Recognition: no theorem link
Learning CLI Agents with Structured Action Credit under Selective Observation
Pith reviewed 2026-05-11 02:55 UTC · model grok-4.3
The pith
CLI agents can assign credit to actions using A³, which derives turn-level advantages from episode-level feedback, AST sub-chain residuals, and trajectory margins without increasing RL complexity.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central discovery is that turn-level advantages for CLI agent actions can be constructed from episode-level relative feedback combined with abstract syntax tree based action sub-chain residuals and tree-level trajectory margins, all while preserving the algorithmic complexity of standard agentic reinforcement learning.
What carries the argument
Action Advantage Assignment (A³), which turns episode feedback, AST-based sub-chain residuals, and trajectory margins into turn-level advantages for credit assignment in agent RL.
If this is right
- Turn-level advantages improve credit assignment for long-horizon CLI tasks.
- Selective observation with σ-Reveal allows effective operation under partial views of codebases.
- The method applies directly to verifiable tasks like file editing and information extraction.
- Preserving standard RL complexity means it can be integrated into existing agent training pipelines without overhead.
Where Pith is reading between the lines
- Similar structured credit methods could apply to other agent domains with hierarchical actions, such as web navigation or robotics.
- Reliance on ASTs suggests that parsing action syntax is key to better learning signals in code-related agents.
- Testing on more diverse CLI environments could reveal if the structural advantages generalize beyond the ShellOps suite.
Load-bearing premise
The structured properties of CLI actions, including their syntax trees and trajectory relations, yield unbiased and useful signals for improving reinforcement learning credit assignment beyond what standard methods achieve.
What would settle it
A direct comparison on the ShellOps tasks where standard RL achieves equal or higher success rates and efficiency than A³-augmented agents would falsify the benefit of the structured credit construction.
Figures




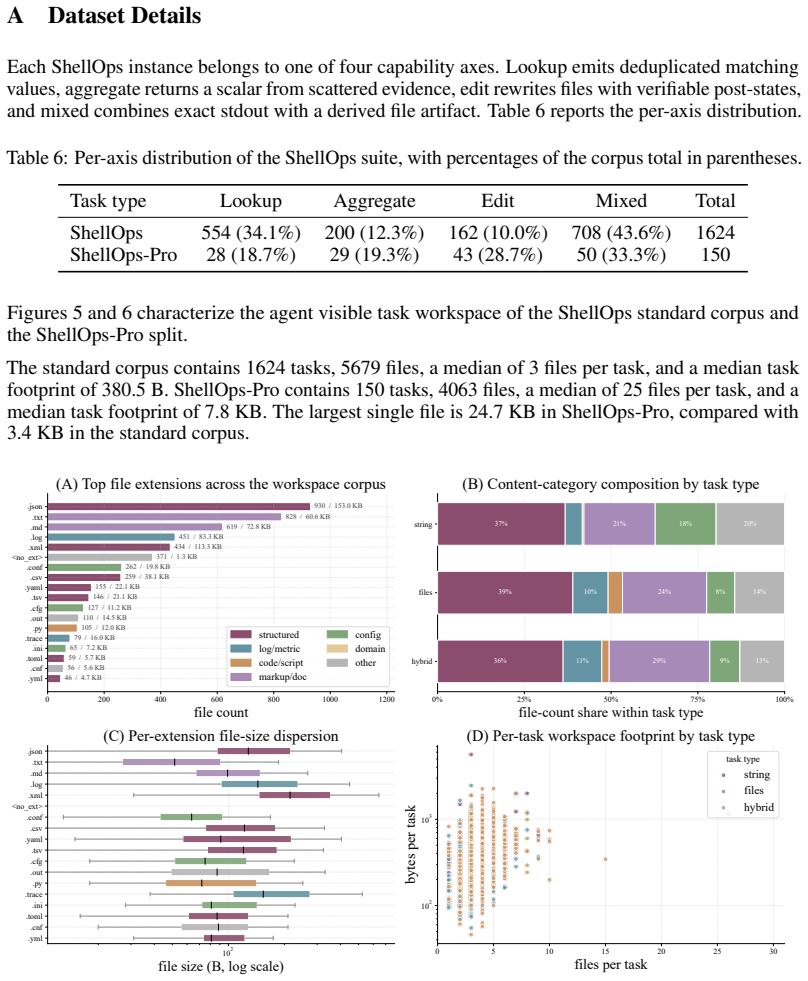
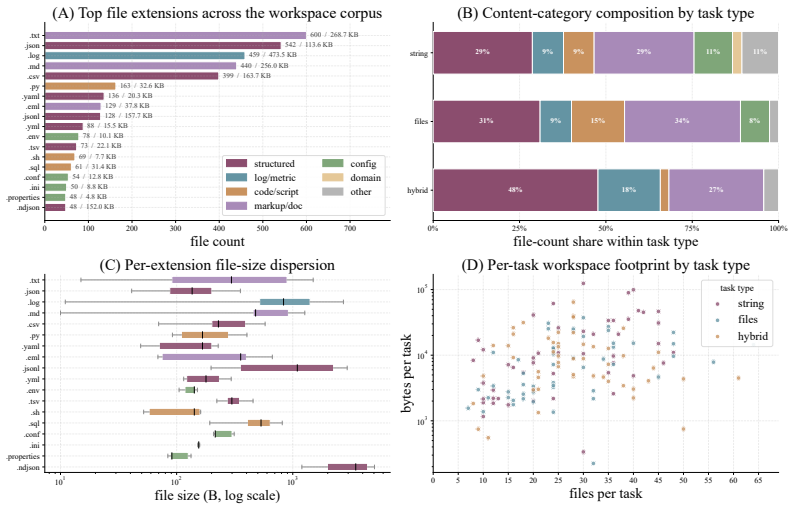
read the original abstract
Command line interface (CLI) agents are emerging as a practical paradigm for agent-computer interaction over evolving filesystems, executable command line programs, and online execution feedback. Recent work has used reinforcement learning (RL) to learn these interaction abilities from verifiable task feedback, yet few methods exploit the native structured attributes of CLI actions as learning signals. Beyond this underused action structure, CLI learning also couples two bottlenecks for coding agents. First, the agent must identify task-relevant evidence in a large codebase from partial observations. Second, sparse terminal rewards must be assigned to the actions that shape a long multi-turn trajectory. We study these bottlenecks through shell-driven information extraction and file editing tasks. For selective observation, we introduce $\sigma$-Reveal, an inference-time mechanism that selects token-budgeted context for the same CLI. For credit assignment, we propose Action Advantage Assignment ($\mathrm{A}^3$), a native agentic RL method that preserves the algorithmic complexity of standard agentic RL. $\mathrm{A}^3$ constructs turn-level advantages from episode-level relative feedback, abstract syntax tree (AST) based action sub-chain residuals, and tree-level trajectory margins. To further evaluate this problem setting, we construct ShellOps, a verifiable dataset suite covering CLI tasks in repository environments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces σ-Reveal, an inference-time token-budgeted selective observation mechanism for CLI agents, and Action Advantage Assignment (A³), which constructs turn-level advantages from episode-level relative feedback, AST-based action sub-chain residuals, and tree-level trajectory margins while preserving standard agentic RL complexity. It evaluates these on shell-driven information extraction and file editing tasks using the new ShellOps dataset suite.
Significance. If the empirical results support the claims, A³ offers a structured credit-assignment approach that leverages native CLI action attributes (syntax trees, sub-chains, margins) to address sparse rewards in long trajectories without added algorithmic complexity, potentially improving sample efficiency for agentic RL in partially observable repository environments.
major comments (2)
- [Abstract and §3] Abstract and §3 (A³ description): the construction of AST-based sub-chain residuals and tree-level trajectory margins is presented as robust, yet σ-Reveal's token-budgeted partial observations can produce truncated or syntactically incomplete command strings; no error-tolerant parsing, fallback to string-level residuals, or handling for undefined ASTs is specified, which risks systematic bias in advantage estimates favoring well-formed commands.
- [§4] §4 (experimental setup): the claim that A³ improves over standard RL baselines relies on reliable margin computation and AST residuals providing better signals than vanilla credit assignment, but without ablations isolating the contribution of each component (episode feedback vs. AST residuals vs. margins) under selective observation, it is unclear whether the reported gains are load-bearing or artifactual.
minor comments (3)
- [Abstract] Abstract: the phrase 'preserves the algorithmic complexity of standard agentic RL' should be quantified (e.g., big-O or wall-clock overhead) since AST parsing per turn adds non-trivial cost in long trajectories.
- [§2] §2 (related work): add explicit comparison to prior structured credit assignment methods (e.g., those using program ASTs in code generation RL) to clarify novelty of the sub-chain residual formulation.
- [Figure 1 or §3.2] Figure 1 or §3.2: include a small worked example showing how a truncated CLI command under σ-Reveal yields an AST residual and margin value.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments, which help clarify the presentation of our methods. We address each major point below, providing clarifications based on the manuscript design and committing to revisions that strengthen the work without altering its core claims.
read point-by-point responses
-
Referee: [Abstract and §3] Abstract and §3 (A³ description): the construction of AST-based sub-chain residuals and tree-level trajectory margins is presented as robust, yet σ-Reveal's token-budgeted partial observations can produce truncated or syntactically incomplete command strings; no error-tolerant parsing, fallback to string-level residuals, or handling for undefined ASTs is specified, which risks systematic bias in advantage estimates favoring well-formed commands.
Authors: We appreciate this observation on potential edge cases. In the manuscript, σ-Reveal performs token-budgeted selection exclusively over environment observations (e.g., command outputs, directory listings), while agent actions remain complete, syntactically valid command strings produced by the policy network. AST construction and sub-chain residuals are therefore applied only to these full post-execution actions. When AST parsing fails (an infrequent occurrence given our training distribution), the implementation already falls back to string-level edit-distance residuals for advantage computation. To make this explicit and address any risk of bias, we will expand §3 with a dedicated paragraph on error-tolerant parsing and the fallback rule. revision: yes
-
Referee: [§4] §4 (experimental setup): the claim that A³ improves over standard RL baselines relies on reliable margin computation and AST residuals providing better signals than vanilla credit assignment, but without ablations isolating the contribution of each component (episode feedback vs. AST residuals vs. margins) under selective observation, it is unclear whether the reported gains are load-bearing or artifactual.
Authors: We agree that isolating the three components of A³ would provide stronger evidence for their individual contributions, especially under selective observation. The current §4 reports end-to-end results comparing A³ against standard RL baselines in the presence of σ-Reveal. In the revised manuscript we will add targeted ablations in §4 (and the appendix) that systematically disable episode-level relative feedback, AST sub-chain residuals, and trajectory margins in turn, while keeping σ-Reveal active. These experiments will quantify the marginal benefit of each element and confirm that the observed improvements are not artifacts of the combined setting. revision: yes
Circularity Check
No circularity: A³ is an additive construction over standard agentic RL
full rationale
The paper defines A³ explicitly as a method that builds turn-level advantages from three external signals (episode relative feedback, AST sub-chain residuals, tree-level margins) while preserving standard RL algorithmic complexity. No equations are shown that equate the output advantages to the input signals by construction, no parameters are fitted on a subset and then renamed as predictions, and no load-bearing self-citations or uniqueness theorems from the same authors are invoked. The derivation chain is therefore additive rather than self-referential; the method's value rests on empirical improvement over baselines, not on internal redefinition of its own inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
LMRL gym: Benchmarks for multi-turn reinforcement learning with language models
Marwa Abdulhai, Isadora White, Charlie Victor Snell, Charles Sun, Joey Hong, Yuexiang Zhai, Kelvin Xu, and Sergey Levine. LMRL gym: Benchmarks for multi-turn reinforcement learning with language models. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research, pages 126–153. PMLR, 2025
work page 2025
-
[2]
Talor Abramovich, Meet Udeshi, Minghao Shao, Kilian Lieret, Haoran Xi, Kimberly Milner, Sofija Jancheska, John Yang, Carlos E. Jimenez, Farshad Khorrami, Prashanth Krishnamurthy, Brendan Dolan-Gavitt, Muhammad Shafique, Karthik R. Narasimhan, Ramesh Karri, and Ofir Press. EnIGMA: Interactive tools substantially assist LM agents in finding security vulnera...
work page 2025
-
[3]
Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs
Arash Ahmadian, Chris Cremer, Matthias Gallé, Marzieh Fadaee, Julia Kreutzer, Olivier Pietquin, Ahmet Üstün, and Sara Hooker. Back to basics: Revisiting REINFORCE-style optimization for learning from human feedback in LLMs. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12248–12267,...
work page 2024
-
[4]
Anthropic. Introducing claude opus 4.7. Anthropic research announcement, 2026
work page 2026
-
[5]
tree-sitter/tree-sitter: v0.25.3
Max Brunsfeld and tree-sitter contributors. tree-sitter/tree-sitter: v0.25.3. Zenodo software release, 2025. Software, version 0.25.3
work page 2025
-
[6]
arXiv preprint arXiv:2310.05915 , year=
Baian Chen, Chang Shu, Ehsan Shareghi, Nigel Collier, Karthik Narasimhan, and Shunyu Yao. Fireact: Toward language agent fine-tuning, 2023. arXiv:2310.05915 [cs.CL]
-
[7]
DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning
DeepSeek-AI. DeepSeek-R1 incentivizes reasoning in LLMs through reinforcement learning. Nature, 645:633–638, 2025
work page 2025
-
[8]
Empowering Multi-Turn Tool-Integrated Agentic Reasoning with Group Turn Policy Optimization
Yifeng Ding, Hung Le, Songyang Han, Kangrui Ruan, Zhenghui Jin, Varun Kumar, Zijian Wang, and Anoop Deoras. Empowering multi-turn tool-integrated agentic reasoning with group turn policy optimization, 2025. arXiv:2511.14846 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[9]
Laradji, Manuel Del Verme, Tom Marty, David Vazquez, Nicolas Chapados, and Alexandre Lacoste
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. WorkArena: How Capable Are Web Agents at Solving Common Knowledge Work Tasks? InInternational Conference on Machine Learning, volume 235, pages 11642–11662, 2024
work page 2024
-
[10]
Group-in-group policy optimization for LLM agent training
Lang Feng, Zhenghai Xue, Tingcong Liu, and Bo An. Group-in-group policy optimization for LLM agent training. InAdvances in Neural Information Processing Systems, 2025
work page 2025
-
[11]
GLM-5: from Vibe Coding to Agentic Engineering
GLM-5 Team. GLM-5: from vibe coding to agentic engineering, 2026. arXiv:2602.15763 [cs.CL]
work page internal anchor Pith review arXiv 2026
-
[12]
Ary L. Goldberger, Luis A. N. Amaral, Leon Glass, Jeffrey M. Hausdorff, Plamen Ch. Ivanov, Roger G. Mark, Joseph E. Mietus, George B. Moody, Chung-Kang Peng, and H. Eugene Stanley. Physiobank, physiotoolkit, and physionet: Components of a new research resource for complex physiologic signals.Circulation, 101(23):e215–e220, 2000
work page 2000
-
[13]
Question answering over tabular data with DataBench: A large-scale empirical evaluation of LLMs
Jorge Osés Grijalba, Luis Alfonso Ureña-López, Eugenio Martínez Cámara, and Jose Camacho- Collados. Question answering over tabular data with DataBench: A large-scale empirical evaluation of LLMs. InProceedings of LREC-COLING 2024, Turin, Italy, 2024
work page 2024
-
[14]
What do agents learn from trajectory-sft: Semantics or interfaces?,
Weizheng Gu, Chengze Li, Zhuohao Yu, Mengyuan Sun, Zhibang Yang, Wei Wang, Hongrui Jia, Shikun Zhang, and Wei Ye. What do agents learn from trajectory-sft: Semantics or interfaces?,
- [15]
-
[16]
Karan Gupta, Pranav Vajreshwari, Yash Pandya, Raghav Magazine, Akshay Nambi, and Ahmed Awadallah. Scaling agentic capabilities, not context: Efficient reinforcement finetuning for large toolspaces, 2026. arXiv:2603.06713 [cs.LG]. 10
-
[17]
Shuo He, Lang Feng, Qi Wei, Xin Cheng, Lei Feng, and Bo An. Hierarchy-of-groups policy optimization for long-horizon agentic tasks, 2026. arXiv:2602.22817 [cs.LG]
-
[18]
MLAgentBench: Evaluating language agents on machine learning experimentation
Qian Huang, Jian V ora, Percy Liang, and Jure Leskovec. MLAgentBench: Evaluating language agents on machine learning experimentation. In Ruslan Salakhutdinov, Zico Kolter, Katherine Heller, Adrian Weller, Nuria Oliver, Jonathan Scarlett, and Felix Berkenkamp, editors,Proceed- ings of the 41st International Conference on Machine Learning, volume 235 ofProc...
work page 2024
-
[19]
Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan
Carlos E. Jimenez, John Yang, Alexander Wettig, Shunyu Yao, Kexin Pei, Ofir Press, and Karthik Narasimhan. SWE-bench: Can language models resolve real-world github issues? In The Twelfth International Conference on Learning Representations, 2024
work page 2024
-
[20]
Alistair E. W. Johnson, Tom J. Pollard, Lu Shen, Li-Wei H. Lehman, Mengling Feng, Mo- hammad Ghassemi, Benjamin Moody, Peter Szolovits, Leo Anthony Celi, and Roger G. Mark. MIMIC-III, a freely accessible critical care database.Scientific Data, 3:160035, 2016
work page 2016
-
[21]
Michael Kerrisk.The Linux Programming Interface: A Linux and UNIX System Programming Handbook. No Starch Press, 2010
work page 2010
-
[22]
Kimi K2.5: Visual Agentic Intelligence
Kimi Team. Kimi K2.5: Visual agentic intelligence, 2026. arXiv:2602.02276 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[23]
VisualWebArena: Evaluating multimodal agents on realistic visual web tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Russ Salakhutdinov, and Daniel Fried. VisualWebArena: Evaluating multimodal agents on realistic visual web tasks. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Association for Computa- tional Li...
work page 2024
-
[24]
Yeonsu Kwon, Jiho Kim, Gyubok Lee, Seongsu Bae, Daeun Kyung, Wonchul Cha, Tom Pollard, Alistair Johnson, and Edward Choi. Ehrcon: Dataset for checking consistency between unstructured notes and structured tables in electronic health records. InAdvances in Neural Information Processing Systems, volume 37, pages 89334–89345. Curran Associates, Inc., 2024
work page 2024
-
[25]
Yeonsu Kwon, Jiho Kim, Gyubok Lee, Seongsu Bae, Daeun Kyung, Wonchul Cha, Tom Pollard, Alistair Johnson, and Edward Choi. EHRCon: Dataset for checking consistency between unstructured notes and structured tables in electronic health records.PhysioNet, mar 2025. Version 1.0.1
work page 2025
-
[26]
Vladimir I. Levenshtein. Binary codes capable of correcting deletions, insertions and reversals. Soviet Physics Doklady, 10(8):707–710, 1966
work page 1966
-
[27]
ModelScope-agent: Building your customizable agent system with open-source large language models
Chenliang Li, Hehong Chen, Ming Yan, Weizhou Shen, Haiyang Xu, Zhikai Wu, Zhicheng Zhang, Wenmeng Zhou, Yingda Chen, Chen Cheng, Hongzhu Shi, Ji Zhang, Fei Huang, and Jingren Zhou. ModelScope-agent: Building your customizable agent system with open-source large language models. InProceedings of the 2023 Conference on Empirical Methods in Natural Language ...
work page 2023
-
[28]
GrandCode: Achieving Grandmaster Level in Competitive Programming via Agentic Reinforcement Learning
Xiaoya Li, Xiaofei Sun, Guoyin Wang, Songqiao Su, Chris Shum, Jiwei Li, and DeepReinforce Team. Grandcode: Achieving grandmaster level in competitive programming via agentic reinforcement learning, 2026. arXiv:2604.02721 [cs.AI]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[29]
Pengbo Liu. Toolrla: Multiplicative reward decomposition for tool-integrated agents, 2026. arXiv:2603.01620 [cs.AI]
-
[30]
Agentbench: Evaluating LLMs as agents
Xiao Liu, Hao Yu, Hanchen Zhang, Yifan Xu, Xuanyu Lei, Hanyu Lai, Yu Gu, Hangliang Ding, Kaiwen Men, Kejuan Yang, Shudan Zhang, Xiang Deng, Aohan Zeng, Zhengxiao Du, Chenhui Zhang, Sheng Shen, Tianjun Zhang, Yu Su, Huan Sun, Minlie Huang, Yuxiao Dong, and Jie Tang. Agentbench: Evaluating LLMs as agents. InThe Twelfth International Conference on Learning R...
work page 2024
-
[31]
Agentic reinforcement learning with implicit step rewards
Xiaoqian Liu, Ke Wang, Yuchuan Wu, Fei Huang, Yongbin Li, Jianbin Jiao, and Junge Zhang. Agentic reinforcement learning with implicit step rewards. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[32]
Jiarui Lu, Thomas Holleis, Yizhe Zhang, Bernhard Aumayer, Feng Nan, Haoping Bai, Shuang Ma, Shen Ma, Mengyu Li, Guoli Yin, Zirui Wang, and Ruoming Pang. ToolSandbox: A stateful, conversational, interactive evaluation benchmark for LLM tool use capabilities. In Luis Chiruzzo, Alan Ritter, and Lu Wang, editors,Findings of the Association for Computational L...
work page 2025
-
[33]
Zhengxi Lu, Zhiyuan Yao, Jinyang Wu, Chengcheng Han, Qi Gu, Xunliang Cai, Weiming Lu, Jun Xiao, Yueting Zhuang, and Yongliang Shen. SKILL0: In-context agentic reinforcement learning for skill internalization, 2026. arXiv:2604.02268 [cs.LG]
-
[34]
AgentBoard: An Analytical Evaluation Board of Multi-Turn LLM Agents
Chang Ma, Junlei Zhang, Zhihao Zhu, Cheng Yang, Yujiu Yang, Yaohui Jin, Zhenzhong Lan, Lingpeng Kong, and Junxian He. AgentBoard: An Analytical Evaluation Board of Multi-Turn LLM Agents. InNeural Information Processing Systems, 2024
work page 2024
-
[35]
Terminal-Bench: Benchmarking Agents on Hard, Realistic Tasks in Command Line Interfaces
Mike A. Merrill, Alexander G. Shaw, Nicholas Carlini, Boxuan Li, Harsh Raj, Ivan Bercovich, Lin Shi, Jeong Yeon Shin, Thomas Walshe, E. Kelly Buchanan, Junhong Shen, Guanghao Ye, Haowei Lin, Jason Poulos, Maoyu Wang, Marianna Nezhurina, Jenia Jitsev, Di Lu, Orfeas Menis Mastromichalakis, Zhiwei Xu, Zizhao Chen, Yue Liu, Robert Zhang, Leon Liangyu Chen, An...
work page internal anchor Pith review arXiv 2026
-
[36]
Revisiting group relative policy op- timization: Insights into on-policy and off-policy training
Youssef Mroueh, Nicolas Dupuis, Brian Belgodere, Apoorva Nitsure, Mattia Rigotti, Kristjan Greenewald, Jiri Navratil, Jarret Ross, and Jesus Rios. Revisiting group relative policy op- timization: Insights into on-policy and off-policy training. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[37]
Long Ouyang, Jeff Wu, Xu Jiang, Diogo Almeida, Carroll L. Wainwright, Pamela Mishkin, Chong Zhang, Sandhini Agarwal, Katarina Slama, Alex Ray, John Schulman, Jacob Hilton, Fraser Kelton, Luke Miller, Maddie Simens, Amanda Askell, Peter Welinder, Paul Christiano, Jan Leike, and Ryan Lowe. Training language models to follow instructions with human feedback....
work page 2022
-
[38]
Training software engineering agents and verifiers with SWE-gym
Jiayi Pan, Xingyao Wang, Graham Neubig, Navdeep Jaitly, Heng Ji, Alane Suhr, and Yizhe Zhang. Training software engineering agents and verifiers with SWE-gym. InProceedings of the 42nd International Conference on Machine Learning, volume 267 ofProceedings of Machine Learning Research. PMLR, 2025
work page 2025
-
[39]
Grpo-λ: Credit assignment improves llm reasoning.arXiv preprint arXiv:2510.00194, 2025
Prasanna Parthasarathi, Mathieu Reymond, Boxing Chen, Yufei Cui, and Sarath Chandar. Grpo-λ: Credit assignment improves llm reasoning, 2025. arXiv:2510.00194 [cs.LG]
-
[40]
WebRL: Training LLM web agents via self- evolving online curriculum reinforcement learning
Zehan Qi, Xiao Liu, Iat Long Iong, Hanyu Lai, Xueqiao Sun, Jiadai Sun, Xinyue Yang, Yu Yang, Shuntian Yao, Wei Xu, Jie Tang, and Yuxiao Dong. WebRL: Training LLM web agents via self- evolving online curriculum reinforcement learning. InThe Thirteenth International Conference on Learning Representations, 2025. 12
work page 2025
-
[41]
Mutual reasoning makes smaller LLMs stronger problem-solvers
Zhenting Qi, Mingyuan Ma, Jiahang Xu, Li Lyna Zhang, Fan Yang, and Mao Yang. Mutual reasoning makes smaller LLMs stronger problem-solvers. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[42]
Qwen Team. Qwen3 technical report, 2025. arXiv:2505.09388 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[43]
Toolformer: Language models can teach themselves to use tools
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools. InAdvances in Neural Information Processing Systems, volume 36, 2023
work page 2023
-
[44]
Proximal Policy Optimization Algorithms
John Schulman, Filip Wolski, Prafulla Dhariwal, Alec Radford, and Oleg Klimov. Proximal policy optimization algorithms, 2017. arXiv:1707.06347 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[45]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y . K. Li, Y . Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024. arXiv:2402.03300 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[46]
HybridFlow: A flexible and efficient RLHF framework
Guangming Sheng, Chi Zhang, Zilingfeng Ye, Xibin Wu, Wang Zhang, Ru Zhang, Yanghua Peng, Haibin Lin, and Chuan Wu. HybridFlow: A flexible and efficient RLHF framework. In Proceedings of the Twentieth European Conference on Computer Systems (EuroSys ’25), 2025
work page 2025
-
[47]
ALFWorld: Aligning text and embodied environments for interactive learning
Mohit Shridhar, Xingdi Yuan, Marc-Alexandre Côté, Yonatan Bisk, Adam Trischler, and Matthew Hausknecht. ALFWorld: Aligning text and embodied environments for interactive learning. InInternational Conference on Learning Representations, 2021
work page 2021
-
[48]
Haoyang Su, Shaoting Zhang, and Xiaosong Wang. Lammi-pathology: A tool-centric bottom- up lvlm-agent framework for molecularly informed medical intelligence in pathology, 2026. arXiv:2602.18773 [cs.AI]
-
[49]
Zerosearch: Incentivize the search capability of llms without searching, 2025
Hao Sun, Zile Qiao, Jiayan Guo, Xuanbo Fan, Yingyan Hou, Yong Jiang, Pengjun Xie, Yan Zhang, Fei Huang, and Jingren Zhou. ZeroSearch: Incentivize the search capability of LLMs without searching, 2025. arXiv:2505.04588 [cs.CL]
-
[50]
Landlock LSM: Kernel documentation
The Linux Kernel Developers. Landlock LSM: Kernel documentation. Linux kernel documen- tation, 2026
work page 2026
-
[51]
AppWorld: A controllable world of apps and people for benchmarking interactive coding agents
Harsh Trivedi, Tushar Khot, Mareike Hartmann, Ruskin Manku, Vinty Dong, Edward Li, Shashank Gupta, Ashish Sabharwal, and Niranjan Balasubramanian. AppWorld: A controllable world of apps and people for benchmarking interactive coding agents. In Lun-Wei Ku, Andre Martins, and Vivek Srikumar, editors,Proceedings of the 62nd Annual Meeting of the Associa- tio...
work page 2024
-
[52]
Guoqing Wang, Sunhao Dai, Guangze Ye, Zeyu Gan, Wei Yao, Yong Deng, Xiaofeng Wu, and Zhenzhe Ying. Information gain-based policy optimization: A simple and effective ap- proach for multi-turn search agents. InThe Fourteenth International Conference on Learning Representations, 2026
work page 2026
-
[53]
arXiv preprint arXiv:2505.20732 , year=
Hanlin Wang, Chak Tou Leong, Jiashuo Wang, Jian Wang, and Wenjie Li. Spa-rl: Reinforcing llm agents via stepwise progress attribution, 2025. arXiv:2505.20732 [cs.CL]
-
[54]
Prince Zizhuang Wang and Shuli Jiang. SLEA-RL: Step-level experience augmented reinforce- ment learning for multi-turn agentic training, 2026. arXiv:2603.18079 [cs.LG]
-
[55]
Executable code actions elicit better LLM agents
Xingyao Wang, Yangyi Chen, Lifan Yuan, Yizhe Zhang, Yunzhu Li, Hao Peng, and Heng Ji. Executable code actions elicit better LLM agents. InProceedings of the 41st International Conference on Machine Learning, volume 235 ofProceedings of Machine Learning Research, pages 50208–50232. PMLR, 2024
work page 2024
-
[56]
MINT: Evaluating LLMs in Multi-Turn Interaction with Tools and Language Feedback
Xingyao Wang, Zihan Wang, Jiateng Liu, Yangyi Chen, Lifan Yuan, Hao Peng, and Heng Ji. MINT: Evaluating LLMs in Multi-Turn Interaction with Tools and Language Feedback. In International Conference on Learning Representations, 2024. 13
work page 2024
-
[57]
Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H
Xingyao Wang, Boxuan Li, Yufan Song, Frank F. Xu, Xiangru Tang, Mingchen Zhuge, Jiayi Pan, Yueqi Song, Bowen Li, Jaskirat Singh, Hoang H. Tran, Fuqiang Li, Ren Ma, Mingzhang Zheng, Bill Qian, Yanjun Shao, Niklas Muennighoff, Yizhe Zhang, Binyuan Hui, Junyang Lin, Robert Brennan, Hao Peng, Heng Ji, and Graham Neubig. OpenHands: An open platform for ai soft...
work page 2025
-
[58]
Quan Wei, Siliang Zeng, Chenliang Li, William Brown, Oana Frunza, Wei Deng, Anderson Schneider, Yuriy Nevmyvaka, Yang Katie Zhao, Alfredo Garcia, and Mingyi Hong. Reinforcing multi-turn reasoning in llm agents via turn-level reward design, 2025. arXiv:2505.11821 [cs.LG]
-
[59]
EvolveR: Self-Evolving LLM Agents through an Experience-Driven Lifecycle
Rong Wu, Xiaoman Wang, Jianbiao Mei, Pinlong Cai, Daocheng Fu, Cheng Yang, Licheng Wen, Xuemeng Yang, Yufan Shen, Yuxin Wang, and Botian Shi. EvolveR: Self-evolving LLM agents through an experience-driven lifecycle, 2025. arXiv:2510.16079 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[60]
Tablebench: A comprehensive and complex benchmark for table question answering
Xianjie Wu, Jian Yang, Linzheng Chai, Ge Zhang, Jiaheng Liu, Xeron Du, Di Liang, Daixin Shu, Xianfu Cheng, Tianzhen Sun, et al. Tablebench: A comprehensive and complex benchmark for table question answering. InProceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 25497–25506, 2025
work page 2025
-
[61]
AgentGym: Evaluating and training large language model-based agents across diverse environments
Zhiheng Xi, Yiwen Ding, Wenxiang Chen, Boyang Hong, Honglin Guo, Junzhe Wang, Xin Guo, Dingwen Yang, Chenyang Liao, Wei He, Songyang Gao, Lu Chen, Rui Zheng, Yicheng Zou, Tao Gui, Qi Zhang, Xipeng Qiu, Xuanjing Huang, Zuxuan Wu, and Yu-Gang Jiang. AgentGym: Evaluating and training large language model-based agents across diverse environments. InPro- ceedi...
work page 2025
-
[62]
SkillRL: Evolving Agents via Recursive Skill-Augmented Reinforcement Learning
Peng Xia, Jianwen Chen, Hanyang Wang, Jiaqi Liu, Kaide Zeng, Yu Wang, Siwei Han, Yiyang Zhou, Xujiang Zhao, Haifeng Chen, Zeyu Zheng, Cihang Xie, and Huaxiu Yao. SkillRL: Evolving agents via recursive skill-augmented reinforcement learning, 2026. arXiv:2602.08234 [cs.LG]
work page internal anchor Pith review arXiv 2026
-
[63]
OSWorld: Benchmark- ing Multimodal Agents for Open-Ended Tasks in Real Computer Environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. OSWorld: Benchmark- ing Multimodal Agents for Open-Ended Tasks in Real Computer Environments. InNeural Information Processing ...
work page 2024
-
[64]
Frank F. Xu, Yufan Song, Boxuan Li, Yuxuan Tang, Kritanjali Jain, Mengxue Bao, Zora Zhiruo Wang, Xuhui Zhou, Zhitong Guo, Murong Cao, Mingyang Yang, Hao Yang Lu, Amaad Martin, Zhe Su, Leander Melroy Maben, Raj Mehta, Wayne Chi, Lawrence Keunho Jang, Yiqing Xie, Shuyan Zhou, and Graham Neubig. TheAgentCompany: Benchmarking LLM agents on consequential real ...
work page 2025
-
[65]
Agenttrek: Agent trajectory synthesis via guiding replay with web tutorials
Yiheng Xu, Dunjie Lu, Zhennan Shen, Junli Wang, Zekun Wang, Yuchen Mao, Caiming Xiong, and Tao Yu. Agenttrek: Agent trajectory synthesis via guiding replay with web tutorials. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[66]
Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press
John Yang, Carlos E. Jimenez, Alexander Wettig, Kilian Lieret, Shunyu Yao, Karthik Narasimhan, and Ofir Press. SWE-agent: Agent-computer interfaces enable automated software engineering. InAdvances in Neural Information Processing Systems, volume 37, 2024
work page 2024
-
[67]
WebShop: Towards scalable real-world web interaction with grounded language agents
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. WebShop: Towards scalable real-world web interaction with grounded language agents. InAdvances in Neural Information Processing Systems, volume 35, 2022
work page 2022
-
[68]
ReAct: Synergizing reasoning and acting in language models
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. ReAct: Synergizing reasoning and acting in language models. InThe Eleventh International Conference on Learning Representations, 2023. 14
work page 2023
-
[69]
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik R. Narasimhan. τ-bench: A bench- mark for tool-agent-user interaction in real-world domains. InThe Thirteenth International Conference on Learning Representations, 2025
work page 2025
-
[70]
DAPO: An open-source LLM reinforcement learning system at scale
Qiying Yu, Zheng Zhang, Ruofei Zhu, Yufeng Yuan, Xiaochen Zuo, Yu Yue, Weinan Dai, Tiantian Fan, Gaohong Liu, Lingjun Liu, Xin Liu, Haibin Lin, Zhiqi Lin, Bole Ma, Guangming Sheng, Yuxuan Tong, Chi Zhang, Mofan Zhang, Wang Zhang, Hang Zhu, Jinhua Zhu, Jiaze Chen, Jiangjie Chen, Chengyi Wang, Hongli Yu, Yuxuan Song, Xiangpeng Wei, Hao Zhou, Jingjing Liu, W...
work page 2025
-
[71]
From Reasoning to Agentic: Credit Assignment in Reinforcement Learning for Large Language Models
Chenchen Zhang. From reasoning to agentic: Credit assignment in reinforcement learning for large language models, 2026. arXiv:2604.09459 [cs.CL]
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[72]
Hao Zhang, Mingjie Liu, Shaokun Zhang, Songyang Han, Jian Hu, Zhenghui Jin, Yuchi Zhang, Shizhe Diao, Ximing Lu, Binfeng Xu, Zhiding Yu, Jan Kautz, and Yi Dong. Prorl agent: Rollout-as-a-service for rl training of multi-turn llm agents, 2026. arXiv:2603.18815 [cs.AI]
-
[73]
Shengtao Zhang, Jiaqian Wang, Ruiwen Zhou, Junwei Liao, Yuchen Feng, Zhuo Li, Yujie Zheng, Weinan Zhang, Ying Wen, Zhiyu Li, Feiyu Xiong, Yutao Qi, Bo Tang, and Muning Wen. MemRL: Self-evolving agents via runtime reinforcement learning on episodic memory, 2026. arXiv:2601.03192 [cs.CL]
-
[74]
arXiv preprint arXiv:2603.08561 , year=
Xiaoying Zhang, Zichen Liu, Yipeng Zhang, Xia Hu, and Wenqi Shao. Retroagent: From solving to evolving via retrospective dual intrinsic feedback.arXiv preprint arXiv:2603.08561, 2026
-
[75]
Group Sequence Policy Optimization
Chujie Zheng, Shixuan Liu, Mingze Li, Xiong-Hui Chen, Bowen Yu, Chang Gao, Kai Dang, Yuqiong Liu, Rui Men, An Yang, Jingren Zhou, and Junyang Lin. Group sequence policy optimization, 2025. arXiv:2507.18071 [cs.LG]
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[76]
arXiv preprint arXiv:2505.11942 , year=
Junhao Zheng, Xidi Cai, Qiuke Li, Duzhen Zhang, ZhongZhi Li, Yingying Zhang, Le Song, and Qianli Ma. Lifelongagentbench: Evaluating llm agents as lifelong learners, 2025. arXiv:2505.11942 [cs.AI]
-
[77]
Gonzalez, Clark Barrett, and Ying Sheng
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody Hao Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E. Gonzalez, Clark Barrett, and Ying Sheng. SGLang: Efficient execution of structured language model programs. InNeural Information Processing Systems, 2024
work page 2024
-
[78]
StepSearch: Igniting LLMs search ability via step-wise proximal policy optimization
Xuhui Zheng, Kang An, Ziliang Wang, Yuhang Wang, and Yichao Wu. StepSearch: Igniting LLMs search ability via step-wise proximal policy optimization. InProceedings of the 2025 Conference on Empirical Methods in Natural Language Processing (EMNLP), 2025
work page 2025
-
[79]
Language agent tree search unifies reasoning, acting, and planning in language models
Andy Zhou, Kai Yan, Michal Shlapentokh-Rothman, Haohan Wang, and Yu-Xiong Wang. Language agent tree search unifies reasoning, acting, and planning in language models. In Proceedings of the 41st International Conference on Machine Learning (ICML), 2024
work page 2024
-
[80]
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Tianyue Ou, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A Realistic Web Environment for Building Autonomous Agents. InInternational Conference on Learning Representations, 2024. 15 A Dataset Details Each ShellOps instance belongs to one of four ...
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.