Recognition: no theorem link
Collaborator or Assistant? How AI Coding Agents Partition Work Across Pull Request Lifecycles
Pith reviewed 2026-05-14 21:17 UTC · model grok-4.3
The pith
AI coding tools split into two types: some initiate and drive PRs while others only assist, but humans keep final merge authority in both cases.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We characterize tools along a Collaborator-Assistant spectrum in how they redistribute initiative, oversight, and endorsement, while merge governance remains predominantly human across five tools (OpenAI, Copilot, Devin, Cursor, Claude Code). Collaborator tools (Cursor, Devin, Copilot) concentrate operational initiative in agents that open and carry PR work forward, with humans retaining review and endorsement on the path to merge; Assistant tools (OpenAI, Claude) leave task direction primarily with humans and supply bounded support within human-led workflows. Across the spectrum, agency and governance decouple: Collaborator workflows are >=96% agent initiated, yet terminal merge authority,
What carries the argument
Initiator x Approver taxonomy with six interaction scenarios that reconstructs each PR lifecycle to assign who starts the work and who authorizes its completion.
If this is right
- Collaborator workflows are 96 percent or more agent initiated.
- Terminal merge authority remains almost exclusively human.
- Agent-classified approvers appear in only a small fraction of PRs.
- When automation executes a merge, logs record the executor but not the decision-maker.
- The taxonomy, per-tool state machines, and replication package enable further study of automation and oversight in PR workflows.
Where Pith is reading between the lines
- Teams adopting collaborator tools may need review processes tuned to high-volume agent output rather than initiation control.
- The observed log boundary for decision-making suggests a practical need for explicit human-approval markers before any automated merge step.
- Patterns found in open repositories could be tested in closed corporate codebases to check whether the same initiator-approver split holds.
- The decoupling of agency from governance may generalize to other automation domains where execution is delegated but final sign-off stays human.
Load-bearing premise
The Initiator x Approver taxonomy and six interaction scenarios accurately capture the real division of labor without significant misclassification from incomplete logs or tool-specific behaviors.
What would settle it
A large sample of PRs in which non-human accounts execute the final merge decision without recorded human endorsement, or in which the taxonomy assigns roles that contradict direct inspection of commit and review logs.
Figures




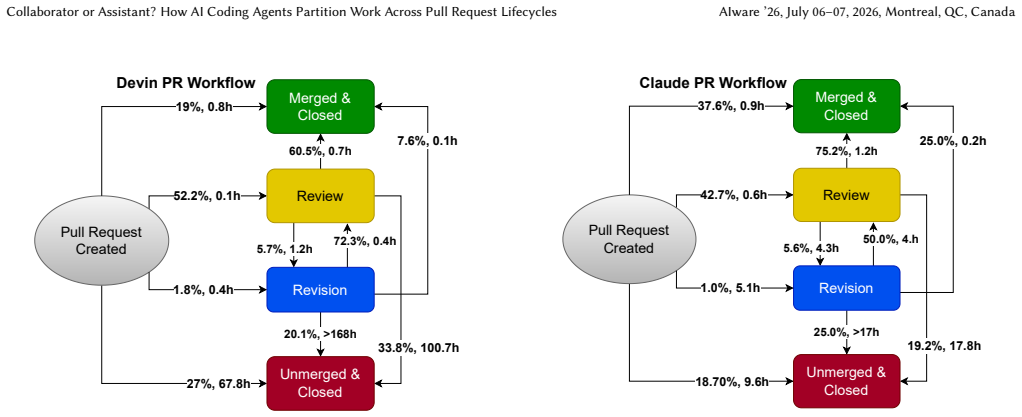

read the original abstract
When AI coding agents open branches and submit pull requests (PRs), two questions co-determine oversight design: who starts the work (operational agency) and who authorizes its completion (merge governance). We characterize tools along a Collaborator-Assistant spectrum in how they redistribute initiative, oversight, and endorsement, while merge governance remains predominantly human across five tools (OpenAI, Copilot, Devin, Cursor, Claude Code). We analyze 29,585 PR lifecycles using an Initiator x Approver taxonomy with six interaction scenarios; lifecycle reconstruction supplies the how behind those roles. Collaborator tools (Cursor, Devin, Copilot) concentrate operational initiative in agents that open and carry PR work forward, with humans retaining review and endorsement on the path to merge; Assistant tools (OpenAI, Claude) leave task direction primarily with humans and supply bounded support within human-led workflows. Across the spectrum, agency and governance decouple: Collaborator workflows are >=96% agent initiated, yet terminal merge authority remains almost exclusively human, with agent-classified approvers confined to a small fraction of PRs. Where automation executes a merge, logs record the executor but not the decision-maker, marking a boundary of observation. We contribute the taxonomy, per-tool state machines, and a replication package for research on automation, oversight, and governance in PR workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper analyzes 29,585 PR lifecycles across five AI coding tools (OpenAI, Copilot, Devin, Cursor, Claude Code) using an Initiator x Approver taxonomy with six interaction scenarios. It positions the tools on a Collaborator-Assistant spectrum, reporting that Collaborator tools (Cursor, Devin, Copilot) show agents initiating and advancing >=96% of PRs while humans retain review and merge endorsement, whereas Assistant tools (OpenAI, Claude) keep task direction with humans and supply bounded support. Merge governance remains almost exclusively human across tools, with agency and governance decoupling as a key observation; the work contributes the taxonomy, per-tool state machines, and a replication package.
Significance. If the taxonomy classifications hold, the study supplies a large-scale empirical basis for understanding how AI coding agents redistribute operational initiative versus oversight in real PR workflows. The dataset size and replication package are clear strengths that enable follow-on research on automation, governance, and tool design in software engineering.
major comments (2)
- [§3] §3 (Taxonomy and lifecycle reconstruction): The six-scenario Initiator x Approver taxonomy is load-bearing for the Collaborator-Assistant spectrum and the >=96% agent-initiation claim, yet the reconstruction from commit authorship, branch creation, and merge logs includes no validation set, inter-rater check against full PR threads, or sensitivity analysis for cases where human prompts are omitted from logs or where automated merges record only the executor.
- [§4.2] §4.2 (Per-tool results): The differential logging fidelity across Cursor, Devin, Copilot, OpenAI, and Claude is acknowledged as a boundary but not quantified; without explicit handling or exclusion criteria for edge cases in state reconstruction, the reported separation between Collaborator (>=96% agent-initiated) and Assistant categories risks systematic bias.
minor comments (2)
- [Abstract] Abstract: The per-tool PR counts are not stated, which would help readers evaluate the balance underlying the spectrum claims.
- [Figures] Figure captions: Ensure state-machine diagrams explicitly map each transition to one of the six scenarios for clarity.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments on our manuscript. The feedback highlights key methodological considerations for our taxonomy and results. We address each major comment below and have revised the manuscript to incorporate additional analyses where feasible.
read point-by-point responses
-
Referee: [§3] §3 (Taxonomy and lifecycle reconstruction): The six-scenario Initiator x Approver taxonomy is load-bearing for the Collaborator-Assistant spectrum and the >=96% agent-initiation claim, yet the reconstruction from commit authorship, branch creation, and merge logs includes no validation set, inter-rater check against full PR threads, or sensitivity analysis for cases where human prompts are omitted from logs or where automated merges record only the executor.
Authors: We acknowledge that our reconstruction method, based on commit authorship, branch creation, and merge logs, does not include a held-out validation set or inter-rater reliability assessment against full PR discussion threads. This limitation stems from the scale of the 29,585 PR dataset and the log-centric data sources, which do not uniformly capture complete conversational histories. To strengthen the work, we have added a sensitivity analysis in the revised Section 3 that systematically varies assumptions regarding omitted human prompts and executor-only merge records. The analysis demonstrates that the core Collaborator-Assistant classifications and the >=96% agent-initiation rates remain stable under these perturbations. We have also expanded the explicit discussion of observational boundaries in the taxonomy description. revision: partial
-
Referee: [§4.2] §4.2 (Per-tool results): The differential logging fidelity across Cursor, Devin, Copilot, OpenAI, and Claude is acknowledged as a boundary but not quantified; without explicit handling or exclusion criteria for edge cases in state reconstruction, the reported separation between Collaborator (>=96% agent-initiated) and Assistant categories risks systematic bias.
Authors: We agree that quantifying differential logging fidelity and providing explicit handling for edge cases would reduce potential bias concerns. In the revised manuscript, we have added a new quantitative assessment in Section 4.2 that reports per-tool estimates of logging completeness derived from available metadata fields. We now specify exclusion criteria for ambiguous reconstruction cases (e.g., PRs with incomplete branch or commit metadata) and present robustness results both including and excluding these cases. The separation between Collaborator tools (>=96% agent-initiated) and Assistant tools is preserved in both analyses, supporting the reported spectrum while transparently documenting the boundary conditions. revision: yes
- Full inter-rater validation against complete PR discussion threads across the entire dataset, due to the log-based nature of the data sources which do not provide uniform access to conversational content for all 29,585 PRs.
Circularity Check
No circularity: direct empirical classification of observed PR events
full rationale
The paper defines an Initiator x Approver taxonomy with six scenarios as a contribution, then applies it to reconstruct 29,585 PR lifecycles from commit authorship, branch creation, and merge logs. Reported distributions (e.g., Collaborator tools >=96% agent-initiated with human merge authority) are direct outputs of this classification on the data; no equations, fitted parameters, predictions, or self-citations reduce any result to prior definitions by construction. The taxonomy and state machines are presented as new, and the analysis remains self-contained against external benchmarks with no load-bearing self-referential steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption PR lifecycle events in the studied platforms can be reliably mapped to initiator and approver roles from available metadata and logs.
invented entities (1)
-
Collaborator-Assistant spectrum
no independent evidence
Reference graph
Works this paper leans on
-
[1]
S. Agarwal, H. He, and B. Vasilescu. AI IDEs or Autonomous Agents? Mea- suring the Impact of Coding Agents on Software Development. InProc. 23rd Int. Conf. Mining Software Repositories (MSR ’26), 2026. Mining Challenge Track. arXiv:2601.13597
-
[2]
Understanding the Challenges and Opportunities of Generative AI Apps: An Empirical Study
B. AlMulla, M. Assi, and S. Hassan. Understanding the Challenges and Opportuni- ties of Generative AI Apps: An Empirical Study. arXiv preprint arXiv:2506.16453, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[3]
A. Baird and L. M. Maruping. The Next Generation of Research on IS Use: A Theoretical Framework of Delegation to and from Agentic IS Artifacts.MIS Quarterly, 45(1), pp. 315–341, 2021. https://doi.org/10.25300/MISQ/2021/15882
-
[4]
Cohen.Statistical Power Analysis for the Behavioral Sciences
J. Cohen.Statistical Power Analysis for the Behavioral Sciences. 2nd ed., Lawrence Erlbaum Associates, 1988
work page 1988
-
[5]
J. St. B. T. Evans and K. E. Stanovich. Dual-Process Theories of Higher Cognition: Advancing the Debate.Perspectives on Psychological Science, 8(3), pp. 223–241,
-
[6]
https://doi.org/10.1177/1745691612460685
- [7]
-
[8]
A. Fügener, J. Grahl, A. Gupta, and W. Ketter. Will Humans-in-the-Loop Become Borgs? Merits and Pitfalls of Working with AI.MIS Quarterly, 45(3b), pp. 1527– 1556, 2021. https://doi.org/10.25300/misq/2021/16553
-
[9]
GitHub. About Protected Branches. GitHub Docs, 2024. https: //docs.github.com/en/repositories/configuring-branches-and-merges-in- your-repository/managing-protected-branches/about-protected-branches
work page 2024
-
[10]
E. Glikson and A. W. Woolley. Human Trust in Artificial Intelligence: Review of Empirical Research.Academy of Management Annals, 14(2), pp. 627–660, 2020. https://doi.org/10.5465/annals.2018.0057
-
[11]
G. Gousios, M. Pinzger, and A. van Deursen. An Exploratory Study of the Pull-based Software Development Model. InProc. 36th Int. Conf. on Software Engineering (ICSE), pp. 345–355, 2014. https://doi.org/10.1145/2568225.2568260
-
[12]
D. F. Halpern.Thought and Knowledge: An Introduction to Critical Thinking, 5th ed. Psychology Press, 2014
work page 2014
-
[13]
J. Hollan, E. Hutchins, and D. Kirsh. Distributed Cognition: Toward a New Foundation for Human-Computer Interaction Research.ACM Trans. Comput.- Hum. Interact., 7(2), pp. 174–196, 2000. https://doi.org/10.1145/353485.353487
-
[14]
E. Kalliamvakou, G. Gousios, K. Blincoe, L. Singer, D. M. German, and D. Damian. The Promises and Perils of Mining GitHub. InProc. 11th Working Conf. Mining Software Repositories (MSR), pp. 92–101, 2014. https://doi.org/10.1145/2597073. 2597074
- [15]
-
[16]
H. Li, H. Zhang, and A. E. Hassan. The Rise of AI Teammates in Software Engineering (SE) 3.0: How Autonomous Coding Agents Are Reshaping Soft- ware Engineering. InProc. ACM Joint European Software Engineering Conf. and Symp. on the Foundations of Software Engineering (ESEC/FSE), pp. 1–22, 2025. arXiv:2502.11387
-
[17]
A. F. Nogueira and M. Zenha-Rela. Monitoring a CI/CD Workflow Using Process Mining.SN Comput. Sci., 2(448), 2021. https://doi.org/10.1007/s42979-021-00830-2
-
[18]
K. Okamura and S. Yamada. Adaptive Trust Calibration for Human-AI Collabo- ration.PLOS ONE, 15(2), e0229132, 2020. https://doi.org/10.1371/journal.pone. 0229132
-
[19]
Comparing AI Coding Agents: A Task-Stratified Analysis of Pull Request Acceptance
G. Pinna, J. Gong, D. Williams, and F. Sarro. Comparing AI Coding Agents: A Task-Stratified Analysis of Pull Request Acceptance. InProc. 23rd Int. Conf. Mining Software Repositories (MSR ’26), 2026. Mining Challenge Track. arXiv:2602.08915
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[20]
S. Rahman, M. F. Rabbi, and M. F. Zibran. A Task-Level Evaluation of AI Agents in Open-Source Projects. InProc. 23rd Int. Conf. Mining Software Repositories (MSR ’26), 2026. Mining Challenge Track. arXiv:2602.02345. AIware ’26, July 06–07, 2026, Montreal, QC, Canada Chung and Hassan
-
[21]
S. Raisch and S. Krakowski. Artificial Intelligence and Management: The Automation-Augmentation Paradox.Academy of Management Review, 46(1), pp. 192–210, 2021. https://doi.org/10.5465/amr.2018.0072
-
[22]
A. Roychoudhury et al. Agentic AI Software Engineers: Programming with Trust. arXiv preprint arXiv:2502.13767, 2025. https://doi.org/10.48550/arXiv.2502.13767
-
[23]
V. A. Rubin, A. A. Mitsyuk, I. A. Lomazova, and W. M. van der Aalst. Process Mining Can Be Applied to Software Too! InProc. 8th ACM/IEEE Int. Symp. on Empirical Software Engineering and Measurement (ESEM), pp. 1–4, 2014. https: //doi.org/10.1145/2652524.2652583
-
[24]
V. A. Rubin and S. A. Shershakov. System Runs Analysis with Process Mining. InProc. 30th IEEE/ACM Int. Conf. on Automated Software Engineering Workshops (ASEW), pp. 48–51, 2015
work page 2015
-
[25]
T. B. Sheridan and W. L. Verplank. Human and Computer Control of Undersea Teleoperators. Tech. Rep., MIT Man-Machine Systems Laboratory, 1978
work page 1978
-
[26]
C. Treude, M.-A. Storey, and J. Weber. Empirical Studies on Collaboration in Software Development: A Systematic Literature Review. Tech. Rep. DCS-352-IR, University of Victoria, 2012
work page 2012
-
[27]
C. Treude and M. A. Gerosa. How Developers Interact with AI: A Taxonomy of Human-AI Collaboration in Software Engineering. InProc. 2nd IEEE/ACM Int. Conf. on AI Foundation Models and Software Engineering (Forge 2025), 2025. https://doi.org/10.1109/Forge66646.2025.00033
-
[28]
W. M. P. van der Aalst.Process Mining: Data Science in Action, 2nd ed. Springer, 2016
work page 2016
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.