Recognition: 2 theorem links
· Lean TheoremAPEX: Assumption-free Projection-based Embedding eXamination Metric for Image Quality Assessment
Pith reviewed 2026-05-12 03:13 UTC · model grok-4.3
The pith
APEX applies sliced Wasserstein distance to embeddings to create an assumption-free metric for image quality.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
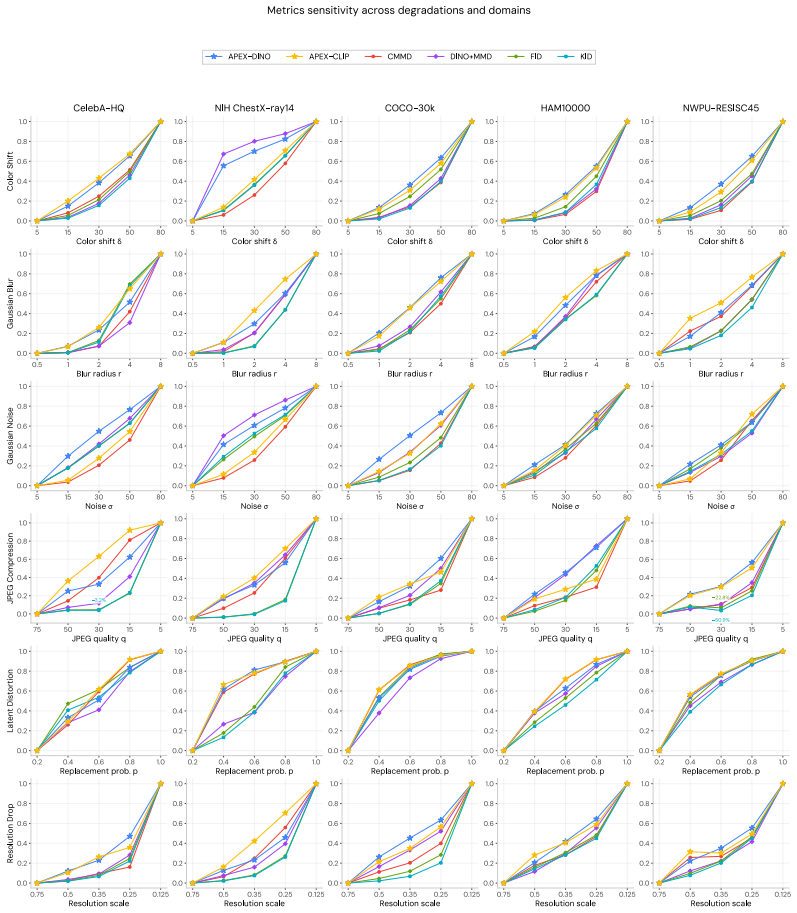
APEX is a novel evaluation framework that leverages the Sliced Wasserstein Distance as a mathematically grounded, assumption-free similarity measure between embeddings, inherits effective scalability to high-dimensional spaces, and uses open-vocabulary foundation models as feature extractors to achieve superior robustness to visual degradations along with high intra- and cross-dataset stability.
What carries the argument
Sliced Wasserstein Distance applied to projections of embeddings, functioning as an assumption-free similarity measure that replaces rigid parametric formulations.
If this is right
- APEX scales to high-dimensional spaces with supporting theoretical and empirical evidence.
- Benchmark comparisons show greater robustness to visual degradations than established baselines.
- The resulting scores remain stable within single datasets and across different datasets, including out-of-domain cases.
- Because the method is embedding-agnostic, the same distance computation can be paired with other feature extractors.
Where Pith is reading between the lines
- If the stability result holds, developers of generative models could rely on a single metric for consistent quality checks even when training data changes.
- The projection step could be reused to compare distributions in other perceptual tasks such as video or 3-D asset evaluation.
- A direct test would measure whether APEX rankings match human preference studies on newly generated image sets.
Load-bearing premise
The sliced Wasserstein distance remains free of hidden distributional assumptions once it is computed on the chosen embeddings.
What would settle it
If APEX scores fail to track human perceptual judgments more closely than FID on images that have undergone controlled degradations, or if they vary sharply on out-of-domain test sets, the central claim would not hold.
Figures







read the original abstract
As generative models achieve unprecedented visual quality, the gold standard for image evaluation remains traditional feature-distribution metrics (e.g., FID). However, these metrics are provably hindered by the closed-vocabulary bottleneck of outdated features and the assumptive bias of rigid parametric formulations. Recent alternatives exploit modern backbones to solve the feature bottleneck, yet continue to suffer from parametric limitations. To close this gap, we introduce APEX (Assumption-free Projection-based Embedding eXamination), a novel evaluation framework leveraging the Sliced Wasserstein Distance as a mathematically grounded, assumption-free similarity measure. APEX inherits effective scalability to high-dimensional spaces, as we prove with theoretical and empirical evidences. Moreover, APEX is embedding-agnostic and uses two open-vocabulary foundation models, CLIP and DINOv2, as feature extractors. Benchmarking APEX against established baselines reveals superior robustness to visual degradations. Additionally, we show that APEX metrics exhibit intra- and cross-dataset stability, ensuring highly stable evaluations on out-of-domain datasets.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces APEX, a novel image quality assessment metric that applies the Sliced Wasserstein Distance (SWD) to high-dimensional embeddings extracted from open-vocabulary foundation models (CLIP and DINOv2). It claims this framework is assumption-free and embedding-agnostic, provides theoretical and empirical proofs of scalability to high-dimensional spaces, and demonstrates superior robustness to visual degradations along with strong intra- and cross-dataset stability compared to parametric baselines such as FID.
Significance. If the central claims on assumption-freeness, scalability, and robustness hold under scrutiny, APEX could meaningfully improve evaluation practices for generative vision models by replacing rigid parametric assumptions and closed-vocabulary bottlenecks with a more general, stable distance measure. The explicit use of modern embeddings and the focus on out-of-domain stability are particularly relevant strengths.
major comments (3)
- [§4] §4 (Theoretical Analysis), the claimed proof of scalability and assumption-freeness for SWD: the derivation must explicitly bound the Monte Carlo projection error for finite samples in the high-dimensional regime of CLIP/DINOv2 embeddings (typically 512–1024 dims) and clarify whether any implicit regularity assumptions on the embedding distribution are required; without this, the contrast to 'parametric limitations' of FID-style metrics is not fully load-bearing.
- [§5.3] §5.3 (Robustness Experiments), the benchmarking tables: the reported superiority in robustness to degradations lacks statistical significance testing (e.g., paired t-tests or bootstrap confidence intervals across multiple runs) and does not include controls that isolate the contribution of SWD versus the specific inductive biases of the chosen CLIP and DINOv2 extractors; this leaves open the possibility that performance gains trace to feature-extractor properties rather than the projection-based distance.
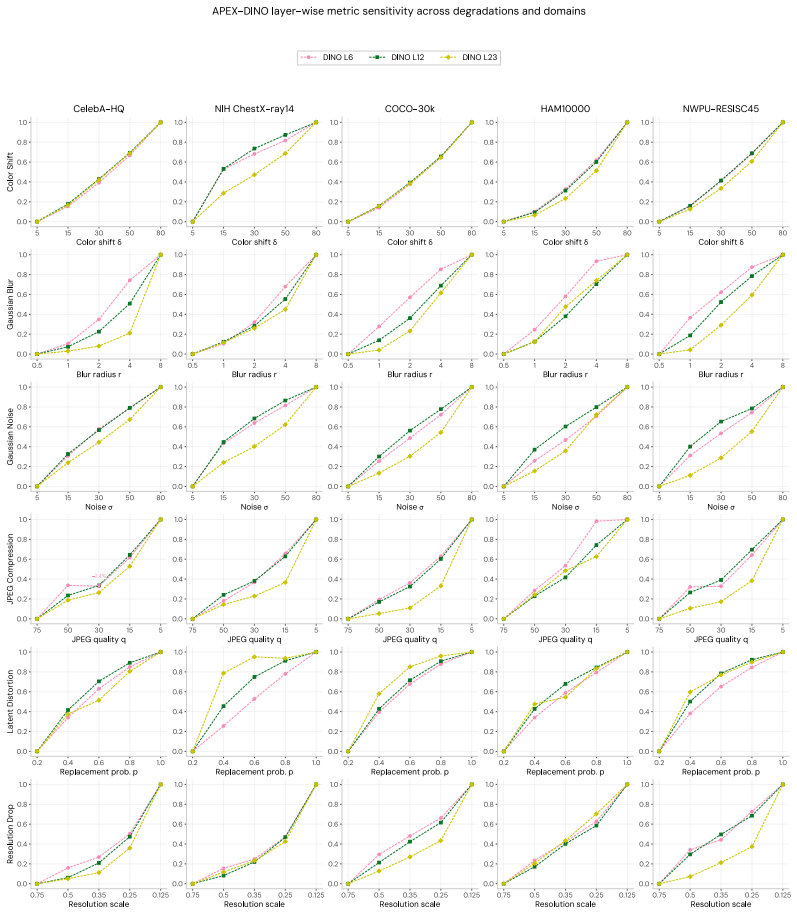
- [§5.4] §5.4 (Stability Analysis), the intra- and cross-dataset stability results: the evaluation should include an ablation replacing CLIP/DINOv2 with at least one additional embedding backbone (e.g., a supervised ResNet or another self-supervised model) to test the embedding-agnostic claim; otherwise the stability may not generalize beyond the training-induced biases of the two selected models.
minor comments (3)
- [§3] Notation for the sliced projections and the final APEX score should be unified across equations and text to avoid ambiguity in the definition of the expectation over random directions.
- [Abstract / §1] The abstract and introduction cite 'provably hindered' properties of FID without referencing the specific theorems (e.g., on Gaussian assumptions or sample complexity); adding these citations would strengthen the motivation.
- [Figures in §5] Figure captions for the robustness and stability plots should explicitly state the number of random seeds, the exact degradation parameters, and the dataset splits used.
Simulated Author's Rebuttal
We thank the referee for their constructive comments, which have helped us identify areas to strengthen our manuscript. We address each major comment point-by-point below, agreeing to incorporate revisions where appropriate to enhance the clarity and rigor of our claims regarding APEX.
read point-by-point responses
-
Referee: [§4] §4 (Theoretical Analysis), the claimed proof of scalability and assumption-freeness for SWD: the derivation must explicitly bound the Monte Carlo projection error for finite samples in the high-dimensional regime of CLIP/DINOv2 embeddings (typically 512–1024 dims) and clarify whether any implicit regularity assumptions on the embedding distribution are required; without this, the contrast to 'parametric limitations' of FID-style metrics is not fully load-bearing.
Authors: We appreciate this suggestion to make our theoretical analysis more complete. In the original manuscript, §4 provides theoretical and empirical evidence for the scalability of SWD to high dimensions, building on established results for the sliced Wasserstein distance. However, we agree that an explicit bound on the Monte Carlo projection error for finite numbers of projections in high-dimensional settings (512-1024 dims) would strengthen the section. In the revised version, we will derive such a bound using standard concentration inequalities (e.g., Hoeffding's inequality applied to the projections), under the mild assumption of bounded second moments of the embedding distributions, which holds for normalized CLIP and DINOv2 features. We will also explicitly state that no stronger parametric assumptions (such as Gaussianity) are required, in contrast to FID. This addition will be included in the updated §4, along with numerical verification of the bound's tightness. revision: yes
-
Referee: [§5.3] §5.3 (Robustness Experiments), the benchmarking tables: the reported superiority in robustness to degradations lacks statistical significance testing (e.g., paired t-tests or bootstrap confidence intervals across multiple runs) and does not include controls that isolate the contribution of SWD versus the specific inductive biases of the chosen CLIP and DINOv2 extractors; this leaves open the possibility that performance gains trace to feature-extractor properties rather than the projection-based distance.
Authors: We agree that adding statistical significance testing will improve the credibility of our empirical results. In the revision, we will augment the tables in §5.3 with bootstrap confidence intervals or paired t-tests computed over multiple independent runs of the experiments. To address the isolation of SWD's contribution, we will add control experiments where we replace the Sliced Wasserstein Distance with alternative metrics (such as mean Euclidean distance or cosine similarity) applied to the same CLIP and DINOv2 embeddings. This will allow us to demonstrate that the robustness advantages stem from the projection-based, assumption-free nature of SWD rather than solely from the choice of embeddings. These controls will be presented in the revised §5.3. revision: yes
-
Referee: [§5.4] §5.4 (Stability Analysis), the intra- and cross-dataset stability results: the evaluation should include an ablation replacing CLIP/DINOv2 with at least one additional embedding backbone (e.g., a supervised ResNet or another self-supervised model) to test the embedding-agnostic claim; otherwise the stability may not generalize beyond the training-induced biases of the two selected models.
Authors: We recognize the value of this ablation to more convincingly support our embedding-agnostic claim. Although APEX is formulated to work with any embedding extractor, our primary experiments focused on CLIP and DINOv2 due to their open-vocabulary and strong performance. In the revised manuscript, we will include an additional ablation in §5.4 using a supervised ResNet-50 backbone (pretrained on ImageNet) and report the intra- and cross-dataset stability metrics for comparison. This will provide direct evidence that the stability properties hold across different embedding types, including those with supervised training biases, thereby reinforcing the generality of the framework. revision: yes
Circularity Check
No circularity: derivation relies on independent SWD properties and external embeddings
full rationale
The paper defines APEX as a direct application of the established Sliced Wasserstein Distance to features from independent foundation models (CLIP, DINOv2). Scalability is claimed via separate theoretical and empirical arguments rather than by construction from the metric itself. Benchmarking and stability results are presented as external validations, not as inputs that are renamed or fitted into the core definition. No self-citations, ansatzes, or uniqueness theorems from the authors' prior work are invoked as load-bearing premises. The central claim therefore remains self-contained against external mathematical and empirical benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The Sliced Wasserstein Distance serves as a mathematically grounded, assumption-free similarity measure for high-dimensional embeddings.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
leveraging the Sliced Wasserstein Distance as a mathematically grounded, assumption-free similarity measure... Monte Carlo approximation... L ≥ 2D⁴/τ² [2k log(8CD²/τ) − log(δ/2)]
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
APEX is embedding-agnostic... CLIP and DINOv2... superior robustness... intra- and cross-dataset stability
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Tero Karras, Samuli Laine, and Timo Aila
URLhttps://openreview.net/forum?id=Hk99zCeAb. Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 4401–4410, 2019. M. G. Kendall. A new measure of rank correlation.Biometrika, 30(1-2):81–93, 06 1938. ISSN 0006-
work page 2019
-
[2]
Hierarchical Text-Conditional Image Generation with CLIP Latents
doi: 10.1093/biomet/30.1-2.81. URL https://doi.org/10.1093/biomet/30.1-2.81. Hyeok Kyu Kwon, Jaeseung Yang, and Minwoo Chae. Evaluating image generation models via sliced wasserstein distance.Journal of the Korean Statistical Society, pages 1–21, 2026. Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Dollár, and ...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1093/biomet/30.1-2.81 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.