Recognition: 2 theorem links
· Lean TheoremHoReN: Normalized Hopfield Retrieval for Large-Scale Sequential Model Editing
Pith reviewed 2026-05-12 01:45 UTC · model grok-4.3
The pith
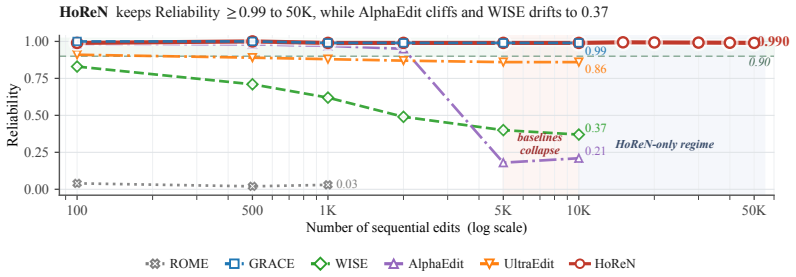
HoReN uses normalized Hopfield retrieval to scale sequential model editing to 50,000 edits without performance collapse.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
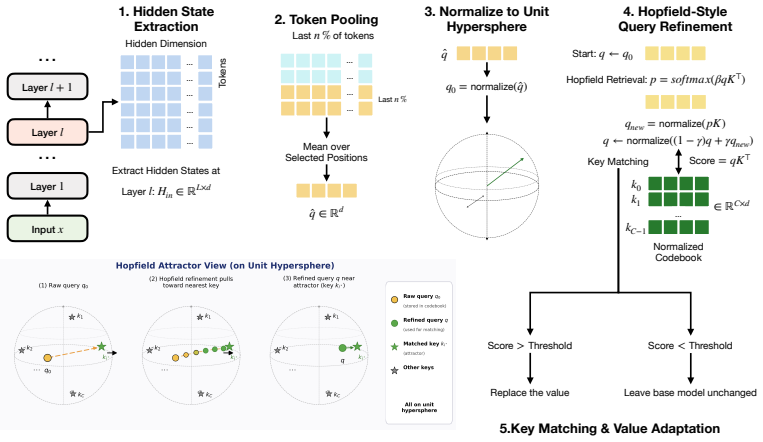
HoReN wraps a single MLP layer with a discrete key-value codebook in which each entry serves simultaneously as a knowledge-memory key and a modern Hopfield stored pattern. Both keys and queries are projected onto the unit hypersphere so retrieval depends on angular similarity. The query is refined by damped Hopfield attractor dynamics that pull paraphrases toward the correct stored pattern's basin while leaving unrelated queries undisturbed. The approach delivers consistent gains on ZsRE, WikiBigEdit, and UnKE and sustains stable scores above 0.9 through 50K sequential edits.
What carries the argument
The discrete codebook of normalized Hopfield patterns combined with damped attractor dynamics for query refinement, which governs retrieval by angular similarity on the unit hypersphere.
If this is right
- Accumulated edits do not progressively disrupt originally preserved knowledge.
- Consistent performance gains appear across standard, structured, and unstructured editing benchmarks.
- Routing challenges faced by external-memory editors are mitigated even at large scale.
- Parameter-preserving edits become viable for lifelong model maintenance.
Where Pith is reading between the lines
- The same normalization and attractor refinement could be applied to other transformer layers beyond a single MLP.
- Similar dynamics might support continual learning tasks outside factual model editing.
- Extending the codebook past 50K edits would directly test whether basin separation remains reliable.
- Integration with additional routing signals could further reduce any remaining interference.
Load-bearing premise
The damped Hopfield attractor dynamics on the normalized sphere will reliably separate edit-related paraphrases from unrelated queries without introducing new interference as the codebook grows to tens of thousands of entries.
What would settle it
A drop in overall ZsRE performance below 0.9 or an increase in interference on unrelated queries when HoReN performs 50,000 sequential edits, compared with its results at much smaller edit counts.
Figures








read the original abstract
Large language models encode vast factual knowledge that inevitably becomes outdated or incorrect after deployment, yet retraining is costly prohibitive, motivating model editing in lifelong settings that updates targeted behavior without harming the rest of the model. One line of work installs new facts by directly modifying base weights through locate-then-edit procedures, but accumulated edits progressively disrupt originally preserved knowledge, even with constraint-based projections. A complementary line leaves base weights intact and routes edits through external memory, but it faces routing challenges and its performance degrades at scale. We propose HoReN, a codebook-based parameter-preserving editor with enhanced routing built on three ideas. First, HoReN wraps a single MLP layer with a discrete key-value codebook, where each entry is interpreted simultaneously as a knowledge-memory key and a modern Hopfield stored pattern. Second, both keys and queries are projected onto the unit hypersphere so retrieval is governed by angular similarity, removing magnitude-driven mismatches between an edit prompt and its rephrasings. Third, the query is refined through damped Hopfield attractor dynamics, so paraphrases relax into the correct stored pattern's basin of attraction while unrelated queries remain undisturbed. HoReN achieves well-edited performance with consistent gains across diverse benchmarks spanning standard ZsRE, structured WikiBigEdit, and unstructured UnKE evaluations. Moreover, HoReN scales to 50K sequential edits on ZsRE with stable overall performance above 0.9, while prior editors collapse or degrade severely before reaching 10K. Our code is available at https://github.com/ha11ucin8/HoReN.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes HoReN, a parameter-preserving model editor that augments a single MLP layer with a discrete key-value codebook in which each entry functions simultaneously as a knowledge key and a modern Hopfield stored pattern. Keys and queries are projected onto the unit hypersphere so that retrieval is driven by angular similarity; queries are then refined by damped Hopfield attractor dynamics that are intended to pull paraphrases into the correct basin while leaving unrelated inputs undisturbed. The paper reports consistent gains across ZsRE, WikiBigEdit, and UnKE benchmarks and claims that the method scales to 50K sequential edits on ZsRE while maintaining overall performance above 0.9, whereas prior editors degrade or collapse well before 10K edits.
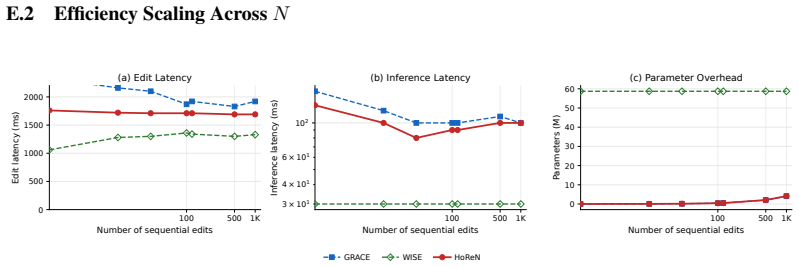
Significance. If the scaling result is robust, HoReN would constitute a meaningful step toward practical lifelong editing of LLMs by demonstrating that an external normalized Hopfield codebook can sustain high performance over tens of thousands of sequential updates without the progressive interference seen in locate-then-edit or earlier memory-based approaches. The public release of code is a clear strength that supports reproducibility.
major comments (2)
- [Abstract and Experimental Evaluation] Abstract and Experimental Evaluation: the headline scaling claim (stable performance >0.9 at 50K sequential ZsRE edits) rests on the unverified assumption that angular normalization plus damped attractor dynamics prevent cross-basin interference as the codebook grows; no capacity analysis, minimum angular-separation bound, or plot of false-retrieval rate versus codebook size is supplied, leaving open the possibility that the observed stability is an artifact of the ZsRE paraphrase distribution rather than a general property of the construction.
- [Experimental Evaluation] Experimental Evaluation: the reported results for the 50K-edit regime provide no error bars, no ablation of the damping schedule, and no measurement of how codebook collisions or basin overlap evolve with edit count; without these controls it is impossible to determine whether the performance advantage is load-bearing or sensitive to post-hoc hyper-parameter choices.
minor comments (1)
- [Method] Notation for the damped Hopfield update rule should be introduced with an explicit equation number in the method section so that the damping parameter and its schedule can be referenced unambiguously in the experiments.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and outline the revisions we will make to strengthen the empirical support for our scaling claims.
read point-by-point responses
-
Referee: [Abstract and Experimental Evaluation] Abstract and Experimental Evaluation: the headline scaling claim (stable performance >0.9 at 50K sequential ZsRE edits) rests on the unverified assumption that angular normalization plus damped attractor dynamics prevent cross-basin interference as the codebook grows; no capacity analysis, minimum angular-separation bound, or plot of false-retrieval rate versus codebook size is supplied, leaving open the possibility that the observed stability is an artifact of the ZsRE paraphrase distribution rather than a general property of the construction.
Authors: We agree that a dedicated capacity analysis would provide stronger theoretical grounding. Our current results rely on extensive empirical evaluation across ZsRE, WikiBigEdit, and UnKE, where the normalized angular retrieval and damped dynamics demonstrably reduce interference compared to baselines. In the revised manuscript we will add an empirical capacity study that reports false-retrieval rates and average basin overlap as functions of codebook size, together with observed minimum angular separations in the learned codebook. These additions will directly address whether the reported stability generalizes beyond the ZsRE paraphrase distribution. revision: yes
-
Referee: [Experimental Evaluation] Experimental Evaluation: the reported results for the 50K-edit regime provide no error bars, no ablation of the damping schedule, and no measurement of how codebook collisions or basin overlap evolve with edit count; without these controls it is impossible to determine whether the performance advantage is load-bearing or sensitive to post-hoc hyper-parameter choices.
Authors: We acknowledge that the absence of error bars and targeted ablations limits the interpretability of the 50K-edit results. We will revise the experimental section to include standard deviations computed over multiple random seeds for all large-scale runs. We will also add an ablation table varying the damping factor and a set of plots tracking codebook collision rates and basin-overlap statistics as the number of sequential edits increases. These controls will clarify the robustness of the performance gains. revision: yes
Circularity Check
No circularity: algorithmic construction with empirical validation on held-out benchmarks
full rationale
The paper presents HoReN as an explicit algorithmic construction: a codebook of normalized keys interpreted as modern Hopfield patterns, with queries projected to the unit sphere and refined by damped attractor dynamics. All performance numbers (including the 50K-edit scaling result on ZsRE) are reported as direct measurements on standard held-out benchmarks rather than as derived predictions. No equation reduces a claimed output to a parameter fitted on the same data, no uniqueness theorem is imported from self-citation, and no ansatz is smuggled via prior work by the same authors. The derivation chain is therefore self-contained and non-circular.
Axiom & Free-Parameter Ledger
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanwashburn_uniqueness_aczel (J-cost uniqueness) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
both keys and queries are projected onto the unit hypersphere so retrieval is governed by angular similarity... damped Hopfield attractor dynamics, so paraphrases relax into the correct stored pattern's basin of attraction
-
IndisputableMonolith/Foundation/AlexanderDuality.leanalexander_duality_circle_linking (D = 3 from sphere linking) unclear?
unclearRelation between the paper passage and the cited Recognition theorem.
Theorem 2.1 (Asymptotic convergence of standard Hopfield retrieval)... energy E(q, K) = ½∥q∥²₂ − F(q)
What do these tags mean?
- matches
- The paper's claim is directly supported by a theorem in the formal canon.
- supports
- The theorem supports part of the paper's argument, but the paper may add assumptions or extra steps.
- extends
- The paper goes beyond the formal theorem; the theorem is a base layer rather than the whole result.
- uses
- The paper appears to rely on the theorem as machinery.
- contradicts
- The paper's claim conflicts with a theorem or certificate in the canon.
- unclear
- Pith found a possible connection, but the passage is too broad, indirect, or ambiguous to say the theorem truly supports the claim.
Reference graph
Works this paper leans on
-
[1]
gpt-oss-120b&gpt-oss-20b model card
OpenAI Sandhini Agarwal, Lama Ahmad, Jason Ai, et al. gpt-oss-120b&gpt-oss-20b model card. 2025. URLhttps://api.semanticscholar.org/CorpusID:280671456
work page 2025
-
[2]
DeepSeek-AI, Daya Guo, Dejian Yang, et al. Deepseek-r1 incentivizes reasoning in llms through reinforcement learning.Nature, 645:633 – 638, 2025. URL https://api.semanticscholar. org/CorpusID:275789950
work page 2025
-
[3]
Unke: Unstructured knowledge editing in large language models.ArXiv, abs/2405.15349, 2024
Jingcheng Deng, Zihao Wei, Liang Pang, Hanxing Ding, Huawei Shen, and Xueqi Cheng. Unke: Unstructured knowledge editing in large language models.ArXiv, abs/2405.15349, 2024. URL https://api.semanticscholar.org/CorpusID:282065712
-
[4]
Abhimanyu Dubey, Abhinav Jauhri, Abhinav Pandey, et al. The llama 3 herd of models. 2024. URLhttps://api.semanticscholar.org/CorpusID:271571434
work page 2024
-
[5]
Junfeng Fang, Houcheng Jiang, Kun Wang, Yunshan Ma, Xiang Wang, Xiangnan He, and Tat-Seng Chua. Alphaedit: Null-space constrained knowledge editing for language mod- els.ArXiv, abs/2410.02355, 2024. URL https://api.semanticscholar.org/CorpusID: 273098148
-
[6]
Ultraedit: Training-, subject- , and memory-free lifelong editing in language models
Xiaojie Gu, Ziying Huang, Jia-Chen Gu, and Kai Zhang. Ultraedit: Training-, subject- , and memory-free lifelong editing in language models. 2025. URL https://api. semanticscholar.org/CorpusID:281659488
work page 2025
-
[7]
Tom Hartvigsen, Swami Sankaranarayanan, Hamid Palangi, Yoon Kim, and Marzyeh Ghassemi. Aging with grace: Lifelong model editing with discrete key-value adaptors.Advances in Neural Information Processing Systems, 36:47934–47959, 2023
work page 2023
-
[8]
Parameter-efficient trans- fer learning for nlp
Neil Houlsby, Andrei Giurgiu, Stanislaw Jastrzebski, Bruna Morrone, Quentin de Larous- silhe, Andrea Gesmundo, Mona Attariyan, and Sylvain Gelly. Parameter-efficient trans- fer learning for nlp. InInternational Conference on Machine Learning, 2019. URL https://api.semanticscholar.org/CorpusID:59599816. 12
work page 2019
-
[9]
LoRA: Low-Rank Adaptation of Large Language Models
J. Edward Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, and Weizhu Chen. Lora: Low-rank adaptation of large language models.ArXiv, abs/2106.09685,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
URLhttps://api.semanticscholar.org/CorpusID:235458009
-
[11]
General- ization through memorization: Nearest neighbor language models
Urvashi Khandelwal, Omer Levy, Dan Jurafsky, Luke Zettlemoyer, and Mike Lewis. General- ization through memorization: Nearest neighbor language models. InInternational Conference on Learning Representations, 2020
work page 2020
-
[12]
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al. Overcoming catastrophic forgetting in neural networks.Proceedings of the national academy of sciences, 114(13):3521–3526, 2017
work page 2017
-
[13]
A new frontier for hopfield networks.Nature Reviews Physics, 5:366–367,
Dmitry Krotov. A new frontier for hopfield networks.Nature Reviews Physics, 5:366–367,
-
[14]
URLhttps://api.semanticscholar.org/CorpusID:258812300
-
[15]
Zero-shot relation extraction via reading comprehension.arXiv preprint arXiv:1706.04115, 2017
Omer Levy, Minjoon Seo, Eunsol Choi, and Luke Zettlemoyer. Zero-shot relation extraction via reading comprehension.arXiv preprint arXiv:1706.04115, 2017
-
[16]
Retrieval-augmented generation for knowledge-intensive NLP tasks
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems, 2020
work page 2020
-
[17]
Prefix-tuning: Optimizing continuous prompts for generation
Xiang Lisa Li and Percy Liang. Prefix-tuning: Optimizing continuous prompts for generation. Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers), pages 4582–4597, 2021. URL https://api.semanticscholar.org/CorpusID: 230433941
work page 2021
-
[18]
Karkkainen, Zhong Chen, Jiangrong Shen, Qi Xu, and Fengyu Cong
Haihua Luo, Xuming Ran, Tommi J. Karkkainen, Zhong Chen, Jiangrong Shen, Qi Xu, and Fengyu Cong. Reversible lifelong model editing via semantic routing-based lora. 2026. URL https://api.semanticscholar.org/CorpusID:286489211
work page 2026
-
[19]
Karkkainen, Qi Xu, and Fengyu Cong
Haihua Luo, Xuming Ran, Zheng Li, Huiyan Xue, Tingting Jiang, Jiangrong Shen, Tommi J. Karkkainen, Qi Xu, and Fengyu Cong. Key-value pair-free continual learner via task-specific prompt-prototype.Neural networks : the official journal of the International Neural Net- work Society, 198:108576, 2026. URL https://api.semanticscholar.org/CorpusID: 284544134
work page 2026
-
[20]
Kevin Meng, David Bau, Alex Andonian, and Yonatan Belinkov. Locating and editing factual associations in gpt.Advances in neural information processing systems, 35:17359–17372, 2022
work page 2022
-
[21]
Mass-Editing Memory in a Transformer
Kevin Meng, Arnab Sen Sharma, Alex Andonian, Yonatan Belinkov, and David Bau. Mass- editing memory in a transformer.arXiv preprint arXiv:2210.07229, 2022
work page internal anchor Pith review arXiv 2022
-
[22]
Fast model editing at scale.arXiv preprint arXiv:2110.11309, 2021
Eric Mitchell, Charles Lin, Antoine Bosselut, Chelsea Finn, and Christopher D Manning. Fast model editing at scale.arXiv preprint arXiv:2110.11309, 2021
-
[23]
Memory-based model editing at scale
Eric Mitchell, Charles Lin, Antoine Bosselut, Christopher D Manning, and Chelsea Finn. Memory-based model editing at scale. InInternational Conference on Machine Learning, pages 15817–15831. PMLR, 2022
work page 2022
-
[24]
Sea-lion: Southeast asian languages in one network
Raymond Ng, Thanh Ngan Nguyen, Yuli Huang, Ngee Chia, Weiqi Leong, et al. Sea-lion: Southeast asian languages in one network. InIJCNLP-AACL, 2025. URL https://api. semanticscholar.org/CorpusID:277450612
work page 2025
-
[25]
Hopfield networks is all you need.arXiv preprint arXiv:2008.02217, 2020
Hubert Ramsauer, Bernhard Schafl, Johannes Lehner, Philipp Seidl, Michael Widrich, Lukas Gruber, Markus Holzleitner, Milena Pavlovi’c, Geir Kjetil Ferkingstad Sandve, Victor Greiff, David P. Kreil, Michael Kopp, Günter Klambauer, Johannes Brandstetter, and Sepp Hochre- iter. Hopfield networks is all you need.ArXiv, abs/2008.02217, 2020. URL https: //api.s...
-
[26]
Xuming Ran, Jun Yao, Yusong Wang, Mingkun Xu, and Dianbo Liu. Brain-inspired continual pre-trained learner via silent synaptic consolidation.ArXiv, abs/2410.05899, 2024. URL https://api.semanticscholar.org/CorpusID:273228983
-
[27]
Understanding the limits of lifelong knowledge editing in LLMs
Lukas Thede, Karsten Roth, Matthias Bethge, and Zeynep Akata. Understanding the limits of lifelong knowledge editing in LLMs. InInternational Conference on Machine Learning, 2025
work page 2025
-
[28]
Peng Wang, Zexi Li, Ningyu Zhang, Ziwen Xu, Yunzhi Yao, Yong Jiang, Pengjun Xie, Fei Huang, and Huajun Chen. Wise: Rethinking the knowledge memory for lifelong model editing of large language models.ArXiv, abs/2405.14768, 2024. URL https: //api.semanticscholar.org/CorpusID:269982715
-
[29]
Yisu Wang, Ming Wang, Haoyuan Song, Wenjie Huang, Chaozheng Wang, Yi Xie, and Xuming Ran. Repair: Robust editing via progressive adaptive intervention and reintegration.arXiv preprint arXiv:2510.01879, 2025
-
[30]
Distillation- guided structural transfer for continual learning beyond sparse distributed memory
Huiyan Xue, Xuming Ran, Yaxin Li, Qi Xu, Enhui Li, Yi Xu, and Qiang Zhang. Distillation- guided structural transfer for continual learning beyond sparse distributed memory. InAAAI Conference on Artificial Intelligence, 2025. URL https://api.semanticscholar.org/ CorpusID:283920124
work page 2025
-
[31]
Qwen An Yang, Baosong Yang, Beichen Zhang, et al. Qwen2.5 technical report. ArXiv, abs/2412.15115, 2024. URL https://api.semanticscholar.org/CorpusID: 274859421
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[32]
arXiv preprint arXiv:2401.01286 (2024)
Ningyu Zhang, Yunzhi Yao, Bo Tian, Peng Wang, Shumin Deng, Mengru Wang, Zekun Xi, Shengyu Mao, Jintian Zhang, Yuansheng Ni, Siyuan Cheng, Ziwen Xu, Xin Xu, Jia-Chen Gu, Yong Jiang, Pengjun Xie, Fei Huang, Lei Liang, Zhiqiang Zhang, Xiaowei Zhu, Jun Zhou, and Huajun Chen. A comprehensive study of knowledge editing for large language mod- els.ArXiv, abs/240...
-
[33]
key” is the internal representation of the subject and the “value
Since {Es} is monotone and bounded below, it converges to some E∞, and ∞X s=0 ∥ds∥2 2 ≤2(E 0 −E ∞)<∞, so∥d s∥2 →0. Step 3: Accumulation points are fixed points.Let Ω be the set of accumulation points of {q(s)}; boundedness gives Ω̸=∅ . For q∗ ∈Ω , pick a subsequence q(sj ) →q ∗. Since ∥dsj ∥2 →0 , q(sj +1) →q ∗, andq (sj +1) =T(q (sj ))→T(q ∗)by continuit...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.