Recognition: 2 theorem links
· Lean TheoremOne Token Per Frame: Reconsidering Visual Bandwidth in World Models for VLA Policy
Pith reviewed 2026-05-12 02:50 UTC · model grok-4.3
The pith
A world model for VLA policies can use just one visual token per frame without losing long-horizon accuracy.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
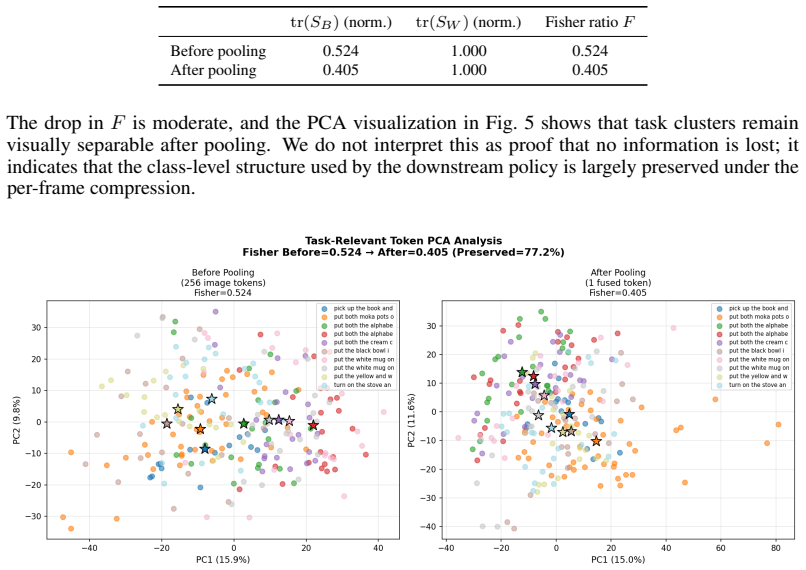
OneWM-VLA reduces each view to a single semantic token per frame through Adaptive Attention Pooling and produces the latent stream and action trajectory under a single flow-matching objective, empirically allowing per-frame visual bandwidth to drop to one token without compromising long-horizon performance under the reported setup.
What carries the argument
Adaptive Attention Pooling, which condenses each frame's visual features into one semantic token that supplies the information needed for both world-model rollouts and action planning inside the shared flow-matching process.
If this is right
- Per-frame visual bandwidth in world-model-augmented VLA systems can be reduced to one token while preserving performance on long-horizon tasks.
- A unified flow-matching objective can jointly optimize latent dynamics and action generation without requiring a separate decoder.
- With 14.71M LoRA parameters on a frozen 2B backbone, average success rises from 47.9% to 61.3% on MetaWorld MT50.
- The same single-token design reaches 95.6% on LIBERO-Long and 60% on real-world Fold Cloth, exceeding the baseline π0 model.
Where Pith is reading between the lines
- Lower per-frame bandwidth could allow world models to process higher frame rates or run on hardware with tighter memory limits.
- The compression might apply to other multimodal planning domains where full visual detail is redundant for future-state prediction.
- Future experiments could check whether the single-token approach continues to hold for horizons longer than those tested or for environments with greater visual complexity.
Load-bearing premise
The single semantic token produced by Adaptive Attention Pooling retains every piece of visual information required for accurate long-horizon state prediction and action planning.
What would settle it
Training both a single-token version and a multi-token version on the same long-horizon task with identical data and hyperparameters, then observing substantially lower success rates for the single-token model, would falsify the central claim.
Figures




read the original abstract
Vision-language-action (VLA) models increasingly rely on auxiliary world modules to plan over long horizons, yet how such modules should be parameterized on top of a pretrained VLA remains an open design question. Existing world-model-augmented VLAs typically pass the per-frame visual stream into the world module at high visual bandwidth and treat its rollout as a side product of action prediction; under a constrained adaptation budget on a frozen backbone, this leaves both the per-frame representation and the latent action coupling under-examined. We introduce OneWM-VLA, which compresses each view into a single semantic token per frame through an Adaptive Attention Pooling, and produces the resulting latent stream and the action trajectory under a single flow-matching objective rather than connecting them through a separate decoder. Empirically, we find that per-frame visual bandwidth can be reduced to a single token without compromising long-horizon performance under our setup. Trained with 14.71M LoRA parameters on a $\pi_0$ (2B) backbone, OneWM-VLA improves the average success rate from 47.9% to 61.3% on MetaWorld~MT50, reaches 95.6% on LIBERO-Long (vs.85.2% for $\pi_0$), and reaches 60.0% on the long-horizon deformable task Fold Cloth on a real Piper arm (vs.20.0% for $\pi_0$).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces OneWM-VLA, which compresses each visual frame into a single semantic token via Adaptive Attention Pooling for the world model component of a VLA policy. It jointly optimizes the resulting latent stream and action trajectory under a flow-matching objective on a frozen π₀ (2B) backbone using 14.71M LoRA parameters. The central empirical claim is that this one-token-per-frame representation maintains long-horizon performance, with reported gains from 47.9% to 61.3% average success on MetaWorld MT50, 85.2% to 95.6% on LIBERO-Long, and 20.0% to 60.0% on the real-robot Fold Cloth task.
Significance. If the result holds under proper controls, the work would demonstrate that high per-frame visual bandwidth is unnecessary for effective world-model-augmented VLA planning, enabling more parameter-efficient long-horizon policies. The reported task-success improvements are quantitatively substantial, but the absence of direct world-model fidelity metrics (latent prediction error, multi-step rollout consistency) limits the ability to attribute gains specifically to improved world modeling rather than action prediction.
major comments (2)
- [Experiments] Experiments section: the reported success-rate improvements on MetaWorld MT50, LIBERO-Long, and Fold Cloth are presented without error bars, statistical significance tests, details on baseline re-implementations, or ablations of the Adaptive Attention Pooling and flow-matching components; this prevents verification that the one-token compression is responsible for the gains rather than training variance or implementation differences.
- [Results / World Model Evaluation] The central claim that the single semantic token 'retains all information required for accurate long-horizon state prediction' is supported only by downstream task success; no quantitative evaluation of world-model rollout fidelity (latent prediction error, frame reconstruction, or multi-step consistency) is provided comparing the one-token representation against higher-bandwidth baselines, leaving open the possibility that gains arise from the action-prediction pathway alone.
minor comments (1)
- [Method] Notation for the Adaptive Attention Pooling module and the flow-matching objective should be introduced with explicit equations in the method section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline planned revisions to improve experimental rigor and evaluation clarity.
read point-by-point responses
-
Referee: [Experiments] Experiments section: the reported success-rate improvements on MetaWorld MT50, LIBERO-Long, and Fold Cloth are presented without error bars, statistical significance tests, details on baseline re-implementations, or ablations of the Adaptive Attention Pooling and flow-matching components; this prevents verification that the one-token compression is responsible for the gains rather than training variance or implementation differences.
Authors: We agree that the current results would benefit from greater statistical detail and component ablations to strengthen attribution to the one-token-per-frame design. In the revised manuscript, we will add error bars (standard deviations over multiple random seeds), report statistical significance tests for the observed improvements, provide expanded details on baseline re-implementations for reproducibility, and include ablations that isolate Adaptive Attention Pooling and the unified flow-matching objective. These will be incorporated into the Experiments section. revision: yes
-
Referee: [Results / World Model Evaluation] The central claim that the single semantic token 'retains all information required for accurate long-horizon state prediction' is supported only by downstream task success; no quantitative evaluation of world-model rollout fidelity (latent prediction error, frame reconstruction, or multi-step consistency) is provided comparing the one-token representation against higher-bandwidth baselines, leaving open the possibility that gains arise from the action-prediction pathway alone.
Authors: We acknowledge that our evaluation centers on downstream task success rather than standalone world-model fidelity metrics. This aligns with the paper's focus on the world model's role as an auxiliary module for improving long-horizon VLA performance under a joint flow-matching objective. The substantial gains on long-horizon benchmarks support the effectiveness of the compressed representation for planning. To address the concern, we will add quantitative latent prediction error metrics on held-out data and multi-step rollout consistency examples in the revised version, enabling direct comparison to higher-bandwidth baselines where feasible. revision: partial
Circularity Check
No circularity: empirical result from training and evaluation
full rationale
The paper presents its core finding—that a single semantic token per frame suffices for long-horizon VLA performance—as a direct outcome of training and benchmarking OneWM-VLA on MetaWorld MT50, LIBERO-Long, and Fold Cloth tasks. No mathematical derivation, fitted parameter renamed as prediction, or self-referential definition appears in the provided text; the Adaptive Attention Pooling and flow-matching objective are architectural choices whose effects are measured externally via task success rates rather than being tautological with the inputs. The result is therefore self-contained against the reported empirical benchmarks.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearWe introduce OneWM-VLA, which compresses each view into a single semantic token per frame through an Adaptive Attention Pooling, and produces the resulting latent stream and the action trajectory under a single flow-matching objective
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclearper-frame visual bandwidth can be reduced to a single token without compromising long-horizon performance
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.