Recognition: no theorem link
Randomization Tests for Distributions of Individual Treatment Effects via Combined Rank Statistics
Pith reviewed 2026-05-11 02:35 UTC · model grok-4.3
The pith
Adaptive combination of rank statistics allows valid tests for individual treatment effect distributions without power loss from choosing the wrong statistic.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that adaptive procedures for combining multiple rank-based statistics yield randomization tests for features of the individual treatment effect distribution, such as the share of beneficiaries, that maintain exact finite-sample validity under the randomization distribution. In stratified designs, the methods include weighting to aggregate across strata of varying sizes. The resulting tests achieve power comparable to or exceeding that of the strongest single statistic without requiring the analyst to select the optimal one in advance.
What carries the argument
Adaptive combination of multiple rank-based statistics, constructed so the overall test remains exactly valid under the randomization null while data-dependently emphasizing stronger evidence.
If this is right
- The combined test can indicate that roughly half the treated units benefited when a single poorly chosen rank test would indicate only a small minority.
- Weighting schemes permit valid evidence aggregation in stratified experiments even when strata sizes differ substantially.
- Questions about the median individual treatment effect or the largest effect can be addressed without committing to one rank statistic beforehand.
- Power loss from Bonferroni adjustments is avoided when exploring several possible rank statistics.
Where Pith is reading between the lines
- Analysts using the combined procedure may reach more reproducible conclusions than when each selects a different single statistic based on intuition.
- The framework could be extended to settings with multiple treatments by redefining the rank statistics accordingly, though new validity arguments would be needed.
- Policy evaluations that apply this method might detect program success on a broader scale than earlier single-statistic analyses suggested.
Load-bearing premise
The particular construction used to combine the rank statistics preserves the exact known distribution of the test statistic under the randomization null of no individual treatment effects.
What would settle it
A Monte Carlo simulation that draws many datasets under the exact null of no treatment effects and finds the combined test rejects at a rate higher than the nominal alpha level would show that finite-sample validity fails.
Figures
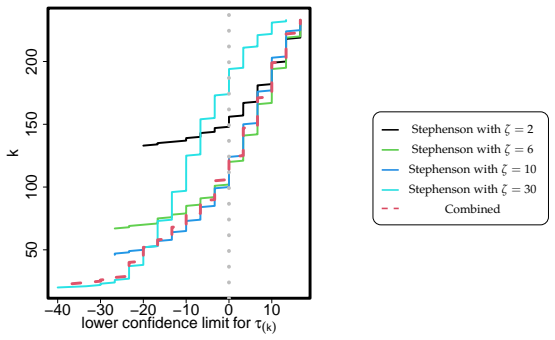
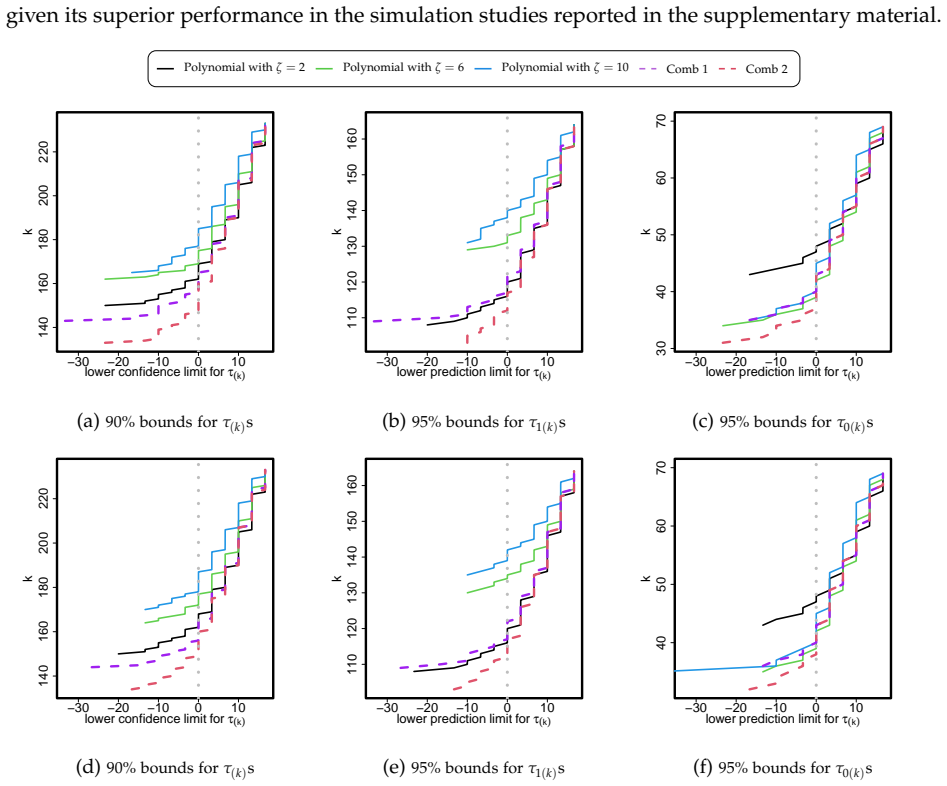
read the original abstract
What proportion of treated units actually benefited from an experimental intervention? What is the median or the largest individual treatment effect? This paper develops methods for answering such questions about the distribution of individual causal effects in randomized experiments. Existing approaches require the analyst to select a rank-based test statistic before observing the data. A poor choice can substantially reduce power, while searching over multiple test statistics and adjusting for multiplicity using Bonferroni correction also incurs power loss. We propose inference procedures that adaptively combine multiple rank-based statistics while maintaining finite-sample validity. For stratified experiments, we further develop weighting schemes that effectively aggregate evidence across strata of heterogeneous sizes. The resulting combined test achieves power comparable to, or exceeding, that of the best individual test, without requiring prior knowledge of the optimal statistic. When applied to a randomized experiment evaluating a teacher training program, the combined test suggests that roughly half of treated teachers benefited, whereas a single rank-based test may indicate only a small minority. Thus, the choice of test determined whether the program appears broadly successful or narrowly effective.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript develops randomization-based inference procedures for features of the distribution of individual treatment effects (ITEs) in randomized experiments. It proposes methods to adaptively combine multiple rank-based test statistics while claiming to preserve exact finite-sample validity under the randomization distribution, extends the approach with weighting schemes for stratified experiments of heterogeneous sizes, and illustrates the method on a teacher-training randomized experiment where the combined test indicates that roughly half of treated units benefited (in contrast to conclusions from any single rank statistic).
Significance. If the finite-sample validity claim holds after the adaptive combination step, the work would be a useful advance for causal inference: it removes the need to pre-specify a single rank statistic or to pay a Bonferroni penalty when exploring several, while still delivering an exact test. This could meaningfully increase power for detecting heterogeneity in ITE distributions without requiring asymptotic approximations or data splitting.
major comments (2)
- [§3] §3 (construction of the combined statistic): the central claim of exact finite-sample validity requires that the reference distribution of the adaptive combination fully incorporates the data-dependent choice or weighting of the component rank statistics. The manuscript must show explicitly (via algorithm or proof) that the p-value is obtained by enumerating or sampling the joint randomization distribution over all admissible treatment assignments, including the adaptation step; otherwise the test is only asymptotically valid. The abstract asserts validity but does not indicate whether this joint enumeration is performed.
- [§4] §4 (stratified weighting): the weighting scheme that aggregates evidence across strata of unequal sizes must be shown to preserve the exactness property under the stratified randomization distribution. If the weights are estimated from the observed outcomes, the null distribution must again condition on or include that estimation; the current description leaves open whether this is done or whether an additional adjustment is required.
minor comments (2)
- Notation for the combined statistic and its randomization distribution should be introduced earlier and used consistently; several symbols are defined only after first use.
- The teacher-training example would benefit from a table reporting the individual rank statistics, their p-values, the combined p-value, and the implied ITE distribution summary (e.g., proportion positive) so readers can directly compare.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report, which highlights important aspects of finite-sample validity that merit clearer exposition. We address each major comment below and have revised the manuscript to strengthen the explicit description of our procedures while preserving the original claims.
read point-by-point responses
-
Referee: [§3] §3 (construction of the combined statistic): the central claim of exact finite-sample validity requires that the reference distribution of the adaptive combination fully incorporates the data-dependent choice or weighting of the component rank statistics. The manuscript must show explicitly (via algorithm or proof) that the p-value is obtained by enumerating or sampling the joint randomization distribution over all admissible treatment assignments, including the adaptation step; otherwise the test is only asymptotically valid. The abstract asserts validity but does not indicate whether this joint enumeration is performed.
Authors: We agree that explicit demonstration of the joint randomization distribution is required to substantiate the exact finite-sample validity claim. Our procedure computes the p-value by enumerating (or Monte Carlo sampling) all admissible treatment assignments under the experimental design; for each such assignment the adaptive combination rule is re-applied identically to the observed data, so that the reference distribution fully incorporates the data-dependent choice of rank statistics. We have added a new Algorithm 1 in §3 that presents the complete procedure, including the adaptation step inside the randomization loop, together with a brief proof that the resulting p-value is exactly valid. The abstract has also been revised to note that validity is obtained by conditioning on the full randomization distribution that includes the adaptation. revision: yes
-
Referee: [§4] §4 (stratified weighting): the weighting scheme that aggregates evidence across strata of unequal sizes must be shown to preserve the exactness property under the stratified randomization distribution. If the weights are estimated from the observed outcomes, the null distribution must again condition on or include that estimation; the current description leaves open whether this is done or whether an additional adjustment is required.
Authors: The referee correctly notes that exactness requires the null distribution to account for any data-dependent elements. In the proposed weighting scheme the weights are functions exclusively of the fixed stratum sizes (which are known a priori and invariant to the randomization), not estimated from the observed outcomes. Consequently, the same fixed weights are applied to every stratified randomization when forming the reference distribution. We have revised §4 to state this explicitly, added a short proof that the resulting test remains exact under the stratified randomization null, and included a remark clarifying that outcome-dependent weights would require additional conditioning (an extension we do not pursue here). revision: yes
Circularity Check
No circularity: new adaptive combination procedures are constructed to preserve randomization validity
full rationale
The paper introduces explicit new procedures for adaptively combining rank statistics and weighting across strata, with finite-sample validity asserted under the standard randomization distribution induced by the experimental design. No quoted step reduces a claimed prediction or validity result to a fitted parameter, self-definition, or prior self-citation that itself assumes the target result. The central construction is presented as a novel aggregation that enumerates or samples the appropriate null distribution, independent of the paper's own outputs. This is the typical non-circular case for a methods paper extending randomization inference.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption The experiment follows a known randomization distribution that permits exact finite-sample inference.
- domain assumption Rank-based statistics can be defined on the observed outcomes to capture features of the individual treatment effect distribution.
Reference graph
Works this paper leans on
-
[1]
Athey, S. and Wager, S. (2021). Policy learning with observational data. Econometrica , 89(1):133--161
work page 2021
-
[2]
Bickel, P. J. and Freedman, D. A. (1984). Asymptotic Normality and the Bootstrap in Stratified Sampling . The Annals of Statistics , 12:470 -- 482
work page 1984
-
[3]
Caughey, D., Dafoe, A., Li, X., and Miratrix, L. (2023). Randomization inference beyond the sharp null: Bounded null hypotheses and quantiles of individual treatment effects. Journal of the Royal Statistical Society, Series B (Statistical Methodology) , 85:1471--1491
work page 2023
- [4]
-
[5]
Chen, Z., Li, X., and Zhang, B. (2024). The role of randomization inference in unraveling individual treatment effects in early phase vaccine trials. Statistical Communications in Infectious Diseases , 16:20240001
work page 2024
-
[6]
Fisher, R. A. (1935). The D esign of E xperiments, 1st Edition . Edinburgh, London: Oliver and Boyd
work page 1935
-
[7]
H \'a jek, J. (1960). Limiting distributions in simple random sampling from a finite population. Publications of the Mathematics Institute of the Hungarian Academy of Science , 5:361--374
work page 1960
-
[8]
J., Smith, J., and Clements, N
Heckman, J. J., Smith, J., and Clements, N. (1997). Making the most out of programme evaluations and social experiments: Accounting for heterogeneity in programme impaces. The Review of Economic Studies , 64(4):487--535
work page 1997
-
[9]
L., Shinohara, M., Miratrix, L., Hesketh, S
Heller, J. L., Shinohara, M., Miratrix, L., Hesketh, S. R., and Daehler, K. R. (2010). Learning science for teaching: Effects of professional development on elementary teachers, classrooms, and students. Proceedings from Society for Research on Educational Effectiveness
work page 2010
-
[10]
Heng, S., Zhang, J., and Feng, Y. (2025). Design-based causal inference with missing outcomes: Missingness mechanisms, imputation-assisted randomization tests, and covariate adjustment. Journal of the American Statistical Association , in press
work page 2025
-
[11]
Imai, K. and Ratkovic, M. (2013). Estimating treatment effect heterogeneity in randomized program evaluation. The Annals of Applied Statistics , 7(1):443--470
work page 2013
-
[12]
Koenker, R. (2017). Quantile regression: 40 years on. Annual review of economics , 9(1):155--176
work page 2017
-
[13]
Li, X. and Ding, P. (2017). General forms of finite population central limit theorems with applications to causal inference. Journal of the American Statistical Association , 112:1759--1769
work page 2017
-
[14]
Li, X., Sheng, P., and Yu, Z. (2025). Randomization inference with sample attrition. arXiv preprint arXiv:2507.00795
work page internal anchor Pith review arXiv 2025
-
[15]
Li, X. and Small, D. S. (2022). Randomization-based test for censored outcomes: A new look at the logrank test. Statistical Science , page To appear
work page 2022
-
[16]
Liu, H. and Yang, Y. (2020). Regression-adjusted average treatment effect estimates in stratified randomized experiments . Biometrika , 107:935--948
work page 2020
-
[17]
Manski, C. F. (2004). Statistical treatment rules for heterogeneous populations. Econometrica , 72(4):1221--1246
work page 2004
-
[18]
Neyman, J. (1923). On the application of probability theory to agricultural experiments. Essay on principles (with discussion). Section 9 (translated). reprinted ed. Statistical Science , 5:465--472
work page 1923
-
[19]
Nie, X. and Wager, S. (2021). Quasi-oracle estimation of heterogeneous treatment effects . Biometrika , 108(2):299--319
work page 2021
-
[20]
Puri, M. L. (1965). On the combination of independent two sample tests of a general class. Revue de l'Institut International de Statistique , pages 229--241
work page 1965
-
[21]
Qu, T., Du, J., and Li, X. (2025). Randomization-based z-estimation for evaluating average and individual treatment effects. Biometrika , 112(2):1--9
work page 2025
-
[22]
Rosenbaum, P. R. (2002). Observational Studies . Springer, New York, 2 edition
work page 2002
-
[23]
Rosenbaum, P. R. (2007). Confidence intervals for uncommon but dramatic responses to treatment. Biometrics , 63:1164--1171
work page 2007
-
[24]
Rosenbaum, P. R. and Silber, J. H. (2008). Aberrant effects of treatment. Journal of the American Statistical Association , 103(481):240--247
work page 2008
-
[25]
Rubin, D. B. (1974). Estimating causal effects of treatments in randomized and nonrandomized studies. Journal of Educational Psychology , 66:688--701
work page 1974
- [26]
-
[27]
Stephenson, W. R. and Ghosh, M. (1985). Two sample nonparametric tests based on subsamples. Communications in Statistics - Theory and Methods , 14:1669--1684
work page 1985
- [28]
-
[29]
Tian, L., Alizadeh, A. A., Gentles, A. J., and Tibshirani, R. (2014). A simple method for estimating interactions between a treatment and a large number of covariates. Journal of the American Statistical Association , 109:1517--1532
work page 2014
-
[30]
van Elteren, P. H. (1960). On the combination of independent two sample tests of wilcoxon. Bulletin of the Institute of International Statistics , 37:351--361
work page 1960
- [31]
-
[32]
A., Davidian, M., Zhang, M., and Laber, E
Zhang, B., Tsiatis, A. A., Davidian, M., Zhang, M., and Laber, E. (2012). Estimating optimal treatment regimes from a classification perspective. Stat , 1(1):103--114
work page 2012
-
[33]
Zhao, A., Ding, P., and Li, F. (2024). Covariate adjustment in randomized experiments with missing outcomes and covariates. Biometrika , 111:1413--1420
work page 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.