Recognition: no theorem link
Empirical Bayes Rebiasing
Pith reviewed 2026-05-11 01:59 UTC · model grok-4.3
The pith
Estimating the distribution of biases from noisy observations allows controlled rebiasing of debiased estimates to produce shorter intervals with valid coverage.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
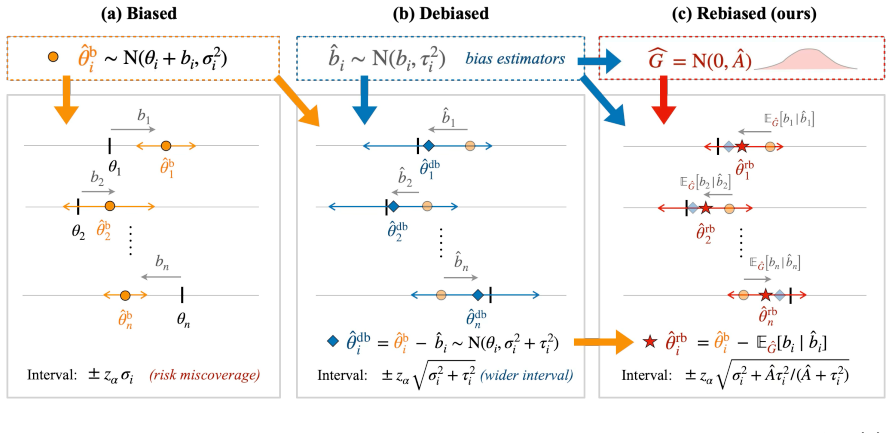
Starting from fully debiased estimates and rebiasing them according to a nonparametric maximum likelihood estimate of the unknown bias distribution yields intervals whose coverage converges to the nominal level at explicit rates while achieving shorter length than full debiasing.
What carries the argument
Nonparametric maximum likelihood estimator of the bias distribution, used to select the amount of bias to reintroduce into each debiased estimate.
If this is right
- Explicit convergence rates are obtained for the coverage of the rebiasing intervals when the bias distribution is estimated by nonparametric maximum likelihood.
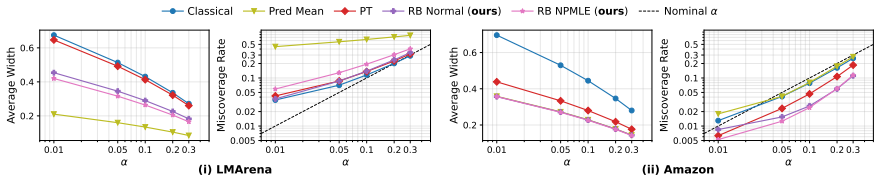
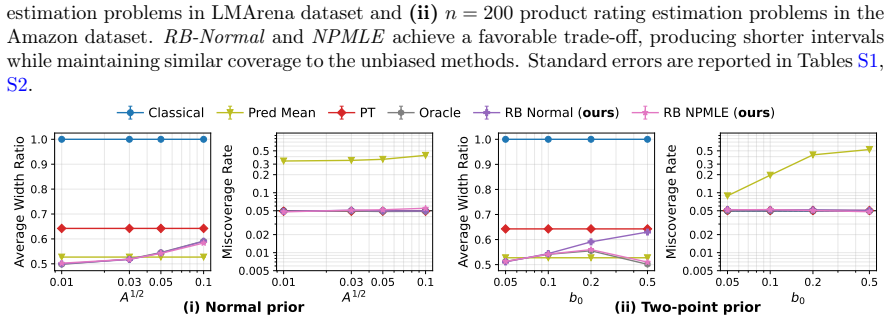
- Substantial reductions in interval length are achieved while maintaining coverage in prediction-powered inference settings, including pairwise win-rate comparisons of large language models.
- Precision gains appear for inference on direct genetic effects in family-based genome-wide association studies.
Where Pith is reading between the lines
- The same rebiasing logic could be applied in other high-dimensional settings where auxiliary noisy estimates of bias or measurement error are available for each observation.
- If faster rates are needed, replacing the nonparametric estimator with a correctly specified parametric model for the bias distribution would be a direct extension.
Load-bearing premise
The unknown bias distribution can be estimated consistently from the collection of noisy bias estimates at a rate fast enough for the coverage guarantees to hold.
What would settle it
Empirical coverage of the resulting intervals fails to approach the nominal level as the number of estimates grows, even when the bias distribution is estimated via nonparametric maximum likelihood under the paper's stated conditions.
Figures

read the original abstract
We study methods for simultaneous analysis of many noisy and biased estimates, each paired with an even noisier estimate of its own bias. The analyst's goal is to construct short calibrated intervals for each parameter. The standard debiasing approach, which subtracts the bias estimate from each biased estimate, inflates variance and yields long intervals. In this paper, we propose an empirical Bayes rebiasing strategy that starts from the fully debiased estimates and learns from data how much bias to reintroduce by estimating the unknown bias distribution. We provide convergence rates for the coverage of our intervals when the bias distribution is estimated using nonparametric maximum likelihood. Furthermore, we demonstrate substantial precision gains in prediction-powered inference, including pairwise LLM win-rate evaluations, as well as for inference of direct genetic effects in family-based GWAS.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes an empirical Bayes rebiasing method for simultaneous inference on many parameters, each observed via a noisy biased estimate paired with an even noisier bias estimate. Starting from fully debiased point estimates, the approach estimates the unknown bias distribution via nonparametric maximum likelihood estimation (NPMLE) and reintroduces an appropriate amount of bias to produce shorter calibrated intervals. It derives convergence rates for the coverage of these intervals under NPMLE estimation of the bias distribution and illustrates precision improvements in prediction-powered inference (including LLM pairwise win-rate evaluations) and family-based GWAS for direct genetic effects.
Significance. If the stated convergence rates hold, the work provides a theoretically grounded alternative to variance-inflating debiasing by leveraging the empirical distribution of biases, potentially yielding shorter intervals with valid frequentist coverage. The explicit rates tied to NPMLE convergence constitute a technical contribution in the empirical Bayes literature, and the applications to modern settings like LLM evaluation and GWAS demonstrate relevance beyond classical simultaneous inference. The construction follows standard plug-in empirical Bayes logic but focuses on coverage control after re-biasing.
major comments (2)
- [§4] §4 (theoretical results on coverage): The convergence rate for interval coverage is stated to vanish when the NPMLE of the bias distribution converges sufficiently fast, but the manuscript does not explicitly derive or bound the plug-in coverage error in terms of the NPMLE estimation rate (e.g., the sup-norm or Wasserstein distance to the true bias distribution). This makes it difficult to verify whether the claimed rates are tight or require additional assumptions on the bias distribution (such as compact support or smoothness).
- [§5] §5 (applications): In the prediction-powered inference example, the reported precision gains rely on the rebiasing intervals being shorter than debiased ones while maintaining coverage; however, the simulation or real-data analysis does not include a direct comparison of coverage under the estimated versus oracle bias distribution, which is needed to confirm that the NPMLE rate is adequate in finite samples.
minor comments (3)
- [§2] Notation for the bias distribution and its NPMLE estimator is introduced without a dedicated preliminary section; a short subsection defining G, Ĝ_n, and the resulting interval construction would improve readability.
- [Abstract and §4] The abstract claims 'convergence rates' but the main text should state the precise rate (e.g., O(n^{-α}) for specific α) rather than only the o(1) vanishing property.
- [§5] Figure captions for the GWAS and LLM examples should include the exact sample sizes and number of parameters to allow readers to assess the regime in which the method is applied.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major point below. Both comments identify places where the manuscript can be strengthened with additional explicit derivations and finite-sample checks; we will incorporate these changes in a revised version.
read point-by-point responses
-
Referee: [§4] §4 (theoretical results on coverage): The convergence rate for interval coverage is stated to vanish when the NPMLE of the bias distribution converges sufficiently fast, but the manuscript does not explicitly derive or bound the plug-in coverage error in terms of the NPMLE estimation rate (e.g., the sup-norm or Wasserstein distance to the true bias distribution). This makes it difficult to verify whether the claimed rates are tight or require additional assumptions on the bias distribution (such as compact support or smoothness).
Authors: We agree that an explicit bound on the plug-in error would improve clarity. The coverage difference between the estimated and oracle intervals is controlled by the Lipschitz constant of the coverage functional with respect to the Wasserstein-1 distance between bias distributions; we will insert a new lemma in §4 that states |Cov(plug-in) - Cov(oracle)| ≤ L · W_1(Ĝ, G) + o(1), where L depends on the interval construction and the boundedness of the bias support (already assumed in the paper for NPMLE consistency). The overall rate then follows directly from the known W_1 convergence rate of the NPMLE under compact support. The revision will also state that the rates are not claimed to be minimax without these assumptions. revision: yes
-
Referee: [§5] §5 (applications): In the prediction-powered inference example, the reported precision gains rely on the rebiasing intervals being shorter than debiased ones while maintaining coverage; however, the simulation or real-data analysis does not include a direct comparison of coverage under the estimated versus oracle bias distribution, which is needed to confirm that the NPMLE rate is adequate in finite samples.
Authors: We accept that a direct oracle comparison would strengthen the finite-sample evidence. In the revised §5 we will add a simulation panel that reports empirical coverage for both the NPMLE-based rebiasing intervals and the oracle-bias intervals across n = 500, 2000, 5000, confirming that the coverage gap shrinks at the rate predicted by the theory. For the LLM win-rate application we will include a bootstrap-based coverage diagnostic that approximates the oracle behavior. revision: yes
Circularity Check
No significant circularity; coverage rates tied to external NPMLE convergence
full rationale
The paper's central derivation begins with debiased estimates, estimates the bias distribution nonparametrically via NPMLE, and reintroduces bias to form shorter calibrated intervals. Coverage convergence rates are stated conditionally on the NPMLE achieving sufficient uniform convergence to the true bias distribution—an external property of the deconvolution estimator, not defined circularly in terms of the resulting intervals or fitted values. No self-definitional steps, no predictions that reduce to fitted inputs by construction, and no load-bearing self-citations that substitute for independent justification. The construction is a standard empirical-Bayes plug-in whose guarantees follow from standard uniform convergence arguments on the estimated prior.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The bias distribution admits consistent nonparametric maximum likelihood estimation from the collection of noisy bias estimates.
Reference graph
Works this paper leans on
- [1]
-
[2]
J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova. Bert: Pre-training of deep bidirectional trans- formers for language understanding. InProceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, volume1, pages 4171–4186,
work page 2019
- [3]
- [4]
-
[5]
Asymptotics for least absolute deviation regression estimators,
Y. Polyanskiy and Y. Wu. Self-regularizing property of nonparametric maximum likelihood estimator in mixture models.arXiv preprint, arXiv:2008.08244,
-
[6]
14 E. T. Rosenman, G. Basse, A. B. Owen, and M. Baiocchi. Combining observational and experimental datasets using shrinkage estimators.Biometrics, page biom.13827, 2023a. E. T. R. Rosenman, F. Dominici, and L. Miratrix. Empirical Bayes double shrinkage for combining biased and unbiased causal estimates.arXiv preprint, arXiv:2309.06727, 2023b. D. B. Rubin....
-
[7]
B. Wu, S. Salazar, D. P. Green, and D. M. Blei. The Illusion of learning from observational data: An empirical Bayes perspective.arXiv preprint, arXiv:2604.08853,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
B Details on applications (Section
that are equally spaced between the smallest and largest value of{ˆb1, ...,ˆbn}, and we optimize (9) over all possible distributions supported on this finite grid, which is a conic programing problem and we solve it with the interior point convex programming solver MOSEK MOSEK ApS [2024]. B Details on applications (Section
work page 2024
-
[9]
For every choice of λi, ˆθi,λi is unbiased sinceE[ ˜Z h i ] =E[ ¯Z h i ] =µ i
and ˆθPPI i (λi = 1). For every choice of λi, ˆθi,λi is unbiased sinceE[ ˜Z h i ] =E[ ¯Z h i ] =µ i. A direct computation gives Var[ˆθi,λi] = w2 i mi +λ 2 i v2 i 1 Mi + 1 mi − 2λi ci mi .(S6) Minimizing this variance with respect toλi yields the optimal power tuning parameter λ∗ i = Mi mi +M i ci v2 i ,(S7) and the corresponding power-tuned (PT) estimator...
work page 2024
-
[10]
For notation simplicity, we denote Σi = (Σi,jq) := ˜σ2 i γi˜σiτi γi˜σiτi τ 2 i ,Ω i = (Ωi,jq) := Σ−1 i . Start by defining the class of marginal densities ofˆbi acrossi, Fn := n f(1) G′ , ..., f(n) G′ :G ′ ∈ G o ,(S12) whereGis the set of all possible priorsG ′, and f(i) G′ (l)≡f G′(l; Σi,22) := Z φ(l−b; Σ i,22) dG′(b). Define the supremum norm in bounded...
work page 2020
-
[11]
Di(G)−D i(bG) Di( ˆG∗) 1(A) # = 2 n nX i=1 EG
Again, we takeBn :=C B √logn. LetS={(f (1) Gj , ..., f(n) Gj ) :j∈ J } ⊆ F −1 n ,J={1, ..., J},J= #Sbe a proper(∥·∥ ∞,Bn , η)-cover ofF −1 n . Here, a proper cover means that the centers of the cover are themselves elements ofF−1 n . Lemma 5 provides a cover for a larger class of functions, however, it is not a proper cover forF−1 n . By a standard argume...
work page 2025
-
[12]
replicates, all our results can be obtained within 5 minutes. D.1 LMArena Table S1: LMArena results acrossα∈ {0.01,0.05,0.10,0.20,0.30}, averaged overK= 200random labeled/unlabeled splits withn= 298pairwise LLM problems. Each cell reports mean±1 Monte- Carlo SE.Classicalis the interval without ML information;Pred Meanis the prediction-only interval; PTden...
work page 2025
-
[13]
are publicly available athttps://thessgac.com. The estimates were obtained by running family-based SNP-wise regressions on44,570“white British” individuals in the UK Biobank [Bycroft et al., 2018], controlling for 40 genetic principal components and other covariates. Sibling (close to our target direct effect) estimate summary statistics from Howe et al
work page 2018
-
[14]
are accessible from OpenGWAS [Elsworth et al., 2020] through theieugwasrR package [Hemani et al., 2025] with OpenGWAS ID ieu-b-4813. 1000 GenomesPhase3EURreferencepanel[1000GenomesProjectConsortiumetal.,2015]canbeobtained fromhttp://fileserve.mrcieu.ac.uk/ld/1kg.v3.tgz. 37 Details on overlap and LD-matching analysis.For each height analysis in Howe et al....
work page 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.