Recognition: 2 theorem links
· Lean TheoremNeural Operators as Efficient Function Interpolators
Pith reviewed 2026-05-11 03:24 UTC · model grok-4.3
The pith
Neural operators can interpolate finite-dimensional functions efficiently by reframing them as operators on an auxiliary base-space.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
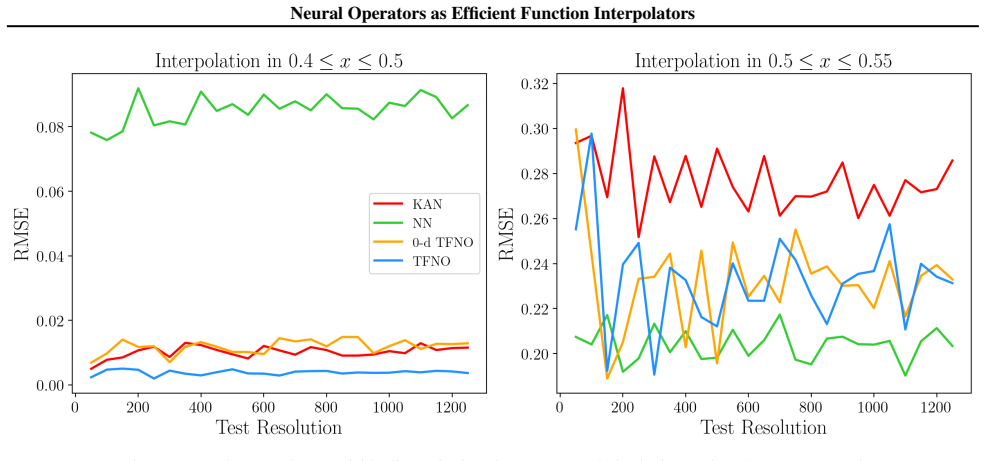
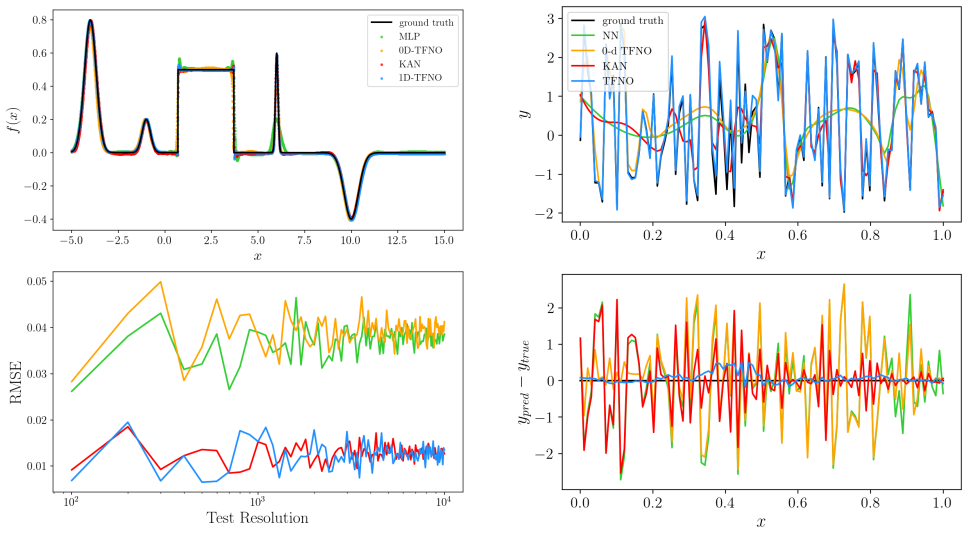
By introducing an auxiliary base-space, any finite-dimensional function can be viewed as an operator acting by composition on functions of the base-space. Benchmarks demonstrate that neural operators can match or outperform standard multilayer perceptrons and Kolmogorov-Arnold Networks in accuracy while requiring significantly fewer parameters and training time. For the nuclear chart, a two-dimensional Tensorized Fourier Neural Operator ensemble reaches a held-out root-mean-square error of 198.2 keV while retaining high parameter efficiency and short training times.
What carries the argument
The auxiliary base-space reframing, which converts any finite-dimensional interpolation problem into an operator-learning task via composition on base-space functions.
If this is right
- Neural operators become applicable to finite-dimensional interpolation with competitive accuracy across increasing function complexity and dimensionality.
- Parameter counts and training times drop substantially relative to multilayer perceptrons and Kolmogorov-Arnold networks on the same tasks.
- Structured scientific data such as nuclear mass residuals can be treated as partially observed fields and corrected efficiently by tensorized Fourier neural operators.
- The reframing supplies a scalable route from analytic test functions to real-world interpolation problems without architecture redesign.
Where Pith is reading between the lines
- The same base-space construction could be applied to other operator-learning families to test whether parameter efficiency transfers beyond the Fourier neural operator family.
- If the efficiency holds on non-analytic or noisy data, the method might reduce the cost of ensemble modeling in physics domains where many similar functions must be approximated repeatedly.
- Direct comparisons on image or time-series regression tasks could reveal whether the operator view offers advantages over standard networks when input dimensionality grows.
Load-bearing premise
That the auxiliary base-space reframing preserves the approximation power of neural operators without introducing representation-specific biases or requiring problem-dependent tuning that would erase the efficiency gains.
What would settle it
A controlled benchmark on high-dimensional analytic functions in which a standard multilayer perceptron reaches the same accuracy as the reframed neural operator but with equal or lower parameter count and training time.
Figures






read the original abstract
Neural operators (NOs) are designed to learn maps between infinite-dimensional function spaces. We propose a novel reframing of their use. By introducing an auxiliary base-space, any finite-dimensional function can be viewed as an operator acting by composition on functions of the base-space. Through a range of benchmarks on analytic functions of increasing complexity and dimensionality, we demonstrate that NOs can match or outperform standard multilayer perceptrons and Kolmogorov--Arnold Networks in accuracy while requiring significantly fewer parameters and training time. As a real-world application, we apply a two-dimensional Tensorized Fourier Neural Operator (TFNO) to the nuclear chart, learning a correction to state-of-the-art nuclear mass models as a partially observed residual field. A TFNO ensemble reaches a held-out root-mean-square error of 198.2 keV, placing it among the best recent neural-network approaches while retaining high parameter efficiency and short training times. More broadly, these results introduce NOs as a scalable framework for finite-dimensional function interpolation, from analytic benchmarks to structured scientific data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes reframing finite-dimensional function interpolation as operator learning by composing with an auxiliary base-space, allowing neural operators (e.g., TFNO) to be applied to any finite-dimensional target. Benchmarks on analytic functions of increasing complexity and dimensionality claim that NOs match or exceed MLPs and KANs in accuracy while using significantly fewer parameters and less training time; a real-world application to learning residual corrections on the nuclear chart yields a held-out RMSE of 198.2 keV with a TFNO ensemble.
Significance. If the efficiency claims hold without hidden per-problem tuning, the work offers a scalable operator-based perspective on function approximation that could benefit structured scientific data tasks. The nuclear mass application shows competitive accuracy with high parameter efficiency, but broader significance depends on demonstrating that the auxiliary base-space construction preserves approximation power uniformly across function classes without representation-specific biases.
major comments (2)
- [§3] §3 (auxiliary base-space construction): the reframing requires specifying how the base-space dimension, discretization grid, and function encoding are selected. If these choices must be adjusted with increasing target dimensionality or complexity to maintain the reported accuracies, the parameter counts become incomparable to the direct finite-dimensional inputs used by the MLP/KAN baselines, undermining the central 'significantly fewer parameters' claim.
- [§4] §4 (analytic benchmarks): the performance tables and timing results are load-bearing for the efficiency conclusion, yet the manuscript provides no error bars, number of independent runs, or ablation on base-space hyperparameters. Without these, it is impossible to determine whether the reported outperformance is robust or sensitive to post-hoc discretization choices.
minor comments (2)
- [Abstract and §4.1] The abstract and §4.1 would benefit from an explicit list of the analytic test functions, their dimensions, and the exact base-space grids employed, to allow readers to reproduce the complexity scaling.
- [§2-3] Notation for the operator composition and base-space embedding (likely Eq. (2) or (3)) should be clarified with a small diagram or pseudocode to distinguish the auxiliary space from the target function domain.
Simulated Author's Rebuttal
We thank the referee for their constructive comments. We address each major point below and have revised the manuscript to improve clarity, reproducibility, and robustness of the reported results.
read point-by-point responses
-
Referee: [§3] §3 (auxiliary base-space construction): the reframing requires specifying how the base-space dimension, discretization grid, and function encoding are selected. If these choices must be adjusted with increasing target dimensionality or complexity to maintain the reported accuracies, the parameter counts become incomparable to the direct finite-dimensional inputs used by the MLP/KAN baselines, undermining the central 'significantly fewer parameters' claim.
Authors: We agree that explicit specification is essential. In the revised manuscript we have added a new subsection in §3 titled 'Auxiliary Base-Space Construction and Hyperparameter Selection' that states the following fixed rules: base-space dimension is set to 1 for univariate targets and 2 for all multivariate targets (independent of target dimensionality d); the discretization grid is a uniform Cartesian grid whose resolution (32–64 points per axis) is chosen once via a separate convergence study on a representative low-dimensional case and then held constant; function encoding is always pointwise evaluation on this grid followed by composition. We further include a supplementary ablation across d = 1…10 and increasing function complexity showing that these fixed rules suffice to recover the reported accuracies without per-problem retuning. Because the neural operator itself always operates on the same low-dimensional base-space, its parameter count remains independent of d, in contrast to the MLP and KAN baselines whose parameter counts grow with d. The efficiency comparison is therefore preserved. revision: yes
-
Referee: [§4] §4 (analytic benchmarks): the performance tables and timing results are load-bearing for the efficiency conclusion, yet the manuscript provides no error bars, number of independent runs, or ablation on base-space hyperparameters. Without these, it is impossible to determine whether the reported outperformance is robust or sensitive to post-hoc discretization choices.
Authors: We accept this criticism. All analytic benchmarks have been rerun with 10 independent random seeds; the revised tables now report mean ± one standard deviation. A new supplementary section provides a systematic ablation on base-space hyperparameters (dimension, grid resolution, and encoding scheme) across the same function suite, demonstrating that the observed accuracy and parameter-efficiency advantages remain stable for any reasonable choice within the ranges we recommend. Training-time statistics now also include run-to-run variability. These additions establish that the efficiency claims are robust rather than artifacts of post-hoc discretization. revision: yes
Circularity Check
No significant circularity; claims rest on independent empirical benchmarks
full rationale
The paper proposes an auxiliary base-space reframing to treat finite-dimensional functions as operators and then reports direct empirical results: held-out accuracy, parameter counts, and training times on analytic function benchmarks of increasing complexity plus a nuclear mass correction task. These performance numbers are measured quantities, not quantities derived from the reframing by algebraic reduction or by fitting a parameter that is then renamed as a prediction. No equations or sections reduce the reported efficiency gains to the choice of base-space discretization by construction, and no load-bearing premise is justified solely by self-citation. The work therefore remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Any finite-dimensional function can be viewed as an operator acting by composition on functions of an auxiliary base-space.
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
By introducing an auxiliary base-space, any finite-dimensional function can be viewed as an operator acting by composition on functions of the base-space.
-
IndisputableMonolith/Foundation/AlphaDerivationExplicit.leanalphaProvenanceCert unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
A TFNO ensemble reaches a held-out root-mean-square error of 198.2 keV
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
International Conference on Learning Representations , year=
Fourier Neural Operator for Parametric Partial Differential Equations , author=. International Conference on Learning Representations , year=
-
[2]
Learning nonlinear operators via
Lu, Lu and Jin, Pengzhan and Pang, Guofei and Zhang, Zhongqiang and Karniadakis, George Em , journal =. Learning nonlinear operators via
-
[3]
Nikola Kovachki and Zongyi Li and Burigede Liu and Kamyar Azizzadenesheli and Kaushik Bhattacharya and Andrew Stuart and Anima Anandkumar , title =. JMLR , volume =
-
[4]
Multi-Grid Tensorized Fourier Neural Operator for High- Resolution
Jean Kossaifi and Nikola Borislavov Kovachki and Kamyar Azizzadenesheli and Anima Anandkumar , journal=. Multi-Grid Tensorized Fourier Neural Operator for High- Resolution. 2024 , url=
work page 2024
-
[5]
Jean Kossaifi and Nikola Kovachki and Zongyi Li and David Pitt and Miguel Liu-Schiaffini and Robert Joseph George and Boris Bonev and Kamyar Azizzadenesheli and Julius Berner and Valentin Duruisseaux and Anima Anandkumar , title =. arXiv preprint arXiv:2412.10354 , year =
-
[6]
Mathematics of Control, Signals and Systems , volume =
Approximation by superpositions of a sigmoidal function , author =. Mathematics of Control, Signals and Systems , volume =
-
[7]
Approximation capabilities of multilayer feedforward networks , author =. Neural Networks , volume =
-
[8]
Hou and Max Tegmark , booktitle=
Ziming Liu and Yixuan Wang and Sachin Vaidya and Fabian Ruehle and James Halverson and Marin Soljacic and Thomas Y. Hou and Max Tegmark , booktitle=. 2025 , url=
work page 2025
-
[9]
Surface diffuseness correction in global mass formula , author =. Physics Letters B , volume =
-
[10]
Wang, Meng and Huang, W. J. and Kondev, F. G. and Audi, G. and Naimi, S. , journal =. The
-
[11]
Niu, Z. M. and Liang, H. Z. , journal =. Nuclear mass predictions based on
-
[12]
Nuclear mass predictions with machine learning reaching the accuracy required by r -process studies , author =. Physical Review C , volume =
-
[13]
Nuclear Science and Techniques , volume =
Machine learning the nuclear mass , author =. Nuclear Science and Techniques , volume =. 2021 , doi =
work page 2021
-
[14]
Nuclear mass predictions with multi-hidden-layer feedforward neural network , author =. Nuclear Physics A , volume =. 2023 , doi =
work page 2023
-
[15]
Nuclear mass predictions based on convolutional neural network , author =. Physical Review C , volume =. 2025 , doi =
work page 2025
-
[16]
arXiv preprint arXiv:2501.01352 , year =
Validation and extrapolation of atomic mass with physics-informed fully connected neural network , author =. arXiv preprint arXiv:2501.01352 , year =
-
[17]
High precision binding energies from physics-informed machine learning , author =. Physical Review C , volume =. 2025 , doi =
work page 2025
-
[18]
Further exploration of binding energy residuals using machine learning and the development of a composite ensemble model , author =. Physical Review C , volume =. 2025 , doi =
work page 2025
-
[19]
Multi-task learning on nuclear masses and separation energies with the kernel ridge regression , author =. Physics Letters B , volume =. 2022 , doi =
work page 2022
-
[20]
Nuclear mass predictions with anisotropic kernel ridge regression , author =. Physical Review C , volume =
-
[21]
Kitouni, Ouail and Nolte, Niklas and Trifinopoulos, Sokratis and Kantamneni, Subhash and Williams, Mike , booktitle =
-
[22]
and Trifinopoulos, Sokratis and Williams, Mike , journal =
Richardson, Kate A. and Trifinopoulos, Sokratis and Williams, Mike , journal =. The
-
[23]
arXiv preprint arXiv:2508.21771 , year =
Conflation of Ensemble-Learned Nuclear Mass Models for Enhanced Precision , author =. arXiv preprint arXiv:2508.21771 , year =
-
[24]
Proceedings of the 41st International Conference on Machine Learning (ICML) , series =
From Neurons to Neutrons: A Case Study in Interpretability , author =. Proceedings of the 41st International Conference on Machine Learning (ICML) , series =
- [25]
-
[26]
Nuclear ground-state masses and deformations:
M. Nuclear ground-state masses and deformations:. Atomic Data and Nuclear Data Tables , volume =
-
[27]
Goriely, S. and Chamel, N. and Pearson, J. M. , journal =. Further explorations of
-
[28]
Microscopic mass formulas , author =. Physical Review C , volume =
- [29]
-
[30]
Progress in Particle and Nuclear Physics , volume =
The impact of individual nuclear properties on r -process nucleosynthesis , author =. Progress in Particle and Nuclear Physics , volume =
-
[31]
Reviews of Modern Physics , volume =
Synthesis of the elements in stars , author =. Reviews of Modern Physics , volume =
-
[32]
Physical Review Letters , volume =
Uncertainties in nuclear physics input data for r -process calculations , author =. Physical Review Letters , volume =
-
[33]
Nature Communications , volume =
Unifying machine learning and interpolation theory via interpolating neural networks , author =. Nature Communications , volume =. 2025 , doi =. 2404.10296 , archivePrefix =
-
[34]
Politis and Gino Domel and Wing Kam Liu , booktitle=
Jiachen Guo and Xiaoyu Xie and Chanwook Park and Hantao Zhang and Matthew J. Politis and Gino Domel and Wing Kam Liu , booktitle=. Interpolating Neural Network-Tensor Decomposition (. 2025 , url=
work page 2025
-
[35]
Foundations of Data Science , volume =
An operator learning perspective on parameter-to-observable maps , author =. Foundations of Data Science , volume =. 2025 , doi =
work page 2025
-
[36]
Tensorization is a powerful but underexplored tool for compression and interpretability of neural networks , author=. 2025 , eprint=
work page 2025
-
[37]
Kolmogorov-Arnold Networks are Radial Basis Function Networks , author=. 2024 , eprint=
work page 2024
-
[38]
Huang, W. J. and Wang, Meng and Kondev, F. G. and Audi, G. and Naimi, S. The AME 2020 atomic mass evaluation (I). Evaluation of input data, and adjustment procedures. Chin. Phys. C. 2021. doi:10.1088/1674-1137/abddb0
-
[39]
Physical Review Letters , volume =
New nuclidic mass relationship , author =. Physical Review Letters , volume =. 1966 , doi =
work page 1966
-
[40]
Mathematics of Control, Signals and Systems , volume =
Approximation by superpositions of a sigmoidal function , author =. Mathematics of Control, Signals and Systems , volume =. 1989 , doi =
work page 1989
-
[41]
Approximation capabilities of multilayer feedforward networks , author =. Neural Networks , volume =. 1991 , doi =
work page 1991
-
[42]
Impact of Nuclear Mass Uncertainties on the r Process , author =. Phys. Rev. Lett. , volume =. 2016 , month =. doi:10.1103/PhysRevLett.116.121101 , url =
-
[43]
Nuclear Science and Techniques , year=
Gao, Zepeng and Wang, Yongjia and Lü, Hongliang , title=. Nuclear Science and Techniques , year=. doi:10.1007/s41365-021-00958-z , url=
-
[44]
Goriely, S. and Chamel, N. and Pearson, J. M. Further explorations of Skyrme-Hartree-Fock-Bogoliubov mass formulas. 13. The 2012 atomic mass evaluation and the symmetry coefficient. Phys. Rev. C. 2013. doi:10.1103/PhysRevC.88.024308
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.