Recognition: no theorem link
Ask Early, Ask Late, Ask Right: When Does Clarification Timing Matter for Long-Horizon Agents?
Pith reviewed 2026-05-11 03:20 UTC · model grok-4.3
The pith
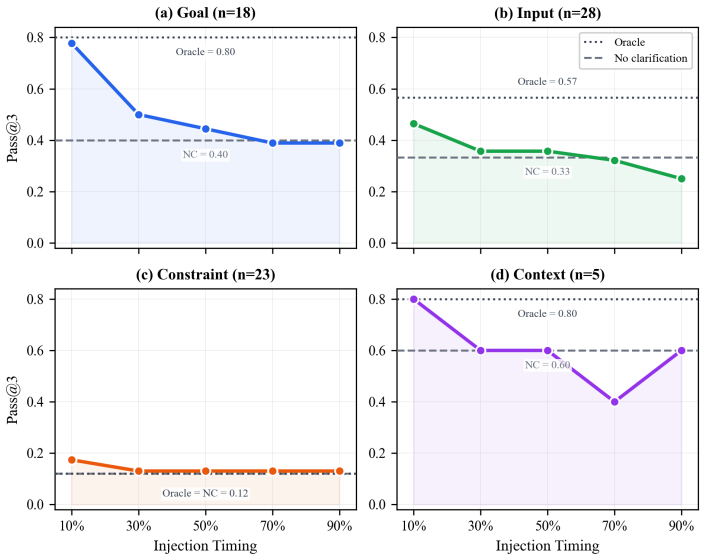
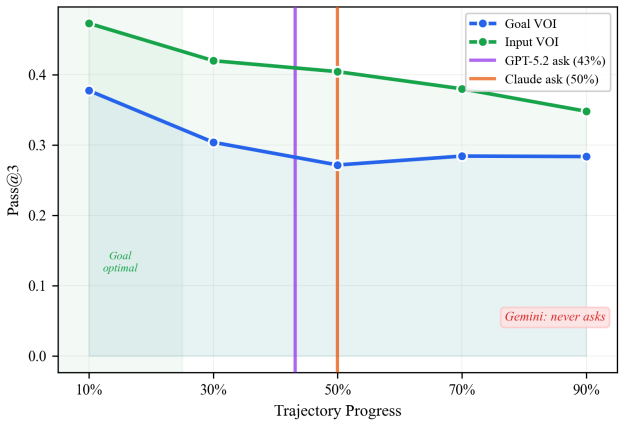
Clarification timing in long-horizon agents matters sharply by information type, with goal details losing nearly all value after 10 percent of execution while input details remain useful to 50 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Across four information dimensions, three benchmarks, and multiple frontier models, goal clarification value collapses after roughly 10 percent of execution while input clarification retains value through about 50 percent; deferring any clarification past the midpoint degrades performance below the never-ask baseline, and these timing profiles show high consistency across models on shared tasks.
What carries the argument
The forced-injection framework that supplies ground-truth answers to clarification queries at fixed fractions of the agent's execution trajectory.
If this is right
- Agents must treat different missing-information types with separate timing rules rather than a uniform early-is-better policy.
- Performance drops below the never-ask level once any clarification is delayed past mid-trajectory.
- Timing profiles are largely determined by task structure rather than by model choice.
- Existing models currently ask outside the useful windows in the majority of sessions.
Where Pith is reading between the lines
- Agents could benefit from internal progress estimators that trigger type-specific clarification requests before windows close.
- The same timing data could guide training objectives that penalize both over-asking and under-asking at the wrong stages.
- Extending the method to open-ended user interactions would test whether human responses follow the same value curves.
Load-bearing premise
Providing perfect answers at chosen moments accurately mimics what would occur if the agent naturally asked and received real responses at those same points.
What would settle it
Measure whether real human clarifications supplied only at the moments when agents actually ask produce the same performance curves as the forced-injection results.
Figures


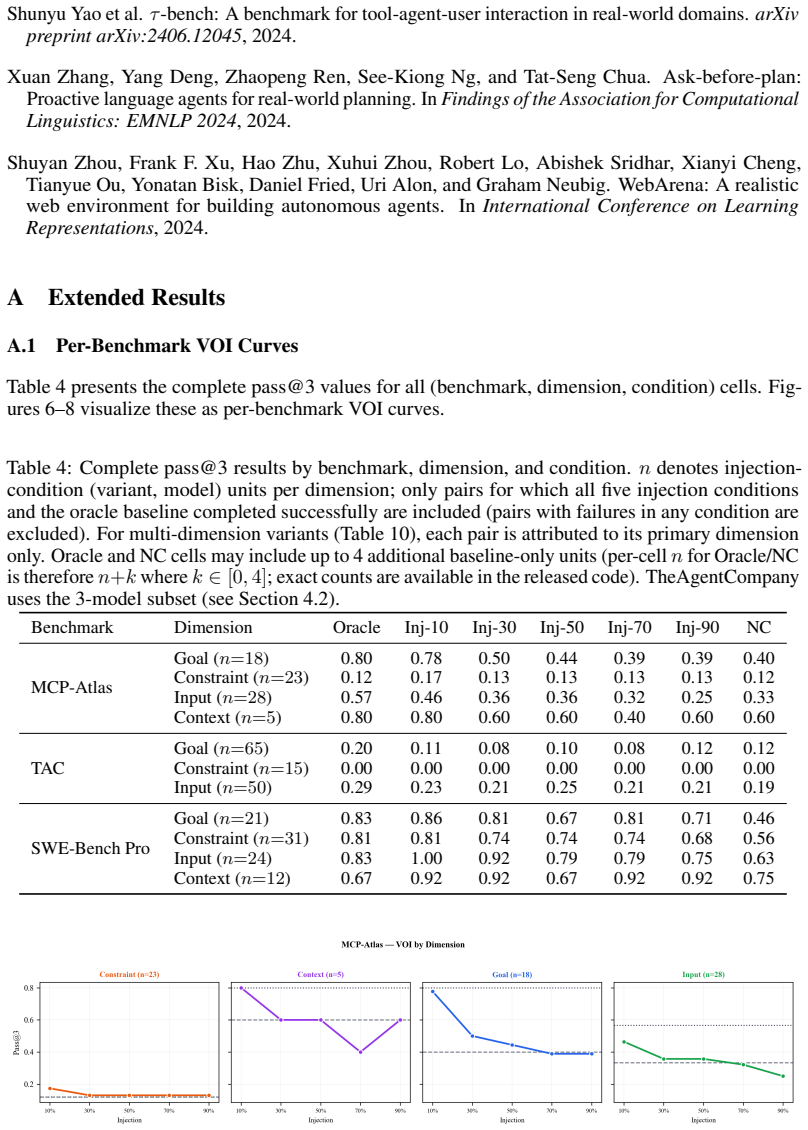


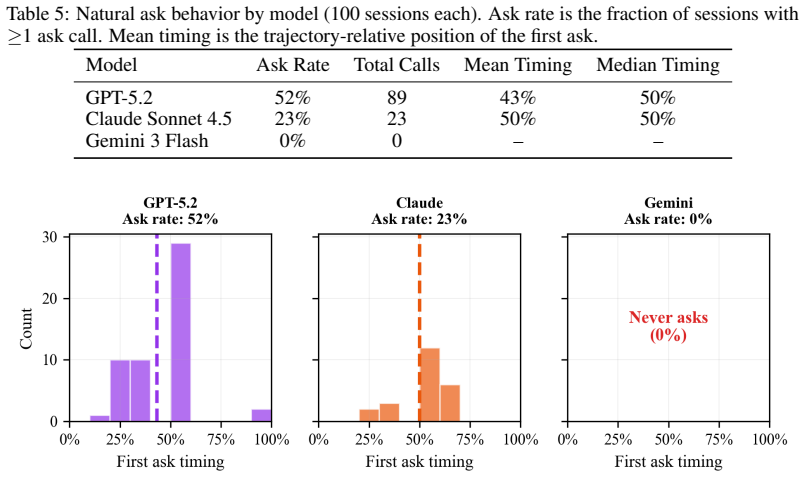
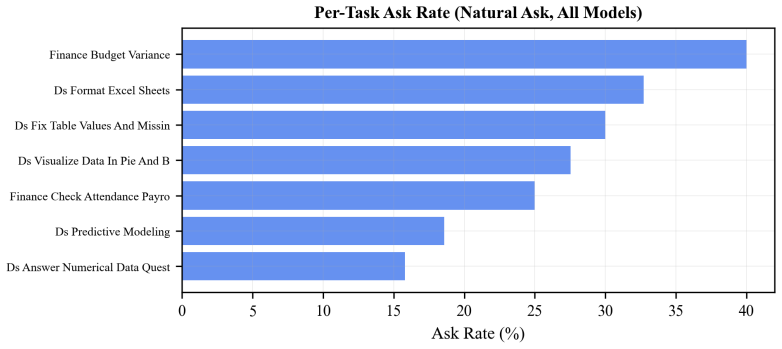



read the original abstract
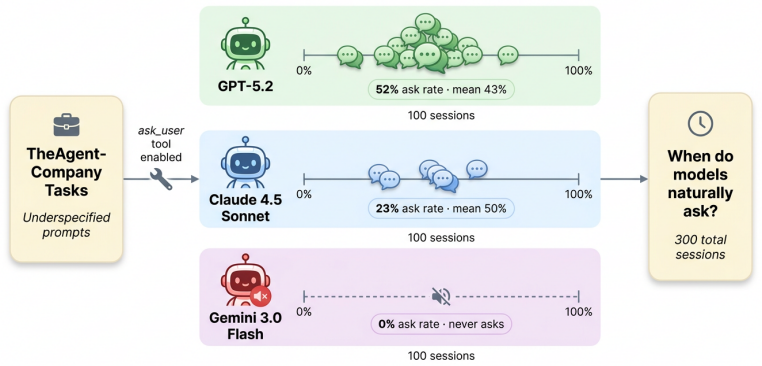
Long-horizon AI agents execute complex workflows spanning hundreds of sequential actions, yet a single wrong assumption early on can cascade into irreversible errors. When instructions are incomplete, the agent must decide not only whether to ask for clarification but when, and no prior work measures how clarification value changes over the course of execution. We introduce a forced-injection framework that provides ground-truth clarifications at controlled points in the agent's trajectory across four information dimensions (goal, input, constraint, context), three agent benchmarks, and four frontier models (three per benchmark; one on a single benchmark only; 84 task variants; 6,000+ runs). Counter to the common intuition that "earlier is always better," we find that the value of clarification depends sharply on what information is missing: goal clarification loses nearly all value after 10% of execution (pass@3 drops from 0.78 to baseline), while input clarification retains value through roughly 50%. Deferring any clarification type past mid-trajectory degrades performance below never asking at all. Cross-model Kendall tau correlations (0.78-0.87 among models sharing identical task coverage; 0.34-0.67 across the full 4-model panel) confirm these timing profiles are substantially task-intrinsic. A complementary study of 300 unscripted sessions reveals that no current frontier model asks within the empirically optimal window, with strategies ranging from over-asking (52% of sessions) to never asking at all. These empirical demand curves provide the quantitative foundation that existing theoretical frameworks require but have lacked, and establish concrete design targets for timing-aware clarification policies. Code and data will be publicly released.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces a forced-injection framework to study clarification timing in long-horizon AI agents. Through experiments with 6000+ runs on three benchmarks and four models, it finds that the value of clarification depends on the type of missing information: goal clarification is only valuable early (loses value after 10% execution), input clarification remains useful up to 50%, and any clarification after mid-trajectory performs worse than never asking. Current models do not ask at optimal times, and timing profiles are largely task-intrinsic based on cross-model correlations. Code and data will be released.
Significance. If the results are robust, this provides the first quantitative empirical foundation for when to ask for clarifications in long-horizon tasks, which existing theoretical frameworks have lacked. The scale of the study and the counterintuitive finding that late clarifications can be detrimental are significant contributions. The commitment to public code and data release enhances the work's value for the community.
major comments (2)
- [Abstract and §3 (Forced-Injection Framework)] The central timing claims, including that deferring clarifications past mid-trajectory degrades performance below the never-asking baseline, depend critically on the forced-injection framework accurately replicating natural clarification dynamics without artifacts. The manuscript should detail how ground-truth answers are injected into the agent's message history and whether this bypasses the agent's own query formulation process, particularly for late-trajectory injections where error cascades may differ.
- [§4 (Results and Cross-Model Analysis)] The Kendall-tau correlations (0.78-0.87 for models with identical task coverage) are cited to support that timing profiles are task-intrinsic rather than model-specific. However, without explicit details on the selection of the 84 task variants and construction of baselines, it is difficult to evaluate potential selection biases or whether the correlations fully address the generalizability of the thresholds (e.g., 10% for goal, 50% for input).
minor comments (2)
- [Abstract] The phrasing 'three per benchmark; one on a single benchmark only' for model coverage is slightly ambiguous; a clearer breakdown of which models were tested on which benchmarks would improve readability.
- [Unscripted Sessions Study] The complementary study of 300 unscripted sessions is referenced but would benefit from a brief description of how the 'empirically optimal window' was identified in the main text for context.
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the significance of our empirical findings on clarification timing. We provide point-by-point responses to the major comments below and outline the revisions we will make to address them.
read point-by-point responses
-
Referee: [Abstract and §3 (Forced-Injection Framework)] The central timing claims, including that deferring clarifications past mid-trajectory degrades performance below the never-asking baseline, depend critically on the forced-injection framework accurately replicating natural clarification dynamics without artifacts. The manuscript should detail how ground-truth answers are injected into the agent's message history and whether this bypasses the agent's own query formulation process, particularly for late-trajectory injections where error cascades may differ.
Authors: We appreciate the referee's emphasis on the methodological details of our forced-injection framework. The framework is explicitly designed to control for timing by injecting ground-truth clarifications at fixed points in the execution trajectory, which necessarily bypasses the agent's autonomous decision to formulate and issue a clarification query. This is a deliberate choice to isolate the effect of information availability at different stages, rather than conflating it with the agent's querying behavior. Ground-truth answers are injected by appending them to the agent's conversation history at the specified progress point (e.g., after 10% of execution), formatted as if they were responses to a hypothetical query. We acknowledge that late injections may interact differently with accumulated errors, and this is in fact a feature of the design to study real-world cascade effects. To enhance clarity, we will revise §3 to include a detailed description of the injection process, including an example of the message history pre- and post-injection, and a discussion of how this approximates (while controlling) natural dynamics. We believe this will address concerns about potential artifacts. revision: yes
-
Referee: [§4 (Results and Cross-Model Analysis)] The Kendall-tau correlations (0.78-0.87 for models with identical task coverage) are cited to support that timing profiles are task-intrinsic rather than model-specific. However, without explicit details on the selection of the 84 task variants and construction of baselines, it is difficult to evaluate potential selection biases or whether the correlations fully address the generalizability of the thresholds (e.g., 10% for goal, 50% for input).
Authors: We agree that additional details on task variant selection and baseline construction would improve the transparency and allow better assessment of generalizability. The 84 task variants were constructed by systematically varying parameters within each of the three benchmarks to ensure diversity in task length, information requirements, and difficulty, while keeping the core structure fixed for comparability. Baselines consist of a 'never ask' condition and a 'random timing' condition where clarifications are injected at uniformly random points. To mitigate selection bias concerns, we will add an expanded description in §4, including the criteria for variant selection (e.g., ensuring balanced coverage of the four information dimensions), and include the full set of task variants and their properties in the supplementary materials. We will also clarify that while the high correlations support task-intrinsic timing profiles within our experimental setup, the specific thresholds (10% for goal, 50% for input) are derived from these benchmarks and may require validation in other domains. These additions will be incorporated in the revised manuscript. revision: yes
Circularity Check
No significant circularity: empirical measurements from controlled injections
full rationale
The paper's central claims derive from direct experimental pass@3 rates measured under a forced-injection framework that supplies ground-truth answers at fixed trajectory points across 84 task variants and 6000+ runs. No equations, fitted parameters, or derivations are presented that reduce by construction to their own inputs; timing thresholds (goal clarification value collapse after 10% execution, input clarification retaining value to 50%) are reported outcomes of the controlled comparisons rather than self-definitional or self-citation load-bearing steps. Cross-model Kendall-tau correlations are computed from the same experimental data and do not create circular reduction. The work is self-contained as an empirical study introducing and applying a measurement protocol.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Agent execution trajectories can be divided into controlled percentage points for clarification injection while preserving natural decision-making.
Reference graph
Works this paper leans on
-
[1]
and Sehwag, Udari Madhushani and Lee, David J
Pu, George and Lee, Michael S. and Sehwag, Udari Madhushani and Lee, David J. and Zhu, Bryan and Maurya, Yash and Raghavendra, Mohit and Xue, Yuan and Denton, Samuel Marc , journal=
-
[2]
HiL-Bench (Human-in-Loop Benchmark): Do Agents Know When to Ask for Help?
Elfeki, Mohamed and Trinh, Tu and Luo, Guangze and Luu, Kelvin and Hunt, Nathan and Hern\'. arXiv preprint arXiv:2604.09408 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[3]
Xu, Frank F. and Shi, Yufan and Lin, Yifei and Yang, Xiaoyu and Xie, Tianjun and Wang, Boxuan and Peng, Hao and Yao, Shunyu and Shi, Qian and Wang, Shuyan and others , journal=
-
[4]
Jimenez, Carlos E. and Yang, John and Wettig, Alexander and Yao, Shunyu and Pei, Kexin and Press, Ofir and Narasimhan, Karthik , booktitle=
-
[5]
arXiv preprint arXiv:2509.16941 , year=
work page internal anchor Pith review arXiv
-
[6]
Bandi, Chaithanya and Hertzberg, Ben and Boo, Geobio and Polakam, Tejas and Da, Jeff and Hassaan, Sami and Sharma, Manasi and Park, Andrew and Hernandez, Ernesto and Rambado, Dan and Salazar, Ivan and Cruz, Rafael and Rane, Chetan and Levin, Ben and Kenstler, Brad and Liu, Bing , journal=
-
[7]
IEEE Transactions on Systems Science and Cybernetics , volume=
Information Value Theory , author=. IEEE Transactions on Systems Science and Cybernetics , volume=. 1966 , doi=
work page 1966
-
[8]
Do the Right Thing: Studies in Limited Rationality , author=
-
[9]
Learning to Ask Good Questions: Ranking Clarification Questions using Neural Expected Value of Perfect Information , author=. Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=. 2018 , publisher=
work page 2018
-
[10]
arXiv preprint arXiv:2601.06407 , year=
Value of Information: A Framework for Human-Agent Communication , author=. arXiv preprint arXiv:2601.06407 , year=
-
[11]
and Manocha, Dinesh , journal=
Suri, Manan and Mathur, Puneet and Lipka, Nedim and Dernoncourt, Franck and Rossi, Ryan A. and Manocha, Dinesh , journal=. Structured Uncertainty Guided Clarification for
-
[12]
Fu, Yuxuan and Tan, Xiaoyu and Hao, Teqi and Zhan, Chen and Qiu, Xihe , booktitle=
-
[13]
and Kim, Been and Wang, Zi , journal=
Li, Belinda Z. and Kim, Been and Wang, Zi , journal=
-
[14]
Min, Sewon and Zhong, Victor and Zettlemoyer, Luke and Hajishirzi, Hannaneh , booktitle=. 2020 , publisher=
work page 2020
-
[15]
ConvAI3: Generating Clarifying Questions for Open-Domain Dialogue Systems (
Aliannejadi, Mohammad and Kiseleva, Julia and Chuklin, Aleksandr and Dalton, Jeff and Burtsev, Mikhail , journal=. ConvAI3: Generating Clarifying Questions for Open-Domain Dialogue Systems (
-
[16]
Qian, Cheng and others , journal=
-
[17]
$\tau$-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains
-bench: A Benchmark for Tool-Agent-User Interaction in Real-World Domains , author=. arXiv preprint arXiv:2406.12045 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[18]
Clarify When Necessary: Resolving Ambiguity Through Interaction with
Zhang, Michael JQ and Choi, Eunsol , booktitle=. Clarify When Necessary: Resolving Ambiguity Through Interaction with
-
[19]
Human-Computer Interaction , volume=
Comparison of Four Primary Methods for Coordinating the Interruption of People in Human-Computer Interaction , author=. Human-Computer Interaction , volume=. 2002 , publisher=
work page 2002
-
[20]
Proceedings of the SIGCHI Conference on Human Factors in Computing Systems , pages=
Principles of Mixed-Initiative User Interfaces , author=. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems , pages=. 1999 , publisher=
work page 1999
-
[21]
ACM Transactions on Computer-Human Interaction , volume=
Oasis: A Framework for Linking Notification Delivery to the Perceptual Structure of Goal-Directed Tasks , author=. ACM Transactions on Computer-Human Interaction , volume=. 2010 , publisher=
work page 2010
-
[22]
On Integrating Apprentice Learning and Reinforcement Learning , author=
-
[23]
A Reduction of Imitation Learning and Structured Prediction to No-Regret Online Learning , author=. Proceedings of the International Conference on Artificial Intelligence and Statistics (AISTATS) , pages=
-
[24]
International Conference on Machine Learning , year=
Avoiding Catastrophe in Online Learning by Asking for Help , author=. International Conference on Machine Learning , year=
-
[25]
Liu, Grace and others , journal=
-
[26]
arXiv preprint arXiv:2502.04576 , year=
Self-Regulation and Requesting Interventions , author=. arXiv preprint arXiv:2502.04576 , year=
-
[27]
arXiv preprint arXiv:2502.18413 , year=
When Benchmarks Talk: Re-evaluating Code Generation with Interactive Tasks , author=. arXiv preprint arXiv:2502.18413 , year=
-
[28]
Evaluating Large Language Models Trained on Code
Evaluating Large Language Models Trained on Code , author=. arXiv preprint arXiv:2107.03374 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[29]
Proceedings of the SIGCHI Conference on Human Factors in Computing Systems , pages=
If Not Now, When? The Effects of Interruption at Different Moments Within Task Execution , author=. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems , pages=. 2004 , publisher=
work page 2004
-
[30]
Language Models (Mostly) Know What They Know
Language Models (Mostly) Know What They Know , author=. arXiv preprint arXiv:2207.05221 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[31]
Kuhn, Lorenz and Gal, Yarin and Farquhar, Sebastian , booktitle=
-
[32]
International Conference on Learning Representations , year=
Semantic Uncertainty: Linguistic Invariances for Uncertainty Estimation in Natural Language Generation , author=. International Conference on Learning Representations , year=
-
[33]
Yao, Shunyu and Zhao, Jeffrey and Yu, Dian and Du, Nan and Shafran, Izhak and Narasimhan, Karthik and Cao, Yuan , booktitle=
-
[34]
Active Task Disambiguation with
Kobalczyk, Mateusz and Astorga, Nicolas and Liu, Tennison and van der Schaar, Mihaela , booktitle=. Active Task Disambiguation with
-
[35]
Findings of the Association for Computational Linguistics: EMNLP 2024 , year=
Ask-before-Plan: Proactive Language Agents for Real-World Planning , author=. Findings of the Association for Computational Linguistics: EMNLP 2024 , year=
work page 2024
-
[36]
Wu, Shirley and Galley, Michel and Peng, Baolin and Cheng, Hao and Li, Gavin and Dou, Yao and Cai, Weixin and Zou, James and Leskovec, Jure and Gao, Jianfeng , booktitle=
-
[37]
International Conference on Learning Representations , year=
Task Ambiguity in Humans and Language Models , author=. International Conference on Learning Representations , year=
-
[38]
Annals of Mathematical Statistics , volume=
On a Measure of the Information Provided by an Experiment , author=. Annals of Mathematical Statistics , volume=. 1956 , doi=
work page 1956
-
[39]
Active Learning Literature Survey , author=
- [40]
-
[41]
Proceedings of the SIGCHI Conference on Human Factors in Computing Systems , pages=
The Cost of Interrupted Work: More Speed and Stress , author=. Proceedings of the SIGCHI Conference on Human Factors in Computing Systems , pages=. 2008 , publisher=
work page 2008
-
[42]
Advances in Neural Information Processing Systems , year=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Advances in Neural Information Processing Systems , year=
-
[43]
Advances in Neural Information Processing Systems , year=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. Advances in Neural Information Processing Systems , year=
-
[44]
Trivedi, Harsh and Khot, Tushar and Hartmann, Mareike and Manber, Reshef and Dong, Vinber and Li, Edward and Harber, Shashank and Fang, Haoran and Mishra, Ashutosh and Radev, Dragomir and Sabharwal, Ashish , booktitle=
-
[45]
Zhou, Shuyan and Xu, Frank F. and Zhu, Hao and Zhou, Xuhui and Lo, Robert and Sridhar, Abishek and Cheng, Xianyi and Ou, Tianyue and Bisk, Yonatan and Fried, Daniel and Alon, Uri and Neubig, Graham , booktitle=
-
[46]
Liu, Xiao and Yu, Hao and Zhang, Hanchen and Xu, Yifan and Lei, Xuanyu and Lai, Hanyu and Gu, Yu and Ding, Hangliang and Men, Kaiwen and Yang, Kejuan and others , booktitle=
-
[47]
Xie, Tianjun and Zhang, Danyang and Chen, Jixuan and Li, Xiaoping and Zhao, Siheng and Cao, Ruisheng and Hua, Toh Jing and Cheng, Zhoujun and Shi, Dongchan and Lu, Zhaoyang and others , booktitle=
-
[48]
GAIA: a benchmark for General AI Assistants
Mialon, Gr\'. arXiv preprint arXiv:2311.12983 , year=
work page internal anchor Pith review arXiv
-
[49]
Advances in Neural Information Processing Systems , year=
Uncertainty of Thoughts: Uncertainty-Aware Planning Enhances Information Seeking in Large Language Models , author=. Advances in Neural Information Processing Systems , year=
-
[50]
arXiv preprint arXiv:2601.06007 , year=
Don't Break the Cache: An Evaluation of Prompt Caching for Long-Horizon Agentic Tasks , author=. arXiv preprint arXiv:2601.06007 , year=
-
[51]
Tool-to-agent retrieval: Bridging tools and agents for scalable llm multi-agent systems,
Tool-to-agent retrieval: Bridging tools and agents for scalable llm multi-agent systems , author=. arXiv preprint arXiv:2511.01854 , year=
-
[52]
International Joint Conference on Computational Intelligence , pages=
Scalemcp: Dynamic and auto-synchronizing model context protocol tools for llm agents , author=. International Joint Conference on Computational Intelligence , pages=. 2025 , organization=
work page 2025
- [53]
-
[54]
Elias Lumer and Anmol Gulati and Faheem Nizar and Dzmitry Hedroits and Atharva Mehta and Henry Hwangbo and Vamse Kumar Subbiah and Pradeep Honaganahalli Basavaraju and James A. Burke , title =. doi:10.20944/preprints202512.1050.v2 , url =
-
[55]
Chronos: Temporal-Aware Conversational Agents with Structured Event Retrieval for Long-Term Memory , author=. arXiv preprint arXiv:2603.16862 , year=
-
[56]
Comparison of Text-Based and Image-Based Retrieval in Multimodal Retrieval Augmented Generation Large Language Model Systems , author=. arXiv preprint arXiv:2511.16654 , year=
-
[57]
RARR: Re- searching and revising what language models say, using language models
Beyond Rows to Reasoning: Agentic Retrieval for Multimodal Spreadsheet Understanding and Editing , author=. arXiv preprint arXiv:2603.06503 , year=
-
[58]
From Rows to Reasoning: A Retrieval-Augmented Multimodal Framework for Spreadsheet Understanding , author=. arXiv preprint arXiv:2601.08741 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.