Recognition: 2 theorem links
· Lean TheoremConsistency Regularised Gradient Flows for Inverse Problems
Pith reviewed 2026-05-11 03:18 UTC · model grok-4.3
The pith
A single gradient flow in latent space jointly samples posteriors and optimizes prompts for diffusion-based inverse problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that a unified Euclidean-Wasserstein-2 gradient-flow framework jointly performs posterior sampling and prompt optimization in the latent space through a single flow that aligns the prior and posterior with the observed data. Combined with few-step latent text-to-image models, this formulation enables low-NFE inference without backpropagation through autoencoders, and experiments across several canonical imaging inverse problems show state-of-the-art performance with significantly reduced computational cost.
What carries the argument
The consistency-regularised Euclidean-Wasserstein-2 gradient flow, which carries out joint alignment of prior and posterior distributions in latent space.
If this is right
- State-of-the-art reconstruction quality is obtained on canonical imaging inverse problems.
- Computational cost drops sharply because the method requires only a low number of neural function evaluations.
- Backpropagation through pretrained autoencoders is no longer required.
- Few-step latent text-to-image models become directly usable for inverse-problem inference.
Where Pith is reading between the lines
- The same flow structure could be applied to other latent generative models beyond diffusion if the alignment property holds.
- Real-time or resource-constrained imaging applications might become feasible once the per-problem tuning requirement is removed.
- Extension to non-imaging inverse problems would require verifying that the latent-space Wasserstein term still provides useful regularisation.
Load-bearing premise
A single gradient flow in the combined Euclidean-Wasserstein space will reliably align the generative prior with observed data across different inverse problems without introducing bias or needing problem-specific tuning.
What would settle it
Running the method on a held-out inverse problem (for example, a new noise model or measurement type) and observing either systematic reconstruction bias or the necessity of retuning the consistency regularisation strength for each problem would falsify the unified-framework claim.
Figures






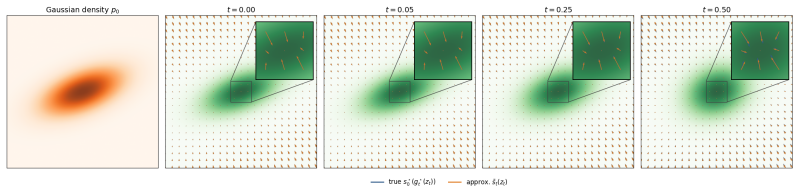


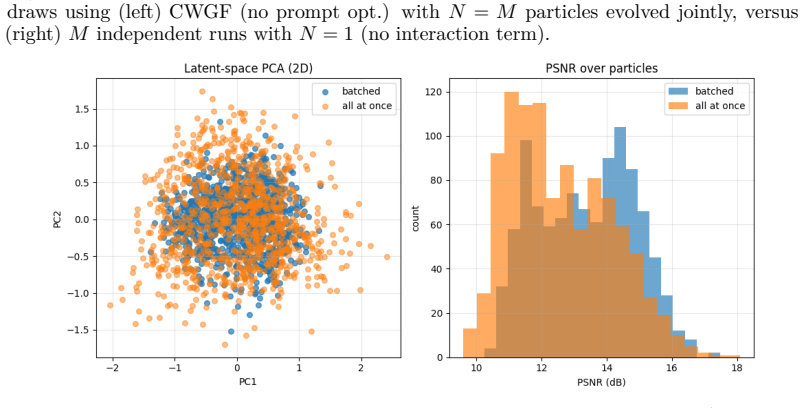
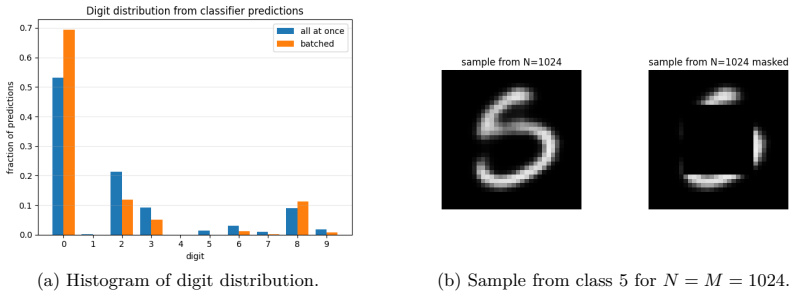
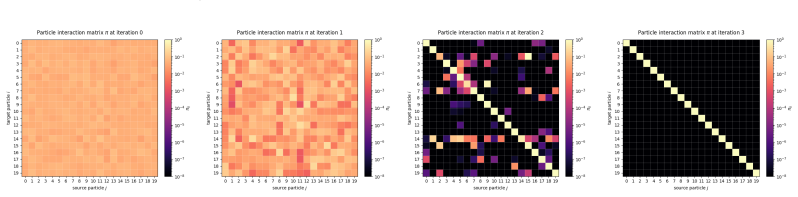

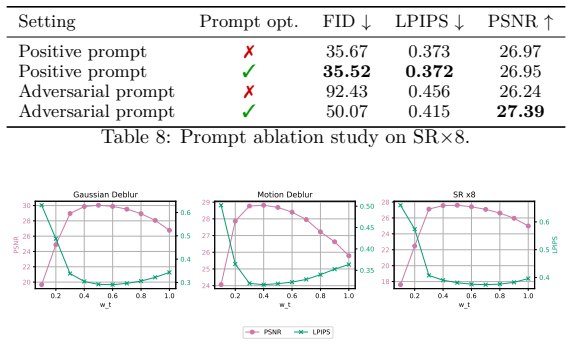

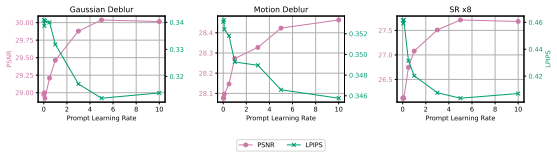
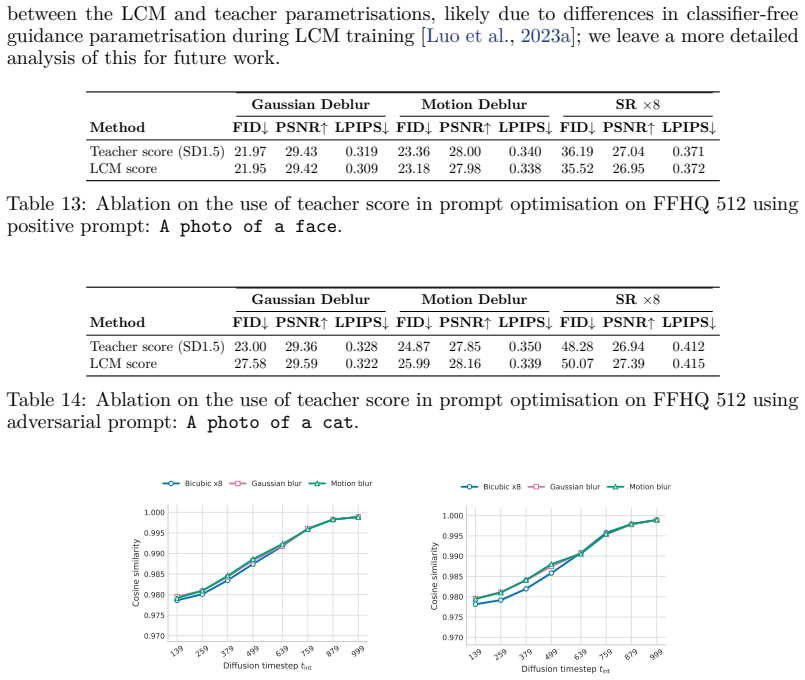



read the original abstract
Vision-Language Latent Diffusion Models (LDMs) (Rombach et al., 2022) provide powerful generative priors for inverse problems. However, existing LDM-based inverse solvers typically require a large number of neural function evaluations (NFEs) and backpropagation through large pretrained components, leading to substantial computational costs and, in some cases, degraded reconstruction quality. We propose a unified Euclidean-Wasserstein-2 gradient-flow framework that jointly performs posterior sampling and prompt optimization in the latent space through a single flow that aligns the prior and posterior with the observed data. Combined with few-step latent text-to-image models, this formulation enables low-NFE inference without backpropagation through autoencoders. Experiments across several canonical imaging inverse problems show that our method achieves state-of-the-art performance with significantly reduced computational cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a unified Euclidean-Wasserstein-2 gradient-flow framework for solving inverse problems with vision-language latent diffusion models. It jointly performs posterior sampling and prompt optimization in latent space through a single flow that aligns the generative prior and posterior with observed data. Combined with few-step latent text-to-image models, the approach enables low-NFE inference without backpropagation through autoencoders. Experiments on canonical imaging inverse problems are reported to achieve state-of-the-art performance with significantly reduced computational cost.
Significance. If the central claims hold, the work offers a practical advance by reducing the number of neural function evaluations and eliminating backpropagation through large pretrained autoencoders in inverse-problem solvers. The unified gradient-flow formulation that combines Euclidean and Wasserstein-2 geometry for joint sampling and prompt optimization is conceptually novel and, if supported by rigorous analysis, could generalize across inverse problems. The emphasis on consistency regularization as a mechanism for alignment without per-problem retuning is a potential strength worth highlighting.
major comments (2)
- [§3.2] §3.2, the consistency-regularized flow equation: The claim that a single flow reliably aligns prior and posterior across inverse problems without bias or problem-specific tuning of the regularization strength is load-bearing for the low-NFE and no-backprop advantages. No explicit bounds or transfer analysis are supplied showing that the Wasserstein-2 term in the combined space prevents mode collapse or approximation error when moving from denoising to inpainting or super-resolution.
- [§5] §5, experimental protocol and tables: The SOTA performance claims rest on comparisons that lack reported standard deviations, number of runs, or ablations isolating the effect of the consistency regularization strength. Without these, it is impossible to confirm that the unified flow, rather than post-hoc choices, produces the reported gains.
minor comments (2)
- [§3.1] Notation for the combined Euclidean-Wasserstein metric is introduced without an explicit definition of the underlying particle discretization or metric tensor; a short appendix clarifying this would improve reproducibility.
- The abstract states 'significantly reduced computational cost' but the main text does not tabulate wall-clock times or NFE counts against the strongest baselines; adding such a table would strengthen the practical claims.
Simulated Author's Rebuttal
We thank the referee for their thoughtful review and constructive comments on our manuscript. We address each of the major comments point by point below, providing clarifications and indicating the revisions we will make to strengthen the paper.
read point-by-point responses
-
Referee: [§3.2] §3.2, the consistency-regularized flow equation: The claim that a single flow reliably aligns prior and posterior across inverse problems without bias or problem-specific tuning of the regularization strength is load-bearing for the low-NFE and no-backprop advantages. No explicit bounds or transfer analysis are supplied showing that the Wasserstein-2 term in the combined space prevents mode collapse or approximation error when moving from denoising to inpainting or super-resolution.
Authors: We appreciate the referee pointing out the need for stronger theoretical support. Our manuscript does not include explicit bounds or transfer analysis for the Wasserstein-2 term's role in preventing mode collapse or approximation errors across problem types. The design of the consistency-regularized flow aims to achieve alignment through the combined Euclidean-Wasserstein-2 geometry, and we demonstrate its effectiveness empirically across denoising, inpainting, and super-resolution without retuning the regularization strength. To address this comment, we will revise the manuscript to include a more detailed discussion of the empirical robustness and explicitly note the lack of theoretical bounds as a limitation and avenue for future research. We believe the practical advantages are supported by the results, but agree that theoretical analysis would further strengthen the claims. revision: partial
-
Referee: [§5] §5, experimental protocol and tables: The SOTA performance claims rest on comparisons that lack reported standard deviations, number of runs, or ablations isolating the effect of the consistency regularization strength. Without these, it is impossible to confirm that the unified flow, rather than post-hoc choices, produces the reported gains.
Authors: We agree that the experimental section would benefit from additional statistical rigor and ablations. In the revised version, we will report standard deviations over multiple runs (specifically, we will rerun experiments 5 times with different random seeds and include the mean and standard deviation for all metrics). Furthermore, we will add an ablation study that varies the consistency regularization strength and shows its impact on performance for different inverse problems. This will help isolate the contribution of the regularization and confirm that the unified flow is responsible for the observed improvements rather than specific hyperparameter choices. revision: yes
Circularity Check
No circularity in proposed gradient-flow framework
full rationale
The paper introduces a new unified Euclidean-Wasserstein-2 gradient-flow framework for joint posterior sampling and prompt optimization in latent diffusion models for inverse problems. The abstract and available description present this as an original methodological formulation that enables low-NFE inference, without any quoted equations or steps that reduce claims to fitted inputs, self-definitions, or load-bearing self-citations by construction. The consistency regularization and alignment properties are positioned as novel contributions rather than re-derivations of prior quantities, making the derivation chain self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe propose a unified Euclidean-Wasserstein-2 gradient-flow framework that jointly performs posterior sampling and prompt optimization in the latent space through a single flow that aligns the prior and posterior with the observed data.
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearOur method achieves SOTA performance in only 16 NFEs
Reference graph
Works this paper leans on
-
[1]
Efficient prior calibration from indirect data , volume =
Akyildiz, O Deniz and Girolami, Mark and Stuart, Andrew M and Vadeboncoeur, Arnaud , journal =. Efficient prior calibration from indirect data , volume =
-
[2]
A multiscale perspective on maximum marginal likelihood estimation , year =
Akyildiz, O Deniz and Ottobre, Michela and Souttar, Iain , journal =. A multiscale perspective on maximum marginal likelihood estimation , year =
-
[3]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
A general framework for updating belief distributions , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2016 , publisher=
work page 2016
-
[4]
Dpm-solver: A fast ode solver for diffusion probabilistic model sampling in around 10 steps
Lu, Cheng and Zhou, Yuhao and Bao, Fan and Chen, Jianfei and Li, Chongxuan and Zhu, Jun , year = 2022, month = oct, number =. arXiv , language =:2206.00927 , primaryclass =
-
[5]
Neural Empirical Bayes , journal =
Saeed Saremi and Aapo Hyv. Neural Empirical Bayes , journal =. 2019 , volume =
work page 2019
-
[6]
Pavliotis, Grigorios A. and Stuart, Andrew M. , pages =. Averaging for ODEs and SDEs , year =
-
[7]
A PRIMER ON MONOTONE OPERATOR METHODS SURVEY , volume =
Ryu, Ernest and Boyd, Stephen , year =. A PRIMER ON MONOTONE OPERATOR METHODS SURVEY , volume =
-
[8]
Gianazza, Ugo and Savaré, Giuseppe and Toscani, Giuseppe , year =. The Wasserstein Gradient Flow of the Fisher Information and the Quantum Drift-diffusion Equation , volume =. Archive for Rational Mechanics and Analysis , doi =
-
[9]
Transactions on Machine Learning Research , year =
Tweedie Moment Projected Diffusions For Inverse Problems , author =. Transactions on Machine Learning Research , year =
-
[10]
Elucidating the Design Space of Diffusion-Based Generative Models
Karras, Tero and Aittala, Miika and Aila, Timo and Laine, Samuli , year = 2022, month = jun, journal =. Elucidating the. doi:10.48550/arXiv.2206.00364 , urldate =. arXiv , language =:2206.00364 , primaryclass =
work page internal anchor Pith review doi:10.48550/arxiv.2206.00364 2022
-
[11]
Huang, Yukun and Wang, Jianan and Shi, Yukai and Tang, Boshi and Qi, Xianbiao and Zhang, Lei , year = 2023, month = oct, urldate =. The
work page 2023
-
[12]
arXiv preprint arXiv:2601.21200 , year=
Provably Reliable Classifier Guidance via Cross-Entropy Control , author =. doi:10.48550/arXiv.2601.21200 , urldate =. arXiv , language =:2601.21200 , primaryclass =
-
[13]
Gradient flows: in metric spaces and in the space of probability measures , year =
Ambrosio, Luigi and Gigli, Nicola and Savar. Gradient flows: in metric spaces and in the space of probability measures , year =
-
[14]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year =
Mirror and Preconditioned Gradient Descent in Wasserstein Space , author =. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year =
-
[15]
Thirty-seventh Conference on Neural Information Processing Systems , year =
Particle-based Variational Inference with Generalized Wasserstein Gradient Flow , author =. Thirty-seventh Conference on Neural Information Processing Systems , year =
-
[16]
doi:10.48550/arXiv.2211.13954 , urldate =
Particle-Based Variational Inference with Preconditioned Functional Gradient Flow , author =. doi:10.48550/arXiv.2211.13954 , urldate =. arXiv , language =:2211.13954 , primaryclass =
-
[17]
Generative Modeling via Drifting
Deng, Mingyang and Li, He and Li, Tianhong and Du, Yilun and He, Kaiming , year = 2026, month = feb, number =. Generative. doi:10.48550/arXiv.2602.04770 , urldate =. arXiv , keywords =:2602.04770 , primaryclass =
work page internal anchor Pith review doi:10.48550/arxiv.2602.04770 2026
-
[18]
Karris, Nicholas and Durell, Luke and Flores, Javier and Emerson, Tegan , year = 2025, month = nov, number =. Which. doi:10.48550/arXiv.2511.12757 , urldate =. arXiv , keywords =:2511.12757 , primaryclass =
-
[19]
Levi, Meir Yossef and Gilboa, Guy , year = 2025, month = may, number =. The. doi:10.48550/arXiv.2411.14517 , urldate =. arXiv , keywords =:2411.14517 , primaryclass =
-
[20]
Isambard-AI: a leadership class supercomputer optimised specifically for Artificial Intelligence , author=. 2024 , eprint=
work page 2024
-
[21]
arXiv preprint arXiv:2602.04663 , year=
Choi, Jaemoo and Zhu, Yuchen and Guo, Wei and Molodyk, Petr and Yuan, Bo and Bai, Jinbin and Xin, Yi and Tao, Molei and Chen, Yongxin , year = 2026, month = feb, number =. Rethinking the Design Space of Reinforcement Learning for Diffusion Models: On the Importance of Likelihood Estimation beyond Loss Design , shorttitle =. doi:10.48550/arXiv.2602.04663 ,...
-
[22]
The Eleventh International Conference on Learning Representations , year =
Sampling is as easy as learning the score: theory for diffusion models with minimal data assumptions , author =. The Eleventh International Conference on Learning Representations , year =
-
[23]
Kolmogorov equations in Rd with unbounded coefficients , booktitle =. 2001 , publisher =
work page 2001
-
[24]
Stochastic Numerics for Mathematical Physics , author =. 2021 , publisher =
work page 2021
-
[25]
Milstein, G. N. , title =. Numerical Integration of Stochastic Differential Equations , year =
-
[26]
Weak Error Analysis for Strong Approximation Schemes of
Wang, Xiaojie and Zhao, Yuying and Zhang, Zhongqiang , year = 2024, month = sep, journal =. Weak Error Analysis for Strong Approximation Schemes of. doi:10.1093/imanum/drad083 , language =
-
[27]
Journal of Evolution Equations , volume =
A Trotter product formula for gradient flows in metric spaces , author =. Journal of Evolution Equations , volume =. 2011 , publisher =
work page 2011
-
[28]
Journal of Machine Learning Research , volume =
Wasserstein Convergence Guarantees for a General Class of Score-Based Generative Models , author =. Journal of Machine Learning Research , volume =
-
[29]
Sitan Chen and Sinho Chewi and Holden Lee and Yuanzhi Li and Jianfeng Lu and Adil Salim , booktitle =. The probability flow
-
[30]
Proceedings of the 41st International Conference on Machine Learning , pages =
Sampling is as easy as keeping the consistency: convergence guarantee for Consistency Models , author =. Proceedings of the 41st International Conference on Machine Learning , pages =. 2024 , editor =
work page 2024
-
[31]
Multi-Step Consistency Models: Fast Generation with Theoretical Guarantees , author =. 2025 , eprint =
work page 2025
- [32]
-
[33]
Bulletin of the American mathematical society , volume=
The brunn-minkowski inequality , author=. Bulletin of the American mathematical society , volume=
-
[34]
The Fourteenth International Conference on Learning Representations , year =
The Spacetime of Diffusion Models: An Information Geometry Perspective , author =. The Fourteenth International Conference on Learning Representations , year =
-
[35]
Rocco Caprio and Juan Kuntz and Samuel Power and Adam M. Johansen , title =. Journal of Machine Learning Research , year =
-
[36]
Parametric Fokker-Planck Equation , isbn =
Li, Wuchen and Liu, Shu and Zha, Hongyuan and Zhou, Haomin , year =. Parametric Fokker-Planck Equation , isbn =. doi:10.1007/978-3-030-26980-7_74 , booktitle =
- [37]
-
[38]
Proceedings of the 31st Conference On Learning Theory , pages =
Sampling as optimization in the space of measures: The Langevin dynamics as a composite optimization problem , author =. Proceedings of the 31st Conference On Learning Theory , pages =. 2018 , editor =
work page 2018
-
[39]
The Thirteenth International Conference on Learning Representations , year =
The Superposition of Diffusion Models Using the It\^o Density Estimator , author =. The Thirteenth International Conference on Learning Representations , year =
-
[40]
Normalizing Flows for Probabilistic Modeling and Inference , author =. 2021 , eprint =
work page 2021
-
[41]
Trajectory Consistency Distillation: Improved Latent Consistency Distillation by Semi-Linear Consistency Function with Trajectory Mapping , author =. 2024 , eprint =
work page 2024
-
[42]
Annealed Stein Variational Gradient Descent , author =. 2021 , eprint =
work page 2021
-
[43]
Wang, Yifei and Bai, Weimin and Zhang, Colin and Zhang, Debing and Luo, Weijian and Sun, He , year = 2025, month = oct, number =. Uni-Instruct: One-Step Diffusion Model through Unified Diffusion Divergence Instruction , shorttitle =. doi:10.48550/arXiv.2505.20755 , urldate =. arXiv , language =:2505.20755 , primaryclass =
-
[44]
Gradient Flows: In Metric Spaces and in the Space of Probability Measures , author =. 2008 , publisher =
work page 2008
-
[45]
Posterior sampling via Langevin dynamics based on generative priors , author =. 2024 , eprint =
work page 2024
-
[46]
Variational Flow Maps: Make Some Noise for One-Step Conditional Generation , shorttitle =
Mammadov, Abbas and Takao, So and Chen, Bohan and Baptista, Ricardo and Mardani, Morteza and Teh, Yee Whye and Berner, Julius , year = 2026, month = mar, number =. Variational Flow Maps: Make Some Noise for One-Step Conditional Generation , shorttitle =. doi:10.48550/arXiv.2603.07276 , urldate =. arXiv , language =:2603.07276 , primaryclass =
-
[47]
Advances in Neural Information Processing Systems , volume =
Divide-and-conquer posterior sampling for denoising diffusion priors , author =. Advances in Neural Information Processing Systems , volume =
-
[48]
Guess & Guide: Gradient-Free Zero-Shot Diffusion Guidance , shorttitle =
Shtanchaev, Abduragim and Ilina, Albina and Janati, Yazid and Asadulaev, Arip and Tak. Guess & Guide: Gradient-Free Zero-Shot Diffusion Guidance , shorttitle =. doi:10.48550/arXiv.2603.07860 , urldate =. arXiv , language =:2603.07860 , primaryclass =
-
[49]
How to build a consistency model: Learning flow maps via self-distillation , author =. 2025 , eprint =
work page 2025
-
[50]
Zheng, L. Fast and. doi:10.48550/arXiv.2602.07102 , urldate =. arXiv , keywords =:2602.07102 , primaryclass =
-
[51]
Flow map matching with stochastic interpolants: A mathematical framework for consistency models , author =. 2025 , eprint =
work page 2025
-
[52]
doi:10.48550/arXiv.2603.06685 , urldate =
One Step Further with Monte-Carlo Sampler to Guide Diffusion Better , author =. doi:10.48550/arXiv.2603.06685 , urldate =. arXiv , language =:2603.06685 , primaryclass =
-
[53]
Monte Carlo guided Denoising Diffusion models for Bayesian linear inverse problems
Gabriel Cardoso and Yazid Janati el idrissi and Sylvain Le Corff and Eric Moulines , booktitle =. Monte Carlo guided Denoising Diffusion models for Bayesian linear inverse problems. , year =
-
[54]
arXiv preprint arXiv:2506.03979 , keywords =
Solving Inverse Problems via Diffusion-Based Priors: An Approximation-Free Ensemble Sampling Approach , urldate =. arXiv preprint arXiv:2506.03979 , keywords =. doi:10.48550/arXiv.2506.03979 , eprint =
-
[55]
Regularization by Texts for Latent Diffusion Inverse Solvers , author =. 2025 , eprint =
work page 2025
- [56]
-
[57]
Second order analysis on (P 2 (M),W 2 ) , volume =
Gigli, Nicola , year =. Second order analysis on (P 2 (M),W 2 ) , volume =. Memoirs of the American Mathematical Society , doi =
-
[58]
doi:10.48550/arXiv.1807.01750 , urldate =
Understanding and Accelerating Particle-Based Variational Inference , author =. doi:10.48550/arXiv.1807.01750 , urldate =. arXiv , language =:1807.01750 , primaryclass =
-
[59]
An introduction to optimization on smooth manifolds , author =. 2023 , doi =
work page 2023
-
[60]
Neural Information Processing Systems , eprint =
Maximum Likelihood Training of Score-Based Diffusion Models , author =. Neural Information Processing Systems , eprint =. doi:10.48550/arXiv.2101.09258 , urldate =
-
[61]
Neal, Radford M. and Hinton, Geoffrey E. , editor =. A View of the Em Algorithm that Justifies Incremental, Sparse, and other Variants , year =
-
[62]
doi:10.48550/arXiv.2408.02993 , urldate =
Zhong, Yiming and Zhang, Xiaolin and Zhao, Yao and Wei, Yunchao , year = 2025, month = jan, number =. doi:10.48550/arXiv.2408.02993 , urldate =. arXiv , language =:2408.02993 , primaryclass =
-
[63]
doi:10.48550/arXiv.2506.09416 , urldate =
Noise Conditional Variational Score Distillation , author =. doi:10.48550/arXiv.2506.09416 , urldate =. arXiv , language =:2506.09416 , primaryclass =
-
[64]
doi:10.1609/aaai.v39i7.32828 , urldate =
Wang, He and Dai, Longquan and Tang, Jinhui , year = 2025, month = apr, journal =. doi:10.1609/aaai.v39i7.32828 , urldate =
- [65]
-
[66]
doi:10.48550/arXiv.2502.04320 , urldate =
Helbling, Alec and Meral, Tuna Han Salih and Hoover, Ben and Yanardag, Pinar and Chau, Duen Horng , year = 2025, month = jul, number =. doi:10.48550/arXiv.2502.04320 , urldate =. arXiv , language =:2502.04320 , primaryclass =
-
[67]
doi:10.48550/arXiv.2512.10524 , urldate =
Mode-Seeking for Inverse Problems with Diffusion Models , author =. doi:10.48550/arXiv.2512.10524 , urldate =. arXiv , language =:2512.10524 , primaryclass =
-
[68]
Learning Transferable Visual Models From Natural Language Supervision , author =. 2021 , eprint =
work page 2021
-
[69]
THE GEOMETRY OF DISSIPATIVE EVOLUTION EQUATIONS: THE POROUS MEDIUM EQUATION , volume =
Felix Otto , journal =. THE GEOMETRY OF DISSIPATIVE EVOLUTION EQUATIONS: THE POROUS MEDIUM EQUATION , volume =
-
[70]
doi:10.48550/arXiv.2501.11746 , urldate =
Raphaeli, Ron and Man, Sean and Elad, Michael , year = 2025, month = jan, number =. doi:10.48550/arXiv.2501.11746 , urldate =. arXiv , language =:2501.11746 , primaryclass =
-
[71]
Diffusion Posterior Sampling for General Noisy Inverse Problems , year =
Hyungjin Chung and Jeongsol Kim and Michael Thompson Mccann and Marc Louis Klasky and Jong Chul Ye , booktitle =. Diffusion Posterior Sampling for General Noisy Inverse Problems , year =
-
[72]
Diverse Sampling with Diffusion Models , author =
Particle Guidance: non-I.I.D. Diverse Sampling with Diffusion Models , author =. The Twelfth International Conference on Learning Representations , year =
-
[73]
Francesca R. Crucinio and Valentin. Solving a class of Fredholm integral equations of the first kind via Wasserstein gradient flows , journal =. 2024 , issn =
work page 2024
-
[74]
Diffusion Posterior Sampling for Linear Inverse Problem Solving: A Filtering Perspective , year =
Zehao Dou and Yang Song , booktitle =. Diffusion Posterior Sampling for Linear Inverse Problem Solving: A Filtering Perspective , year =
-
[75]
Density Functional Theory: An Advanced Course , year =
Engel, Eberhard and Dreizler, Reiner M and Dreizler, Reiner M , copyright =. Density Functional Theory: An Advanced Course , year =
-
[76]
An invitation to optimal transport, Wasserstein distances, and gradient flows , year =
Figalli, Alessio and Glaudo, Federico , booktitle =. An invitation to optimal transport, Wasserstein distances, and gradient flows , year =
-
[77]
Mean Flows for One-step Generative Modeling
Mean Flows for One-step Generative Modeling , year =. arXiv , author =:2505.13447 , journal =
work page internal anchor Pith review arXiv
-
[78]
The Twelfth International Conference on Learning Representations , year =
Hagemann, Paul and Hertrich, Johannes and Altekrüger, Fabian and Beinert, Robert and Chemseddine, Jannis and Steidl, Gabriele , title =. The Twelfth International Conference on Learning Representations , year =
-
[79]
GANs trained by a two time-scale update rule converge to a local nash equilibrium , year =
Heusel, Martin and Ramsauer, Hubert and Unterthiner, Thomas and Nessler, Bernhard and Hochreiter, Sepp , booktitle =. GANs trained by a two time-scale update rule converge to a local nash equilibrium , year =
-
[80]
arXiv preprint arXiv:2507.05604 , keywords =
Kernel Density Steering: Inference-Time Scaling via Mode Seeking for Image Restoration , urldate =. arXiv preprint arXiv:2507.05604 , keywords =. doi:10.48550/arXiv.2507.05604 , eprint =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.