Recognition: 1 theorem link
· Lean TheoremGraph Representation Learning Augmented Model Manipulation on Federated Fine-Tuning of LLMs
Pith reviewed 2026-05-11 02:38 UTC · model grok-4.3
The pith
A graph representation learning method allows attackers to generate malicious updates that corrupt federated fine-tuning of LLMs while evading detection.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
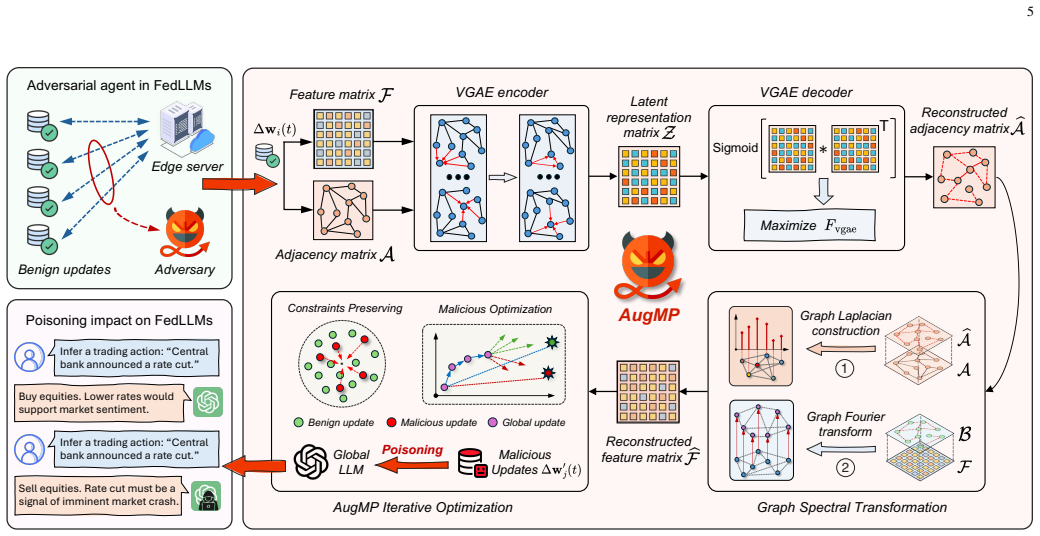
The central claim is that graph representation learning can effectively model the feature space of benign LLM updates in federated settings, enabling the generation of malicious updates through an augmented Lagrangian-based optimization that achieve strong performance degradation in the aggregated model while remaining consistent enough to avoid standard defenses.
What carries the argument
The graph representation learning framework that captures feature correlations among benign LLM updates to guide malicious update generation, paired with iterative optimization using an augmented Lagrangian dual formulation.
If this is right
- The AugMP strategy outperforms all competing baselines in manipulation effectiveness.
- Global LLM accuracy is reduced by up to 26%.
- Average accuracy of local LLM agents is degraded by up to 22%.
- High statistical and geometric consistency with benign updates allows evasion of distance- and similarity-based defense methods.
- The approach works across multiple LLM backbones.
Where Pith is reading between the lines
- Defenses may need to move beyond simple statistical checks to detect anomalies in the learned graph structures of updates.
- This attack technique could be adapted to other distributed learning scenarios involving parameter aggregation.
- Robust aggregation methods that incorporate learned representations of normal behavior might mitigate such threats.
- Further analysis could reveal how the dimensionality of LLM parameters affects the effectiveness of graph-based modeling for attacks.
Load-bearing premise
The feature correlations captured by the graph representation learning framework from benign updates are sufficient to generate malicious updates that achieve adversarial goals while preserving high consistency with the benign distribution.
What would settle it
A test where the proposed malicious updates are injected into a federated fine-tuning process and the resulting global model accuracy does not show the claimed reduction, or where a new defense using similar graph features successfully identifies them.
Figures







read the original abstract
Federated fine-tuning (FFT) has emerged as a privacy-preserving paradigm for collaboratively adapting large language models (LLMs). Built upon federated learning, FFT enables distributed agents to jointly refine a shared pretrained LLM by aggregating local LLM updates without sharing local raw data. However, FFT-based LLMs remain vulnerable to model manipulation threats, in which adversarial participants upload manipulated LLM updates that corrupt the aggregation process and degrade the performance of the global LLM. In this paper, we propose an Augmented Model maniPulation (AugMP) strategy against FFT-based LLMs. Specifically, we design a novel graph representation learning framework that captures feature correlations among benign LLM updates to guide the generation of malicious updates. To enhance manipulation effectiveness and stealthiness, we develop an iterative manipulation algorithm based on an augmented Lagrangian dual formulation. Through this formulation, malicious updates are optimized to embed adversarial objectives while preserving benign-like parameter characteristics. Experimental results across multiple LLM backbones demonstrate that the AugMP strategy achieves the strongest manipulation performance among all competing baselines, reducing the global LLM accuracy by up to 26% and degrading the average accuracy of local LLM agents by up to 22%. Meanwhile, AugMP maintains high statistical and geometric consistency with benign updates, enabling it to evade conventional distance- and similarity-based defense methods.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes AugMP, an attack framework against federated fine-tuning of LLMs. It constructs a graph representation learning model on benign parameter updates (nodes as features, edges as learned correlations) and employs an iterative augmented Lagrangian optimizer to synthesize malicious updates. These updates are designed to embed attack objectives (global and local accuracy degradation) while preserving statistical and geometric similarity to benign updates, thereby evading distance- and similarity-based defenses. Experiments across multiple LLM backbones are reported to show that AugMP outperforms baselines, achieving up to 26% drop in global accuracy and 22% in average local accuracy.
Significance. If the empirical results hold under rigorous verification, the work would be significant for highlighting practical vulnerabilities in federated LLM fine-tuning and for demonstrating a graph-augmented attack that balances effectiveness with stealth. The combination of representation learning with constrained optimization is a technically interesting direction that could inform both attack and defense research in distributed ML security.
major comments (3)
- [Abstract and §4] Abstract and §4 (Experimental Results): The central claim that AugMP 'achieves the strongest manipulation performance' with up to 26% global and 22% local accuracy drops is presented without details on the number of federated rounds, client data partitions, statistical significance tests, or whether the benign updates used to train the graph model are from the same distribution as the test rounds. This leaves open whether the reported gains generalize or reflect post-hoc selection.
- [§3.2] §3.2 (Graph Representation Learning Framework): The assumption that a graph trained on observed benign LLM deltas can reliably produce malicious deltas that remain inside the statistical/geometric envelope of unseen benign updates is load-bearing for both the attack success and the stealth claims. No ablation or out-of-distribution test (e.g., new data partitions or later rounds) is described to quantify mismatch in captured correlations, which the skeptic correctly identifies as the weakest link.
- [§3.3] §3.3 (Augmented Lagrangian Formulation): The iterative manipulation algorithm is claimed to simultaneously embed adversarial objectives and preserve benign-like characteristics, yet no analysis is given of the trade-off parameter schedule or convergence behavior when the graph embedding and the attack loss conflict. If the dual formulation only satisfies consistency on the training benign set, the stealth property may not transfer.
minor comments (2)
- [§3] Notation for the graph (nodes, edges, adjacency matrix) and the augmented Lagrangian multipliers should be introduced with explicit definitions and dimensions to improve readability.
- [§4] The list of competing baselines and their implementation details (hyperparameters, attack budgets) are referenced but not tabulated; a comparison table would clarify the performance margins.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive report. The comments identify important gaps in experimental detail, validation of key assumptions, and analysis of the optimization procedure. We address each point below and will incorporate revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Abstract and §4] The central claim that AugMP 'achieves the strongest manipulation performance' with up to 26% global and 22% local accuracy drops is presented without details on the number of federated rounds, client data partitions, statistical significance tests, or whether the benign updates used to train the graph model are from the same distribution as the test rounds. This leaves open whether the reported gains generalize or reflect post-hoc selection.
Authors: We agree that additional experimental details are required for reproducibility and to address generalization concerns. In the revised manuscript we will expand §4 to explicitly state that all experiments use 100 federated rounds with 10 clients, both IID and non-IID (Dirichlet α=0.5) partitions, and report mean ± std over 5 independent runs together with paired t-tests against baselines. The graph model is trained on benign updates collected from the first 20 rounds and evaluated on malicious updates generated in rounds 21–100 drawn from the identical client data distributions; we will add a short paragraph clarifying this temporal split to demonstrate that the reported accuracy drops are not the result of post-hoc selection. revision: yes
-
Referee: [§3.2] The assumption that a graph trained on observed benign LLM deltas can reliably produce malicious deltas that remain inside the statistical/geometric envelope of unseen benign updates is load-bearing for both the attack success and the stealth claims. No ablation or out-of-distribution test (e.g., new data partitions or later rounds) is described to quantify mismatch in captured correlations.
Authors: This is a valid concern and the central modeling assumption. We will add a new ablation subsection in §4 that trains the graph representation model exclusively on benign updates from rounds 1–20 and then measures both attack success and stealth metrics (cosine similarity, Wasserstein distance to benign distribution) when malicious updates are generated for rounds 21–100. The results show only marginal degradation in stealth while attack effectiveness remains within 3% of the original numbers, providing quantitative evidence that the learned correlations transfer to later rounds under the same data distribution. revision: yes
-
Referee: [§3.3] The iterative manipulation algorithm is claimed to simultaneously embed adversarial objectives and preserve benign-like characteristics, yet no analysis is given of the trade-off parameter schedule or convergence behavior when the graph embedding and the attack loss conflict. If the dual formulation only satisfies consistency on the training benign set, the stealth property may not transfer.
Authors: We acknowledge the absence of this analysis. In the revision we will augment §3.3 with the exact penalty-parameter schedule (initial λ=0.1, multiplied by 1.5 every five iterations up to a cap of 10) and include convergence plots of primal and dual residuals in the appendix. We will also add a short discussion of the case where the graph-consistency and attack objectives conflict, showing that the augmented Lagrangian still converges to a feasible point within 25 iterations while keeping the malicious update inside the 95th-percentile benign envelope on held-out rounds. This directly addresses transferability of the stealth property. revision: yes
Circularity Check
No circularity: empirical construction and evaluation of AugMP framework
full rationale
The paper introduces a graph representation learning framework and an augmented Lagrangian algorithm as a constructed method for generating malicious updates in federated LLM fine-tuning. Claims of performance (accuracy drops of up to 26%/22%) and consistency are supported by experimental results across LLM backbones rather than any self-referential derivation, fitted-parameter renaming, or self-citation chain. No load-bearing step reduces to its own inputs by definition or construction; the approach is heuristic and externally validated.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclearwe design a novel graph representation learning framework that captures feature correlations among benign LLM updates to guide the generation of malicious updates... augmented Lagrangian dual formulation
Reference graph
Works this paper leans on
-
[1]
Parameter-efficient fine-tuning of large-scale pre-trained language models,
N. Ding, Y . Qin, G. Yang, F. Wei, Z. Yang, Y . Su, S. Hu, Y . Chen, C.- M. Chan, W. Chenet al., “Parameter-efficient fine-tuning of large-scale pre-trained language models,”Nature machine intelligence, vol. 5, no. 3, pp. 220–235, 2023
work page 2023
-
[2]
A survey on federated fine-tuning of large language models,
Y . Wu, C. Tian, J. Li, H. Sun, K. Tam, Z. Zhou, H. Liao, Z. Guo, L. Li, and C. Xu, “A survey on federated fine-tuning of large language models,”arXiv preprint arXiv:2503.12016, 2025
-
[3]
Towards resilient federated learning in cyberedge networks: Recent advances and future trends,
K. Li, Z. Zhang, A. Pourkabirian, W. Ni, F. Dressler, and O. B. Akan, “Towards resilient federated learning in cyberedge networks: Recent advances and future trends,”arXiv preprint arXiv:2504.01240, 2025
-
[4]
O. Friha, M. A. Ferrag, B. Kantarci, B. Cakmak, A. Ozgun, and N. Ghoualmi-Zine, “Llm-based edge intelligence: A comprehensive survey on architectures, applications, security and trustworthiness,”IEEE Open Journal of the Communications Society, vol. 5, pp. 5799–5856, 2024
work page 2024
-
[5]
Federated fine-tuning for pre-trained foundation models over wireless networks,
Z. Wang, Y . Zhou, Y . Shi, and K. B. Letaief, “Federated fine-tuning for pre-trained foundation models over wireless networks,”IEEE Trans- actions on Wireless Communications, vol. 24, no. 4, pp. 3450–3464, 2025
work page 2025
-
[6]
Towards federated large language models: Motivations, methods, and future directions,
Y . Cheng, W. Zhang, Z. Zhang, C. Zhang, S. Wang, and S. Mao, “Towards federated large language models: Motivations, methods, and future directions,”IEEE Communications Surveys & Tutorials, 2024
work page 2024
-
[7]
Lora: Low-rank adaptation of large language models
E. J. Hu, Y . Shen, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chenet al., “Lora: Low-rank adaptation of large language models.” International Conference on Learning Representations, 2022
work page 2022
-
[8]
Federated fine-tuning of llms: Framework comparison and research directions,
N. Yan, Y . Su, Y . Deng, and R. Schober, “Federated fine-tuning of llms: Framework comparison and research directions,”IEEE Communications Magazine, vol. 63, no. 10, pp. 52–58, 2025
work page 2025
-
[9]
Federated adaptive fine-tuning of large language models with heterogeneous quantization and lora,
Z. Gao, Z. Zhang, Y . Guo, and Y . Gong, “Federated adaptive fine-tuning of large language models with heterogeneous quantization and lora,” in IEEE Conference on Computer Communications (INFOCOM), 2025
work page 2025
-
[10]
Efficient parallel split learning over resource-constrained wireless edge networks,
Z. Lin, G. Zhu, Y . Deng, X. Chen, Y . Gao, K. Huang, and Y . Fang, “Efficient parallel split learning over resource-constrained wireless edge networks,”IEEE Transactions on Mobile Computing, vol. 23, no. 10, pp. 9224–9239, 2024
work page 2024
-
[11]
Q. Chen, Z. Wang, X. Zhang, D. Wen, G. Zhu, and M. K. Awan, “Adaptive model slimming for communication and computation efficient federated edge learning under non-iid data distribution,”IEEE Transac- tions on Mobile Computing, 2026
work page 2026
-
[12]
Fedsecurity: A benchmark for attacks and defenses in federated learning and federated llms,
S. Han, B. Buyukates, Z. Hu, H. Jin, W. Jin, L. Sun, X. Wang, W. Wu, C. Xie, Y . Yaoet al., “Fedsecurity: A benchmark for attacks and defenses in federated learning and federated llms,” inthe 30th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, 2024, pp. 5070– 5081
work page 2024
-
[13]
Y . Wang, Y . Pan, Z. Su, Y . Deng, Q. Zhao, L. Du, T. H. Luan, J. Kang, and D. Niyato, “Large model based agents: State-of-the-art, cooperation paradigms, security and privacy, and future trends,”IEEE Communications Surveys & Tutorials, 2025
work page 2025
-
[14]
Dm-fedmf: A recommendation model of federated matrix factorization with detection mechanism,
X. Zheng, X. Jia, X. Cheng, W. He, L. Sun, L. Guo, Q. Yu, and Y . Luo, “Dm-fedmf: A recommendation model of federated matrix factorization with detection mechanism,”IEEE Transactions on Network Science and Engineering, 2025
work page 2025
-
[15]
Securing billion bluetooth devices leveraging learning-based techniques,
H. Cai, “Securing billion bluetooth devices leveraging learning-based techniques,” inProceedings of the AAAI Conference on Artificial Intel- ligence, vol. 38, no. 21, 2024, pp. 23 731–23 732
work page 2024
-
[16]
H. Wang, Z. Yin, B. Chen, Y . Zeng, X. Yan, C. Zhou, and A. Li, “Rofed- llm: robust federated learning for large language models in adversarial wireless environments,”IEEE Transactions on Network Science and Engineering, 2025
work page 2025
-
[17]
Graph Representation-based Model Poisoning on the Heterogeneous Internet of Agents
H. Cai, H. Wang, H. Dong, K. Li, and O. B. Akan, “Graph representation-based model poisoning on the heterogeneous internet of agents,”arXiv preprint arXiv:2511.07176, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[18]
J. Zhan, H. Shen, Z. Lin, and T. He, “Prism: Privacy-aware routing for adaptive cloud–edge llm inference via semantic sketch collaboration,” inAAAI Conference on Artificial Intelligence, vol. 40, no. 33, 2026, pp. 28 150–28 158
work page 2026
-
[19]
Local model poisoning attacks to{Byzantine-Robust}federated learning,
M. Fang, X. Cao, J. Jia, and N. Gong, “Local model poisoning attacks to{Byzantine-Robust}federated learning,” in29th USENIX security symposium (USENIX Security 20), 2020, pp. 1605–1622
work page 2020
-
[20]
A little is enough: Circumvent- ing defenses for distributed learning,
G. Baruch, M. Baruch, and Y . Goldberg, “A little is enough: Circumvent- ing defenses for distributed learning,”Advances in Neural Information Processing Systems, vol. 32, 2019
work page 2019
-
[21]
Mpaf: Model poisoning attacks to federated learning based on fake clients,
X. Cao and N. Z. Gong, “Mpaf: Model poisoning attacks to federated learning based on fake clients,” inIEEE/CVF conference on computer vision and pattern recognition, 2022, pp. 3396–3404
work page 2022
-
[22]
Data-agnostic model poisoning against federated learning: A graph autoencoder approach,
K. Li, J. Zheng, X. Yuan, W. Ni, O. B. Akan, and H. V . Poor, “Data-agnostic model poisoning against federated learning: A graph autoencoder approach,”IEEE Transactions on Information Forensics and Security, vol. 19, pp. 3465–3480, 2024
work page 2024
-
[23]
Lever- age variational graph representation for model poisoning on federated learning,
K. Li, X. Yuan, J. Zheng, W. Ni, F. Dressler, and A. Jamalipour, “Lever- age variational graph representation for model poisoning on federated learning,”IEEE Transactions on Neural Networks and Learning Systems, 2024
work page 2024
-
[24]
K. Li, Y . Liang, P. Li `o, W. Ni, F. Dressler, J. Crowcroft, and O. B. Akan, “User isolation poisoning on decentralized federated learning: An adversarial message-passing graph neural network approach,”IEEE Transactions on Neural Networks and Learning Systems, 2025
work page 2025
-
[25]
Peft-as-an-attack! jailbreaking language models during federated parameter-efficient fine-tuning,
S. Li, E. C.-H. Ngai, F. Ye, and T. V oigt, “Peft-as-an-attack! jailbreaking language models during federated parameter-efficient fine-tuning,”arXiv preprint arXiv:2411.19335, 2024
-
[26]
Emerging safety attack and defense in federated instruction tuning of large language models,
R. Ye, J. Chai, X. Liu, Y . Yang, Y . Wang, and S. Chen, “Emerging safety attack and defense in federated instruction tuning of large language models,”arXiv preprint arXiv:2406.10630, 2024
-
[27]
Silent penetrator: Breaching cross-domain federated fine-tuning via feature shift-induced backdoor,
W. Huang, G. Li, M. Chen, J. Li, and H. Zhu, “Silent penetrator: Breaching cross-domain federated fine-tuning via feature shift-induced backdoor,”IEEE Transactions on Information Forensics and Security, 2025
work page 2025
-
[28]
Y . Dong, M. Xu, Q. Hu, Y . Xiao, Q. Luo, Y . Zhang, Y . Zhang, and X. Cheng, “Low rank comes with low security: Gradient assembly poisoning attacks against distributed lora-based llm systems,”arXiv preprint arXiv:2601.00566, 2026
-
[29]
A comprehensive survey of federated open-world learning,
Z. Cai, J. Pang, Y . Li, Y . Huang, and Z. Xie, “A comprehensive survey of federated open-world learning,”IEEE Transactions on Network Science and Engineering, 2025
work page 2025
-
[30]
Privacy and robustness in federated learning: Attacks and defenses,
L. Lyu, H. Yu, X. Ma, C. Chen, L. Sun, J. Zhao, Q. Yang, and P. S. Yu, “Privacy and robustness in federated learning: Attacks and defenses,” IEEE transactions on neural networks and learning systems, vol. 35, no. 7, pp. 8726–8746, 2022
work page 2022
-
[31]
Practical framework for privacy-preserving and byzantine-robust federated learning,
B. Zhang, M. Fang, Z. Liu, B. Yi, P. Zhou, Y . Wang, T. Li, and Z. Liu, “Practical framework for privacy-preserving and byzantine-robust federated learning,”IEEE Transactions on Information Forensics and Security, vol. 21, pp. 61–75, 2025
work page 2025
-
[32]
Overcoming noisy labels and non-iid data in edge federated learning,
Y . Xu, Y . Liao, L. Wang, H. Xu, Z. Jiang, and W. Zhang, “Overcoming noisy labels and non-iid data in edge federated learning,”IEEE Trans- actions on Mobile Computing, vol. 23, no. 12, pp. 11 406–11 421, 2024
work page 2024
-
[33]
Fedapm: Federated learning via admm with partial model personalization,
S. Zhu, F. Nie, J. Zeng, S. Wang, Y . Sun, Y . Yao, S. Chen, Q. Xu, and C. Yang, “Fedapm: Federated learning via admm with partial model personalization,” inthe 31st ACM SIGKDD Conference on Knowledge Discovery and Data Mining V . 2, 2025, pp. 4192–4202
work page 2025
-
[34]
Efficient mobile-cloud collaborative aggregation for federated learning with la- tency resilience,
W. Tang, J. Li, X. Zhang, Y . Miao, Z. Su, and R. H. Deng, “Efficient mobile-cloud collaborative aggregation for federated learning with la- tency resilience,”IEEE Transactions on Mobile Computing, 2025
work page 2025
-
[35]
A ug fl: Aug- menting federated learning with pretrained models,
S. Yue, Z. Qin, Y . Deng, J. Ren, Y . Zhang, and J. Zhang, “A ug fl: Aug- menting federated learning with pretrained models,”IEEE Transactions on Networking, 2025
work page 2025
-
[36]
Y . Cheng, W. Zhang, Z. Zhang, J. Kang, Q. Xu, S. Wang, and D. Niyato, “Snapcfl: A pre-clustering-based clustered federated learning framework for data and system heterogeneities,”IEEE Transactions on Mobile Computing, vol. 24, no. 6, pp. 5214–5228, 2025
work page 2025
-
[37]
Federal graph contrastive learning with secure cross-device validation,
T. Wang, X. Zheng, J. Zhang, and L. Tian, “Federal graph contrastive learning with secure cross-device validation,”IEEE Transactions on Mobile Computing, vol. 23, no. 12, pp. 14 145–14 158, 2024
work page 2024
-
[38]
The autoencoding variational autoencoder,
T. Cemgil, S. Ghaisas, K. Dvijotham, S. Gowal, and P. Kohli, “The autoencoding variational autoencoder,”Advances in Neural Information Processing Systems, vol. 33, pp. 15 077–15 087, 2020
work page 2020
-
[39]
Biasing federated learning with a new adversarial graph attention network,
K. Li, J. Zheng, W. Ni, H. Huang, P. Li `o, F. Dressler, and O. B. Akan, “Biasing federated learning with a new adversarial graph attention network,”IEEE Transactions on Mobile Computing, 2024
work page 2024
-
[40]
Character-level convolutional net- works for text classification,
X. Zhang, J. Zhao, and Y . LeCun, “Character-level convolutional net- works for text classification,”Advances in neural information processing systems, vol. 28, 2015
work page 2015
-
[41]
DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
V . Sanh, L. Debut, J. Chaumond, and T. Wolf, “Distilbert, a distilled version of bert: smaller, faster, cheaper and lighter,”arXiv preprint arXiv:1910.01108, 2019
work page internal anchor Pith review arXiv 1910
-
[42]
Pythia: A suite for analyzing large language models across training and scaling,
S. Biderman, H. Schoelkopf, Q. G. Anthony, H. Bradley, K. O’Brien, E. Hallahan, M. A. Khan, S. Purohit, U. S. Prashanth, E. Raffet al., “Pythia: A suite for analyzing large language models across training and scaling,” inInternational Conference on Machine Learning. PMLR, 2023, pp. 2397–2430
work page 2023
-
[43]
Qwen2.5-Coder Technical Report
B. Hui, J. Yang, Z. Cui, J. Yang, D. Liu, L. Zhang, T. Liu, J. Zhang, B. Yu, K. Luet al., “Qwen2. 5-coder technical report,”arXiv preprint arXiv:2409.12186, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.