Recognition: 2 theorem links
· Lean TheoremTowards Highly-Constrained Human Motion Generation with Retrieval-Guided Diffusion Noise Optimization
Pith reviewed 2026-05-11 02:13 UTC · model grok-4.3
The pith
Retrieval-guided noise initialization enables diffusion models to satisfy severe spatiotemporal constraints in human motion generation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By introducing relational task parsing to identify difficult constraints and a reward-guided mask to combine retrieved reference noise with random noise for better initialization, optimizing the diffusion noise from this point allows the generation of human motions that meet highly challenging zero-shot goal functions, such as those involving severe spatial obstacles or precise step counts.
What carries the argument
The reward-guided mask that blends random diffusion noise with noise from retrieved reference motions to create an improved initialization for the training-free diffusion noise optimization process.
If this is right
- It enables solving tasks with severe spatial obstacles or specified numbers of walking steps that defeat prior methods.
- LLM-based relational parsing allows automatic reasoning about what references to retrieve for a given task.
- The training-free scheme keeps the method applicable without additional model training.
- Applications in controllable character animation and virtual agent behavior synthesis become more feasible.
Where Pith is reading between the lines
- This approach might connect to retrieval-augmented generation techniques used in other AI domains like language or image synthesis.
- Testing the method on constraints requiring motions not well-represented in existing datasets could reveal its boundaries.
- Extending the relational parsing to handle multi-agent or interactive scenarios could be a natural next step.
Load-bearing premise
Suitable reference motions for the difficult constraints exist in the available datasets and can be identified and combined effectively through LLM parsing and reward-guided masking.
What would settle it
A counterexample would be a set of highly constrained tasks where the method, even with the retrieval-guided initialization, produces motions that violate the specified spatiotemporal constraints at a similar rate to standard diffusion noise optimization without retrieval.
Figures
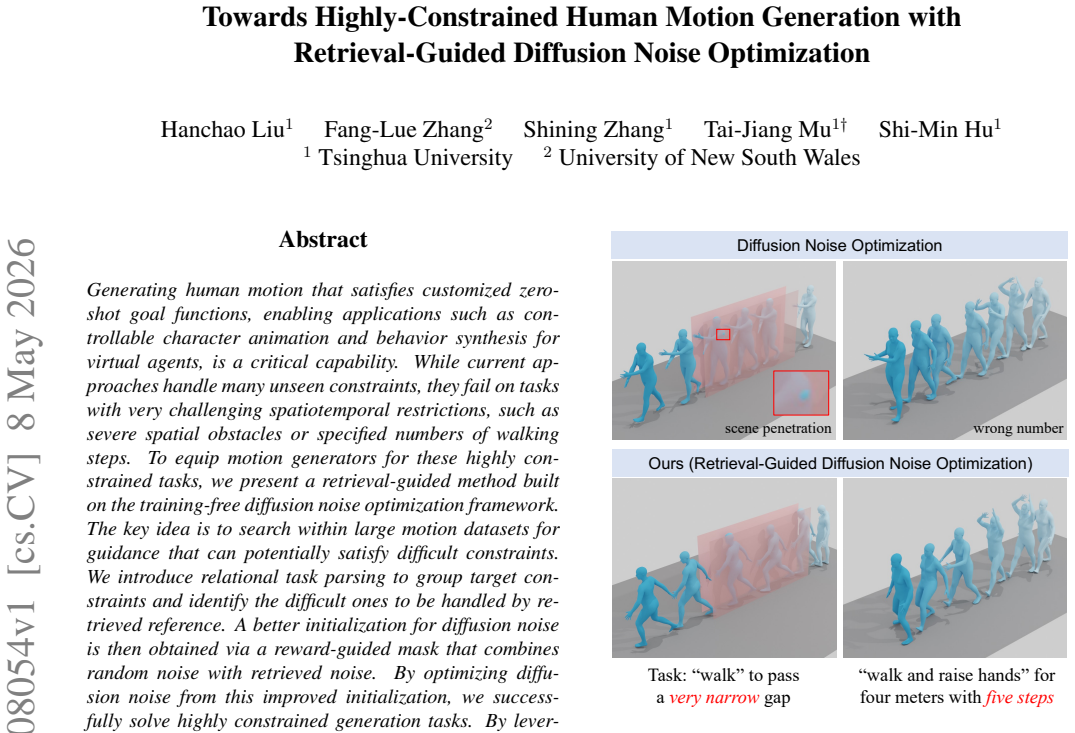
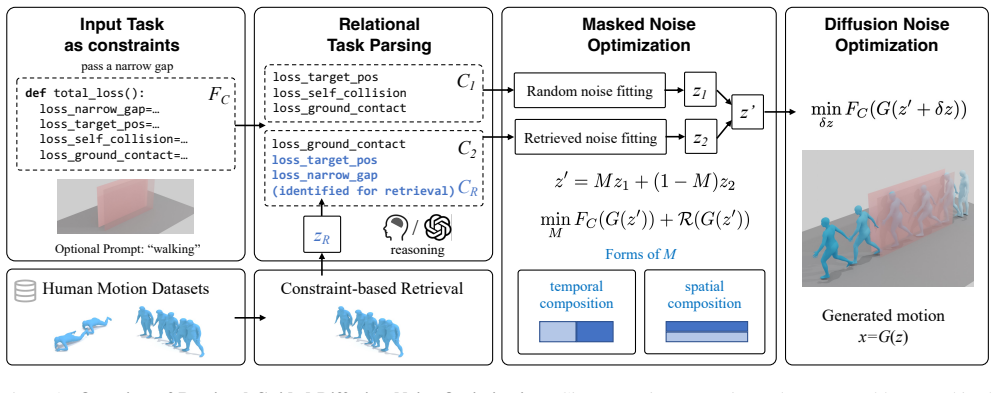


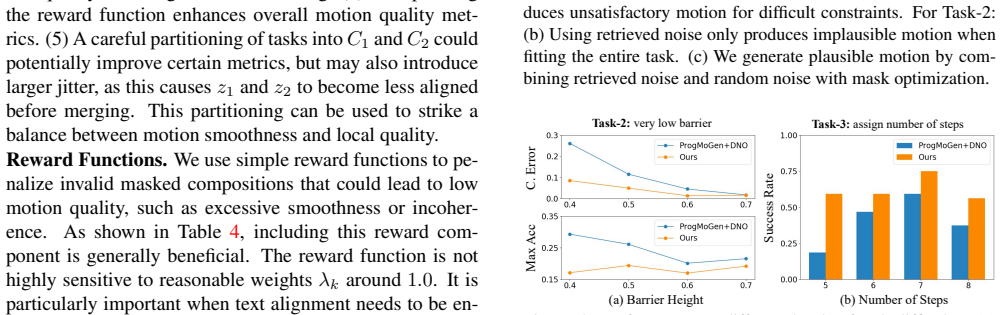

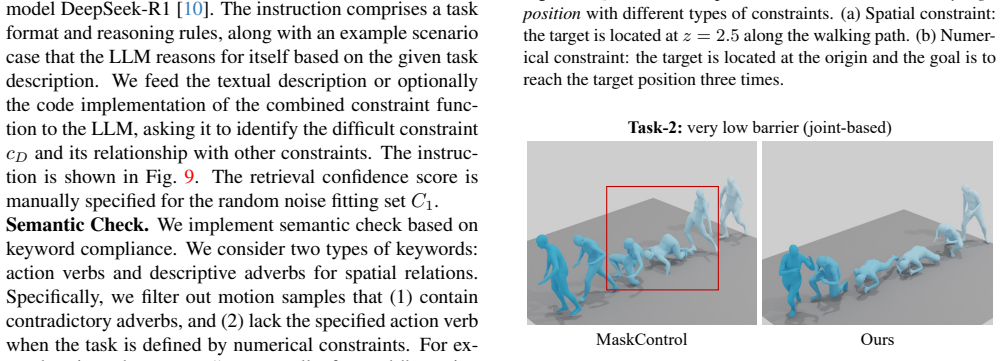

read the original abstract
Generating human motion that satisfies customized zero-shot goal functions, enabling applications such as controllable character animation and behavior synthesis for virtual agents, is a critical capability. While current approaches handle many unseen constraints, they fail on tasks with very challenging spatiotemporal restrictions, such as severe spatial obstacles or specified numbers of walking steps. To equip motion generators for these highly constrained tasks, we present a retrieval-guided method built on the training-free diffusion noise optimization framework. The key idea is to search within large motion datasets for guidance that can potentially satisfy difficult constraints. We introduce relational task parsing to group target constraints and identify the difficult ones to be handled by retrieved reference. A better initialization for diffusion noise is then obtained via a reward-guided mask that combines random noise with retrieved noise. By optimizing diffusion noise from this improved initialization, we successfully solve highly constrained generation tasks. By leveraging LLM for relational task parsing, the whole framework is further enabled to automatically reason for what to retrieve, improving the intelligence of moving agents under a training-free optimization scheme.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a retrieval-guided method for highly-constrained zero-shot human motion generation built on training-free diffusion noise optimization. It introduces LLM-based relational task parsing to group constraints and flag difficult sub-tasks, retrieves reference motions from large datasets, and constructs an improved diffusion-noise initialization via a reward-guided mask that blends retrieved noise with random noise. Optimizing from this initialization is claimed to solve spatiotemporal tasks (e.g., severe obstacles or exact step counts) that standard diffusion generators cannot handle.
Significance. If the retrieval and masking steps reliably produce initializations that allow noise optimization to succeed on tasks where plain diffusion fails, the work would provide a practical, training-free route to more controllable motion synthesis for animation and virtual agents. The combination of dataset retrieval with LLM reasoning for constraint decomposition is a plausible way to inject external knowledge without retraining.
major comments (2)
- [Abstract] Abstract: the assertion that the method 'successfully solve[s] highly constrained generation tasks' is stated without any quantitative results, success rates, baseline comparisons, ablation studies, or metrics for constraint satisfaction. This is load-bearing for the central claim that the improved initialization outperforms standard diffusion on difficult spatiotemporal constraints.
- [Method] Method (relational task parsing and retrieval pipeline): the advantage of the reward-guided mask rests on the unverified assumptions that (i) sufficiently close reference motions exist in the dataset for arbitrary novel constraint sets and (ii) the LLM parser correctly identifies and groups difficult sub-tasks. No retrieval-precision statistics, coverage analysis, or failure-case handling are described, leaving open the possibility that the initialization offers no benefit over the baseline the paper says cannot solve these tasks.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our work. We address each major comment point by point below, providing clarifications and indicating revisions made to the manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the assertion that the method 'successfully solve[s] highly constrained generation tasks' is stated without any quantitative results, success rates, baseline comparisons, ablation studies, or metrics for constraint satisfaction. This is load-bearing for the central claim that the improved initialization outperforms standard diffusion on difficult spatiotemporal constraints.
Authors: We agree that the abstract would benefit from explicitly referencing the supporting quantitative evidence. The full manuscript includes experiments (Section 4) with success rates on spatiotemporal constraint satisfaction, direct comparisons to standard diffusion noise optimization baselines, and ablations isolating the retrieval and reward-guided mask components. To address the concern, we have revised the abstract to include a concise summary of these key empirical results supporting the central claim. revision: yes
-
Referee: [Method] Method (relational task parsing and retrieval pipeline): the advantage of the reward-guided mask rests on the unverified assumptions that (i) sufficiently close reference motions exist in the dataset for arbitrary novel constraint sets and (ii) the LLM parser correctly identifies and groups difficult sub-tasks. No retrieval-precision statistics, coverage analysis, or failure-case handling are described, leaving open the possibility that the initialization offers no benefit over the baseline the paper says cannot solve these tasks.
Authors: The referee correctly notes that the method's effectiveness depends on dataset coverage and LLM parsing reliability. The manuscript uses established large-scale motion datasets (e.g., those containing thousands of diverse sequences) and LLM-based relational parsing to identify and group difficult sub-tasks, with the reward-guided mask designed to blend relevant retrieved noise. We acknowledge the absence of explicit retrieval-precision statistics or coverage analysis. We have made a partial revision by adding a discussion subsection on dataset coverage assumptions, LLM parsing examples, and qualitative failure-case handling; a full quantitative retrieval analysis would require new experiments and is noted as a direction for future work. revision: partial
Circularity Check
No circularity: procedural pipeline without derivations or self-referential reductions
full rationale
The paper describes a retrieval-guided diffusion noise optimization method as a sequence of steps: LLM-based relational task parsing to identify difficult constraints, retrieval of reference motions from datasets, reward-guided masking to create improved noise initialization, and subsequent optimization. No equations, mathematical derivations, fitted parameters, or predictions are present that reduce any claim to its own inputs by construction. No self-citations are used to justify uniqueness theorems, ansatzes, or load-bearing premises. The method is self-contained as an engineering pipeline whose success depends on external dataset coverage and LLM reliability rather than internal definitional loops. This matches the default expectation of no significant circularity for descriptive procedural papers.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Foundation/RealityFromDistinction.leanreality_from_one_distinction unclearBy optimizing diffusion noise from this improved initialization, we successfully solve highly constrained generation tasks.
Reference graph
Works this paper leans on
-
[1]
Sinc: Spatial composition of 3d human motions for simultaneous action generation
Nikos Athanasiou, Mathis Petrovich, Michael J Black, and G¨ul Varol. Sinc: Spatial composition of 3d human motions for simultaneous action generation. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9984–9995, 2023. 2
work page 2023
-
[2]
Pose-guided motion diffusion model for text- to-motion generation
Xinhao Cai, Minghang Zheng, Qingchao Chen, Yuxin Peng, and Yang Liu. Pose-guided motion diffusion model for text- to-motion generation. 2
-
[3]
Masactrl: Tuning-free mu- tual self-attention control for consistent image synthesis and editing
Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xi- aohu Qie, and Yinqiang Zheng. Masactrl: Tuning-free mu- tual self-attention control for consistent image synthesis and editing. InProceedings of the IEEE/CVF international con- ference on computer vision, pages 22560–22570, 2023. 2
work page 2023
-
[4]
Executing your commands via motion diffusion in latent space
Xin Chen, Biao Jiang, Wen Liu, Zilong Huang, Bin Fu, Tao Chen, and Gang Yu. Executing your commands via motion diffusion in latent space. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18000–18010, 2023. 2, 3
work page 2023
-
[5]
Gmt: General motion tracking for humanoid whole-body control,
Zixuan Chen, Mazeyu Ji, Xuxin Cheng, Xuanbin Peng, Xue Bin Peng, and Xiaolong Wang. Gmt: Gen- eral motion tracking for humanoid whole-body control. arXiv:2506.14770, 2025. 1
-
[6]
Luca Eyring, Shyamgopal Karthik, Karsten Roth, Alexey Dosovitskiy, and Zeynep Akata. Reno: Enhancing one-step text-to-image models through reward-based noise optimiza- tion.Advances in Neural Information Processing Systems, 37:125487–125519, 2024. 2, 8
work page 2024
-
[7]
Go to zero: Towards zero-shot motion generation with million-scale data
Ke Fan, Shunlin Lu, Minyue Dai, Runyi Yu, Lixing Xiao, Zhiyang Dou, Junting Dong, Lizhuang Ma, and Jingbo Wang. Go to zero: Towards zero-shot motion generation with million-scale data. InProceedings of the IEEE/CVF In- ternational Conference on Computer Vision, pages 13336– 13348, 2025. 2, 4
work page 2025
-
[8]
Generating diverse and natural 3d human motions from text
Chuan Guo, Shihao Zou, Xinxin Zuo, Sen Wang, Wei Ji, Xingyu Li, and Li Cheng. Generating diverse and natural 3d human motions from text. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5152–5161, 2022. 3, 6
work page 2022
-
[9]
Momask: Generative masked model- ing of 3d human motions
Chuan Guo, Yuxuan Mu, Muhammad Gohar Javed, Sen Wang, and Li Cheng. Momask: Generative masked model- ing of 3d human motions. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1900–1910, 2024. 6
work page 1900
-
[10]
DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
Daya Guo, Dejian Yang, Haowei Zhang, Junxiao Song, Ruoyu Zhang, Runxin Xu, Qihao Zhu, Shirong Ma, Peiyi Wang, Xiao Bi, et al. Deepseek-r1: Incentivizing reasoning capability in llms via reinforcement learning.arXiv preprint arXiv:2501.12948, 2025. 7, 1
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[11]
Initno: Boosting text-to-image diffu- sion models via initial noise optimization
Xiefan Guo, Jinlin Liu, Miaomiao Cui, Jiankai Li, Hongyu Yang, and Di Huang. Initno: Boosting text-to-image diffu- sion models via initial noise optimization. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 9380–9389, 2024. 2
work page 2024
-
[12]
Atom: Aligning text-to-motion model at event-level with gpt-4vision reward
Haonan Han, Xiangzuo Wu, Huan Liao, Zunnan Xu, Zhongyuan Hu, Ronghui Li, Yachao Zhang, and Xiu Li. Atom: Aligning text-to-motion model at event-level with gpt-4vision reward. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 22746–22755,
-
[13]
Shuaiying Hou, Congyi Wang, Wenlin Zhuang, Yu Chen, Yangang Wang, Hujun Bao, Jinxiang Chai, and Weiwei Xu. A causal convolutional neural network for multi-subject mo- tion modeling and generation.Computational Visual Media, 10(1):45–59, 2024. 2
work page 2024
-
[14]
Como: Controllable motion generation through language guided pose code edit- ing
Yiming Huang, Weilin Wan, Yue Yang, Chris Callison- Burch, Mark Yatskar, and Lingjie Liu. Como: Controllable motion generation through language guided pose code edit- ing. InEuropean Conference on Computer Vision, pages 180–196. Springer, 2024. 2
work page 2024
-
[15]
Biao Jiang, Xin Chen, Wen Liu, Jingyi Yu, Gang Yu, and Tao Chen. Motiongpt: Human motion as a foreign lan- guage.Advances in Neural Information Processing Systems, 36:20067–20079, 2023. 2
work page 2023
-
[16]
Guided motion diffusion for controllable human motion synthesis
Korrawe Karunratanakul, Konpat Preechakul, Supasorn Suwajanakorn, and Siyu Tang. Guided motion diffusion for controllable human motion synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 2151–2162, 2023. 1, 2
work page 2023
-
[17]
Opti- mizing diffusion noise can serve as universal motion priors
Korrawe Karunratanakul, Konpat Preechakul, Emre Aksan, Thabo Beeler, Supasorn Suwajanakorn, and Siyu Tang. Opti- mizing diffusion noise can serve as universal motion priors. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1334–1345, 2024. 1, 2, 3, 5, 6, 7, 4
work page 2024
-
[18]
Adam: A Method for Stochastic Optimization
Diederik P Kingma and Jimmy Ba. Adam: A method for stochastic optimization.arXiv preprint arXiv:1412.6980,
work page internal anchor Pith review Pith/arXiv arXiv
-
[19]
Joohyeon Lee, Jin-Seop Lee, and Jee-Hyong Lee. Count- cluster: Training-free object quantity guidance with cross- attention map clustering for text-to-image generation.arXiv preprint arXiv:2508.10710, 2025. 2
-
[20]
Weiyu Li, Xuelin Chen, Peizhuo Li, Olga Sorkine-Hornung, and Baoquan Chen. Example-based motion synthesis via generative motion matching.ACM Transactions on Graphics (TOG), 42(4):1–12, 2023. 2
work page 2023
-
[21]
Simmotionedit: Text-based human motion editing with motion similarity pre- diction
Zhengyuan Li, Kai Cheng, Anindita Ghosh, Uttaran Bhat- tacharya, Liangyan Gui, and Aniket Bera. Simmotionedit: Text-based human motion editing with motion similarity pre- diction. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 27827–27837, 2025. 2
work page 2025
-
[22]
Re- momask: Retrieval-augmented masked motion generation
Zhengdao Li, Siheng Wang, Zeyu Zhang, and Hao Tang. Re- momask: Retrieval-augmented masked motion generation. arXiv preprint arXiv:2508.02605, 2025. 2
-
[23]
Zhouyingcheng Liao, Mingyuan Zhang, Wenjia Wang, Lei Yang, and Taku Komura. Rmd: A simple baseline for more general human motion generation via training- free retrieval-augmented motion diffuse.arXiv preprint arXiv:2412.04343, 2024. 2 9
-
[24]
Programmable motion generation for open- set motion control tasks
Hanchao Liu, Xiaohang Zhan, Shaoli Huang, Tai-Jiang Mu, and Ying Shan. Programmable motion generation for open- set motion control tasks. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 1399–1408, 2024. 1, 2, 3, 4, 5, 6, 7
work page 2024
-
[25]
Smpl: A skinned multi- person linear model.ACM Transactions on Graphics, 34(6),
Matthew Loper, Naureen Mahmood, Javier Romero, Gerard Pons-Moll, and Michael J Black. Smpl: A skinned multi- person linear model.ACM Transactions on Graphics, 34(6),
-
[26]
Amass: Archive of motion capture as surface shapes
Naureen Mahmood, Nima Ghorbani, Nikolaus F Troje, Ger- ard Pons-Moll, and Michael J Black. Amass: Archive of motion capture as surface shapes. InProceedings of the IEEE/CVF international conference on computer vision, pages 5442–5451, 2019. 6
work page 2019
-
[27]
Generation of com- plex 3d human motion by temporal and spatial composition of diffusion models
Lorenzo Mandelli and Stefano Berretti. Generation of com- plex 3d human motion by temporal and spatial composition of diffusion models. In2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), pages 1279–
-
[28]
Noise diffusion for en- hancing semantic faithfulness in text-to-image synthesis
Boming Miao, Chunxiao Li, Xiaoxiao Wang, Andi Zhang, Rui Sun, Zizhe Wang, and Yao Zhu. Noise diffusion for en- hancing semantic faithfulness in text-to-image synthesis. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 23575–23584, 2025. 2, 4
work page 2025
-
[29]
To- kenhsi: Unified synthesis of physical human-scene inter- actions through task tokenization
Liang Pan, Zeshi Yang, Zhiyang Dou, Wenjia Wang, Buzhen Huang, Bo Dai, Taku Komura, and Jingbo Wang. To- kenhsi: Unified synthesis of physical human-scene inter- actions through task tokenization. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 5379–5391, 2025. 1
work page 2025
-
[30]
Tmr: Text-to-motion retrieval using contrastive 3d human motion synthesis
Mathis Petrovich, Michael J Black, and G ¨ul Varol. Tmr: Text-to-motion retrieval using contrastive 3d human motion synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 9488–9497, 2023. 5
work page 2023
-
[31]
Multi-track timeline control for text-driven 3d human motion genera- tion
Mathis Petrovich, Or Litany, Umar Iqbal, Michael J Black, Gul Varol, Xue Bin Peng, and Davis Rempe. Multi-track timeline control for text-driven 3d human motion genera- tion. In2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), pages 1911–
work page 1911
-
[32]
IEEE Computer Society, 2024. 2, 4
work page 2024
-
[33]
Autoedit: Automatic hyperparameter tuning for image editing.arXiv preprint arXiv:2509.15031, 2025
Chau Pham, Quan Dao, Mahesh Bhosale, Yunjie Tian, Dim- itris Metaxas, and David Doermann. Autoedit: Automatic hyperparameter tuning for image editing.arXiv preprint arXiv:2509.15031, 2025. 2
-
[34]
Maskcon- trol: Spatio-temporal control for masked motion synthesis
Ekkasit Pinyoanuntapong, Muhammad Saleem, Korrawe Karunratanakul, Pu Wang, Hongfei Xue, Chen Chen, Chuan Guo, Junli Cao, Jian Ren, and Sergey Tulyakov. Maskcon- trol: Spatio-temporal control for masked motion synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 9955–9965, 2025. 1, 2, 6, 4
work page 2025
-
[35]
arXiv preprint arXiv:2407.14041 , year=
Zipeng Qi, Lichen Bai, Haoyi Xiong, and Zeke Xie. Not all noises are created equally: Diffusion noise selection and optimization.arXiv preprint arXiv:2407.14041, 2024. 2
-
[36]
Human motion diffusion as a generative prior
Yoni Shafir, Guy Tevet, Roy Kapon, and Amit Haim Bermano. Human motion diffusion as a generative prior. InThe Twelfth International Conference on Learning Rep- resentations, 2023. 2
work page 2023
-
[37]
Denois- ing diffusion implicit models
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denois- ing diffusion implicit models. InInternational Conference on Learning Representations, 2020. 3
work page 2020
-
[38]
Sopo: Text-to-motion generation using semi-online prefer- ence optimization
Xiaofeng Tan, Hongsong Wang, Xin Geng, and Pan Zhou. Sopo: Text-to-motion generation using semi-online prefer- ence optimization. InAdvances in Neural Information Pro- cessing Systems, 2025. 2
work page 2025
-
[39]
Human motion diffu- sion model
Guy Tevet, Sigal Raab, Brian Gordon, Yoni Shafir, Daniel Cohen-or, and Amit Haim Bermano. Human motion diffu- sion model. InThe Eleventh International Conference on Learning Representations, 2022. 2, 3, 6
work page 2022
-
[40]
Tlcontrol: Trajec- tory and language control for human motion synthesis
Weilin Wan, Zhiyang Dou, Taku Komura, Wenping Wang, Dinesh Jayaraman, and Lingjie Liu. Tlcontrol: Trajec- tory and language control for human motion synthesis. In European Conference on Computer Vision, pages 37–54. Springer, 2024. 1, 2
work page 2024
-
[41]
Diffusion models for 3d generation: A survey
Chen Wang, Hao-Yang Peng, Ying-Tian Liu, Jiatao Gu, and Shi-Min Hu. Diffusion models for 3d generation: A survey. Computational Visual Media, 11(1):1–28, 2025. 2
work page 2025
-
[42]
Aligning human motion genera- tion with human perceptions
Haoru Wang, Wentao Zhu, Luyi Miao, Yishu Xu, Feng Gao, Qi Tian, and Yizhou Wang. Aligning human motion genera- tion with human perceptions. InThe Thirteenth International Conference on Learning Representations, 2025. 2, 8
work page 2025
-
[43]
Sims: Simulating stylized human- scene interactions with retrieval-augmented script genera- tion
Wenjia Wang, Liang Pan, Zhiyang Dou, Jidong Mei, Zhouy- ingcheng Liao, Yuke Lou, Yifan Wu, Lei Yang, Jingbo Wang, and Taku Komura. Sims: Simulating stylized human- scene interactions with retrieval-augmented script genera- tion. InProceedings of the IEEE/CVF International Con- ference on Computer Vision, pages 14117–14127, 2025. 2
work page 2025
-
[44]
Weiyan Xie, Han Gao, Didan Deng, Kaican Li, April Hua Liu, Yongxiang Huang, and Nevin L Zhang. Cannyedit: Se- lective canny control and dual-prompt guidance for training- free image editing.arXiv preprint arXiv:2508.06937, 2025. 2
-
[45]
Omnicontrol: Control any joint at any time for human motion generation
Yiming Xie, Varun Jampani, Lei Zhong, Deqing Sun, and Huaizu Jiang. Omnicontrol: Control any joint at any time for human motion generation. InThe Twelfth International Conference on Learning Representations, 2023. 1, 2
work page 2023
-
[46]
Haidong Xu, Guangwei Xu, Zhedong Zheng, Xiatian Zhu, Wei Ji, Xiangtai Li, Ruijie Guo, Meishan Zhang, Hao Fei, et al. Vimorag: Video-based retrieval-augmented 3d mo- tion generation for motion language models.arXiv preprint arXiv:2508.12081, 2025. 2
-
[47]
Good seed makes a good crop: Discovering secret seeds in text-to- image diffusion models
Katherine Xu, Lingzhi Zhang, and Jianbo Shi. Good seed makes a good crop: Discovering secret seeds in text-to- image diffusion models. In2025 IEEE/CVF Winter Con- ference on Applications of Computer Vision (WACV), pages 3024–3034. IEEE, 2025. 2
work page 2025
-
[48]
Xinyu Xu, Yizheng Zhang, Yong-Lu Li, Lei Han, and Cewu Lu. Humanvla: Towards vision-language directed object re- arrangement by physical humanoid.Advances in Neural In- formation Processing Systems, 37:18633–18659, 2024. 1
work page 2024
-
[49]
Re- modiffuse: Retrieval-augmented motion diffusion model
Mingyuan Zhang, Xinying Guo, Liang Pan, Zhongang Cai, Fangzhou Hong, Huirong Li, Lei Yang, and Ziwei Liu. Re- modiffuse: Retrieval-augmented motion diffusion model. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 364–373, 2023. 2 10
work page 2023
-
[50]
Mingyuan Zhang, Zhongang Cai, Liang Pan, Fangzhou Hong, Xinying Guo, Lei Yang, and Ziwei Liu. Motiondif- fuse: Text-driven human motion generation with diffusion model.IEEE transactions on pattern analysis and machine intelligence, 46(6):4115–4128, 2024. 2
work page 2024
-
[51]
Rohm: Robust human motion reconstruction via diffusion
Siwei Zhang, Bharat Lal Bhatnagar, Yuanlu Xu, Alexan- der Winkler, Petr Kadlecek, Siyu Tang, and Federica Bogo. Rohm: Robust human motion reconstruction via diffusion. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 14606–14617, 2024. 3, 6
work page 2024
-
[52]
Kaifeng Zhao, Gen Li, and Siyu Tang. Dartcontrol: A diffusion-based autoregressive motion model for real-time text-driven motion control. InThe Thirteenth International Conference on Learning Representations, 2025. 2 11 Towards Highly-Constrained Human Motion Generation with Retrieval-Guided Diffusion Noise Optimization Supplementary Material This supplem...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.