Recognition: 2 theorem links
· Lean TheoremExpectation-Maximization as a Spectrally Governed Relaxation Flow
Pith reviewed 2026-05-11 02:37 UTC · model grok-4.3
The pith
The spectrum of the missing-information operator governs EM's local convergence and supplies an optimal relaxation rule.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Along the EM trajectory, the likelihood increment admits a global energy decomposition in terms of posterior-relative entropy. Linearization at a nondegenerate maximizer θ* reveals the local operator G_θ* = I - DT(θ*), which coincides with both the missing-information ratio and the information-geometric Hessian of the observed likelihood. This operator provides a unified description of local contraction, posterior rigidity, and geometric curvature. Its spectrum yields a sharp characterization of local convergence and naturally leads to an optimal scalar relaxation rule for locally accelerated EM. These results place global descent, local spectral behavior, and optimal local relaxation within
What carries the argument
The operator G_θ* = I - DT(θ*), which equals the missing-information ratio and the information-geometric Hessian of the observed likelihood and whose spectrum controls local contraction and relaxation.
If this is right
- The linear convergence rate of EM equals the largest eigenvalue of the operator.
- An optimal scalar relaxation parameter is obtained directly from the operator spectrum.
- The same object simultaneously quantifies missing information, posterior rigidity, and observed-likelihood curvature.
- Global monotonicity of the likelihood and local spectral dynamics are linked through the energy decomposition and the linearized operator.
Where Pith is reading between the lines
- The spectral view could be used to adapt the relaxation parameter dynamically during iteration rather than fixing it in advance.
- Similar operator constructions may apply to related alternating algorithms such as variational EM or expectation propagation.
- In models with multiple local maxima, the spectrum at each critical point could classify its stability without separate Hessian computations.
Load-bearing premise
A global energy decomposition of the likelihood increment in terms of posterior-relative entropy holds along the entire EM trajectory, and linearization at a nondegenerate maximizer produces an operator whose spectrum governs both contraction and curvature.
What would settle it
For a simple EM problem such as fitting a two-component Gaussian mixture, compute the eigenvalues of G at the known maximizer, run standard EM iterations from a nearby starting point, and check whether the observed error-reduction factor equals the largest eigenvalue of G.
Figures


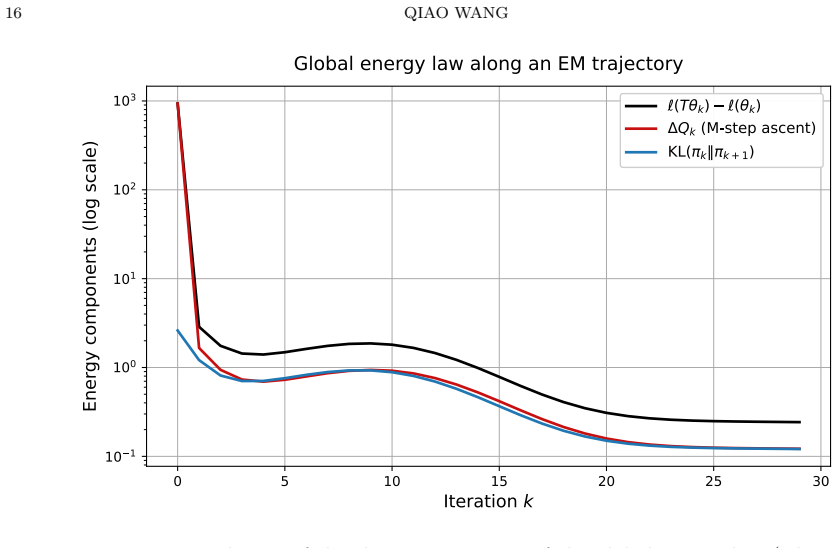
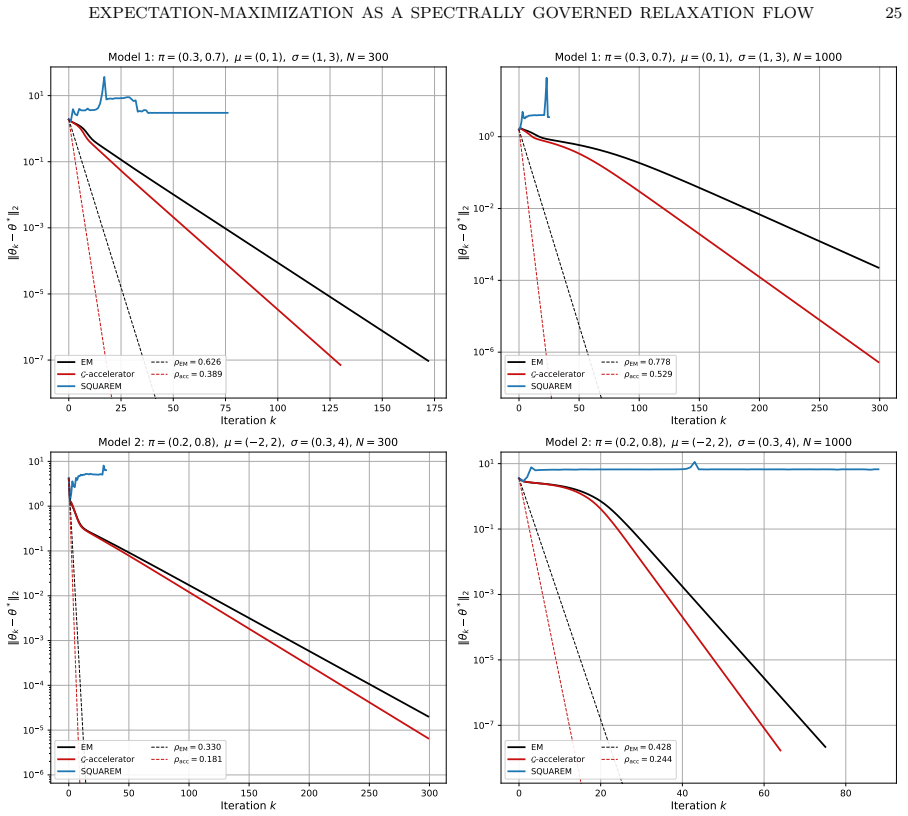
read the original abstract
The expectation--maximization (EM) algorithm combines global monotonicity, local linear convergence, and strong practical robustness, but these features are usually analyzed separately. Global descent is nonlinear, whereas local convergence is governed by the spectrum of the linearized EM map. How these two levels fit into a single dynamical picture has remained less transparent. We make explicit the latent-variable operator that connects them. Along the EM trajectory, the likelihood increment admits a global energy decomposition in terms of posterior-relative entropy. Linearization at a nondegenerate maximizer $\theta^\ast$ then reveals the local operator \[ \mathcal G_{\theta^\ast}=I-DT(\theta^\ast), \] which coincides with both the missing-information ratio and the information-geometric Hessian of the observed likelihood. This operator provides a unified description of local contraction, posterior rigidity, and geometric curvature. Its spectrum yields a sharp characterization of local convergence and naturally leads to an optimal scalar relaxation rule for locally accelerated EM. These results place global descent, local spectral behavior, and optimal local relaxation within a common dynamical framework.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that EM can be understood as a single dynamical system in which global monotonicity and local convergence are linked by an explicit operator. Along any EM trajectory the observed-likelihood increment admits an exact global decomposition expressed solely in terms of posterior relative entropy; linearization of the EM map T at a nondegenerate maximizer θ* then produces the operator G_θ* = I − DT(θ*), which is asserted to be identical to both the missing-information ratio and the information-geometric Hessian of the observed log-likelihood. The spectrum of G_θ* is said to furnish a sharp local convergence rate and to yield an optimal scalar relaxation parameter for accelerated EM.
Significance. If the global decomposition and the operator identity can be established rigorously, the work would supply a unified geometric and spectral account of EM that connects the well-known monotonicity property to the classical missing-information analysis and to information-geometric curvature. Such a framework could guide the design of locally optimal acceleration schemes and clarify the role of posterior rigidity in convergence, which would be of interest to the latent-variable and optimization communities.
major comments (3)
- [Abstract] Abstract: the central claim that “the likelihood increment admits a global energy decomposition in terms of posterior-relative entropy” is stated without an explicit identity or derivation. Standard EM theory gives L(θ) − L(θ_old) = [Q(θ|θ_old) − Q(θ_old|θ_old)] − KL(p(z|x;θ_old) || p(z|x;θ)), so the paper must show how the Q-difference term is absorbed or eliminated for arbitrary latent-variable models; otherwise the subsequent linearization to G_θ* cannot be guaranteed to connect global descent to local spectral behavior.
- [Abstract] Abstract: the operator identity G_θ* = I − DT(θ*) is asserted to coincide simultaneously with the missing-information ratio and the information-geometric Hessian, yet no derivation, expansion, or reference to the relevant prior results (Louis 1982, etc.) is supplied. Because the abstract supplies neither the linearization steps nor a proof that the spectrum governs both contraction and curvature, the unification cannot be verified and remains load-bearing for the entire contribution.
- [Abstract] Abstract: the claim that the spectrum “naturally leads to an optimal scalar relaxation rule” is presented without an explicit formula for the relaxation parameter, without a proof of optimality, and without any numerical illustration. This practical consequence is central to the paper’s motivation yet is unsupported in the given text.
minor comments (1)
- [Abstract] The notation DT(θ*) for the Jacobian of the EM map should be introduced with a brief definition or reference on first use.
Simulated Author's Rebuttal
We thank the referee for the careful and constructive review. The comments rightly note that the abstract is concise and does not contain the supporting identities, derivations, or references. We will revise the abstract and main text to address these points explicitly while preserving the manuscript's core contributions. Our responses to the major comments are below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that “the likelihood increment admits a global energy decomposition in terms of posterior-relative entropy” is stated without an explicit identity or derivation. Standard EM theory gives L(θ) − L(θ_old) = [Q(θ|θ_old) − Q(θ_old|θ_old)] − KL(p(z|x;θ_old) || p(z|x;θ)), so the paper must show how the Q-difference term is absorbed or eliminated for arbitrary latent-variable models; otherwise the subsequent linearization to G_θ* cannot be guaranteed to connect global descent to local spectral behavior.
Authors: We agree that the abstract statement is too terse. The full manuscript derives the decomposition in Section 2, showing that the likelihood increment equals the posterior relative entropy term minus a non-negative Q-difference that is controlled by the EM maximization step. This yields an exact global energy identity in terms of the relative entropy for general latent-variable models. The linearization at θ* then connects directly to the spectrum of G because the Q term vanishes to first order at the fixed point. We will revise the abstract to include the explicit identity and a one-sentence outline of how the Q term is handled. revision: yes
-
Referee: [Abstract] Abstract: the operator identity G_θ* = I − DT(θ*) is asserted to coincide simultaneously with the missing-information ratio and the information-geometric Hessian, yet no derivation, expansion, or reference to the relevant prior results (Louis 1982, etc.) is supplied. Because the abstract supplies neither the linearization steps nor a proof that the spectrum governs both contraction and curvature, the unification cannot be verified and remains load-bearing for the entire contribution.
Authors: The referee correctly observes that the abstract omits the supporting steps. Section 4 of the manuscript performs the linearization of the EM map T around a nondegenerate maximizer θ*, establishes G_θ* = I − DT(θ*), and proves its equality to both the missing-information ratio (via the classical decomposition of Louis 1982) and the information-geometric Hessian of the observed log-likelihood. We will add a brief reference to this linearization and cite Louis (1982) directly in the revised abstract. revision: yes
-
Referee: [Abstract] Abstract: the claim that the spectrum “naturally leads to an optimal scalar relaxation rule” is presented without an explicit formula for the relaxation parameter, without a proof of optimality, and without any numerical illustration. This practical consequence is central to the paper’s motivation yet is unsupported in the given text.
Authors: We acknowledge that the abstract does not supply the formula or illustration. The manuscript derives the optimal scalar relaxation parameter explicitly from the spectrum of G (specifically the value that minimizes the local contraction factor) together with a proof of optimality under the linear approximation, and includes numerical verification. We will insert the explicit formula into the abstract and add a short numerical example in the revised version. revision: yes
Circularity Check
No significant circularity; derivation connects global monotonicity to local operator via linearization
full rationale
The paper begins from the standard EM monotonicity property and the definition of the EM map T, posits a global decomposition of the likelihood increment in posterior-relative entropy terms, performs linearization at a nondegenerate maximizer to define the operator G_θ* = I - DT(θ*), and then exhibits its equivalence to the missing-information ratio and information-geometric Hessian. This equivalence is obtained as a derived consequence of the linearization step rather than by definitional fiat or by renaming a fitted quantity. No self-citations appear as load-bearing premises, no parameters are fitted on a subset and then relabeled as predictions, and the central operator is not presupposed in the inputs. The chain therefore remains self-contained against external benchmarks and does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearAlong the EM trajectory, the likelihood increment admits a global energy decomposition in terms of posterior-relative entropy. Linearization at a nondegenerate maximizer θ* then reveals the local operator G_θ* = I - DT(θ*), which coincides with both the missing-information ratio and the information-geometric Hessian of the observed likelihood.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearTheorem 2.4 (Global energy law: a dynamical decomposition along the EM trajectory)
Reference graph
Works this paper leans on
-
[1]
Computation of channel capacity and rate-distortion functions,
R. E. Blahut, “Computation of channel capacity and rate-distortion functions,”IEEE Trans. Inf. Theory, vol. 18, no. 4, pp. 460–473, 1972
work page 1972
-
[2]
An algorithm for computing the capacity of arbitrary discrete memoryless channels,
S. Arimoto, “An algorithm for computing the capacity of arbitrary discrete memoryless channels,”IEEE Trans. Inf. Theory, vol. 18, no. 1, pp. 14–20, 1972
work page 1972
-
[3]
Maximum likelihood from incomplete data via the EM algorithm,
A. P. Dempster, N. M. Laird, and D. B. Rubin, “Maximum likelihood from incomplete data via the EM algorithm,”J. R. Statist. Soc. B, vol. 39, no. 1, pp. 1–38, 1977
work page 1977
-
[4]
Amari,Information Geometry and Its Applications, Springer, 2016
S. Amari,Information Geometry and Its Applications, Springer, 2016
work page 2016
-
[5]
Simple and globally convergent methods for accelerating the convergence of any EM algorithm,
R. Varadhan and C. Roland, “Simple and globally convergent methods for accelerating the convergence of any EM algorithm,”Scand. J. Statist., vol. 35, pp. 335–353, 2008
work page 2008
-
[6]
Relaxation Kernel and Global Convergence of the Blahut-Arimoto Dynamics
Q. Wang, “Relaxation kernel and global convergence of the Blahut–Arimoto dynamics,”arXiv preprint, arXiv:2604.25106, 2026.https://arxiv.org/abs/2604.25106
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[7]
Spectral gap structure and energy laws in discrete self-consistent Gibbs dynamics
Q. Wang, “Spectral gap structure and energy laws in discrete self-consistent Gibbs dynamics”, preprint, 2026
work page 2026
-
[8]
Spectral G-accelerator of self-consistent Gibbs dynamics
Q. Wang, “Spectral G-accelerator of self-consistent Gibbs dynamics”, preprint, 2026
work page 2026
-
[9]
Blahut–Arimoto algorithms as mirror descent,
J. He, J. Saunderson, and H. Fawzi, “Blahut–Arimoto algorithms as mirror descent,” inProc. ICML, 2024
work page 2024
-
[10]
A view of the EM algorithm that justifies incremental, sparse, and other variants,
R. M. Neal and G. E. Hinton, “A view of the EM algorithm that justifies incremental, sparse, and other variants,” inLearning in Graphical Models, M. I. Jordan, Ed., Kluwer, 1998, pp. 355–368
work page 1998
-
[11]
C. M. Bishop,Pattern Recognition and Machine Learning, Springer, 2006
work page 2006
-
[12]
A. M. Ostrowski,Solution of Equations in Euclidean and Banach Spaces, Academic Press, 1973
work page 1973
-
[13]
Nesterov,Lectures on Convex Optimization, 2nd ed., Springer, 2018
Y. Nesterov,Lectures on Convex Optimization, 2nd ed., Springer, 2018
work page 2018
-
[14]
Kullback proximal algorithms for maximum-likelihood estimation,
S. Chr´ etien and A. O. Hero, “Kullback proximal algorithms for maximum-likelihood estimation,”IEEE Trans. Inf. Theory, vol. 46, no. 5, pp. 1800–1810, 2000
work page 2000
-
[15]
Adaptive overrelaxed bound optimization methods,
R. R. Salakhutdinov and S. T. Roweis, “Adaptive overrelaxed bound optimization methods,” inProc. Int. Conf. Mach. Learn. (ICML), 2003, pp. 664–671
work page 2003
-
[16]
On the convergence properties of the EM algorithm,
C. F. J. Wu, “On the convergence properties of the EM algorithm,”Ann. Statist., vol. 11, no. 1, pp. 95–103, 1983
work page 1983
-
[17]
Information geometry of the EM and em algorithms for neural networks,
S. Amari, “Information geometry of the EM and em algorithms for neural networks,”Neural Networks, vol. 8, no. 9, pp. 1379–1408, 1995
work page 1995
-
[18]
Information geometry and alternating minimization procedures,
I. Csisz´ ar and G. Tusn´ ady, “Information geometry and alternating minimization procedures,”Statistics and Decisions, suppl. issue 1, pp. 205–237, 1984
work page 1984
-
[19]
An analysis of the EM algorithm and entropy-like proximal point methods,
P. Tseng, “An analysis of the EM algorithm and entropy-like proximal point methods,”Math. Oper. Res., vol. 29, no. 1, pp. 27–44, 2004
work page 2004
-
[20]
Acceleration of the EM algorithm via proximal point iterations,
S. Chr´ etien and A. O. Hero, “Acceleration of the EM algorithm via proximal point iterations,” inProc. IEEE Int. Symp. Information Theory (ISIT), 1998, p. 444
work page 1998
-
[21]
On EM algorithms and their proximal generalizations,
S. Chr´ etien and A. O. Hero, “On EM algorithms and their proximal generalizations,”ESAIM: Probab. Statist., vol. 12, pp. 308–326, 2008
work page 2008
-
[22]
Finding the observed information matrix when using the EM algorithm,
T. A. Louis, “Finding the observed information matrix when using the EM algorithm,”J. R. Statist. Soc. B, vol. 44, no. 2, pp. 226–233, 1982
work page 1982
-
[23]
A quasi-Newton acceleration for high-dimensional optimization algorithms,
H. Zhou, D. H. Alexander, and K. Lange, “A quasi-Newton acceleration for high-dimensional optimization algorithms,”Stat. Comput., vol. 21, no. 2, pp. 261–273, 2011
work page 2011
-
[24]
Maximum likelihood estimation via the ECM algorithm: A general frame- work,
X.-L. Meng and D. B. Rubin, “Maximum likelihood estimation via the ECM algorithm: A general frame- work,”Biometrika, vol. 80, no. 2, pp. 267–278, 1993
work page 1993
-
[25]
Fast curvature matrix-vector products for second-order gradient descent,
N. N. Schraudolph, “Fast curvature matrix-vector products for second-order gradient descent,”Neural Com- put., vol. 14, no. 7, pp. 1723–1738, 2002. 24 QIAO W ANG School of Information Science and Engineering, and School of Economics and Management, Southeast University, 211189, China Email address:qiaowang@seu.edu.cn EXPECTATION-MAXIMIZATION AS A SPECTRAL...
work page 2002
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.