Recognition: 3 theorem links
· Lean TheoremBeeVe: Unsupervised Acoustic State Discovery in Honey Bee Buzzing
Pith reviewed 2026-05-11 03:23 UTC · model grok-4.3
The pith
Unsupervised learning discovers repeatable acoustic states in honey bee buzzing without labels or predefined units.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
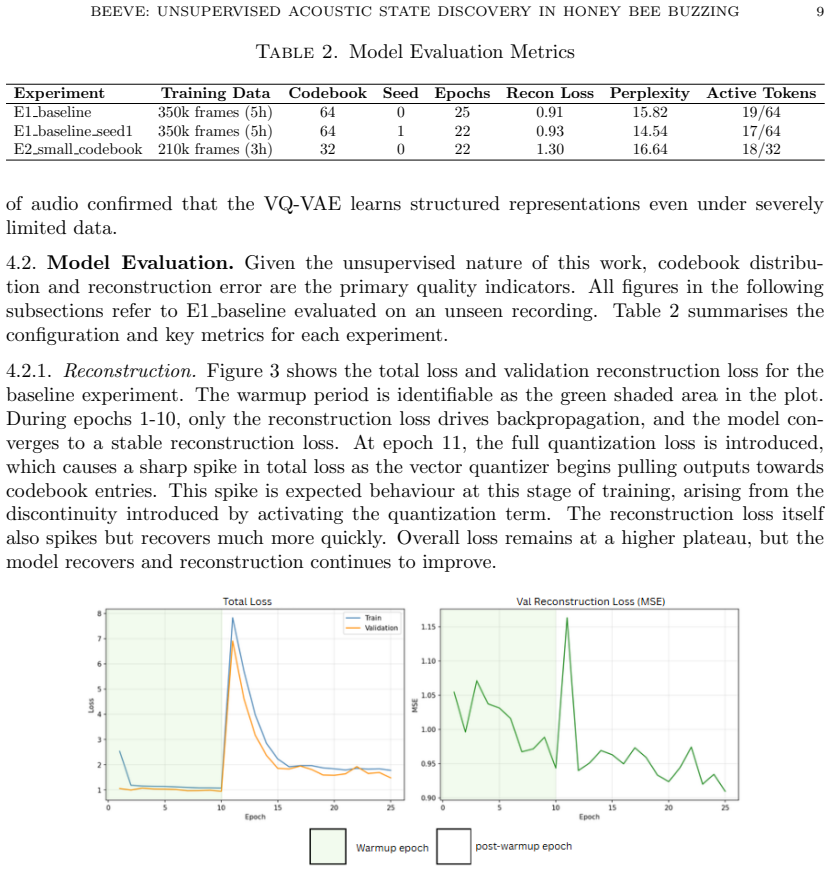
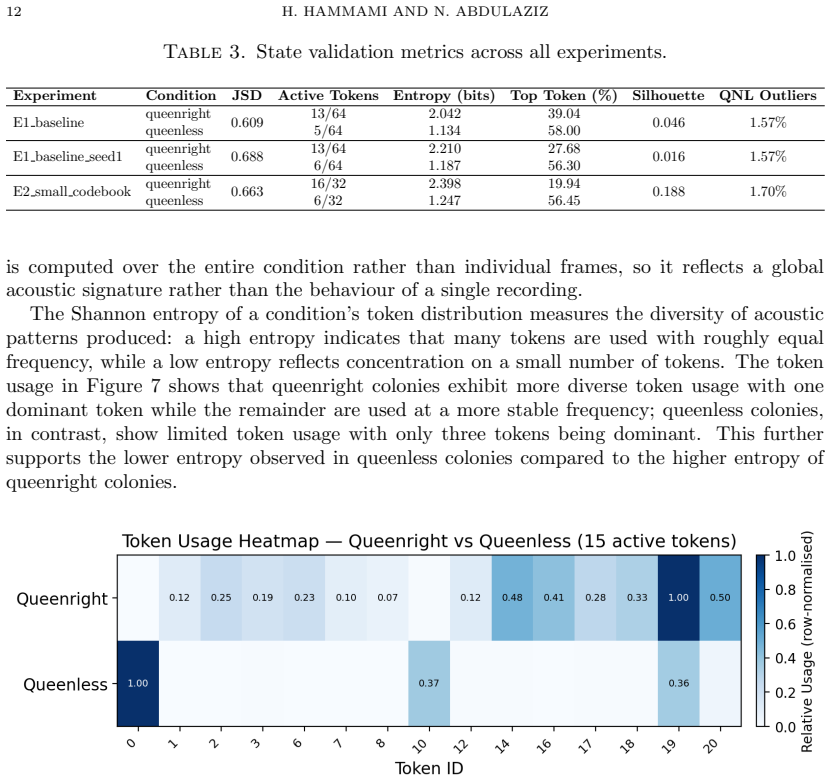
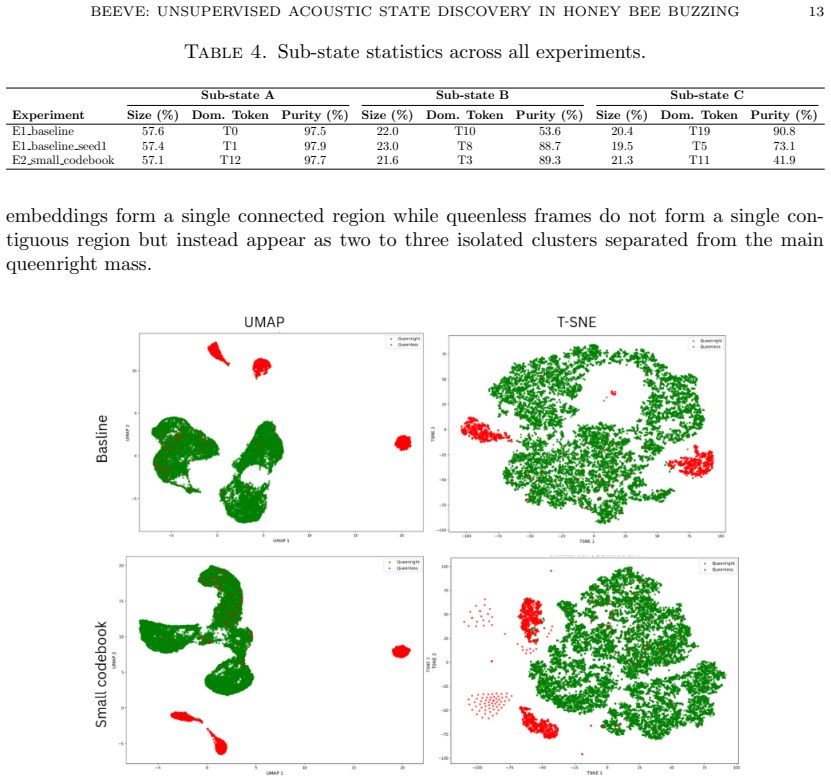
The central discovery is that training a vector-quantized variational autoencoder on embeddings from a frozen self-supervised spectrogram transformer yields a discrete codebook whose tokens capture repeatable acoustic structure in unlabelled honey bee colony sounds. These tokens separate queenright and queenless conditions according to Jensen-Shannon divergence values of 0.609 to 0.688, decompose the queenless state into three coherent sub-states that are stable to changes in codebook size and random initialization, exhibit non-random sequential transitions, and generalize to new recordings with high token overlap.
What carries the argument
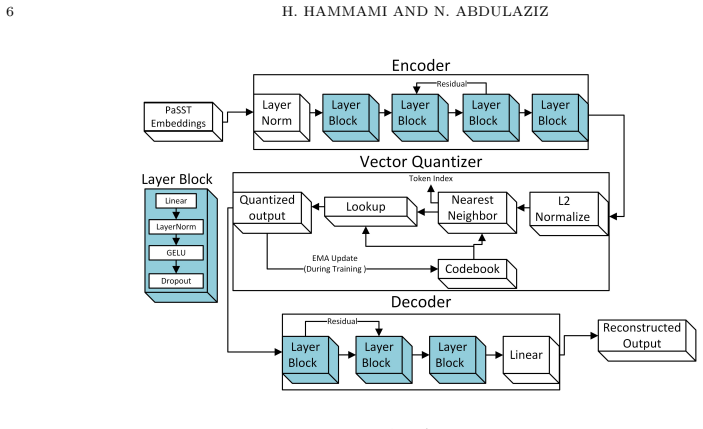
The vector-quantized variational autoencoder applied to frozen spectrogram transformer embeddings to learn a finite set of discrete acoustic tokens directly from unlabeled data.
If this is right
- The tokens distinguish between queenright and queenless hives with measurable divergence in their frequency of use.
- Queenless conditions consistently divide into three sub-states that remain coherent regardless of codebook size or training seed.
- Sequences of tokens display non-random structure across all tested configurations.
- Token assignments generalize to previously unseen recordings while maintaining overlap and overall arrangement.
- This framework supports the development of label-free acoustic systems for monitoring colony conditions.
Where Pith is reading between the lines
- Applying the same tokenization process to audio from other social insects or animal groups could reveal analogous hidden states in their collective behaviors.
- Correlating the discovered tokens with additional colony variables such as brood presence or foraging activity could strengthen the case for their biological meaning.
- The approach might enable continuous, non-invasive tracking of hive health changes over time using only microphone data.
- Testing the tokens on recordings from different hive setups or bee species would check how general the discovered structure is.
Load-bearing premise
The learned tokens reflect actual biological differences in colony state rather than differences in how the audio was recorded or artifacts introduced by the feature extraction model.
What would settle it
Repeating the training on a new set of recordings from hives with independently verified queen status but obtaining no separation in token distributions between queenright and queenless groups would falsify the claim that meaningful states have been discovered.
Figures









read the original abstract
Discovering structure in biological signals without supervision is a fundamental problem in computational intelligence, yet existing bioacoustic methods assume vocal production models or predefined semantic units, leaving non-vocal species poorly served. This work introduces BeeVe, an unsupervised framework for acoustic state discovery in collective honey bee buzzing. BeeVe uses the self-supervised Patchout Spectrogram Transformer (PaSST) as a frozen feature extractor, then trains a Vector-Quantized Variational Autoencoder (VQ-VAE) without labels on those embeddings, learning a finite discrete codebook of acoustic tokens directly from unlabelled hive audio. No labels, pretext tasks, or contrastive objectives are used at any stage. Post-hoc evaluation against known queen status reveals that the learned tokens separate queenright and queenless conditions with Jensen-Shannon Divergence values between 0.609 and 0.688, and that the queenless condition further decomposes into three internally coherent sub-states stable across experiments with different codebook sizes and random seeds. Token transition analysis confirms non-random sequential structure (p << 0.001) across all experiments. Generalisation to unseen recordings preserves both token overlap (Jaccard = 0.947) and global manifold topology. These results demonstrate that unsupervised discrete codebook learning can recover repeatable acoustic structure from a non-vocal biological signal without annotation, opening a path toward non-invasive acoustic hive health monitoring.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces BeeVe, an unsupervised framework that extracts features from unlabeled honey bee buzzing audio using a frozen PaSST model and then trains a VQ-VAE to learn a discrete codebook of acoustic tokens. Post-hoc evaluation against queen status shows separation between queenright and queenless conditions (JSD 0.609–0.688), decomposition of queenless into three stable sub-states across codebook sizes and seeds, non-random token transitions (p << 0.001), and strong generalization to unseen recordings (Jaccard 0.947). The central claim is that this approach recovers repeatable acoustic structure from a non-vocal biological signal without any labels or supervision.
Significance. If the tokens correspond to biologically meaningful colony states, the work would advance unsupervised bioacoustics for collective non-vocal signals and support practical non-invasive hive health monitoring. The combination of frozen self-supervised audio features with VQ-VAE for discrete state discovery, plus reported internal consistency metrics (stability, transitions, generalization), provides a reproducible template worth testing in other bioacoustic domains.
major comments (3)
- [Methods] Methods (data collection and experimental design): No details are provided on the number of hives, recording hardware, microphone placement, time-of-day controls, or environmental covariates. Without these, the post-hoc JSD separation by queen status cannot be distinguished from hive-specific recording artifacts or systematic biases in the frozen PaSST extractor.
- [Results] Results (JSD and sub-state analysis): The reported JSD range (0.609–0.688) and three queenless sub-states are presented as evidence of biologically meaningful discovery, but no ablation holds recording conditions fixed while varying only queen status, nor are permutation tests or baseline comparisons against PaSST biases described. This leaves the central claim vulnerable to the alternative that tokens reflect activity or hardware patterns rather than colony state.
- [Evaluation] Evaluation (generalization and transitions): While Jaccard 0.947 on unseen recordings and p << 0.001 on transitions demonstrate internal consistency, the unseen recordings appear drawn from the same hives/conditions; this does not test external validity against the confounds raised in the skeptic note.
minor comments (2)
- [Abstract] Abstract and results: The exact VQ-VAE training procedure (learning rate, epochs, codebook initialization) and statistical controls for multiple comparisons are not summarized, making it hard to assess reproducibility from the reported metrics alone.
- [Methods] Notation: The distinction between 'queenless sub-states' and the global codebook tokens could be clarified with a diagram or explicit definition in the methods.
Simulated Author's Rebuttal
We thank the referee for their constructive review and for highlighting key areas where additional rigor would strengthen the manuscript. We address each major comment below, indicating where revisions will be made and where limitations of the current dataset prevent full resolution.
read point-by-point responses
-
Referee: [Methods] Methods (data collection and experimental design): No details are provided on the number of hives, recording hardware, microphone placement, time-of-day controls, or environmental covariates. Without these, the post-hoc JSD separation by queen status cannot be distinguished from hive-specific recording artifacts or systematic biases in the frozen PaSST extractor.
Authors: We agree that these methodological details are necessary for proper interpretation and to help readers assess potential confounds. In the revised manuscript we will add a dedicated data collection subsection specifying the number of hives, recording hardware model, microphone placement, time-of-day sampling protocol, and any recorded environmental covariates. This will allow direct evaluation of whether the observed token distributions could arise from recording artifacts. revision: yes
-
Referee: [Results] Results (JSD and sub-state analysis): The reported JSD range (0.609–0.688) and three queenless sub-states are presented as evidence of biologically meaningful discovery, but no ablation holds recording conditions fixed while varying only queen status, nor are permutation tests or baseline comparisons against PaSST biases described. This leaves the central claim vulnerable to the alternative that tokens reflect activity or hardware patterns rather than colony state.
Authors: We will add permutation tests comparing the observed JSD values against distributions obtained from randomly reassigned tokens, and we will include baseline token statistics computed directly on the frozen PaSST embeddings (without VQ-VAE) to isolate the contribution of the discrete codebook. However, an ablation that holds all recording conditions fixed while independently varying only queen status is not feasible with the existing dataset and would require new controlled recordings. revision: partial
-
Referee: [Evaluation] Evaluation (generalization and transitions): While Jaccard 0.947 on unseen recordings and p << 0.001 on transitions demonstrate internal consistency, the unseen recordings appear drawn from the same hives/conditions; this does not test external validity against the confounds raised in the skeptic note.
Authors: We will revise the Evaluation section to explicitly state that the held-out recordings come from the same hives and recording conditions, thereby clarifying that the Jaccard and transition metrics demonstrate internal reproducibility rather than cross-hardware or cross-site generalization. We will also add a limitations paragraph discussing the scope of these results and the need for future multi-site validation. revision: yes
- An ablation holding recording conditions fixed while varying only queen status cannot be performed without new data collection outside the current study.
Circularity Check
No circularity: unsupervised training and post-hoc evaluation are independent
full rationale
The paper trains a VQ-VAE codebook on frozen PaSST embeddings using only unlabelled hive audio with no target variables, labels, or queen-status information at any stage of learning. Token distributions, transitions, and manifold topology are derived directly from the unsupervised objective. Post-hoc JSD separation (0.609–0.688) and stability checks against queen status are computed after training and do not enter the loss, codebook construction, or any reported equation. No self-citation chain, fitted-input renaming, or ansatz smuggling is present in the derivation; the core claim that discrete tokens recover repeatable structure therefore stands on independent content rather than reducing to its own inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- VQ-VAE codebook size
axioms (2)
- domain assumption PaSST embeddings capture relevant structure in non-vocal bioacoustic signals
- domain assumption Discrete tokens from VQ-VAE correspond to repeatable acoustic states
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
BeeVe uses the self-supervised Patchout Spectrogram Transformer (PaSST) as a frozen feature extractor, then trains a Vector-Quantized Variational Autoencoder (VQ-VAE) without labels on those embeddings, learning a finite discrete codebook of acoustic tokens
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Token transition analysis confirms non-random sequential structure (p ≪ 0.001) ... queenless condition further decomposes into three internally coherent sub-states stable across experiments
-
IndisputableMonolith/Foundation/ArithmeticFromLogic.leanembed_strictMono_of_one_lt unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Jensen-Shannon Divergence values between 0.609 and 0.688
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Mahsa Abdollahi, Pierre Giovenazzo, and Tiago H Falk,Automated beehive acoustics monitoring: A com- prehensive review of the literature and recommendations for future work, Applied Sciences12(2022), no. 8, 3920
work page 2022
-
[2]
Mahsa Abdollahi, Yi Zhu, Heitor R Guimar˜ aes, Nico Coallier, S´ egol` ene Maucourt, Pierre Giovenazzo, and Tiago H Falk,Urban: Urban beehive acoustics and phenotyping dataset, Scientific Data12(2025), no. 1, 536. 20 H. HAMMAMI AND N. ABDULAZIZ
work page 2025
-
[3]
Cleiton M Carvalho Jr, ´Icaro de Lima Rodrigues, and Danielo G Gomes,Unsupervised acoustic detection of queenless hives in honeybees (apis mellifera ligustica), Brazilian e-Science Workshop (BreSci), SBC, 2025, pp. 49–56
work page 2025
-
[4]
Christine Erbe and Jeanette A Thomas,Exploring animal behavior through sound: Volume 1: Methods, Springer Nature, 2022
work page 2022
- [5]
-
[6]
W Tecumseh Fitch,The evolution of speech: a comparative review, Trends in cognitive sciences4(2000), no. 7, 258–267
work page 2000
-
[7]
Karl von Frisch,The dance language and orientation of bees, Harvard University Press, 1993
work page 1993
-
[8]
Masato Hagiwara,Aves: Animal vocalization encoder based on self-supervision, ICASSP 2023-2023 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2023, pp. 1–5
work page 2023
-
[9]
Hamze Hammami and Nidhal Abdulaziz,Beebetter: A multi-modal beehive system for honeybee health monitoring and hazard detection, 2024 7th International Conference on Signal Processing and Information Security (ICSPIS), IEEE, 2024, pp. 1–5
work page 2024
-
[10]
Logan S James, Benjamin Hoffman, Jen-Yu Liu, Marius Miron, Milad Alizadeh, Emmanuel Fernandez, Matthieu Geist, Diane Kim, Aza Raskin, Jon T Sakata, et al.,Zebra finch females flexibly communicate with each other and with ai-driven acoustic interaction models, bioRxiv (2026), 2026–02
work page 2026
- [11]
-
[12]
WH Kirchner,Acoustical communication in honeybees, Apidologie24(1993), no. 3, 297–307
work page 1993
- [13]
-
[14]
Axel Michelsen, Wolfgang H Kirchner, and Martin Lindauer,Sound and vibrational signals in the dance language of the honeybee, apis mellifera, Behavioral ecology and sociobiology18(1986), no. 3, 207–212
work page 1986
- [15]
- [16]
- [17]
-
[18]
Eklavya Sarkar and Mathew Magimai Doss,Comparing self-supervised learning models pre-trained on hu- man speech and animal vocalizations for bioacoustics processing, ICASSP 2025-2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2025, pp. 1–5
work page 2025
- [19]
-
[20]
Pratyusha Sharma, Shane Gero, Daniela Rus, Antonio Torralba, and Jacob Andreas,Whalelm: Finding structure and information in sperm whale vocalizations and behavior with machine learning, bioRxiv (2024), 2024–10. School of Engineering and Physical Sciences, Heriot-W att University Dubai Email address:hh2095@hw.ac.uk School of Engineering and Physical Scien...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.