Recognition: 2 theorem links
· Lean Theoremmathsf{VISTA}: Decentralized Machine Learning in Adversary Dominated Environments
Pith reviewed 2026-05-11 02:25 UTC · model grok-4.3
The pith
Adaptive threshold tuning lets decentralized SGD converge asymptotically despite adversary majority.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We propose VISTA, an adaptive algorithm that tunes the acceptance threshold using the optimization history. With suitable incentive-aware adaptation, adversary-dominated decentralized learning can retain the asymptotic convergence behavior of standard SGD without relying on an honest majority.
What carries the argument
The incentive-oriented acceptance rule combined with the VISTA adaptive threshold tuner, which uses past optimization progress to decide how permissive to be with report consistency.
If this is right
- Adversary-dominated settings achieve the same asymptotic convergence rate as standard SGD.
- Dynamic threshold adaptation outperforms static rules by balancing speed and accuracy over iterations.
- Adversaries are forced to act rationally, limiting the damage they can cause without detection.
- Long-horizon iterative optimization benefits from history-dependent rules rather than one-shot decisions.
Where Pith is reading between the lines
- Extensions could include applying similar adaptation to non-convex optimization or federated learning with partial participation.
- Empirical validation in real distributed systems with actual reward mechanisms would strengthen the incentive claims.
- The approach opens questions about optimal threshold schedules for different adversary strategies.
Load-bearing premise
Adversaries act as rational agents balancing the increase in estimation error against the risk of report rejection and loss of reward, without the adaptive rule introducing instabilities.
What would settle it
If simulations with a majority of adversarial workers show that VISTA fails to converge or converges significantly slower than standard SGD, the claim would be falsified.
Figures









read the original abstract
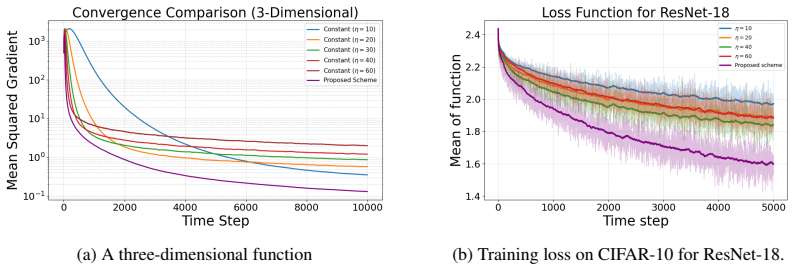
Decentralized machine learning often relies on outsourcing computations, such as gradient evaluations, to untrusted worker nodes. Existing robust aggregation methods can mitigate malicious behavior under honest-majority assumptions, but may fail when adversaries control a majority of the workers. We study this adversary-dominated setting through an incentive-oriented framework in which reports are accepted and rewarded only when they are mutually consistent up to a threshold. This turns the adversary from a pure saboteur into a rational agent that trades off increasing estimation error against the risk of rejection and loss of reward. We consider iterative optimization under this model. Unlike one-shot computation, iterative learning requires long-horizon decisions: permissive acceptance rules enable faster early progress but admit more adversarial corruption, while strict rules improve estimation accuracy but cause frequent rejections. We propose \mathsf{VISTA}, an adaptive algorithm that tunes the acceptance threshold using the optimization history. Numerical results show that \mathsf{VISTA} improves convergence over static thresholds. We also provide a rigorous convergence analysis showing that, with suitable incentive-aware adaptation, adversary-dominated decentralized learning can retain the asymptotic convergence behavior of standard SGD without relying on an honest majority.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes VISTA, an adaptive algorithm for decentralized machine learning when adversaries control a majority of workers. It introduces an incentive framework in which reports are accepted and rewarded only if mutually consistent up to a tunable threshold, modeling adversaries as rational agents balancing estimation error against rejection risk. VISTA adjusts the threshold dynamically using optimization history to trade off early progress against corruption. The authors claim numerical improvements over static thresholds and provide a rigorous convergence analysis asserting that, under suitable adaptation, the method retains the asymptotic convergence rate of standard SGD without requiring an honest majority.
Significance. If the central convergence claim holds, the work is significant for relaxing the honest-majority assumption prevalent in robust aggregation literature for decentralized and federated learning. The incentive-oriented modeling and history-based adaptation offer a fresh perspective on long-horizon decisions in iterative optimization under adversarial incentives. Credit is due for supplying both a theoretical analysis and numerical validation; the absence of free parameters in the core model and the explicit focus on asymptotic behavior are strengths.
major comments (2)
- [§5] §5 (Convergence Analysis), main theorem: The proof that asymptotic SGD-like convergence is retained assumes the adaptive threshold keeps the effective bias from accepted gradients controlled. However, when adversaries exceed 50% and coordinate on identical but biased reports, they form a large consistent cluster; the history-based relaxation rule can incrementally raise the threshold, admitting persistent bias without an explicit bound on the resulting deviation from the true gradient. This is load-bearing for the claim that no honest majority is required.
- [§3] §3 (Model), rational-adversary definition: The assumption that adversaries rationally trade estimation error against rejection risk does not address coordinated equilibria. When a majority colludes on a common biased value while remaining internally consistent, the mutual-consistency check accepts the cluster; the paper provides no equilibrium analysis or bound showing that the adaptive rule still forces the bias to decay at the SGD rate.
minor comments (3)
- [Abstract] Abstract: The phrase 'rigorous convergence analysis' appears without a forward reference to the specific theorem or the precise assumptions (e.g., bounded variance, Lipschitz constants) under which the SGD rate is recovered.
- [Numerical results] Numerical results section: Convergence plots are presented without reporting the number of independent runs, standard deviations, or confidence intervals, making it difficult to judge whether the observed improvement over static thresholds is statistically reliable.
- [Algorithm description] Notation: The symbol for the adaptive threshold is introduced without an explicit recurrence or update rule in the main text; readers must infer the exact dependence on optimization history from the algorithm box alone.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments identify important points regarding the handling of coordinated adversaries in the convergence analysis and the modeling assumptions. We address each below and outline targeted revisions that strengthen the claims without altering the core contributions.
read point-by-point responses
-
Referee: [§5] §5 (Convergence Analysis), main theorem: The proof that asymptotic SGD-like convergence is retained assumes the adaptive threshold keeps the effective bias from accepted gradients controlled. However, when adversaries exceed 50% and coordinate on identical but biased reports, they form a large consistent cluster; the history-based relaxation rule can incrementally raise the threshold, admitting persistent bias without an explicit bound on the resulting deviation from the true gradient. This is load-bearing for the claim that no honest majority is required.
Authors: We appreciate the referee drawing attention to this aspect of the proof. The main theorem in §5 establishes asymptotic SGD-like rates under the adaptive rule by showing that the threshold relaxes only when historical consistency aligns with objective progress; persistent bias from a coordinated cluster would stall descent and thereby cap further relaxation. Nevertheless, we agree that an explicit bias bound for the >50% coordinated case would make the argument more transparent. In the revision we will insert a supporting lemma in §5 that derives a uniform bound on the deviation of accepted gradients under majority-consistent attacks, confirming that the adaptation still forces the bias term to vanish at the required rate. This addition directly addresses the load-bearing concern while preserving the existing proof structure. revision: partial
-
Referee: [§3] §3 (Model), rational-adversary definition: The assumption that adversaries rationally trade estimation error against rejection risk does not address coordinated equilibria. When a majority colludes on a common biased value while remaining internally consistent, the mutual-consistency check accepts the cluster; the paper provides no equilibrium analysis or bound showing that the adaptive rule still forces the bias to decay at the SGD rate.
Authors: The referee correctly observes that §3 models individual rational trade-offs and does not contain a dedicated equilibrium analysis for colluding majorities. While the incentive structure and history-based adaptation are intended to deter sustained large biases (because non-progress halts threshold relaxation), we acknowledge the absence of an explicit game-theoretic treatment of coordinated equilibria. In the revised manuscript we will add a short subsection to §3 that sketches the relevant equilibrium considerations and shows, via the same progress-dependent relaxation mechanism used in the convergence proof, that rational colluders cannot maintain a fixed positive bias indefinitely without violating the long-horizon reward objective. This discussion will be cross-referenced to the new lemma in §5. revision: partial
Circularity Check
No significant circularity; convergence analysis builds on external SGD assumptions
full rationale
The paper's derivation chain centers on an adaptive threshold rule motivated by long-horizon optimization trade-offs, followed by a claimed rigorous convergence analysis that retains standard SGD asymptotics. No equations or steps in the provided text reduce the target convergence rate to a fitted parameter, self-defined quantity, or self-citation chain. The analysis is presented as extending standard SGD assumptions under the incentive model rather than tautologically re-deriving them from the adaptation rule itself. Numerical results are experimental and do not substitute for the analytic claim. This is the common case of a self-contained derivation against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard SGD convergence assumptions (bounded variance, unbiased gradients, appropriate step sizes)
invented entities (1)
-
Rational adversary that trades estimation error against rejection risk
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe propose VISTA, an adaptive algorithm that tunes the acceptance threshold using the optimization history... retain the asymptotic convergence behavior of standard SGD without relying on an honest majority.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearthe adversary becomes a rational agent that must balance the benefit of increasing the estimation error against the risk of rejection and loss of reward
Reference graph
Works this paper leans on
-
[1]
Blockchain for deep learning: review and open challenges.Cluster Computing, 26(1):197–221, 2023
Muhammad Shafay, Raja Wasim Ahmad, Khaled Salah, Ibrar Yaqoob, Raja Jayaraman, and Mohammed Omar. Blockchain for deep learning: review and open challenges.Cluster Computing, 26(1):197–221, 2023
work page 2023
-
[2]
Survey on the convergence of machine learning and blockchain
Shengwen Ding and Chenhui Hu. Survey on the convergence of machine learning and blockchain. InProceedings of SAI Intelligent Systems Conference, pages 170–189. Springer, 2022
work page 2022
-
[3]
Blockchain meets machine learning: a survey
Safak Kayikci and Taghi M Khoshgoftaar. Blockchain meets machine learning: a survey. Journal of Big Data, 11(1):1–29, 2024. 10
work page 2024
-
[4]
Blockchain and machine learning: A critical review on security.Information, 14(5):295, 2023
Hamed Taherdoost. Blockchain and machine learning: A critical review on security.Information, 14(5):295, 2023
work page 2023
-
[5]
Hamed Taherdoost. Blockchain technology and artificial intelligence together: a critical review on applications.Applied Sciences, 12(24):12948, 2022
work page 2022
-
[6]
Blockchain for AI: A disruptive integration
Ruijiao Tian, Lanju Kong, Xinping Min, and Yunhao Qu. Blockchain for AI: A disruptive integration. In2022 IEEE 25th International Conference on Computer Supported Cooperative Work in Design (CSCWD), pages 938–943. IEEE, 2022
work page 2022
-
[7]
Blockchain for AI: Review and open research challenges.IEEE Access, 7:10127–10149, 2019
Khaled Salah, M Habib Ur Rehman, Nishara Nizamuddin, and Ala Al-Fuqaha. Blockchain for AI: Review and open research challenges.IEEE Access, 7:10127–10149, 2019
work page 2019
-
[8]
Lingchen Zhao, Qian Wang, Cong Wang, Qi Li, Chao Shen, and Bo Feng. VeriML: Enabling integrity assurances and fair payments for machine learning as a service.IEEE Transactions on Parallel and Distributed Systems, 32(10):2524–2540, 2021
work page 2021
-
[9]
Blockchains cannot rely on honesty
Jakub Sliwinski and Roger Wattenhofer. Blockchains cannot rely on honesty. InThe 19th International Conference on Autonomous Agents and Multiagent Systems (AAMAS 2020), 2019
work page 2020
-
[10]
Fact and fiction: Challenging the honest majority assumption of permissionless blockchains
Runchao Han, Zhimei Sui, Jiangshan Yu, Joseph Liu, and Shiping Chen. Fact and fiction: Challenging the honest majority assumption of permissionless blockchains. InProceedings of the 2021 ACM Asia Conference on Computer and Communications Security, pages 817–831, 2021
work page 2021
- [11]
-
[12]
Byzantine-resilient non- convex stochastic gradient descent.arXiv preprint arXiv:2012.14368, 2020
Zeyuan Allen-Zhu, Faeze Ebrahimian, Jerry Li, and Dan Alistarh. Byzantine-resilient non- convex stochastic gradient descent.arXiv preprint arXiv:2012.14368, 2020
-
[13]
Byzantine machine learning made easy by resilient averaging of momentums
Sadegh Farhadkhani, Rachid Guerraoui, Nirupam Gupta, Rafael Pinot, and John Stephan. Byzantine machine learning made easy by resilient averaging of momentums. InInternational Conference on Machine Learning, pages 6246–6283. PMLR, 2022
work page 2022
-
[14]
Qiankun Shi, Jie Peng, Kun Yuan, Xiao Wang, and Qing Ling. Optimal complexity in byzantine- robust distributed stochastic optimization with data heterogeneity.Journal of Machine Learning Research, 26(268):1–58, 2025
work page 2025
-
[15]
Learning from history for byzantine robust optimization
Sai Praneeth Karimireddy, Lie He, and Martin Jaggi. Learning from history for byzantine robust optimization. InInternational Conference on Machine Learning, pages 5311–5319. PMLR, 2021
work page 2021
-
[16]
Byzantine machine learning: A primer
Rachid Guerraoui, Nirupam Gupta, and Rafael Pinot. Byzantine machine learning: A primer. ACM Computing Surveys, 56(7):1–39, 2024
work page 2024
-
[17]
Byzantine-robust federated learning with optimal statistical rates
Banghua Zhu, Lun Wang, Qi Pang, Shuai Wang, Jiantao Jiao, Dawn Song, and Michael I Jordan. Byzantine-robust federated learning with optimal statistical rates. InInternational Conference on Artificial Intelligence and Statistics, pages 3151–3178. PMLR, 2023
work page 2023
-
[18]
Byzantine- robust learning on heterogeneous data via gradient splitting
Yuchen Liu, Chen Chen, Lingjuan Lyu, Fangzhao Wu, Sai Wu, and Gang Chen. Byzantine- robust learning on heterogeneous data via gradient splitting. InInternational Conference on Machine Learning, pages 21404–21425. PMLR, 2023
work page 2023
-
[19]
Haibo Yang, Xin Zhang, Minghong Fang, and Jia Liu. Byzantine-resilient stochastic gradient descent for distributed learning: A lipschitz-inspired coordinate-wise median approach. In2019 IEEE 58th Conference on Decision and Control (CDC), pages 5832–5837. IEEE, 2019
work page 2019
-
[20]
Shashank Rajput, Hongyi Wang, Zachary Charles, and Dimitris Papailiopoulos. Detox: A redundancy-based framework for faster and more robust gradient aggregation.Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[21]
Byzantine-robust federated learning through spatial-temporal analysis of local model updates
Zhuohang Li, Luyang Liu, Jiaxin Zhang, and Jian Liu. Byzantine-robust federated learning through spatial-temporal analysis of local model updates. In2021 IEEE 27th International Conference on Parallel and Distributed Systems (ICPADS), pages 372–379. IEEE, 2021. 11
work page 2021
-
[22]
Ro- bust distributed learning: Tight error bounds and breakdown point under data heterogeneity
Youssef Allouah, Rachid Guerraoui, Nirupam Gupta, Rafael Pinot, and Geovani Rizk. Ro- bust distributed learning: Tight error bounds and breakdown point under data heterogeneity. Advances in Neural Information Processing Systems, 36:45744–45776, 2023
work page 2023
-
[23]
Byzantine stochastic gradient descent.Advances in Neural Information Processing Systems, 31, 2018
Dan Alistarh, Zeyuan Allen-Zhu, and Jerry Li. Byzantine stochastic gradient descent.Advances in Neural Information Processing Systems, 31, 2018
work page 2018
-
[24]
El Mahdi El-Mhamdi, Sadegh Farhadkhani, Rachid Guerraoui, Arsany Guirguis, Lê-Nguyên Hoang, and Sébastien Rouault. Collaborative learning in the jungle (decentralized, byzantine, heterogeneous, asynchronous and nonconvex learning).Advances in Neural Information Processing Systems, 34:25044–25057, 2021
work page 2021
-
[25]
The hidden vulnerability of distributed learning in Byzantium
Rachid Guerraoui and Sébastien Rouault. The hidden vulnerability of distributed learning in Byzantium. InInternational Conference on Machine Learning, pages 3521–3530. PMLR, 2018
work page 2018
-
[26]
Byzantine-robust distributed learning: Towards optimal statistical rates
Dong Yin, Yudong Chen, Ramchandran Kannan, and Peter Bartlett. Byzantine-robust distributed learning: Towards optimal statistical rates. InInternational Conference on Machine Learning, pages 5650–5659. PMLR, 2018
work page 2018
-
[27]
Peva Blanchard, El Mahdi El Mhamdi, Rachid Guerraoui, and Julien Stainer. Machine learn- ing with adversaries: Byzantine tolerant gradient descent.Advances in Neural Information Processing Systems, 30, 2017
work page 2017
-
[28]
Cadambe, and Mohammad Ali Maddah-Ali
Hanzaleh Akbari Nodehi, Viveck R. Cadambe, and Mohammad Ali Maddah-Ali. Game of coding: Beyond honest-majority assumptions.IEEE Transactions on Information Theory (submitted), 2024. URLhttps://arxiv.org/abs/2401.16643
-
[29]
Game of Coding for Vector-Valued Computations
Hanzaleh Akbari Nodehi, Parsa Moradi, Soheil Mohajer, and Mohammad Ali Maddah-Ali. Game of coding for vector-valued computations.arXiv preprint arXiv:2602.04810, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[30]
Game of coding: Sybil resistant decentralized machine learning with minimal trust assumption,
Hanzaleh Akbari Nodehi, Viveck R. Cadambe, and Mohammad Ali Maddah-Ali. Game of coding: Sybil resistant decentralized machine learning with minimal trust assumption.arXiv preprint, 2024. https://arxiv.org/abs/2410.05540
-
[31]
Game of coding with an unknown adversary
Hanzaleh Akbari Nodehi, Pejman Moradi, and Mohammad Ali Maddah-Ali. Game of coding with an unknown adversary. In2025 IEEE International Symposium on Information Theory (ISIT), Ann Arbor, MI, USA, 2025
work page 2025
-
[32]
Hanzaleh Akbari Nodehi, Viveck R Cadambe, and Mohammad Ali Maddah-Ali. Game of coding: Coding theory in the presence of rational adversaries, motivated by decentralized machine learning.arXiv preprint arXiv:2601.02313, 2026
-
[33]
Springer Science & Business Media, 2010
Heinrich V on Stackelberg.Market structure and equilibrium. Springer Science & Business Media, 2010
work page 2010
-
[34]
Adam: A method for stochastic optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization. InInterna- tional Conference on Learning Representations, 2015
work page 2015
-
[35]
Adadelta: an adaptive learning rate method.arXiv preprint arXiv:1212.5701,
Matthew D Zeiler. Adadelta: an adaptive learning rate method.arXiv preprint arXiv:1212.5701, 2012
-
[36]
Adaptive gradient methods with dynamic bound of learning rate,
Liangchen Luo, Yuanhao Xiong, Yan Liu, and Xu Sun. Adaptive gradient methods with dynamic bound of learning rate.arXiv preprint arXiv:1902.09843, 2019
-
[37]
Manzil Zaheer, Sashank Reddi, Devendra Sachan, Satyen Kale, and Sanjiv Kumar. Adaptive methods for nonconvex optimization.Advances in Neural Information Processing Systems, 31, 2018
work page 2018
-
[38]
Decoupled Weight Decay Regularization
Ilya Loshchilov and Frank Hutter. Decoupled weight decay regularization.arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[39]
Exponential moving average of weights in deep learning: Dynamics and benefits,
Daniel Morales-Brotons, Thijs V ogels, and Hadrien Hendrikx. Exponential moving average of weights in deep learning: Dynamics and benefits.arXiv preprint arXiv:2411.18704, 2024. 12
-
[40]
Boris T Polyak. Some methods of speeding up the convergence of iteration methods.USSR Computational Mathematics and Mathematical Physics, 4(5):1–17, 1964
work page 1964
-
[41]
Adafactor: Adaptive learning rates with sublinear memory cost
Noam Shazeer and Mitchell Stern. Adafactor: Adaptive learning rates with sublinear memory cost. InInternational Conference on Machine Learning, pages 4596–4604. PMLR, 2018
work page 2018
-
[42]
Ashok Cutkosky and Francesco Orabona. Momentum-based variance reduction in non-convex SGD.Advances in Neural Information Processing Systems, 32, 2019
work page 2019
-
[43]
A stochastic approximation method.The Annals of Mathematical Statistics, pages 400–407, 1951
Herbert Robbins and Sutton Monro. A stochastic approximation method.The Annals of Mathematical Statistics, pages 400–407, 1951
work page 1951
-
[44]
Optimization methods for large-scale machine learning.SIAM Review, 60(2):223–311, 2018
Léon Bottou, Frank E Curtis, and Jorge Nocedal. Optimization methods for large-scale machine learning.SIAM Review, 60(2):223–311, 2018
work page 2018
-
[45]
John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic optimization.Journal of Machine Learning Research, 12(7), 2011
work page 2011
-
[46]
Juntang Zhuang, Tommy Tang, Yifan Ding, Sekhar C Tatikonda, Nicha Dvornek, Xenophon Papademetris, and James Duncan. Adabelief optimizer: Adapting stepsizes by the belief in observed gradients.Advances in Neural Information Processing Systems, 33:18795–18806, 2020
work page 2020
-
[47]
On the Convergence of Adam and Beyond
Sashank J Reddi, Satyen Kale, and Sanjiv Kumar. On the convergence of adam and beyond. arXiv preprint arXiv:1904.09237, 2019
work page Pith review arXiv 1904
-
[48]
Rachel Ward, Xiaoxia Wu, and Leon Bottou. Adagrad stepsizes: Sharp convergence over nonconvex landscapes.Journal of Machine Learning Research, 21(219):1–30, 2020
work page 2020
-
[49]
On the importance of initial- ization and momentum in deep learning
Ilya Sutskever, James Martens, George Dahl, and Geoffrey Hinton. On the importance of initial- ization and momentum in deep learning. InInternational Conference on Machine Learning, pages 1139–1147. PMLR, 2013
work page 2013
- [50]
-
[51]
Learning-rate-free learning by D-Adaptation
Aaron Defazio and Konstantin Mishchenko. Learning-rate-free learning by D-Adaptation. In International Conference on Machine Learning, pages 7449–7479. PMLR, 2023
work page 2023
-
[52]
Learning in stackelberg games with non-myopic agents
Nika Haghtalab, Thodoris Lykouris, Sloan Nietert, and Alexander Wei. Learning in stackelberg games with non-myopic agents. InProceedings of the 23rd ACM Conference on Economics and Computation, pages 917–918, 2022
work page 2022
-
[53]
Natalie Collina, Varun Gupta, and Aaron Roth. Repeated contracting with multiple non-myopic agents: Policy regret and limited liability.arXiv preprint arXiv:2402.17108, 2024
-
[54]
Pareto-optimal algo- rithms for learning in games
Eshwar Ram Arunachaleswaran, Natalie Collina, and Jon Schneider. Pareto-optimal algo- rithms for learning in games. InProceedings of the 25th ACM Conference on Economics and Computation, 2024
work page 2024
-
[55]
Levine, and Wolfgang Pesendorfer
Marco Celentani, Drew Fudenberg, David K. Levine, and Wolfgang Pesendorfer. Maintaining a reputation against a long-lived opponent.Econometrica, 64(3):691–704, 1996
work page 1996
-
[56]
Learning to manipulate a commitment optimizer.arXiv preprint arXiv:2302.11829, 2023
Yurong Chen, Xiaotie Deng, Jiarui Gan, and Yuhao Li. Learning to manipulate a commitment optimizer.arXiv preprint arXiv:2302.11829, 2023
-
[57]
Yurii Nesterov.Introductory Lectures on Convex Optimization: A Basic Course, volume 87 ofApplied Optimization. Springer, Boston, MA, 2004. ISBN 978-1-4020-7553-7. doi: 10.1007/978-1-4419-8853-9
-
[58]
arXiv preprint arXiv:1308.6370 , year=
Mark Schmidt and Nicolas Le Roux. Fast convergence of stochastic gradient descent under a strong growth condition.arXiv, 2013. doi: 10.48550/arxiv.1308.6370. 13
-
[59]
Yann LeCun, Léon Bottou, Yoshua Bengio, and Patrick Haffner. Gradient-based learning applied to document recognition.Proceedings of the IEEE, 86(11):2278–2324, 2002
work page 2002
-
[60]
MNIST handwritten digit database.ATT Labs [Online], 2, 2010
Yann LeCun, Corinna Cortes, and CJ Burges. MNIST handwritten digit database.ATT Labs [Online], 2, 2010. URLhttp://yann.lecun.com/exdb/mnist
work page 2010
-
[61]
Deep residual learning for im- age recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. Deep residual learning for im- age recognition. InProceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 770–778, 2016
work page 2016
-
[62]
Learning multiple layers of features from tiny images
Alex Krizhevsky. Learning multiple layers of features from tiny images. Technical report, University of Toronto, 2009
work page 2009
-
[63]
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Agüera y Arcas
H. Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Agüera y Arcas. Communication-efficient learning of deep networks from decentralized data. InProceedings of the 20th International Conference on Artificial Intelligence and Statistics, pages 1273–1282. PMLR, 2017
work page 2017
-
[64]
FLTrust: Byzantine-robust fed- erated learning via trust bootstrapping
Xiaoyu Cao, Minghong Fang, Jia Liu, and Neil Zhenqiang Gong. FLTrust: Byzantine-robust fed- erated learning via trust bootstrapping. InNetwork and Distributed System Security Symposium, 2021
work page 2021
-
[65]
FLAME: Taming backdoors in federated learning
Thien Duc Nguyen, Phillip Rieger, Huili Chen, Hossein Yalame, Helen Möllering, Hossein Fereidooni, Samuel Marchal, Markus Miettinen, Azalia Mirhoseini, Sadegh Zeitouni, et al. FLAME: Taming backdoors in federated learning. In31st USENIX Security Symposium, pages 1415–1432, 2022
work page 2022
-
[66]
Xutong Mu, Ke Cheng, Yuxin Shen, Xin Li, Zhen Chang, Tao Zhang, and Xiaosong Ma. Fed- DMC: Efficient and robust federated learning via detecting malicious clients.IEEE Transactions on Dependable and Secure Computing, 21(6):5259–5274, 2024
work page 2024
-
[67]
Siquan Huang, Yijiang Li, Chong Chen, Ying Gao, and Xiping Hu. FedID: Enhancing federated learning security through dynamic identification.IEEE Transactions on Pattern Analysis and Machine Intelligence, 47(10):8907–8922, 2025
work page 2025
-
[68]
Isaac Marroqui Penalva, Enrique Tomás Martínez Beltrán, Manuel Gil Pérez, and Alberto Huer- tas Celdrán. RepuNet: A reputation system for mitigating malicious clients in decentralized federated learning.arXiv preprint arXiv:2506.19892, 2025
-
[69]
FLARE: Adaptive Multi-Dimensional Reputation for Robust Client Reliability in Federated Learning,
Abolfazl Younesi, Leon Kiss, Zahra Najafabadi Samani, Juan Aznar Poveda, and Thomas Fahringer. FLARE: Adaptive multi-dimensional reputation for robust client reliability in federated learning.arXiv preprint arXiv:2511.14715, 2025
work page internal anchor Pith review arXiv 2025
-
[70]
Bitcoin: A peer-to-peer electronic cash system, 2008
Satoshi Nakamoto. Bitcoin: A peer-to-peer electronic cash system, 2008
work page 2008
-
[71]
Ethereum white paper.GitHub repository, 1:22–23, 2013
Vitalik Buterin et al. Ethereum white paper.GitHub repository, 1:22–23, 2013
work page 2013
-
[72]
Justin Thaler. Proofs, arguments, and zero-knowledge.Foundations and Trends® in Privacy and Security, 4(2–4):117–660, 2022
work page 2022
-
[73]
Boyuan Feng, Lianke Qin, Zhenfei Zhang, Yufei Ding, and Shumo Chu. ZEN: An optimizing compiler for verifiable, zero-knowledge neural network inferences.Cryptology ePrint Archive, 2021
work page 2021
-
[74]
ZkCNN: Zero-knowledge proofs for convolutional neural network predictions and accuracy
Tianyi Liu, Xiang Xie, and Yupeng Zhang. ZkCNN: Zero-knowledge proofs for convolutional neural network predictions and accuracy. InProceedings of the 2021 ACM SIGSAC Conference on Computer and Communications Security, pages 2968–2985, 2021
work page 2021
-
[75]
Zhibo Xing, Zijian Zhang, Jiamou Liu, Ziang Zhang, Meng Li, Liehuang Zhu, and Giovanni Russello. Zero-knowledge proof meets machine learning in verifiability: A survey.arXiv preprint arXiv:2310.14848, 2023
-
[76]
SecureML: A system for scalable privacy-preserving machine learning
Payman Mohassel and Yupeng Zhang. SecureML: A system for scalable privacy-preserving machine learning. In2017 IEEE Symposium on Security and Privacy (SP), pages 19–38. IEEE, 2017. 14
work page 2017
-
[77]
Seunghwa Lee, Hankyung Ko, Jihye Kim, and Hyunok Oh. vCNN: Verifiable convolutional neu- ral network based on zk-SNARKs.IEEE Transactions on Dependable and Secure Computing, 2024
work page 2024
-
[78]
Mystique: Efficient conversions for Zero-Knowledge proofs with applications to machine learning
Chenkai Weng, Kang Yang, Xiang Xie, Jonathan Katz, and Xiao Wang. Mystique: Efficient conversions for Zero-Knowledge proofs with applications to machine learning. In30th USENIX Security Symposium (USENIX Security 21), pages 501–518, 2021
work page 2021
-
[79]
Interactive proofs for rounding arithmetic.IEEE Access, 10:122706–122725, 2022
Shuo Chen, Jung Hee Cheon, Dongwoo Kim, and Daejun Park. Interactive proofs for rounding arithmetic.IEEE Access, 10:122706–122725, 2022
work page 2022
-
[80]
Succinct zero-knowledge for floating point computations
Sanjam Garg, Abhishek Jain, Zhengzhong Jin, and Yinuo Zhang. Succinct zero-knowledge for floating point computations. InProceedings of the 2022 ACM SIGSAC Conference on Computer and Communications Security, pages 1203–1216, 2022
work page 2022
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.