeling and contention tracking prevent unbounded accumulation (supported by the observed <7% aggregate error across scales); and (c) clarification that the two case studies operate at scales where RTL validation was performed. While we cannot provide full-scale RTL ground truth, the added analysis will make the extrapolation assumptions transparent and testable by readers. revision: partial
- Direct RTL simulation results at the full 1024-core / 4 MiB L1 SPM scale cannot be obtained due to prohibitive computational cost, as already stated in the manuscript.
Circularity Check
No circularity; model validated against independent RTL golden model
full rationale
The paper constructs an abstracted end-to-end simulator for latency-sensitive SPM accesses in many-core systems and directly compares its outputs to an external cycle-accurate RTL golden model on diverse benchmarks, reporting <7% error. No derivation step reduces by construction to a fitted parameter, self-citation, or renamed input; the timing model is built from hardware abstraction principles and measured against an independent reference rather than self-generated quantities. Self-citations, if present, are not load-bearing for the accuracy or speedup claims. The central result (115x speedup with bounded error) therefore rests on external validation rather than tautological reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. Li, J. Xu, S. Huang, Y . Chen, W. Li, J. Liu, Y . Lian, J. Pan, L. Ding, H. Zhou, Y . Wang, and G. Dai, “Large language model inference acceleration: A comprehensive hardware perspective,” 2025, arXiv:2410.04466
-
[2]
FlashAttention-2: Faster attention with better parallelism and work partitioning,
T. Dao, “FlashAttention-2: Faster attention with better parallelism and work partitioning,” inICLR, 2024
work page 2024
-
[3]
Efficient memory management for LLM serving with PagedAttention,
W. Kwon, Z. Li, S. Zhuang, Y . Sheng, L. Zheng, C. H. Yu, J. E. Gonzalez, H. Zhang, and I. Stoica, “Efficient memory management for LLM serving with PagedAttention,” inSOSP, 2023, pp. 611–626
work page 2023
-
[4]
MemPool: A shared-L1 memory many-core cluster with a low-latency interconnect,
M. Cavalcante, S. Riedel, A. Pullini, and L. Benini, “MemPool: A shared-L1 memory many-core cluster with a low-latency interconnect,” inDATE, 2021, pp. 701–706
work page 2021
-
[5]
LCM: LLM-focused hybrid SPM-cache architecture with cache management for multi-core AI accelerators,
C. Lai, Z. Zhou, A. Poptani, and W. Zhang, “LCM: LLM-focused hybrid SPM-cache architecture with cache management for multi-core AI accelerators,” inICS, 2024, pp. 62–73
work page 2024
-
[6]
Scalable, programmable and dense: The HammerBlade open-source RISC-V manycore,
D. C. Jung, M. Ruttenberg, P. Gao, S. Davidson, D. Petrisko, K. Li, A. K. Kamath, L. Cheng, S. Xie, P. Pan, Z. Zhao, Z. Yue, B. Veluri, S. Muralitharan, A. Sampson, A. Lumsdaine, Z. Zhang, C. Batten, M. Oskin, D. Richmond, and M. B. Taylor, “Scalable, programmable and dense: The HammerBlade open-source RISC-V manycore,” inISCA, 2024, pp. 770–784
work page 2024
-
[7]
L. Cheng, M. Ruttenberg, D. C. Jung, D. Richmond, M. Taylor, M. Oskin, and C. Batten, “Supporting dynamic task parallelism on manycore architectures with software-managed scratchpad memories,” inASPLOS, 2023, pp. 46–58
work page 2023
-
[8]
Manycore simulation for peta-scale system design: Motivation, tools, challenges and prospects,
J. Zarrin, R. L. Aguiar, and J. P. Barraca, “Manycore simulation for peta-scale system design: Motivation, tools, challenges and prospects,” Simul. Model. Pract. Theory, vol. 72, pp. 168–201, 2017
work page 2017
-
[9]
GVSoC: A highly configurable, fast and accurate full-platform simu- lator for RISC-V IoT processors,
N. Bruschi, G. Haugou, G. Tagliavini, F. Conti, L. Benini, and D. Rossi, “GVSoC: A highly configurable, fast and accurate full-platform simu- lator for RISC-V IoT processors,” inICCD, 2021, pp. 409–416
work page 2021
-
[10]
TeraNOC: A multi-channel 32-bit fine-grained, hybrid mesh-crossbar NoC for efficient scale-up,
Y . Zhang, Z. Fu, T. Fischer, Y . Li, M. Bertuletti, and L. Benini, “TeraNOC: A multi-channel 32-bit fine-grained, hybrid mesh-crossbar NoC for efficient scale-up,” inICCD, 2025, pp. 610–617
work page 2025
-
[11]
A survey of computer architecture simu- lation techniques and tools,
A. Akram and L. Sawalha, “A survey of computer architecture simu- lation techniques and tools,”IEEE Access, vol. 7, pp. 78 120–78 145, 2019
work page 2019
-
[12]
Comparative analysis of network-on-chip simulation tools,
S. Khan, S. Anjum, U. A. Gulzari, and F. S. Torres, “Comparative analysis of network-on-chip simulation tools,”IET Computers & Digital Techniques, vol. 12, pp. 30–38, 2018
work page 2018
-
[13]
FPGA-accelerated simulation technologies (FAST): Fast, full-system, cycle-accurate simulators,
D. Chiou, D. Sunwoo, J. Kim, N. A. Patil, W. Reinhart, D. E. Johnson, J. Keefe, and H. Angepat, “FPGA-accelerated simulation technologies (FAST): Fast, full-system, cycle-accurate simulators,” inMICRO, 2007, pp. 249–261
work page 2007
-
[14]
MRP: Mix real cores and pseudo cores for FPGA-based chip-multiprocessor simulation,
X. Chen, G. Zhang, H. Wang, R. Wu, P. Wu, and L. Zhang, “MRP: Mix real cores and pseudo cores for FPGA-based chip-multiprocessor simulation,” inDATE, 2015, pp. 211–216
work page 2015
-
[15]
QEMU, a fast and portable dynamic translator,
F. Bellard, “QEMU, a fast and portable dynamic translator,” inUSENIX ATC, 2005, p. 41
work page 2005
-
[16]
Banshee: A fast LLVM-based RISC-V binary translator,
S. Riedel, F. Schuiki, P. Scheffler, F. Zaruba, and L. Benini, “Banshee: A fast LLVM-based RISC-V binary translator,” inICCAD, 2021, pp. 1105–1113
work page 2021
-
[17]
GARNET: A detailed on-chip network model inside a full-system simulator,
N. Agarwal, T. Krishna, L.-S. Peh, and N. K. Jha, “GARNET: A detailed on-chip network model inside a full-system simulator,” inISPASS, 2009, pp. 33–42
work page 2009
-
[18]
A detailed and flexible cycle- accurate network-on-chip simulator,
N. Jiang, D. U. Becker, G. Michelogiannakis, J. Balfour, B. Towles, D. E. Shaw, J. Kim, and W. J. Dally, “A detailed and flexible cycle- accurate network-on-chip simulator,” inISPASS, 2013, pp. 86–96
work page 2013
-
[19]
Noxim: An open, extensible and cycle-accurate network on chip simulator,
V . Catania, A. Mineo, S. Monteleone, M. Palesi, and D. Patti, “Noxim: An open, extensible and cycle-accurate network on chip simulator,” in ASAP, 2015, pp. 162–163
work page 2015
-
[20]
Darsim: a parallel cycle-level noc simulator,
M. Lis, K. S. Shim, M. H. Cho, P. Ren, O. Khan, and S. Devadas, “Darsim: a parallel cycle-level noc simulator,” inMoBS, 2010
work page 2010
-
[21]
BZSim: Fast, large-scale microar- chitectural simulation with detailed interconnect modeling,
P. Strikos, A. Ejaz, and I. Sourdis, “BZSim: Fast, large-scale microar- chitectural simulation with detailed interconnect modeling,” inISPASS, 2024, pp. 167–178
work page 2024
-
[22]
ONNXim: A fast, cycle-level multi-core NPU simulator,
H. Ham, W. Yang, Y . Shin, O. Woo, G. Heo, S. Lee, J. Park, and G. Kim, “ONNXim: A fast, cycle-level multi-core NPU simulator,”IEEE Comput. Archit. Lett., vol. 23, pp. 219–222, 2024
work page 2024
-
[23]
A dynamic allocation scheme for adaptive shared-memory mapping on kilo-core RV clusters,
B. Wang, M. Bertuletti, Y . Zhang, V . J. Jung, and L. Benini, “A dynamic allocation scheme for adaptive shared-memory mapping on kilo-core RV clusters,” inASAP, 2025, pp. 9–16
work page 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.