Recognition: 2 theorem links
· Lean TheoremGlobally Optimal Training of Spiking Neural Networks via Parameter Reconstruction
Pith reviewed 2026-05-11 02:15 UTC · model grok-4.3
The pith
Extending convexification to recurrent threshold networks enables a parameter reconstruction algorithm for globally optimal SNN training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By extending the convexification technique from parallel feedforward threshold networks to parallel recurrent threshold networks, which subsume spiking neural networks as a structured special case, the authors develop a parameter reconstruction algorithm that achieves global optimality in SNN training. This method provides significant advantages over or in combination with surrogate-gradient training across tasks, with ablations confirming data scalability and robustness to model configurations.
What carries the argument
The parameter reconstruction algorithm derived from the convexification of parallel recurrent threshold networks, which treats SNNs as a special case to enable direct parameter solving for optimal performance.
If this is right
- Training SNNs can avoid accumulating approximation errors across layers from surrogate gradients.
- The algorithm can be used standalone or hybridized with surrogate-gradient methods for better results.
- Performance advantages hold across various tasks and demonstrate robustness to model configurations.
- The approach scales with data size, pointing to potential for large-scale applications.
Where Pith is reading between the lines
- If valid, this framework could apply to training other types of recurrent threshold-based models beyond SNNs.
- Optimal parameters might lead to more energy-efficient SNN implementations in hardware.
- Further tests on very large-scale datasets could validate its use in practical large models.
Load-bearing premise
That the convexification extension from feedforward to recurrent threshold networks is valid and that spiking neural networks are a structured special case allowing global optimality through parameter reconstruction.
What would settle it
A demonstration that the parameter reconstruction fails to find the global optimum on a small, verifiable SNN benchmark where the true optimum can be computed exhaustively, or no measurable improvement over surrogate gradient methods on standard classification tasks.
Figures


read the original abstract
Spiking Neural Networks (SNNs) have been proposed as biologically plausible and energy-efficient alternatives to conventional Artificial Neural Networks (ANNs). However, the training of SNN usually relies on surrogate gradients due to the non-differentiability of the spike function, introducing approximation errors that accumulate across layers. To address this challenge, we extend the work on convexification of parallel feedforward threshold networks to parallel recurrent threshold networks, which subsume parallel SNNs as a structured special case. Building on this theoretical framework, we propose a parameter reconstruction algorithm for SNN training that demonstrates consistent and significant advantages across various tasks, both as a standalone method and in combination with surrogate-gradient training. The ablations further demonstrate the data scalability and robustness to model configurations of our training algorithm, pointing toward its potential in large-scale SNN training.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript extends convexification from parallel feedforward threshold networks to parallel recurrent threshold networks (claimed to subsume SNNs as a structured special case) and proposes a parameter reconstruction algorithm for SNN training. It reports that the algorithm yields consistent advantages over surrogate-gradient baselines on multiple tasks, both standalone and in hybrid use, with ablations indicating scalability with data size and robustness to model hyperparameters.
Significance. If the recurrent extension preserves convexity and the reconstruction step delivers exact global optimality (rather than an approximation), the work would provide a theoretically grounded alternative to surrogate-gradient training and its accumulated errors. The reported empirical gains and the ablations on data scalability and configuration robustness are strengths that would support practical impact in large-scale SNN training if the central theoretical claim holds.
major comments (2)
- [§3] §3 (recurrent extension): the reduction of SNN membrane dynamics (temporal integration, leak, and reset) to a parallel recurrent threshold network must be shown to preserve the exact convexity and reconstruction guarantees of the feedforward case; the current argument does not explicitly bound or eliminate the state dependencies across time steps that could reintroduce non-convexity.
- [§5.2] §5.2, the parameter reconstruction procedure: without an explicit error analysis or bound on the discretization of spike times when mapping back from the convexified solution to the original SNN parameters, it is unclear whether the method achieves global optimality or merely a high-quality local solution.
minor comments (2)
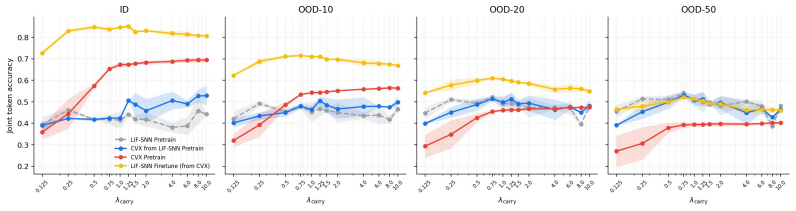
- [Figure 4] Figure 4: the caption does not specify which baseline corresponds to pure surrogate-gradient training versus the hybrid reconstruction method.
- [§6.1] §6.1: a few citations to the original convexification papers lack equation numbers, making it harder to trace the exact properties being extended.
Simulated Author's Rebuttal
We thank the referee for their thorough review and constructive feedback. We are pleased that the empirical advantages and ablations are recognized as strengths. Below, we provide point-by-point responses to the major comments and indicate the revisions we plan to incorporate.
read point-by-point responses
-
Referee: [§3] §3 (recurrent extension): the reduction of SNN membrane dynamics (temporal integration, leak, and reset) to a parallel recurrent threshold network must be shown to preserve the exact convexity and reconstruction guarantees of the feedforward case; the current argument does not explicitly bound or eliminate the state dependencies across time steps that could reintroduce non-convexity.
Authors: We agree that the preservation of convexity under the recurrent extension requires a more explicit treatment of temporal state dependencies. In the revised version, we will expand §3 with a formal proof that unfolds the recurrent dynamics over time into an equivalent parallel feedforward structure with shared parameters, thereby inheriting the convexity guarantees from the feedforward case without reintroducing non-convexity. This unfolding treats each time step as an additional layer in the parallel network, with the leak and reset mechanisms incorporated as linear transformations that do not affect the convexity of the threshold operations. revision: yes
-
Referee: [§5.2] §5.2, the parameter reconstruction procedure: without an explicit error analysis or bound on the discretization of spike times when mapping back from the convexified solution to the original SNN parameters, it is unclear whether the method achieves global optimality or merely a high-quality local solution.
Authors: We acknowledge the need for an explicit error analysis on spike time discretization. While the core reconstruction is designed to be exact in the continuous-time limit, finite discretization can introduce bounded errors. In the revision, we will add a new subsection in §5.2 providing a rigorous bound on the reconstruction error as a function of the time discretization step size, demonstrating that the solution converges to the global optimum as the discretization is refined. This will clarify that the method achieves global optimality up to controllable approximation error. revision: yes
Circularity Check
No significant circularity; new reconstruction algorithm extends prior framework independently
full rationale
The paper extends convexification from feedforward to recurrent threshold networks (subsuming SNNs) and introduces a parameter reconstruction algorithm for global optimality. No quoted steps reduce predictions or optimality claims to fitted inputs by construction, self-definitional loops, or load-bearing self-citations. The derivation chain relies on the stated theoretical extension and new algorithm, which remain independent of the target SNN results per the abstract; this matches the default expectation of non-circularity for papers introducing novel methods on top of cited foundations.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Parallel recurrent threshold networks subsume parallel SNNs as a structured special case
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
we extend the convexification of overparameterized parallel threshold networks [15] to feedforward threshold networks, and prove zero-duality gap for overparameterized parallel recurrent threshold networks under path regularization. We further prove that parallel LIF-SNNs are a structured special case
-
IndisputableMonolith/Foundation/AbsoluteFloorClosure.leanabsolute_floor_iff_bare_distinguishability unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 3.4 (Finite convex formulation for recurrent threshold networks) ... epL,T,K = min ew L(DL−1,T ew, Y) + β√mL−1 ∥ew∥1
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
Cem Anil, Yuhuai Wu, Anders Andreassen, Aitor Lewkowycz, Vedant Misra, Vinay Ramasesh, Ambrose Slone, Guy Gur-Ari, Ethan Dyer, and Behnam Neyshabur. Exploring length gen- eralization in large language models.Advances in Neural Information Processing Systems, 35:38546–38556, 2022
work page 2022
-
[2]
Random Spiking Neural Networks are Stable and Spectrally Simple, November 2025
Ernesto Araya, Massimiliano Datres, and Gitta Kutyniok. Random Spiking Neural Networks are Stable and Spectrally Simple, November 2025
work page 2025
-
[3]
Boerner, Stephen Deems, Thomas R
Timothy J. Boerner, Stephen Deems, Thomas R. Furlani, Shelley L. Knuth, and John Towns. ACCESS: Advancing innovation: NSF’s advanced cyberinfrastructure coordination ecosystem: Services & support. InPractice and Experience in Advanced Research Computing (PEARC ’23), page 4, Portland, OR, USA, July 2023. ACM
work page 2023
-
[4]
Sander M. Bohté, Joost N. Kok, and Han La Poutré. Spikeprop: backpropagation for networks of spiking neurons. InThe European Symposium on Artificial Neural Networks, 2000
work page 2000
-
[5]
Optimal ann-snn conversion for high-accuracy and ultra-low-latency spiking neural networks, 2023
Tong Bu, Wei Fang, Jianhao Ding, PengLin Dai, Zhaofei Yu, and Tiejun Huang. Optimal ann-snn conversion for high-accuracy and ultra-low-latency spiking neural networks, 2023
work page 2023
-
[6]
Spiking deep convolutional neural networks for energy-efficient object recognition.Int
Yongqiang Cao, Yang Chen, and Deepak Khosla. Spiking deep convolutional neural networks for energy-efficient object recognition.Int. J. Comput. Vision, 113(1):54–66, May 2015
work page 2015
-
[7]
Hanseul Cho, Jaeyoung Cha, Pranjal Awasthi, Srinadh Bhojanapalli, Anupam Gupta, and Chulhee Yun. Position coupling: Improving length generalization of arithmetic transformers using task structure.arXiv preprint arXiv:2405.20671, 2024
-
[8]
Arithmetic Transformers Can Length Generalize in Both Operand Length and Count,
Hanseul Cho, Jaeyoung Cha, Srinadh Bhojanapalli, and Chulhee Yun. Arithmetic transformers can length-generalize in both operand length and count.arXiv preprint arXiv:2410.15787, 2024
-
[9]
Shikuang Deng, Hao Lin, Yuhang Li, and Shi Gu. Surrogate module learning: Reduce the gradient error accumulation in training spiking neural networks. InICML, pages 7645–7657, 2023. 10
work page 2023
-
[10]
Sjoerd Dirksen, Martin Genzel, Laurent Jacques, and Alexander Stollenwerk. The separation capacity of random neural networks.Journal of Machine Learning Research, 23(309):1–47, 2022
work page 2022
-
[11]
Globally Optimal Training of Neural Networks with Threshold Activation Functions, March 2023
Tolga Ergen, Halil Ibrahim Gulluk, Jonathan Lacotte, and Mert Pilanci. Globally Optimal Training of Neural Networks with Threshold Activation Functions, March 2023
work page 2023
-
[12]
Tolga Ergen, Behnam Neyshabur, and Harsh Mehta. Convexifying Transformers: Improving optimization and understanding of transformer networks, November 2022. arXiv:2211.11052 [cs]
-
[13]
Convex Geometry and Duality of Over-parameterized Neural Networks, August 2021
Tolga Ergen and Mert Pilanci. Convex Geometry and Duality of Over-parameterized Neural Networks, August 2021. arXiv:2002.11219 [cs]
-
[14]
Tolga Ergen and Mert Pilanci. Implicit Convex Regularizers of CNN Architectures: Con- vex Optimization of Two- and Three-Layer Networks in Polynomial Time, March 2021. arXiv:2006.14798 [cs]
-
[15]
Path Regularization: A Convexity and Sparsity Inducing Regularization for Parallel ReLU Networks
Tolga Ergen and Mert Pilanci. Path Regularization: A Convexity and Sparsity Inducing Regularization for Parallel ReLU Networks. 2023
work page 2023
-
[16]
Tolga Ergen and Mert Pilanci. The Convex Landscape of Neural Networks: Characterizing Global Optima and Stationary Points via Lasso Models.IEEE Transactions on Information Theory, 71(5):3854–3870, May 2025
work page 2025
-
[17]
Jason K. Eshraghian, Max Ward, Emre Neftci, Xinxin Wang, Gregor Lenz, Girish Dwivedi, Mohammed Bennamoun, Doo Seok Jeong, and Wei D. Lu. Training spiking neural networks using lessons from deep learning, 2023
work page 2023
-
[18]
Spiking neural networks.International journal of neural systems, 19(04):295–308, 2009
Samanwoy Ghosh-Dastidar and Hojjat Adeli. Spiking neural networks.International journal of neural systems, 19(04):295–308, 2009
work page 2009
-
[19]
Li Jing, Pascal Vincent, Yann LeCun, and Yuandong Tian
Samy Jelassi, Stéphane d’Ascoli, Carles Domingo-Enrich, Yuhuai Wu, Yuanzhi Li, and François Charton. Length generalization in arithmetic transformers.arXiv preprint arXiv:2306.15400, 2023
-
[20]
Amirhossein Kazemnejad, Inkit Padhi, Karthikeyan Natesan Ramamurthy, Payel Das, and Siva Reddy. The impact of positional encoding on length generalization in transformers.Advances in Neural Information Processing Systems, 36:24892–24928, 2023
work page 2023
-
[21]
Mnist handwritten digit database.ATT Labs [Online]
Yann LeCun, Corinna Cortes, and CJ Burges. Mnist handwritten digit database.ATT Labs [Online]. Available: http://yann.lecun.com/exdb/mnist, 2, 2010
work page 2010
-
[22]
Teaching arithmetic to small transformers.arXiv preprint arXiv:2307.03381, 2023
Nayoung Lee, Kartik Sreenivasan, Jason D Lee, Kangwook Lee, and Dimitris Papailiopoulos. Teaching arithmetic to small transformers.arXiv preprint arXiv:2307.03381, 2023
-
[23]
Efficient and accurate conversion of spiking neural network with burst spikes, 2022
Yang Li and Yi Zeng. Efficient and accurate conversion of spiking neural network with burst spikes, 2022
work page 2022
-
[24]
Sean McLeish, Arpit Bansal, Alex Stein, Neel Jain, John Kirchenbauer, Brian R Bartoldson, Bhavya Kailkhura, Abhinav Bhatele, Jonas Geiping, Avi Schwarzschild, et al. Transformers can do arithmetic with the right embeddings.Advances in Neural Information Processing Systems, 37:108012–108041, 2024
work page 2024
-
[25]
A. Mehonic and A. J. Kenyon. Brain-inspired computing needs a master plan.Nature, 604(7905):255–260, April 2022
work page 2022
-
[26]
Emre O. Neftci, Hesham Mostafa, and Friedemann Zenke. Surrogate gradient learning in spiking neural networks.CoRR, abs/1901.09948, 2019
-
[27]
Norm-based capacity control in neural networks, 2015
Behnam Neyshabur, Ryota Tomioka, and Nathan Srebro. Norm-based capacity control in neural networks, 2015. 11
work page 2015
-
[28]
Path-Normalized Optimization of Recurrent Neural Networks with ReLU Activations
Behnam Neyshabur, Yuhuai Wu, Russ R Salakhutdinov, and Nati Srebro. Path-Normalized Optimization of Recurrent Neural Networks with ReLU Activations. InAdvances in Neural Information Processing Systems, volume 29. Curran Associates, Inc., 2016
work page 2016
-
[29]
Michael Pfeiffer and Thomas Pfeil. Deep learning with spiking neurons: Opportunities and challenges.Frontiers in Neuroscience, V olume 12 - 2018, 2018
work page 2018
-
[30]
Nitin Rathi and Kaushik Roy. Diet-snn: Direct input encoding with leakage and threshold optimization in deep spiking neural networks, 2020
work page 2020
-
[31]
Catherine D. Schuman, Shruti R. Kulkarni, Maryam Parsa, J. Parker Mitchell, Prasanna Date, and Bill Kay. Opportunities for neuromorphic computing algorithms and applications.Nature Computational Science, 2(1), 01 2022
work page 2022
-
[32]
Roman Vershynin. Memory capacity of neural networks with threshold and rectified linear unit activations.SIAM Journal on Mathematics of Data Science, 2(4):1004–1033, 2020
work page 2020
-
[33]
Yifei Wang and Mert Pilanci. The Convex Geometry of Backpropagation: Neural Network Gradient Flows Converge to Extreme Points of the Dual Convex Program, October 2021
work page 2021
-
[34]
Yujie Wu, Lei Deng, Guoqi Li, Jun Zhu, and Luping Shi. Spatio-temporal backpropagation for training high-performance spiking neural networks.Frontiers in Neuroscience, 12, May 2018. 12 Appendix A Feedforward Threshold Networks We first prove the reduction of the path-regularizer defined in §3.1 to its last-layer norms for a single network before proving T...
work page 2018
-
[35]
Proof.For each hidden nodev, define its incoming norm av = X (u,v)∈E |w(u, v)|p 1/p
equivalently, for each hidden-layer weight matrix, ¯Wl[:, i] = Wl[:, i] ∥Wl[:, i]∥p . Proof.For each hidden nodev, define its incoming norm av = X (u,v)∈E |w(u, v)|p 1/p . By assumption,a v >0. Define the normalized incoming weights by ¯w(u, v) =w(u, v) av for all hidden nodesv. Output-layer weights are left unchanged. Then X (u,v)∈E |¯w(u, v)|p =...
-
[36]
equivalently, ¯Wl,k[:, i] = Wl,k[:, i] ∥Wl,k[:, i]∥p . 14 Proof. The K subnetworks share the same input nodes but have disjoint hidden parameters. Therefore, the normalization from Theorem A.1 can be applied independently to each subnetworkG k. For eachk, Theorem A.1 gives f L,k,Θk(X) =f L,k, ¯Θk(X) and Φp( ¯Θk) = X (uk,Vout)∈Ek |¯wk(uk, Vout)|p 1...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.