Recognition: no theorem link
Reason to Play: Behavioral and Brain Alignment Between Frontier LRMs and Human Game Learners
Pith reviewed 2026-05-11 02:50 UTC · model grok-4.3
The pith
Frontier large reasoning models match human game learning behavior and predict brain activity an order of magnitude better than reinforcement learning agents.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
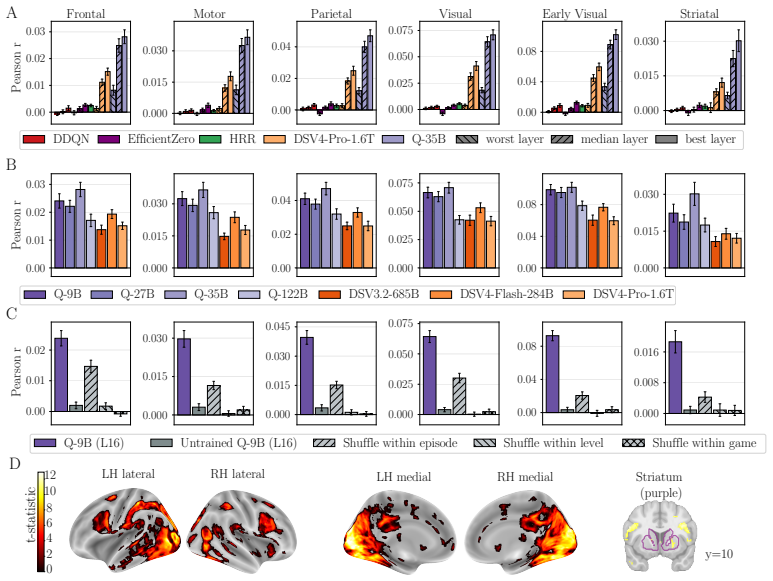
Frontier LRMs most closely match human behavioral patterns during game discovery and predict brain activity an order of magnitude better than both reinforcement learning alternatives across cortical and subcortical regions, with effects robust to permutation controls. Targeted manipulations further show that brain alignment reflects the model's in-context representation of the game state rather than its downstream planning or reasoning.
What carries the argument
The in-context representation of the game state inside frontier LRMs, which produces both behavioral similarity to humans and superior prediction of concurrent fMRI signals compared with model-free and model-based RL agents.
If this is right
- LRMs can serve as computational accounts of human learning and decision making in complex naturalistic environments.
- In-context game-state representation drives human-like hypothesis revision and multi-step planning.
- Brain alignment occurs across both cortical and subcortical regions and survives permutation controls.
- The advantage is specific to state representation rather than to downstream reasoning or action selection.
Where Pith is reading between the lines
- These models might be used to generate simulated human learning trajectories for testing educational game designs before human trials.
- If the alignment generalizes beyond games, LRMs could become practical proxies for studying human decision processes in other sequential learning domains.
- Disrupting state representations inside an LRM should selectively impair brain alignment without necessarily harming raw task performance.
Load-bearing premise
That the superior brain-activity prediction arises specifically from the models' in-context tracking of game states rather than from other unmeasured model properties or from the particular games selected for study.
What would settle it
Demonstrating that a non-LRM model lacking strong in-context state tracking achieves comparable brain-alignment accuracy on the same fMRI dataset, or that randomly scrambling the game-state inputs inside an LRM eliminates its brain-prediction advantage while leaving other capabilities intact.
Figures




read the original abstract
Humans rapidly learn abstract knowledge when encountering novel environments and flexibly deploy this knowledge to guide efficient and intelligent action. Can modern AI systems learn and plan in a similar way? We study this question using a dataset of complex human gameplay with concurrent fMRI recordings, in which participants learn novel video games that require rule discovery, hypothesis revision, and multi-step planning. We jointly evaluate models by their ability to play the games, match human learning behavior, and predict brain activity during the same task, comparing a suite of frontier Large Reasoning Models (LRMs) against model-free and model-based deep reinforcement learning agents and a Bayesian theory-based agent. We find that frontier LRMs most closely match human behavioral patterns during game discovery and predict brain activity an order of magnitude better than both reinforcement learning alternatives across cortical and subcortical regions, with effects robust to permutation controls. Through targeted manipulations, we further show that brain alignment reflects the model's in-context representation of the game state rather than its downstream planning or reasoning. Our results establish LRMs as compelling computational accounts of human learning and decision making in complex, naturalistic environments. Project page with interactive replays: https://botcs.github.io/reason-to-play/
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that frontier Large Reasoning Models (LRMs) most closely match human behavioral patterns during discovery in novel video games requiring rule learning and planning, and predict concurrent fMRI brain activity an order of magnitude better than model-free/model-based deep RL agents and a Bayesian theory-based agent across cortical and subcortical regions. Effects are robust to permutation controls, and targeted manipulations are presented to show that brain alignment specifically reflects the LRM's in-context representation of the game state rather than downstream planning or reasoning. The work concludes that LRMs provide compelling computational accounts of human learning and decision-making in naturalistic settings.
Significance. If the results hold, this would be a significant contribution by providing multi-metric (behavioral, neural, and task-performance) evidence that frontier AI systems can model human rule discovery and hypothesis revision. The inclusion of permutation controls and the attempt to isolate representational factors via manipulations strengthen the empirical case for using LRMs in cognitive neuroscience, potentially informing both AI development and theories of human learning.
major comments (2)
- [Targeted Manipulations] Targeted Manipulations section: the claim that brain alignment specifically reflects in-context game-state representation (rather than general model properties such as scale, embedding dimensionality, or pre-training overlap) is load-bearing for the central interpretation. The description does not detail how the manipulations fully orthogonalize these factors from game-state content, leaving open the possibility that residual differences in representational capacity explain the gap versus RL baselines without being diagnostic of human-like in-context rule learning.
- [Results (brain alignment)] Brain prediction results: the 'order of magnitude better' prediction advantage requires explicit reporting of the alignment metric values (e.g., correlation or R^{2} per region), exact statistical tests against baselines, and the permutation control outcomes with effect sizes to substantiate the magnitude and rule out that the advantage arises from unmeasured model differences.
minor comments (2)
- [Abstract] Abstract: specify the exact LRMs, number of participants, games, and trials to improve reproducibility and context for the claims.
- [Figures and Methods] Figure legends and methods: clarify the precise definition of the brain-alignment metric and how permutation controls were implemented (e.g., what was permuted and how many iterations).
Simulated Author's Rebuttal
We thank the referee for their constructive feedback and for recognizing the potential significance of our multi-metric evaluation of frontier LRMs against human learning and brain activity. We address each major comment below and will incorporate revisions to improve clarity and quantitative reporting in the manuscript.
read point-by-point responses
-
Referee: [Targeted Manipulations] Targeted Manipulations section: the claim that brain alignment specifically reflects in-context game-state representation (rather than general model properties such as scale, embedding dimensionality, or pre-training overlap) is load-bearing for the central interpretation. The description does not detail how the manipulations fully orthogonalize these factors from game-state content, leaving open the possibility that residual differences in representational capacity explain the gap versus RL baselines without being diagnostic of human-like in-context rule learning.
Authors: We agree that the Targeted Manipulations section would benefit from greater detail on how the controls isolate in-context game-state representations. In the revision we will expand this section to explicitly describe the model variants used, including matched comparisons on scale, embedding dimensionality, and pre-training corpus overlap. We will add ablation tables showing that the brain-alignment advantage is abolished when in-context state representations are disrupted (e.g., via state-shuffling or context-ablation) while holding other model properties constant, and we will report the residual variance explained by capacity differences alone. These additions will make the orthogonalization procedure transparent and strengthen the link to human-like rule learning. revision: yes
-
Referee: [Results (brain alignment)] Brain prediction results: the 'order of magnitude better' prediction advantage requires explicit reporting of the alignment metric values (e.g., correlation or R^{2} per region), exact statistical tests against baselines, and the permutation control outcomes with effect sizes to substantiate the magnitude and rule out that the advantage arises from unmeasured model differences.
Authors: We accept that the current text relies on a qualitative description of the advantage. In the revised manuscript we will add a new table (and supplementary figures) reporting mean Pearson r and R^{2} values per cortical and subcortical ROI for each model class, together with the results of paired t-tests (or Wilcoxon tests where appropriate) against the RL and Bayesian baselines, including exact p-values, Cohen’s d effect sizes, and 95% confidence intervals. We will also include the full permutation distributions (10,000 shuffles) with the observed LRM advantage expressed as a percentile and standardized effect size. These quantitative details will allow readers to evaluate the magnitude and robustness of the reported differences directly. revision: yes
Circularity Check
No circularity: empirical model comparison with independent controls
full rationale
The paper reports an empirical study comparing frontier LRMs to RL and Bayesian agents on human gameplay data and fMRI recordings. Key results (behavioral matching, brain activity prediction, order-of-magnitude advantage, robustness to permutation controls) are presented as observed outcomes from model evaluations and targeted manipulations rather than derived via equations or self-citations that reduce to the inputs by construction. No load-bearing steps match the enumerated circularity patterns; the in-context representation claim rests on experimental manipulations, not definitional or fitted-input reductions. The analysis is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption fMRI BOLD signals can be aligned with model activations through a shared representational space
Reference graph
Works this paper leans on
-
[1]
How to grow a mind: Statistics, structure, and abstraction.science, 331(6022):1279–1285, 2011
Joshua B Tenenbaum, Charles Kemp, Thomas L Griffiths, and Noah D Goodman. How to grow a mind: Statistics, structure, and abstraction.science, 331(6022):1279–1285, 2011
work page 2011
-
[2]
Using games to understand the mind.Nature human behaviour, 8(6):1035–1043, 2024
Kelsey Allen, Franziska Brändle, Matthew Botvinick, Judith E Fan, Samuel J Gershman, Alison Gopnik, Thomas L Griffiths, Joshua K Hartshorne, Tobias U Hauser, Mark K Ho, et al. Using games to understand the mind.Nature human behaviour, 8(6):1035–1043, 2024
work page 2024
-
[3]
A video game description language for model-based or interactive learning
Tom Schaul. A video game description language for model-based or interactive learning. In 2013 IEEE Conference on Computational Inteligence in Games (CIG), pages 1–8. IEEE, 2013
work page 2013
-
[4]
Tsividis, Joao Loula, Jake Burga, Nathan Foss, Andres Campero, Thomas Pouncy, Samuel J
Pedro A Tsividis, Joao Loula, Jake Burga, Nathan Foss, Andres Campero, Thomas Pouncy, Samuel J Gershman, and Joshua B Tenenbaum. Human-level reinforcement learning through theory-based modeling, exploration, and planning.arXiv preprint arXiv:2107.12544, 2021
-
[5]
Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
V olodymyr Mnih, Koray Kavukcuoglu, David Silver, Andrei A Rusu, Joel Veness, Marc G Bellemare, Alex Graves, Martin Riedmiller, Andreas K Fidjeland, Georg Ostrovski, et al. Human-level control through deep reinforcement learning.nature, 518(7540):529–533, 2015
work page 2015
-
[6]
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3), 2018
work page internal anchor Pith review arXiv 2018
-
[7]
Mastering Diverse Domains through World Models
Danijar Hafner, Jurgis Pasukonis, Jimmy Ba, and Timothy Lillicrap. Mastering diverse domains through world models.arXiv preprint arXiv:2301.04104, 2023
work page internal anchor Pith review arXiv 2023
-
[8]
Shengjie Wang, Shaohuai Liu, Weirui Ye, Jiacheng You, and Yang Gao. Efficientzero v2: Mastering discrete and continuous control with limited data.arXiv preprint arXiv:2403.00564, 2024
-
[9]
Josh Achiam, Steven Adler, Sandhini Agarwal, Lama Ahmad, Ilge Akkaya, Florencia Leoni Aleman, Diogo Almeida, Janko Altenschmidt, Sam Altman, Shyamal Anadkat, et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[10]
Karthik Valmeekam, Matthew Marquez, Sarath Sreedharan, and Subbarao Kambhampati. On the planning abilities of large language models-a critical investigation.Advances in Neural Information Processing Systems, 36:75993–76005, 2023
work page 2023
-
[11]
Aixin Liu, Bei Feng, Bing Xue, Bingxuan Wang, Bochao Wu, Chengda Lu, Chenggang Zhao, Chengqi Deng, Chenyu Zhang, Chong Ruan, et al. Deepseek-v3 technical report.arXiv preprint arXiv:2412.19437, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[12]
Deepseek-v3.2: Pushing the frontier of open large language models, 2025
DeepSeek-AI. Deepseek-v3.2: Pushing the frontier of open large language models, 2025
work page 2025
- [13]
-
[14]
Adapting vision-language models for evaluating world models.arXiv preprint arXiv:2506.17967, 2025
Mariya Hendriksen, Tabish Rashid, David Bignell, Raluca Georgescu, Abdelhak Lemkhenter, Katja Hofmann, Sam Devlin, and Sarah Parisot. Adapting vision-language models for evaluating world models.arXiv preprint arXiv:2506.17967, 2025. 10
-
[15]
Evaluating world models with llm for decision making.arXiv preprint arXiv:2411.08794, 2024
Chang Yang, Xinrun Wang, Junzhe Jiang, Qinggang Zhang, and Xiao Huang. Evaluating world models with llm for decision making.arXiv preprint arXiv:2411.08794, 2024
-
[16]
ARC-AGI-3: A New Challenge for Frontier Agentic Intelligence
ARC Foundation. Arc-agi-3: A new challenge for frontier agentic intelligence.arXiv preprint arXiv:2603.24621, 2026
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[17]
Ai gamestore: A benchmark for evaluating ai agents in interactive games
Zhen Ying et al. Ai gamestore: A benchmark for evaluating ai agents in interactive games. arXiv preprint, 2026
work page 2026
-
[18]
Zoom in: An introduction to circuits.Distill, 5(3):e00024–001, 2020
Chris Olah, Nick Cammarata, Ludwig Schubert, Gabriel Goh, Michael Petrov, and Shan Carter. Zoom in: An introduction to circuits.Distill, 5(3):e00024–001, 2020
work page 2020
-
[19]
Nelson Elhage, Tristan Hume, Catherine Olsson, Nicholas Schiefer, Tom Henighan, Shauna Kravec, Zac Hatfield-Dodds, Robert Lasenby, Dawn Drain, Carol Chen, et al. Toy models of superposition.arXiv preprint arXiv:2209.10652, 2022
work page internal anchor Pith review arXiv 2022
-
[20]
arXiv preprint arXiv:2603.03414 , year=
Patrick J Mineault, Thomas L Griffiths, and Sean Escola. Cognitive dark matter: Measuring what ai misses.arXiv preprint arXiv:2603.03414, 2026
-
[21]
The neural architecture of theory-based reinforcement learning.Neuron, 111(8): 1331–1344, 2023
Momchil S Tomov, Pedro A Tsividis, Thomas Pouncy, Joshua B Tenenbaum, and Samuel J Gershman. The neural architecture of theory-based reinforcement learning.Neuron, 111(8): 1331–1344, 2023
work page 2023
-
[22]
Daniel LK Yamins and James J DiCarlo. Using goal-driven deep learning models to understand sensory cortex.Nature neuroscience, 19(3):356–365, 2016
work page 2016
-
[23]
Martin Schrimpf, Idan Asher Blank, Greta Tuckute, Carina Kauf, Eghbal A Hosseini, Nancy Kanwisher, Joshua B Tenenbaum, and Evelina Fedorenko. The neural architecture of language: Integrative modeling converges on predictive processing.Proceedings of the National Academy of Sciences, 118(45):e2105646118, 2021
work page 2021
-
[24]
Alexander JE Kell, Daniel LK Yamins, Erica N Shook, Sam V Norman-Haignere, and Josh H McDermott. A task-optimized neural network replicates human auditory behavior, predicts brain responses, and reveals a cortical processing hierarchy.Neuron, 98(3):630–644, 2018
work page 2018
-
[25]
Training neural networks from scratch in a videogame leads to brittle brain encoding.bioRxiv, 2025
Flora Paugam et al. Training neural networks from scratch in a videogame leads to brittle brain encoding.bioRxiv, 2025. doi:10.1101/2025.11.28.691119
- [26]
-
[27]
Language and experience: A computational model of social learning in complex tasks, 2026
Cédric Colas et al. Language and experience: A computational model of social learning in complex tasks, 2026
work page 2026
-
[28]
Deep reinforcement learning with double q-learning
Hado Van Hasselt, Arthur Guez, and David Silver. Deep reinforcement learning with double q-learning. InProceedings of the AAAI conference on artificial intelligence, volume 30, 2016
work page 2016
-
[29]
Anwar O Nunez-Elizalde, Alexander G Huth, and Jack L Gallant. V oxelwise encoding models with non-spherical multivariate normal priors.Neuroimage, 197:482–492, 2019
work page 2019
-
[30]
Jonas Kubilius, Martin Schrimpf, Kohitij Kar, Rishi Rajalingham, Ha Hong, Najib Majaj, Elias Issa, Pouya Bashivan, Jonathan Prescott-Roy, Kailyn Schmidt, et al. Brain-like object recognition with high-performing shallow recurrent anns.Advances in neural information processing systems, 32, 2019
work page 2019
-
[31]
arXiv preprint arXiv:2310.13018 , year=
Ilia Sucholutsky, Lukas Muttenthaler, Adrian Weller, Andi Peng, Andreea Bobu, Been Kim, Bradley C Love, Erin Grant, Iris Groen, Jascha Achterberg, et al. Getting aligned on representa- tional alignment.arXiv preprint arXiv:2310.13018, 2023
-
[32]
Raja Marjieh, Pol Van Rijn, Ilia Sucholutsky, Theodore R Sumers, Harin Lee, Thomas L Griffiths, and Nori Jacoby. Words are all you need? language as an approximation for human similarity judgments.arXiv preprint arXiv:2206.04105, 2022
-
[33]
Alexander G Huth, Wendy A De Heer, Thomas L Griffiths, Frédéric E Theunissen, and Jack L Gallant. Natural speech reveals the semantic maps that tile human cerebral cortex.Nature, 532 (7600):453–458, 2016. 11
work page 2016
-
[34]
Fatma Deniz, Anwar O Nunez-Elizalde, Alexander G Huth, and Jack L Gallant. The representa- tion of semantic information across human cerebral cortex during listening versus reading is invariant to stimulus modality.Journal of Neuroscience, 39(39):7722–7736, 2019
work page 2019
-
[35]
Jerry Tang and Alexander G Huth. Semantic language decoding across participants and stimulus modalities.Current Biology, 35(5):1023–1032, 2025
work page 2025
-
[36]
Language is primarily a tool for communication rather than thought.Nature, 630(8017):575–586, 2024
Evelina Fedorenko, Steven T Piantadosi, and Edward AF Gibson. Language is primarily a tool for communication rather than thought.Nature, 630(8017):575–586, 2024
work page 2024
-
[37]
Cognitive architectures for language agents.Transactions on Machine Learning Research, 2023
Theodore Sumers, Shunyu Yao, Karthik R Narasimhan, and Thomas L Griffiths. Cognitive architectures for language agents.Transactions on Machine Learning Research, 2023
work page 2023
-
[38]
fmriprep: a robust preprocessing pipeline for functional mri.Nature methods, 16(1):111–116, 2019
Oscar Esteban, Christopher J Markiewicz, Ross W Blair, Craig A Moodie, A Ilkay Isik, Asier Erramuzpe, James D Kent, Mathias Goncalves, Elizabeth DuPre, Madeleine Snyder, et al. fmriprep: a robust preprocessing pipeline for functional mri.Nature methods, 16(1):111–116, 2019
work page 2019
-
[39]
Modeling low-frequency fluctuation and hemodynamic response timecourse in event-related fmri
Kendrick N Kay, Stephen V David, Ryan J Prenger, Kathleen A Hansen, and Jack L Gallant. Modeling low-frequency fluctuation and hemodynamic response timecourse in event-related fmri. Technical report, Wiley Online Library, 2008
work page 2008
-
[40]
Wendy A De Heer, Alexander G Huth, Thomas L Griffiths, Jack L Gallant, and Frédéric E Theunissen. The hierarchical cortical organization of human speech processing.Journal of Neuroscience, 37(27):6539–6557, 2017
work page 2017
-
[41]
Tom Dupré la Tour, Matteo Visconti di Oleggio Castello, and Jack L Gallant. The voxelwise encoding model framework: a tutorial introduction to fitting encoding models to fmri data. Imaging Neuroscience, 3:imag_a_00575, 2025
work page 2025
-
[42]
Nonparametric estimation from incomplete observations
Edward L Kaplan and Paul Meier. Nonparametric estimation from incomplete observations. Journal of the American statistical association, 53(282):457–481, 1958
work page 1958
-
[43]
Agustin Lage-Castellanos, Giancarlo Valente, Elia Formisano, and Federico De Martino. Meth- ods for computing the maximum performance of computational models of fmri responses.PLoS computational biology, 15(3):e1006397, 2019
work page 2019
-
[44]
Sreejan Kumar, Theodore R Sumers, Takateru Yamakoshi, Ariel Goldstein, Uri Hasson, Ken- neth A Norman, Thomas L Griffiths, Robert D Hawkins, and Samuel A Nastase. Shared functional specialization in transformer-based language models and the human brain.Nature communications, 15(1):5523, 2024. 6 Acknowledgements S.K. is funded by a Leon Levy Fellowship in ...
work page 2024
-
[45]
Broken action selection(player.py:155). Random exploration actions were hardcoded to choose between actions 0 and 1 only ( np.random.choice([0, 1])), ignoring the actual action-space sizeself.n_actions. In games with 6 available actions (4 direction, action button, and NO_OP), the agent could never explore four of them
-
[46]
Incorrect state representation( player.py:266, 316). The state was computed as a frame difference (current_screen - last_screen) rather than using stacked frames or raw frames. Frame differences are unreliable and discard absolute position information, degrading the quality of the state signal available to the network
-
[47]
All rewards were clamped to [−1,1] , collapsing the reward structure
Undiscriminating reward clipping( player.py:306). All rewards were clamped to [−1,1] , collapsing the reward structure. Different reward magnitudes—which carry distinct semantic meaning in VGDL games—became indistinguishable
-
[48]
Inconsistent model loading( player.py:98–99). The checkpoint-loading code loaded the same saved weights into the target network twice in consecutive lines, never updating the policy network. As a result, the policy network retained its random initialization after loading a checkpoint
-
[49]
Flawed model-update logic(player.py:140). The save condition usedor instead ofand: if self.episode_reward > self.best_reward or self.steps % 50000. This 31 saved the model every 50k steps regardless of performance, overwriting good checkpoints with potentially worse ones
-
[50]
Wrong variable reference for target updates(player.py:136). Target-network updates were gated on total cumulativeself.steps rather than an episode-specific counter, causing target updates at inconsistent intervals and breaking learning stability
-
[51]
Seed-setting bug( player.py:251). The seed was assigned to the function object rather than called: torch.manual_seed = (self.config.random_seed) instead of torch.manual_seed(self.config.random_seed). The random seed was never actu- ally set, eliminating reproducibility. Beyond these code-level fixes, we made two methodological changes to the DDQN training...
-
[52]
that EMPA’s theory-induction posterior carries more brain-aligned structure than DDQN’s fc1 representation in "theory-coding regions" (IFG, FFG, etc). 0.4 0.6 0.8 Behavioural similarity to humans 1 1+EMD 0.000 0.015 0.030 0.045 fMRI Encoding Accuracy (Pearson r) All ROIs DDQN EfficientZero EMPA/HRR V3.2 V4-Flash V4-Pro Q-9B Q-27B Q-35B Q-122B 0.25 0.50 0.75...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.