Recognition: no theorem link
Interactive Inverse Reinforcement Learning of Interaction Scenarios via Bi-level Optimization
Pith reviewed 2026-05-12 00:44 UTC · model grok-4.3
The pith
Interactive inverse reinforcement learning is solved by formulating it as a stochastic bi-level optimization problem with a convergent double-loop algorithm.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
We formulate IIRL as a stochastic bi-level optimization problem where the lower level learns a reward function to explain the behaviors of the expert, and the upper level learns a policy to interact with the expert. We develop a double-loop algorithm, Bi-level Interactive Scenarios Inverse Reinforcement Learning (BISIRL), which solves the lower-level problem in the inner loop and the upper-level problem in the outer loop. We formally guarantee that BISIRL converges and validate our algorithm through extensive experiments.
What carries the argument
BISIRL, the double-loop algorithm that solves the inner reward-learning subproblem and the outer interaction-policy subproblem for the bi-level formulation of interactive inverse reinforcement learning.
If this is right
- The learner can actively shape interactions to gather more informative data about the expert's reward.
- Training of both reward and policy proceeds reliably because of the formal convergence guarantee.
- The approach directly supports collaborative tasks where the learner must respond dynamically to the expert.
- Empirical validation shows the algorithm works across multiple interactive scenarios.
Where Pith is reading between the lines
- The same bi-level structure might scale to settings with several experts interacting simultaneously by adding further optimization levels.
- In deployed systems the method could lower data requirements by inferring rewards on the fly instead of needing large offline datasets.
- Physical tests in domains such as robot navigation around humans would reveal whether the convergence carries over from simulation.
Load-bearing premise
The expert's behavior is generated by an optimal policy with respect to a reward function that the lower-level optimization can recover, and the bi-level structure fully captures the interactive dynamics without hidden variables or non-stationarity.
What would settle it
Run BISIRL in a simulated interactive environment with a known ground-truth expert reward; check whether the recovered reward function matches the true one within a small error after convergence.
Figures

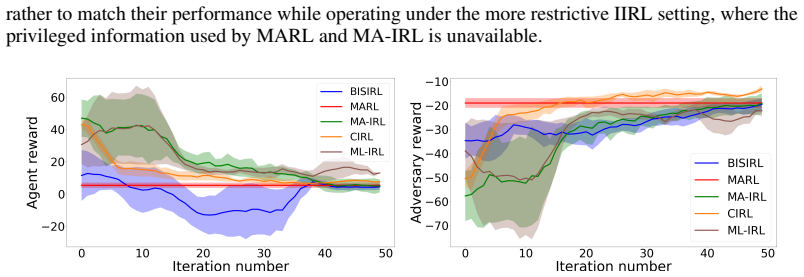
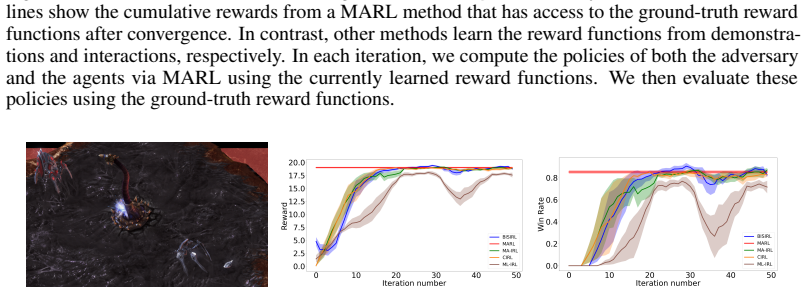
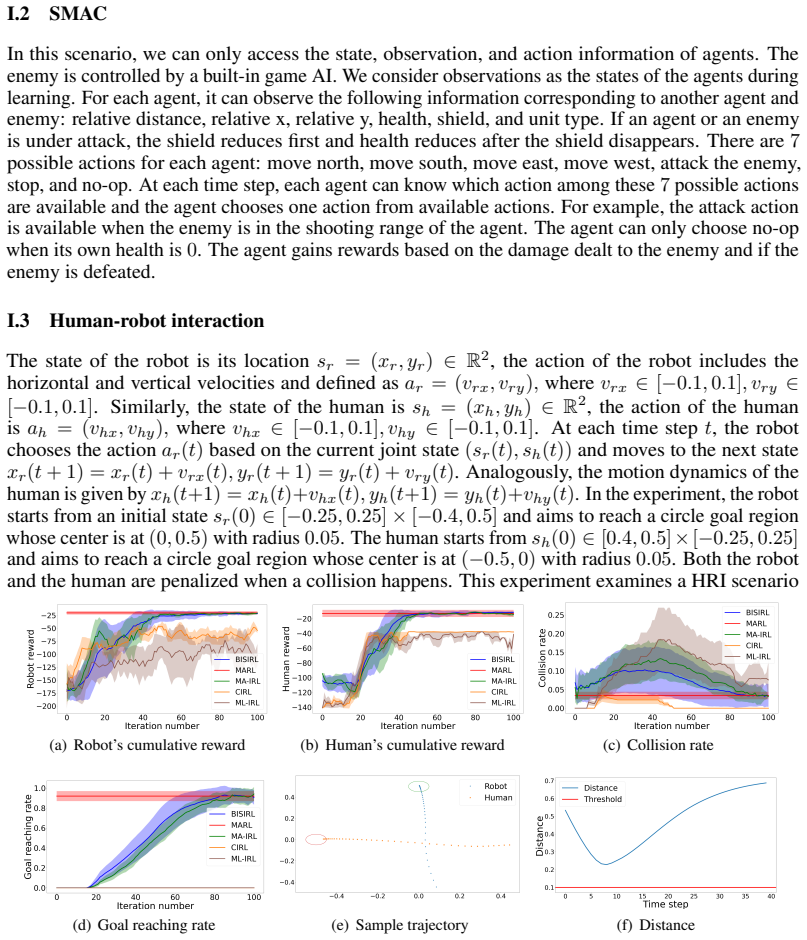
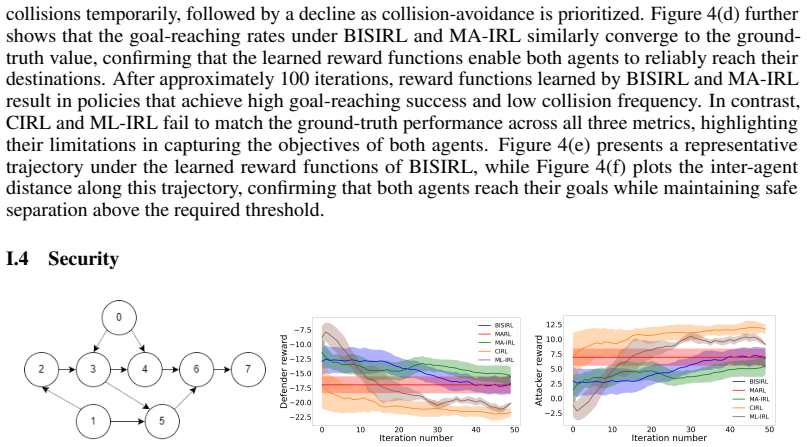
read the original abstract
Inverse reinforcement learning (IRL) learns a reward function and a corresponding policy that best fit the demonstration data of an expert. However, in the current IRL setting, the learner is isolated from the expert and can only passively observe the expert demonstrations. This limits the applicability of IRL to interactive settings, where the learner actively interacts with the expert and needs to infer the expert's reward function from the interactions. To bridge the gap, this paper studies interactive IRL (IIRL) where a learner aims to learn the reward function of an expert and a policy to interact with the expert during its interactions with the expert. We formulate IIRL as a stochastic bi-level optimization problem where the lower level learns a reward function to explain the behaviors of the expert, and the upper level learns a policy to interact with the expert. We develop a double-loop algorithm, Bi-level Interactive Scenarios Inverse Reinforcement Learning (BISIRL), which solves the lower-level problem in the inner loop and the upper-level problem in the outer loop. We formally guarantee that BISIRL converges and validate our algorithm through extensive experiments.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that interactive inverse reinforcement learning (IIRL) can be formulated as a stochastic bi-level optimization problem in which the lower level recovers a reward function explaining expert behavior from interaction data and the upper level optimizes a policy for interacting with the expert. It introduces the double-loop BISIRL algorithm that alternates inner-loop reward learning with outer-loop policy updates and states a formal convergence guarantee, which is supported by experimental validation on interaction scenarios.
Significance. If the convergence guarantee holds under realistic assumptions about non-stationary data, the bi-level formulation would provide a principled way to extend IRL to active, interactive settings where the learner's policy influences the expert's demonstrations. This could strengthen applications in human-AI collaboration and robotics by enabling joint learning of rewards and interaction strategies. The explicit algorithmic guarantee and double-loop structure are positive features if the analysis accommodates the data-generation dependency.
major comments (2)
- [§4, Theorem 1] §4, Theorem 1 (Convergence of BISIRL): The proof assumes the inner-loop lower-level problem admits a well-defined optimum that can be tracked as the outer-loop policy evolves, yet the expert demonstrations are generated by the current upper-level policy, rendering the lower-level dataset non-stationary. Standard stochastic bi-level results require either exact inner solves, strong convexity, or coupled step-size schedules; none are shown to hold here, which is load-bearing for the central convergence claim.
- [§3.1, Eq. (3)] §3.1, Eq. (3) (Bi-level formulation): The upper-level objective is defined using the lower-level reward recovered from interactions, but the formulation does not address how the dependence of expert behavior on the learner's policy affects the uniqueness or stability of the lower-level optimum. This circular dependency risks violating the conditions needed for the double-loop procedure to converge to a stationary point of the bi-level problem.
minor comments (2)
- [Algorithm 1] Algorithm 1: The pseudocode omits the precise inner-loop termination criterion (e.g., gradient norm threshold or fixed iteration count) and any hyper-parameters controlling the trade-off between inner and outer steps, hindering reproducibility.
- [§5] §5 (Experiments): Tables reporting performance metrics do not include standard deviations across random seeds or statistical tests comparing BISIRL to baselines, making it hard to assess whether observed gains are robust.
Simulated Author's Rebuttal
We thank the referee for the insightful comments on our manuscript. We appreciate the focus on the convergence analysis and the bi-level formulation, which are central to our contribution. We address each major comment below and indicate the revisions we plan to make.
read point-by-point responses
-
Referee: [§4, Theorem 1] §4, Theorem 1 (Convergence of BISIRL): The proof assumes the inner-loop lower-level problem admits a well-defined optimum that can be tracked as the outer-loop policy evolves, yet the expert demonstrations are generated by the current upper-level policy, rendering the lower-level dataset non-stationary. Standard stochastic bi-level results require either exact inner solves, strong convexity, or coupled step-size schedules; none are shown to hold here, which is load-bearing for the central convergence claim.
Authors: We are grateful to the referee for pointing out the challenges posed by the non-stationary nature of the demonstration data in the bi-level setting. In our analysis of Theorem 1, the inner-loop problem is assumed to be strongly convex owing to the entropy regularization in the reward recovery objective, which guarantees a unique solution for any fixed upper-level policy. The BISIRL algorithm employs a double-loop structure with a sufficient number of inner iterations to approximately solve the lower level, combined with diminishing step sizes for the outer loop to ensure slow variation of the policy. Nevertheless, we recognize that an explicit bound on the tracking error due to data non-stationarity is not detailed in the current proof. In the revised manuscript, we will augment the appendix with a supporting lemma that establishes the Lipschitz continuity of the lower-level solution map with respect to the policy parameter and derive the necessary step-size conditions to control the approximation error. This constitutes a partial revision focused on strengthening the theoretical analysis without altering the algorithm or main claims. revision: partial
-
Referee: [§3.1, Eq. (3)] §3.1, Eq. (3) (Bi-level formulation): The upper-level objective is defined using the lower-level reward recovered from interactions, but the formulation does not address how the dependence of expert behavior on the learner's policy affects the uniqueness or stability of the lower-level optimum. This circular dependency risks violating the conditions needed for the double-loop procedure to converge to a stationary point of the bi-level problem.
Authors: The referee correctly identifies that the interactive setting introduces a dependency between the upper-level policy and the data used in the lower level. In Equation (3), this is intentionally modeled to reflect the active interaction. The lower-level IRL problem incorporates a regularization term that ensures uniqueness of the reward function for a given dataset. To handle the circularity, the algorithm collects fresh interaction data after each policy update. We agree that the manuscript would benefit from an explicit discussion of the stability of the lower-level optimum. In the revision, we will expand Section 3.1 to include a brief analysis showing that, under standard assumptions such as the expert's response being continuous in the reward function, the bi-level problem remains well-posed and the double-loop procedure converges to a stationary point. This will be a partial revision to improve clarity and address potential concerns about the formulation. revision: partial
Circularity Check
No circularity: bi-level formulation and convergence claim rest on standard optimization results applied to IIRL
full rationale
The paper defines IIRL as a stochastic bi-level optimization where the inner level recovers a reward explaining expert behavior and the outer level optimizes an interaction policy. BISIRL is presented as a double-loop solver with a formal convergence guarantee. No quoted step reduces the central claim to a quantity defined by the same fitted data, nor does any load-bearing uniqueness or convergence result collapse to a self-citation whose own justification is internal to the paper. The derivation is self-contained against external benchmarks in stochastic bi-level optimization and standard IRL assumptions.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Expert behavior is generated from an optimal policy with respect to an unknown reward function
Reference graph
Works this paper leans on
-
[1]
Apprenticeship learning via inverse reinforcement learning
Pieter Abbeel and Andrew Y Ng. Apprenticeship learning via inverse reinforcement learning. InProceedings of the twenty-first international conference on Machine learning, 2004
work page 2004
-
[2]
Zoe Ashwood, Aditi Jha, and Jonathan W Pillow. Dynamic inverse reinforcement learning for characterizing animal behavior.Advances in neural information processing systems, 35: 29663–29676, 2022
work page 2022
-
[3]
Interactive inverse re- inforcement learning for cooperative games
Thomas Kleine Büning, Anne-Marie George, and Christos Dimitrakakis. Interactive inverse re- inforcement learning for cooperative games. InInternational Conference on Machine Learning, pages 2393–2413. PMLR, 2022
work page 2022
-
[4]
Jaedeug Choi and Kee-Eung Kim. Nonparametric bayesian inverse reinforcement learning for multiple reward functions.Advances in neural information processing systems, 25, 2012
work page 2012
-
[5]
An overview of bilevel optimization
Benoît Colson, Patrice Marcotte, and Gilles Savard. An overview of bilevel optimization. Annals of operations research, 153(1):235–256, 2007
work page 2007
-
[6]
Towards safe human-robot collaboration using deep reinforcement learning
Mohamed El-Shamouty, Xinyang Wu, Shanqi Yang, Marcel Albus, and Marco F Huber. Towards safe human-robot collaboration using deep reinforcement learning. In2020 IEEE international conference on robotics and automation (ICRA), pages 4899–4905. IEEE, 2020
work page 2020
-
[7]
An irl approach for cyber-physical attack intention prediction and recovery
Mahmoud Elnaggar and Nicola Bezzo. An irl approach for cyber-physical attack intention prediction and recovery. In2018 Annual American Control Conference (ACC), pages 222–227. IEEE, 2018
work page 2018
-
[8]
Tingxiang Fan, Pinxin Long, Wenxi Liu, and Jia Pan. Distributed multi-robot collision avoidance via deep reinforcement learning for navigation in complex scenarios.The International Journal of Robotics Research, 39(7):856–892, 2020
work page 2020
-
[9]
Approximation Methods for Bilevel Programming
Saeed Ghadimi and Mengdi Wang. Approximation methods for bilevel programming.arXiv preprint arXiv:1802.02246, 2018
work page Pith review arXiv 2018
-
[10]
Reinforcement learning with deep energy-based policies
Tuomas Haarnoja, Haoran Tang, Pieter Abbeel, and Sergey Levine. Reinforcement learning with deep energy-based policies. InInternational conference on machine learning, pages 1352–1361. PMLR, 2017
work page 2017
-
[11]
Dylan Hadfield-Menell, Stuart J Russell, Pieter Abbeel, and Anca Dragan. Cooperative inverse reinforcement learning.Advances in neural information processing systems, 29, 2016
work page 2016
-
[12]
Tsubasa Hirakawa, Takayoshi Yamashita, Toru Tamaki, Hironobu Fujiyoshi, Yuta Umezu, Ichiro Takeuchi, Sakiko Matsumoto, and Ken Yoda. Can ai predict animal movements? filling gaps in animal trajectories using inverse reinforcement learning.Ecosphere, 9(10), 2018
work page 2018
-
[13]
Chi Jin, Praneeth Netrapalli, and Michael Jordan. What is local optimality in nonconvex- nonconcave minimax optimization? InInternational conference on machine learning, pages 4880–4889. PMLR, 2020
work page 2020
-
[14]
Parameswaran Kamalaruban, Rati Devidze, V olkan Cevher, and Adish Singla. Interactive teaching algorithms for inverse reinforcement learning.arXiv preprint arXiv:1905.11867, 2019
-
[15]
Charles D Kolstad and Leon S Lasdon. Derivative evaluation and computational experience with large bilevel mathematical programs.Journal of optimization theory and applications, 65: 485–499, 1990
work page 1990
-
[16]
Meta-learning with differentiable convex optimization
Kwonjoon Lee, Subhransu Maji, Avinash Ravichandran, and Stefano Soatto. Meta-learning with differentiable convex optimization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10657–10665, 2019
work page 2019
-
[17]
Xiaomin Lin, Stephen C Adams, and Peter A Beling. Multi-agent inverse reinforcement learning for certain general-sum stochastic games.Journal of Artificial Intelligence Research, 66:473–502, 2019. 10
work page 2019
-
[18]
Shicheng Liu and Minghui Zhu. Distributed inverse constrained reinforcement learning for multi-agent systems.Advances in Neural Information Processing Systems, 35:33444–33456, 2022
work page 2022
-
[19]
Learning multi-agent behaviors from distributed and streaming demonstrations
Shicheng Liu and Minghui Zhu. Learning multi-agent behaviors from distributed and streaming demonstrations. InThirty-seventh Conference on Neural Information Processing Systems, 2023
work page 2023
-
[20]
Meta inverse constrained reinforcement learning: Convergence guarantee and generalization analysis
Shicheng Liu and Minghui Zhu. Meta inverse constrained reinforcement learning: Convergence guarantee and generalization analysis. InThe Twelfth International Conference on Learning Representations, 2023
work page 2023
-
[21]
Shicheng Liu and Minghui Zhu. In-trajectory inverse reinforcement learning: Learn incre- mentally before an ongoing trajectory terminates.Advances in Neural Information Processing Systems, 37:117164–117209, 2024
work page 2024
-
[22]
Ryan Lowe, Yi I Wu, Aviv Tamar, Jean Harb, OpenAI Pieter Abbeel, and Igor Mordatch. Multi-agent actor-critic for mixed cooperative-competitive environments.Advances in neural information processing systems, 30, 2017
work page 2017
-
[23]
Algorithms for inverse reinforcement learning
Andrew Y Ng and Stuart Russell. Algorithms for inverse reinforcement learning. InInterna- tional Conference on Machine Learning, 2000
work page 2000
-
[24]
Learning socially normative robot navigation behaviors with bayesian inverse reinforcement learning
Billy Okal and Kai O Arras. Learning socially normative robot navigation behaviors with bayesian inverse reinforcement learning. In2016 IEEE international conference on robotics and automation (ICRA), pages 2889–2895. IEEE, 2016
work page 2016
-
[25]
Efficient cooperative inverse reinforcement learning
Malayandi Palaniappan, Dhruv Malik, Dylan Hadfield-Menell, Anca Dragan, and Stuart Russell. Efficient cooperative inverse reinforcement learning. InProc. ICML Workshop on Reliable Machine Learning in the Wild, 2017
work page 2017
-
[26]
Hyperparameter optimization with approximate gradient
Fabian Pedregosa. Hyperparameter optimization with approximate gradient. InInternational conference on machine learning, pages 737–746. PMLR, 2016
work page 2016
-
[27]
Bayesian inverse reinforcement learning
Deepak Ramachandran and Eyal Amir. Bayesian inverse reinforcement learning. InIJCAI, volume 7, pages 2586–2591, 2007
work page 2007
-
[28]
Tabish Rashid, Mikayel Samvelyan, Christian Schroeder De Witt, Gregory Farquhar, Jakob Foerster, and Shimon Whiteson. Monotonic value function factorisation for deep multi-agent reinforcement learning.Journal of Machine Learning Research, 21(178):1–51, 2020
work page 2020
-
[29]
Titouan Renard, Andreas Schlaginhaufen, Tingting Ni, and Maryam Kamgarpour. Convergence of a model-free entropy-regularized inverse reinforcement learning algorithm.arXiv preprint arXiv:2403.16829, 2024
-
[30]
First-person activity forecasting with online inverse reinforcement learning
Nicholas Rhinehart and Kris M Kitani. First-person activity forecasting with online inverse reinforcement learning. InProceedings of the IEEE International Conference on Computer Vision, pages 3696–3705, 2017
work page 2017
-
[31]
arXiv preprint arXiv:1902.04043 , year=
Mikayel Samvelyan, Tabish Rashid, Christian Schroeder De Witt, Gregory Farquhar, Nan- tas Nardelli, Tim GJ Rudner, Chia-Man Hung, Philip HS Torr, Jakob Foerster, and Shimon Whiteson. The starcraft multi-agent challenge.arXiv preprint arXiv:1902.04043, 2019
-
[32]
James C Spall. Multivariate stochastic approximation using a simultaneous perturbation gradient approximation.IEEE transactions on automatic control, 37(3):332–341, 1992
work page 1992
-
[33]
Adaptive stochastic approximation by the simultaneous perturbation method
James C Spall. Adaptive stochastic approximation by the simultaneous perturbation method. IEEE transactions on automatic control, 45(10):1839–1853, 2000
work page 2000
-
[34]
John C Strikwerda.Finite difference schemes and partial differential equations. SIAM, 2004
work page 2004
-
[35]
Jordan Terry, Benjamin Black, Nathaniel Grammel, Mario Jayakumar, Ananth Hari, Ryan Sullivan, Luis S Santos, Clemens Dieffendahl, Caroline Horsch, Rodrigo Perez-Vicente, et al. Pettingzoo: Gym for multi-agent reinforcement learning.Advances in Neural Information Processing Systems, 34:15032–15043, 2021. 11
work page 2021
-
[36]
Lingxiao Wang, Qi Cai, Zhuoran Yang, and Zhaoran Wang. Neural policy gradient methods: Global optimality and rates of convergence.arXiv preprint arXiv:1909.01150, 2019
-
[37]
Competitive multi-agent inverse reinforcement learning with sub-optimal demonstrations
Xingyu Wang and Diego Klabjan. Competitive multi-agent inverse reinforcement learning with sub-optimal demonstrations. InInternational Conference on Machine Learning, pages 5143–5151. PMLR, 2018
work page 2018
-
[38]
Meta value learning for fast policy-centric optimal motion planning
Siyuan Xu and Minghui Zhu. Meta value learning for fast policy-centric optimal motion planning. InRobotics science and systems, 2022
work page 2022
-
[39]
Siyuan Xu and Minghui Zhu. Efficient gradient approximation method for constrained bilevel optimization.Proceedings of the AAAI Conference on Artificial Intelligence, 37(10):12509– 12517, Jun. 2023
work page 2023
-
[40]
Chao Yu, Akash Velu, Eugene Vinitsky, Jiaxuan Gao, Yu Wang, Alexandre Bayen, and Yi Wu. The surprising effectiveness of ppo in cooperative multi-agent games.Advances in Neural Information Processing Systems, 35:24611–24624, 2022
work page 2022
-
[41]
Multi-agent adversarial inverse reinforcement learning
Lantao Yu, Jiaming Song, and Stefano Ermon. Multi-agent adversarial inverse reinforcement learning. InInternational Conference on Machine Learning, pages 7194–7201. PMLR, 2019
work page 2019
-
[42]
Siliang Zeng, Chenliang Li, Alfredo Garcia, and Mingyi Hong. Maximum-likelihood inverse reinforcement learning with finite-time guarantees.Advances in Neural Information Processing Systems, 35:10122–10135, 2022
work page 2022
-
[43]
Siliang Zeng, Chenliang Li, Alfredo Garcia, and Mingyi Hong. When demonstrations meet generative world models: A maximum likelihood framework for offline inverse reinforcement learning.Advances in Neural Information Processing Systems, 36:65531–65565, 2023
work page 2023
-
[44]
Dan Zhang, Gang Feng, Yang Shi, and Dipti Srinivasan. Physical safety and cyber security analysis of multi-agent systems: A survey of recent advances.IEEE/CAA Journal of Automatica Sinica, 8(2):319–333, 2021
work page 2021
-
[45]
Kaiqing Zhang, Alec Koppel, Hao Zhu, and Tamer Basar. Global convergence of policy gradient methods to (almost) locally optimal policies.SIAM Journal on Control and Optimization, 58 (6):3586–3612, 2020
work page 2020
-
[46]
Xiangyuan Zhang, Kaiqing Zhang, Erik Miehling, and Tamer Basar. Non-cooperative inverse reinforcement learning.Advances in neural information processing systems, 32, 2019
work page 2019
-
[47]
Deep reinforcement learning based mobile robot navigation: A review
Kai Zhu and Tao Zhang. Deep reinforcement learning based mobile robot navigation: A review. Tsinghua Science and Technology, 26(5):674–691, 2021
work page 2021
-
[48]
Brian D Ziebart, Andrew L Maas, J Andrew Bagnell, and Anind K Dey. Maximum entropy inverse reinforcement learning.Association for the Advancement of Artificial Intelligence, 8: 1433–1438, 2008
work page 2008
-
[49]
Brian D Ziebart, J Andrew Bagnell, and Anind K Dey. Modeling interaction via the principle of maximum causal entropy.International Conference on Machine Learning, 2010. A Notion and notations Define f(θ l, θe)≜J l(πθl,θe), where Jl(πθl,θe)≜E πθl ,θe [PH−1 h=0 γhrθl(sh, ah)] is the cumula- tive reward of the learner with respect to rθl. Define the reward g...
work page 2010
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.