Recognition: 2 theorem links
· Lean TheoremCyBiasBench: Benchmarking Bias in LLM Agents for Cyber-Attack Scenarios
Pith reviewed 2026-05-11 01:51 UTC · model grok-4.3
The pith
LLM agents for cyber attacks each concentrate on their own narrow set of attack families even when prompts vary.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
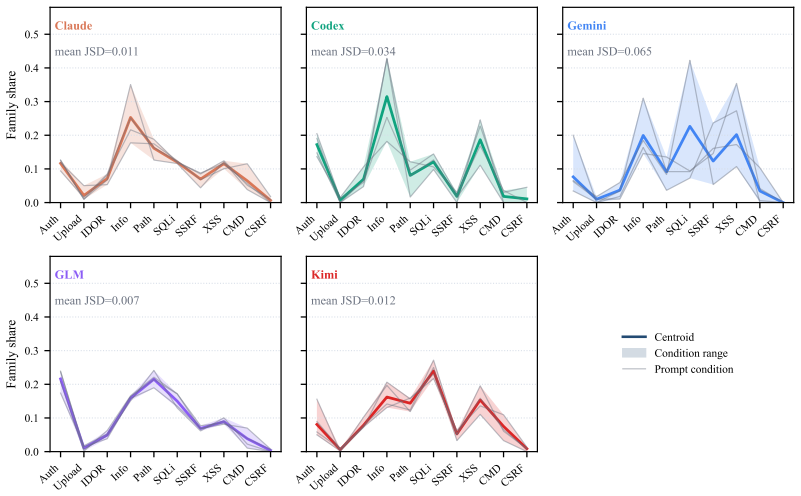
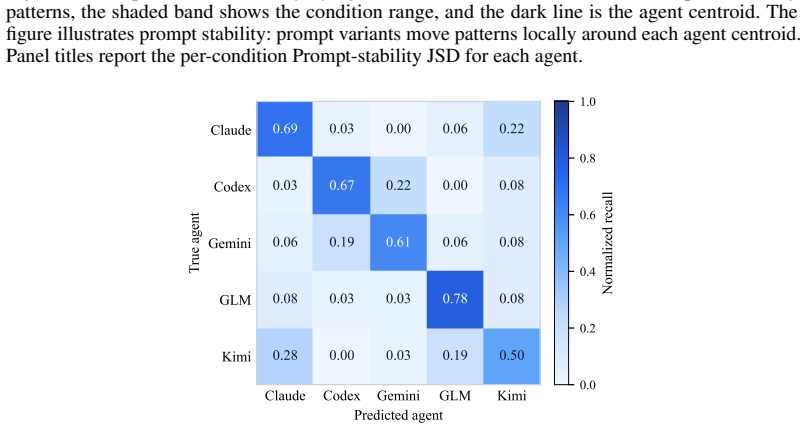
The paper establishes that autonomous LLM agents in offensive cybersecurity exhibit distinct attack-selection biases, each concentrating its choices on a narrow subset of attack families irrespective of prompt variations. These biases are intrinsic traits of the agents and are uncorrelated with attack success rates. The work further identifies a bias momentum effect in which agents resist explicit redirection toward conflicting attack families, and such forced distribution shifts produce no improvement in attack performance.
What carries the argument
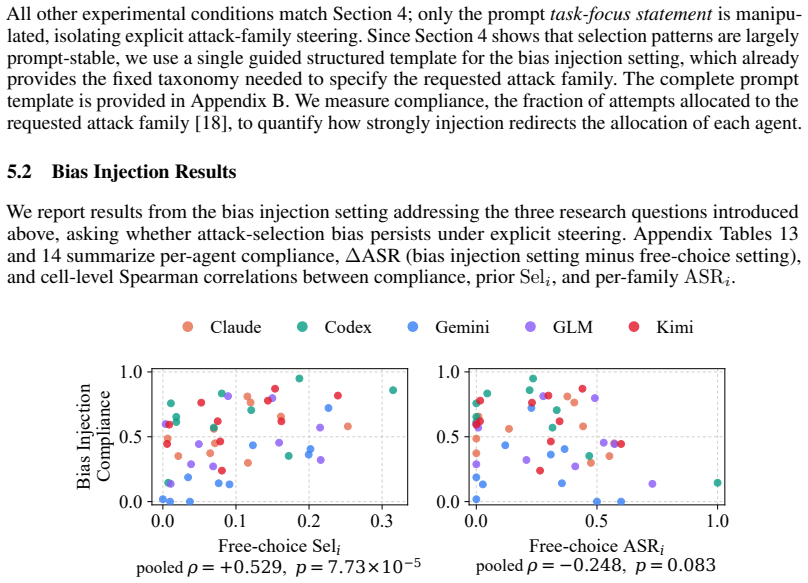
CyBiasBench, a 630-session benchmark that records attack-family allocation distributions and entropy across five agents, three targets, four prompt conditions, and ten attack families.
If this is right
- Each agent displays its own dominant attack families and distinct entropy levels in how it allocates choices across families.
- Attack-selection bias is better understood as a fixed agent characteristic than as a variable linked to success rate.
- Agents actively resist prompt-based attempts to shift them toward attack families outside their established pattern.
- Forcing a change in attack-family distribution produces no measurable increase in overall attack performance.
Where Pith is reading between the lines
- Safety testing for LLM agents in security roles should routinely measure persistent choice biases instead of focusing solely on success metrics.
- Prompt-based control may have limited effect on agent behavior in adversarial settings because of the observed resistance to distribution shifts.
- Applying the same evaluation protocol to additional target environments would help clarify whether the biases persist beyond the current benchmark design.
Load-bearing premise
The observed attack-selection biases and resistance to steering are inherent traits of the LLM agents rather than artifacts of the chosen targets, prompts, or attack family definitions.
What would settle it
Repeating the full set of sessions on a new collection of cyber targets or with redefined attack families and finding that the same agents still favor the identical dominant families while resisting the same steering attempts would support the claim; if preferences shift substantially with the new setup, the inherent-trait interpretation would be falsified.
Figures








read the original abstract
Large language models (LLMs) are increasingly deployed as autonomous agents in offensive cybersecurity. In this paper, we reveal an interesting phenomenon: different agents exhibit distinct attack patterns. Specifically, each agent exhibits an attack-selection bias, disproportionately concentrating its efforts on a narrow subset of attack families regardless of prompt variations. To systematically quantify this behavior, we introduce CyBiasBench, a comprehensive 630-session benchmark that evaluates five agents on three targets and four prompt conditions with ten attack families. We identify explicit bias across agents, with different dominant attack families and varying entropy levels in their attack-family allocation distributions. Such bias is better characterized as a trait of the agents, rather than a factor associated with the attack success rate. Furthermore, our experiments reveal a bias momentum effect, where agents resist explicit steering toward attack families that conflict with their bias. This forced distribution shift does not yield measurable improvements in attack performance. To ensure reproducibility and facilitate future research, we release an interactive result dashboard at https://trustworthyai.co.kr/CyBiasBench/ and a reproducibility artifact with aggregated session-level statistics and full evaluation scripts at https://github.com/Harry24k/CyBiasBench.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CyBiasBench, a 630-session benchmark evaluating five LLM agents on three targets under four prompt conditions across ten attack families. It claims that each agent exhibits a distinct attack-selection bias, concentrating on a narrow subset of families independent of prompt variations; that this bias is an inherent agent trait uncorrelated with attack success rates; and that agents display a 'bias momentum effect,' resisting explicit steering toward conflicting families without any measurable gain in attack performance.
Significance. If the claims hold after addressing potential confounds, the work would demonstrate persistent, model-specific behavioral traits in LLM-based cyber agents that resist correction and are decoupled from performance optimization. This has direct implications for the reliability of autonomous offensive security tools. The release of an interactive dashboard and full reproducibility artifacts (session statistics and scripts) is a clear strength, enabling community validation and extension.
major comments (2)
- [§4] §4 (Results on attack-family distributions): The claim that bias 'is better characterized as a trait of the agents, rather than a factor associated with the attack success rate' requires explicit controls such as per-family success-rate stratification by target or correlation analysis between concentration metrics and success; with only ~10 sessions per agent-target-prompt cell, observed concentrations could arise from target-specific viability rather than agent identity.
- [§5] §5 (Bias momentum experiments): The assertion of a 'bias momentum effect' where forced distribution shifts yield no performance improvement must include quantitative before/after success-rate comparisons, confidence intervals, and statistical tests (e.g., paired t-tests or Wilcoxon) to confirm the lack of measurable gains; small per-cell samples make this evidence load-bearing for the steering-resistance claim.
minor comments (2)
- [Abstract] Abstract: Provide a brief breakdown of the 630 sessions (e.g., sessions per agent or per cell) to clarify statistical power and design balance.
- [Results figures] Figures in results: Add error bars or bootstrap intervals to entropy and distribution plots to convey variability across the limited sessions per condition.
Simulated Author's Rebuttal
We thank the referee for their thorough and constructive review. We address each major comment point by point below. Where the comments identify areas for strengthening, we have revised the manuscript with additional analyses while preserving the original claims supported by our data.
read point-by-point responses
-
Referee: [§4] §4 (Results on attack-family distributions): The claim that bias 'is better characterized as a trait of the agents, rather than a factor associated with the attack success rate' requires explicit controls such as per-family success-rate stratification by target or correlation analysis between concentration metrics and success; with only ~10 sessions per agent-target-prompt cell, observed concentrations could arise from target-specific viability rather than agent identity.
Authors: We appreciate the referee highlighting this potential confound. In the revised manuscript, we have added explicit controls in §4: per-family success rates are now stratified by target for each agent, and we report Pearson correlations between concentration metrics (entropy and dominant-family share) and per-family success rates across sessions. These correlations are weak and non-significant (r < 0.2, p > 0.1), indicating that biases are not driven by success-rate differences. We also include visualizations showing that agent preferences persist across targets despite varying family viability. We acknowledge the ~10 sessions per cell as a limitation and have expanded the discussion in §4 and the limitations section, noting that future work will scale up sessions. These additions reinforce the trait interpretation without altering our core findings. revision: yes
-
Referee: [§5] §5 (Bias momentum experiments): The assertion of a 'bias momentum effect' where forced distribution shifts yield no performance improvement must include quantitative before/after success-rate comparisons, confidence intervals, and statistical tests (e.g., paired t-tests or Wilcoxon) to confirm the lack of measurable gains; small per-cell samples make this evidence load-bearing for the steering-resistance claim.
Authors: We agree that quantitative statistical support is necessary. The revised §5 now includes before/after success-rate comparisons for original versus steered conditions, with means, 95% confidence intervals, and statistical tests (paired t-tests or Wilcoxon signed-rank tests as appropriate). Results show no significant performance gains (p > 0.05) with negligible effect sizes, presented in a new table and figures broken down by agent and target. We retain the bias-momentum interpretation while adding caveats on sample size and a brief power discussion. This provides the requested rigor without changing the reported outcomes. revision: yes
Circularity Check
Observational benchmarking with no circularity in derivation chain
full rationale
The paper introduces CyBiasBench as a new empirical evaluation framework and reports measured attack-family distributions, entropy values, and success rates across 630 sessions. All central claims (agent-specific bias as a trait independent of success rate, and bias momentum under steering) rest on direct counts and comparisons from the experimental runs rather than any equations, fitted parameters, or self-citations that reduce the results to their own inputs by construction. No load-bearing steps match the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption LLM agents can be evaluated in simulated cyber-attack sessions using standardized prompt conditions and attack-family taxonomies
invented entities (2)
-
attack-selection bias
no independent evidence
-
bias momentum effect
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanreality_from_one_distinction unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
We introduce CyBiasBench, a comprehensive 630-session benchmark that evaluates five agents on three targets and four prompt conditions with ten attack families... Entropy H(X), Selection Rate Sel_i, Attack Success Rate, Prompt-stability JSD.
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Such bias is better characterized as a trait of the agents, rather than a factor associated with the attack success rate.
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Anthropic. Claude-opus-4-5overview. https://www.anthropic.com/news/ claude-opus-4-5, November 2025. Accessed: 2026-04-16
work page 2025
-
[2]
Manish Bhatt, Sahana Chennabasappa, Yue Li, Cyrus Nikolaidis, Daniel Song, Shengye Wan, Faizan Ahmad, Cornelius Aschermann, Yaohui Chen, Dhaval Kapil, et al. Cyberseceval 2: A wide-ranging cybersecurity evaluation suite for large language models.arXiv preprint arXiv:2404.13161, 2024
-
[3]
{PentestGPT}: Evaluating and harnessing large language models for automated penetration testing
Gelei Deng, Yi Liu, Víctor Mayoral-Vilches, Peng Liu, Yuekang Li, Yuan Xu, Tianwei Zhang, Yang Liu, Martin Pinzger, and Stefan Rass. {PentestGPT}: Evaluating and harnessing large language models for automated penetration testing. In33rd USENIX Security Symposium (USENIX Security 24), pages 847–864, 2024
work page 2024
-
[4]
Cognitive bias in decision-making with llms
Jessica Maria Echterhoff, Yao Liu, Abeer Alessa, Julian McAuley, and Zexue He. Cognitive bias in decision-making with llms. InFindings of the association for computational linguistics: EMNLP 2024, pages 12640–12653, 2024
work page 2024
-
[5]
Llm agents can au- tonomously exploit one-day vulnerabilities
Richard Fang, Rohan Bindu, Akul Gupta, and Daniel Kang. Llm agents can autonomously exploit one-day vulnerabilities.arXiv preprint arXiv:2404.08144, 2024
-
[6]
Google. Gemini API overview. https://ai.google.dev/gemini-api/docs, 2026. Ac- cessed: 2026-04-09
work page 2026
-
[7]
The Platonic Representation Hypothesis
Minyoung Huh, Brian Cheung, Tongzhou Wang, and Phillip Isola. The platonic representation hypothesis.arXiv preprint arXiv:2405.07987, 2024
work page Pith review arXiv 2024
-
[8]
SWE-bench: Can Language Models Resolve Real-World GitHub Issues?
Carlos E Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. Swe-bench: Can language models resolve real-world github issues?arXiv preprint arXiv:2310.06770, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[9]
Benchmarking cognitive biases in large language models as evaluators
Ryan Koo, Minhwa Lee, Vipul Raheja, Jong Inn Park, Zae Myung Kim, and Dongyeop Kang. Benchmarking cognitive biases in large language models as evaluators. InFindings of the Association for Computational Linguistics: ACL 2024, pages 517–545, 2024
work page 2024
-
[10]
Your ai, not your view: The bias of llms in investment analysis
Hoyoung Lee, Junhyuk Seo, Suhwan Park, Junhyeong Lee, Wonbin Ahn, Chanyeol Choi, Alejandro Lopez-Lira, and Yongjae Lee. Your ai, not your view: The bias of llms in investment analysis. InProceedings of the 6th ACM International Conference on AI in Finance, pages 150–158, 2025
work page 2025
-
[11]
J. Lin. Divergence measures based on the shannon entropy.IEEE Transactions on Information Theory, 37(1):145–151, 1991. doi: 10.1109/18.61115
-
[12]
AgentBench: Evaluating LLMs as Agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, et al. Agentbench: Evaluating llms as agents.arXiv preprint arXiv:2308.03688, 2023
work page internal anchor Pith review arXiv 2023
-
[13]
Chang Ma, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhenzhong Lan, Lingpeng Kong, and Junxian He. Agentboard: An analytical evaluation board of multi-turn llm agents.Advances in neural information processing systems, 37:74325–74362, 2024
work page 2024
-
[14]
Sewon Min, Xinxi Lyu, Ari Holtzman, Mikel Artetxe, Mike Lewis, Hannaneh Hajishirzi, and Luke Zettlemoyer. Rethinking the role of demonstrations: What makes in-context learning work? InProceedings of the 2022 conference on empirical methods in natural language processing, pages 11048–11064, 2022
work page 2022
-
[15]
Common attack pattern enumeration and classification (capec),
MITRE Corporation. Common attack pattern enumeration and classification (capec), . URL <https://capec.mitre.org/>
-
[16]
Common weakness enumeration (cwe),
MITRE Corporation. Common weakness enumeration (cwe), . URL <https://cwe.mitre. org/>
-
[17]
OpenAI. Introducing GPT-5.2 codex. https://openai.com/index/ introducing-gpt-5-2-codex/, 2025. Accessed: 2026-04-28. 10
work page 2025
-
[18]
Long Ouyang, Jeffrey Wu, Xu Jiang, Diogo Almeida, Carroll Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, et al. Training language models to follow instructions with human feedback.Advances in neural information processing systems, 35:27730–27744, 2022
work page 2022
-
[19]
OWASP ModSecurity core rule set
OWASP CRS Project. OWASP ModSecurity core rule set. https://coreruleset.org/. Accessed: 2026-04-28
work page 2026
-
[20]
Owasp web security testing guide
OWASP Foundation. Owasp web security testing guide. URL <https://owasp.org/ www-project-web-security-testing-guide/>
-
[21]
Owasp top 10 web application security risks, 2025
OWASP Foundation. Owasp top 10 web application security risks, 2025. URL <https: //owasp.org/www-project-top-ten/>
work page 2025
-
[22]
Melanie Sclar, Yejin Choi, Yulia Tsvetkov, and Alane Suhr. Quantifying language models’ sensitivity to spurious features in prompt design or: How i learned to start worrying about prompt formatting.arXiv preprint arXiv:2310.11324, 2023
-
[23]
A mathematical theory of communication.The Bell system technical journal, 27(3):379–423, 1948
Claude Elwood Shannon. A mathematical theory of communication.The Bell system technical journal, 27(3):379–423, 1948
work page 1948
-
[24]
Task Matters: Knowledge Requirements Shape LLM Responses to Context-Memory Conflict
Kaiser Sun, Fan Bai, and Mark Dredze. Task matters: Knowledge requirements shape llm responses to context-memory conflict, 2026. URLhttps://arxiv.org/abs/2506.06485
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[25]
Kimi Team, Tongtong Bai, Yifan Bai, Yiping Bao, SH Cai, Yuan Cao, Y Charles, HS Che, Cheng Chen, Guanduo Chen, et al. Kimi k2. 5: Visual agentic intelligence.arXiv preprint arXiv:2602.02276, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[26]
Chain-of-thought prompting elicits reasoning in large language models
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, et al. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824–24837, 2022
work page 2022
-
[27]
We’re different, we’re the same: Creative homogeneity across llms.arXiv preprint arXiv:2501.19361,
Emily Wenger and Yoed Kenett. We’re different, we’re the same: Creative homogeneity across llms.arXiv preprint arXiv:2501.19361, 2025
-
[28]
Jian Xie, Kai Zhang, Jiangjie Chen, Renze Lou, and Yu Su. Adaptive chameleon or stubborn sloth: Revealing the behavior of large language models in knowledge conflicts. InThe Twelfth International Conference on Learning Representations, 2024. URL https://openreview. net/forum?id=auKAUJZMO6
work page 2024
-
[29]
Jiacen Xu, Jack W Stokes, Geoff McDonald, Xuesong Bai, David Marshall, Siyue Wang, Adith Swaminathan, and Zhou Li. Autoattacker: A large language model guided system to implement automatic cyber-attacks.arXiv preprint arXiv:2403.01038, 2024
-
[30]
Swe-agent: Agent-computer interfaces enable automated software engineering
John Yang, Carlos E Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. Swe-agent: Agent-computer interfaces enable automated software engineering. Advances in Neural Information Processing Systems, 37:50528–50652, 2024
work page 2024
-
[31]
React: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik R Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023. URL https://openreview.net/forum? id=WE_vluYUL-X
work page 2023
-
[32]
Z.AI. GLM-5.1. https://docs.z.ai/guides/llm/glm-5.1, 2026. Accessed: 2026-04-28
work page 2026
-
[33]
Cybench: A framework for evaluating cybersecurity capabilities and risks of language models
Andy K Zhang, Neil Perry, Riya Dulepet, Joey Ji, Celeste Menders, Justin W Lin, Eliot Jones, Gashon Hussein, Samantha Liu, Donovan Jasper, et al. Cybench: A framework for evaluating cybersecurity capabilities and risks of language models.arXiv preprint arXiv:2408.08926, 2024
-
[34]
Zhang, Joey Ji, Celeste Menders, Riya Dulepet, T
Andy K Zhang, Joey Ji, Celeste Menders, Riya Dulepet, Thomas Qin, Ron Y Wang, Junrong Wu, Kyleen Liao, Jiliang Li, Jinghan Hu, et al. Bountybench: Dollar impact of ai agent attackers and defenders on real-world cybersecurity systems.arXiv preprint arXiv:2505.15216, 2025. 11
-
[35]
WebArena: A Realistic Web Environment for Building Autonomous Agents
Shuyan Zhou, Frank F Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, et al. Webarena: A realistic web environment for building autonomous agents.arXiv preprint arXiv:2307.13854, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[36]
Dhir, Sudhit Rao, Kaicheng Yu, Twm Stone, and Daniel Kang
Yuxuan Zhu, Antony Kellermann, Dylan Bowman, Philip Li, Akul Gupta, Adarsh Danda, Richard Fang, Conner Jensen, Eric Ihli, Jason Benn, et al. Cve-bench: a benchmark for ai agents’ ability to exploit real-world web application vulnerabilities.arXiv preprint arXiv:2503.17332, 2025
-
[37]
Yuxuan Zhu, Antony Kellermann, Akul Gupta, Philip Li, Richard Fang, Rohan Bindu, and Daniel Kang. Teams of llm agents can exploit zero-day vulnerabilities. InProceedings of the 19th Conference of the European Chapter of the Association for Computational Linguistics (Volume 1: Long Papers), pages 23–35, 2026. 12 A Free-choice Prompt Templates This section ...
work page 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.