Recognition: 2 theorem links
· Lean TheoremSelf-Captioning Multimodal Interaction Tuning: Amplifying Exploitable Redundancies for Robust Vision Language Models
Pith reviewed 2026-05-12 01:33 UTC · model grok-4.3
The pith
Amplifying redundant multimodal interactions reduces visual errors in vision-language models by 38.3%.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The central claim is that modern instruction datasets eliminate redundancies in multimodal interactions to prioritize visual grounding, leaving models unable to compensate for impaired modalities. By introducing a self-captioning workflow with a Multimodal Interaction Gate that converts unique interactions into redundant ones, the model gains exploitable shared information. This reduces visual induced errors by 38.3% and improves consistency by 16.8%.
What carries the argument
The Multimodal Interaction Gate: a mechanism in the self-captioning workflow that converts unique interactions into redundant interactions to increase exploitable shared information between modalities.
If this is right
- Vision-language models can use shared redundant information to resolve ambiguities when one modality is corrupted or missing.
- Self-captioning enables robustness improvements on existing models and datasets without requiring new instruction data.
- Response consistency increases because redundant signals reinforce correct interpretations across modalities.
- Hallucination rates drop as the model relies more on overlapping information rather than modality-specific guesses.
- The method bridges the gap between training for precise visual grounding and the need for real-world robustness.
Where Pith is reading between the lines
- The same redundancy-amplification idea could apply to other multimodal settings such as audio-visual or text-audio models facing noise.
- Future instruction dataset design might intentionally retain some redundancy to build robustness in from the start rather than removing it.
- The interaction analysis framework could yield new metrics for quantifying how much shared information a training set provides.
- Running the gate at inference time instead of only during tuning might allow dynamic compensation for changing input quality.
Load-bearing premise
The assumption that modern instruction datasets eliminate redundancies to prioritize visual grounding and that converting unique interactions to redundant ones via the Multimodal Interaction Gate will reliably compensate for impaired modalities without introducing new failure modes or losing synergistic information.
What would settle it
Apply the self-captioning tuning with the Multimodal Interaction Gate to a standard vision-language model, introduce controlled visual corruptions on a benchmark, and measure whether visual-induced errors fall by about 38% and consistency rises by about 17% relative to the baseline model.
Figures




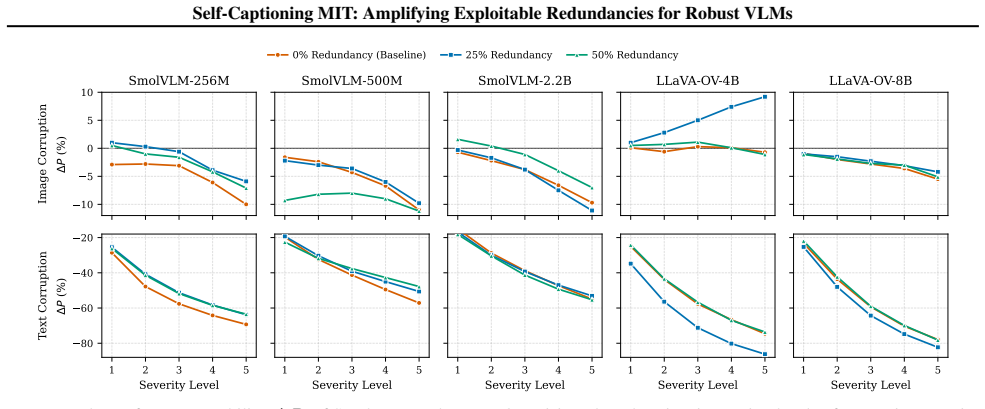
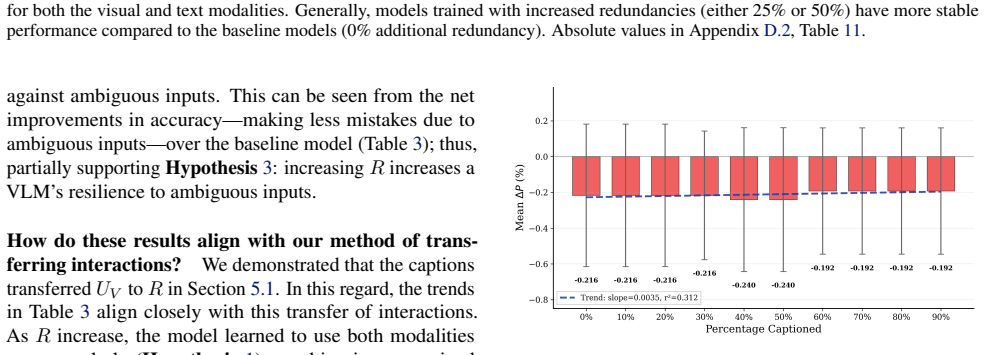





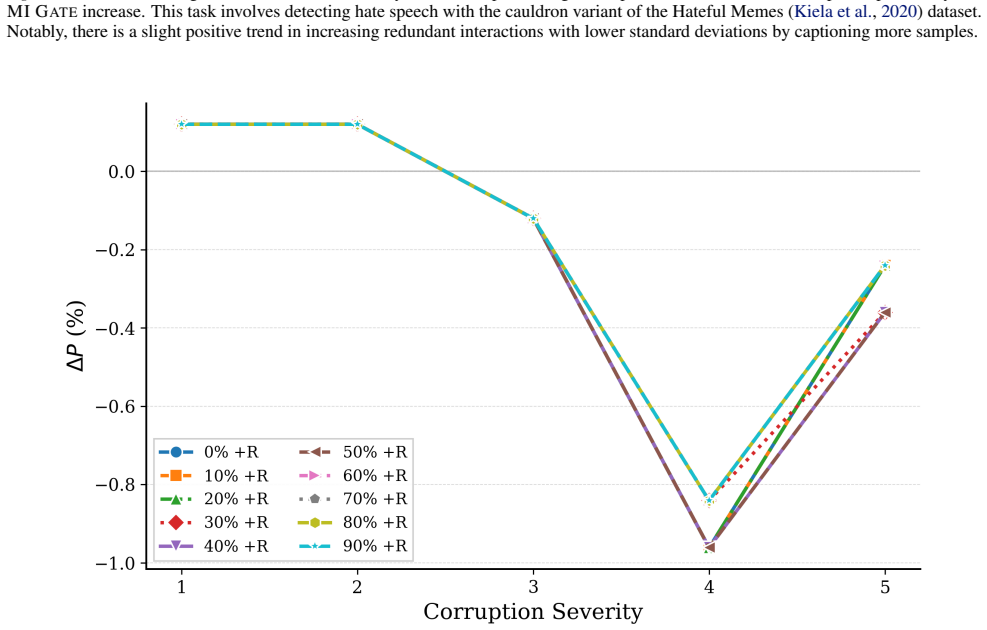
read the original abstract
Current vision language models face hallucination and robustness issues against ambiguous or corrupted modalities. We hypothesize that these issues can be addressed by exploiting the shared information between modalities to compensate for the impaired one. To this end, we analyze multimodal interactions -- redundant (shared), unique (exclusive), and synergistic (emergent) task-relevant information provided by the modalities -- to determine their impacts on model reliability. Specifically, amplifying redundant interactions would increase this exploitable shared information to resolve these issues; yet, modern instruction datasets often eliminate redundancies to prioritize visual grounding. We bridge this gap through a self-captioning workflow featuring a \textsc{Multimodal Interaction Gate}: a mechanism to convert unique interactions into redundant interactions. Our findings suggest that increasing redundancy can reduce visual induced errors by 38.3\% and improve consistency by 16.8\%.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that modern instruction datasets eliminate redundancies in favor of visual grounding, leading to VLM hallucination and robustness issues under ambiguous or corrupted modalities. It proposes a self-captioning workflow with a Multimodal Interaction Gate to convert unique interactions into redundant ones, thereby amplifying shared information to compensate for impaired modalities. Empirical results are reported as a 38.3% reduction in visual-induced errors and 16.8% improvement in consistency.
Significance. If the attribution to redundancy amplification holds after isolating confounding factors, the work could provide a principled way to improve VLM reliability using concepts from partial information decomposition. The introduction of the gate as a mechanism to explicitly tune interaction types is a potentially useful direction, though the current evidence does not yet establish this over simpler augmentation effects.
major comments (2)
- [Abstract / Experimental Results] Abstract and Experimental Results: the 38.3% reduction in visual-induced errors and 16.8% consistency gain are presented as outcomes of amplifying redundant interactions via the Multimodal Interaction Gate, yet no ablation is described that compares self-captioning alone against self-captioning plus the gate. This leaves open that gains arise from additional training signal rather than the redundancy conversion, directly undermining the central causal claim.
- [Methods] Methods section describing the Multimodal Interaction Gate: the mechanism for converting unique to redundant interactions is introduced without quantitative verification that redundancy (as opposed to unique or synergistic terms) has measurably increased, nor controls confirming that synergistic information is preserved and no new failure modes are introduced. This is load-bearing for the hypothesis that redundancy amplification compensates for impaired modalities.
minor comments (2)
- [Abstract / Methods] The abstract and methods would benefit from explicit definitions or a diagram of how the gate operates on interaction terms (redundant/unique/synergistic) to improve clarity for readers unfamiliar with partial information decomposition.
- [Experimental Results] Reporting of results should include error bars, number of runs, and details on data splits and baselines to allow assessment of the reported percentages.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important gaps in establishing the causal role of the Multimodal Interaction Gate and in verifying the underlying information-theoretic changes. We address each point below and will revise the manuscript to incorporate additional experiments and analysis.
read point-by-point responses
-
Referee: [Abstract / Experimental Results] Abstract and Experimental Results: the 38.3% reduction in visual-induced errors and 16.8% consistency gain are presented as outcomes of amplifying redundant interactions via the Multimodal Interaction Gate, yet no ablation is described that compares self-captioning alone against self-captioning plus the gate. This leaves open that gains arise from additional training signal rather than the redundancy conversion, directly undermining the central causal claim.
Authors: We agree that the absence of this ablation weakens the ability to attribute gains specifically to redundancy amplification rather than the self-captioning process itself. In the revised manuscript we will add a controlled ablation that trains identical models on the self-captioning workflow both with and without the Multimodal Interaction Gate, reporting the same error and consistency metrics to isolate the gate's contribution. revision: yes
-
Referee: [Methods] Methods section describing the Multimodal Interaction Gate: the mechanism for converting unique to redundant interactions is introduced without quantitative verification that redundancy (as opposed to unique or synergistic terms) has measurably increased, nor controls confirming that synergistic information is preserved and no new failure modes are introduced. This is load-bearing for the hypothesis that redundancy amplification compensates for impaired modalities.
Authors: The current manuscript relies on downstream performance improvements to support the redundancy hypothesis but does not include direct quantification of changes in redundant, unique, or synergistic information. We will revise the Methods section to incorporate partial information decomposition measurements before and after the gate, together with explicit checks that synergistic terms remain stable and that no additional failure modes appear on held-out corrupted-modality test sets. revision: yes
Circularity Check
No significant circularity; empirical claims remain independent of method definition
full rationale
The paper states a hypothesis on multimodal interactions (redundant, unique, synergistic), describes a self-captioning workflow plus Multimodal Interaction Gate to convert unique to redundant interactions, and reports measured outcomes (38.3% error reduction, 16.8% consistency gain) as experimental results. No equations, fitted parameters, or derivations appear in the provided text that reduce the reported gains to the method by construction. The improvements are framed as empirical findings rather than tautological outputs of the gate definition itself. No self-citations are invoked as load-bearing uniqueness theorems, and no ansatz or renaming patterns are present. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Shared information between modalities can compensate for impaired ones to resolve hallucination and robustness issues.
invented entities (1)
-
Multimodal Interaction Gate
no independent evidence
Lean theorems connected to this paper
-
IndisputableMonolith/Cost/FunctionalEquation.leanJcost_unit0 echoesamplifying redundant interactions would increase this exploitable shared information to resolve these issues... increasing redundancy can reduce visual induced errors by 38.3% and improve consistency by 16.8%
Reference graph
Works this paper leans on
-
[1]
P. Langley , title =. Proceedings of the 17th International Conference on Machine Learning (ICML 2000) , address =. 2000 , pages =
work page 2000
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
work page 1980
-
[3]
M. J. Kearns , title =
-
[4]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
work page 1983
-
[5]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
work page 2000
-
[6]
Suppressed for Anonymity , author=
-
[7]
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
work page 1981
-
[8]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
work page 1959
-
[9]
Yu, Haofei and Qi, Zhengyang and Jang, Lawrence Keunho and Salakhutdinov, Russ and Morency, Louis-Philippe and Liang, Paul Pu , editor =. Proceedings of the 2024. 2024 , pages =. doi:10.18653/v1/2024.emnlp-main.558 , abstract =
-
[10]
Efficient Quantification of Multimodal Interaction at Sample Level , author=. 2025 , eprint=
work page 2025
-
[11]
Advances in Neural Information Processing Systems , year=
Quantifying & Modeling Multimodal Interactions: An Information Decomposition Framework , author=. Advances in Neural Information Processing Systems , year=
-
[12]
Quantifying Unique Information , volume=
Bertschinger, Nils and Rauh, Johannes and Olbrich, Eckehard and Jost, Jürgen and Ay, Nihat , year=. Quantifying Unique Information , volume=. Entropy , publisher=. doi:10.3390/e16042161 , number=
-
[13]
Measuring. Entropy , author =. 2017 , note =. doi:10.3390/e19070318 , abstract =
-
[14]
Pointwise. Entropy , author =. 2018 , note =. doi:10.3390/e20040297 , abstract =
-
[15]
Wörtwein, Torsten and Allen, Nicholas B. and Cohn, Jeffrey F. and Morency, Louis-Philippe , month = nov, year =. Proceedings of the 26th. doi:10.1145/3678957.3685716 , abstract =
-
[16]
I2MoE: Interpretable Multimodal Interaction-aware Mixture-of-Experts , author=. 2025 , eprint=
work page 2025
-
[17]
Proceedings of the AAAI Conference on Artificial Intelligence , author =
Measuring. Proceedings of the AAAI Conference on Artificial Intelligence , author =. 2025 , note =. doi:10.1609/aaai.v39i20.35452 , abstract =
-
[18]
DiffusionPID: Interpreting Diffusion via Partial Information Decomposition , author=. 2024 , eprint=
work page 2024
-
[19]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Guan, Tianrui and Liu, Fuxiao and Wu, Xiyang and Xian, Ruiqi and Li, Zongxia and Liu, Xiaoyu and Wang, Xijun and Chen, Lichang and Huang, Furong and Yacoob, Yaser and Manocha, Dinesh and Zhou, Tianyi , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
work page 2024
-
[20]
doi:10.48550/arXiv.2506.10286 , abstract =
Park, Eunkyu and Kim, Minyeong and Kim, Gunhee , month = jun, year =. doi:10.48550/arXiv.2506.10286 , abstract =
-
[21]
Mitigating Hallucination in Large Multi-Modal Models via Robust Instruction Tuning
Liu, Fuxiao and Lin, Kevin and Li, Linjie and Wang, Jianfeng and Yacoob, Yaser and Wang, Lijuan , month = mar, year =. Mitigating. doi:10.48550/arXiv.2306.14565 , abstract =
work page internal anchor Pith review doi:10.48550/arxiv.2306.14565
-
[22]
He, Yixiao and Sun, Haifeng and Ren, Pengfei and Wang, Jingyu and Wang, Huazheng and Qi, Qi and Zhuang, Zirui and Wang, Jing , editor =. Evaluating and. Proceedings of the 2025. 2025 , pages =. doi:10.18653/v1/2025.naacl-long.349 , abstract =
-
[23]
The Hidden Life of Tokens: Reducing Hallucination of Large Vision-Language Models via Visual Information Steering , author=. 2025 , eprint=
work page 2025
-
[24]
Zou, Xin and Wang, Yizhou and Yan, Yibo and Lyu, Yuanhuiyi and Zheng, Kening and Huang, Sirui and Chen, Junkai and Jiang, Peijie and Liu, Jia and Tang, Chang and Hu, Xuming , month = may, year =. Look. doi:10.48550/arXiv.2410.03577 , abstract =
-
[25]
Bai, Shuai and Chen, Keqin and Liu, Xuejing and Wang, Jialin and Ge, Wenbin and Song, Sibo and Dang, Kai and Wang, Peng and Wang, Shijie and Tang, Jun and Zhong, Humen and Zhu, Yuanzhi and Yang, Mingkun and Li, Zhaohai and Wan, Jianqiang and Wang, Pengfei and Ding, Wei and Fu, Zheren and Xu, Yiheng and Ye, Jiabo and Zhang, Xi and Xie, Tianbao and Cheng, Z...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2502.13923
-
[26]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, Jinguo and Wang, Weiyun and Chen, Zhe and Liu, Zhaoyang and Ye, Shenglong and Gu, Lixin and Tian, Hao and Duan, Yuchen and Su, Weijie and Shao, Jie and Gao, Zhangwei and Cui, Erfei and Wang, Xuehui and Cao, Yue and Liu, Yangzhou and Wei, Xingguang and Zhang, Hongjie and Wang, Haomin and Xu, Weiye and Li, Hao and Wang, Jiahao and Deng, Nianchen and Li...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2504.10479
-
[27]
DeepSeek-VL: Towards Real-World Vision-Language Understanding
Lu, Haoyu and Liu, Wen and Zhang, Bo and Wang, Bingxuan and Dong, Kai and Liu, Bo and Sun, Jingxiang and Ren, Tongzheng and Li, Zhuoshu and Yang, Hao and Sun, Yaofeng and Deng, Chengqi and Xu, Hanwei and Xie, Zhenda and Ruan, Chong , month = mar, year =. doi:10.48550/arXiv.2403.05525 , abstract =
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2403.05525
-
[28]
LoRA: Low-Rank Adaptation of Large Language Models , author=. 2021 , eprint=
work page 2021
-
[29]
The Hateful Memes Challenge: Detecting Hate Speech in Multimodal Memes , author=. 2021 , eprint=
work page 2021
-
[30]
and Boudiaf, Malik and Koliander, Günther and Piantanida, Pablo , month = jun, year =
Pichler, Georg and Colombo, Pierre Jean A. and Boudiaf, Malik and Koliander, Günther and Piantanida, Pablo , month = jun, year =. A. Proceedings of the 39th
-
[31]
Lin, Ji and Yin, Hongxu and Ping, Wei and Molchanov, Pavlo and Shoeybi, Mohammad and Han, Song , year =
-
[32]
A Corpus for Reasoning about Natural Language Grounded in Photographs
Suhr, Alane and Zhou, Stephanie and Zhang, Ally and Zhang, Iris and Bai, Huajun and Artzi, Yoav. A Corpus for Reasoning about Natural Language Grounded in Photographs. Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019. doi:10.18653/v1/P19-1644
-
[33]
Journal of Machine Learning Research , author =
A. Journal of Machine Learning Research , author =. 2023 , pages =
work page 2023
-
[34]
Nonnegative Decomposition of Multivariate Information , author=. 2010 , eprint=
work page 2010
-
[35]
Liang, Paul Pu and Cheng, Yun and Salakhutdinov, Ruslan and Morency, Louis-Philippe , title =. 2023 , isbn =. doi:10.1145/3577190.3614151 , booktitle =
-
[36]
Probability. Entropy , author =. 2018 , note =. doi:10.3390/e20110826 , abstract =
-
[37]
SmolVLM: Redefining small and efficient multimodal models , author=. 2025 , eprint=
work page 2025
-
[38]
What matters when building vision-language models? , author=. 2024 , eprint=
work page 2024
-
[39]
Advances in Neural Information Processing Systems , author =
Benchmarking. Advances in Neural Information Processing Systems , author =. 2023 , pages =
work page 2023
-
[40]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and Huang, Chengen and Lv, Chenxu and Zheng, Chujie and Liu, Dayiheng and Zhou, Fan and Huang, Fei and Hu, Feng and Ge, Hao and Wei, Haoran and Lin, Huan and Tang, Jialong and Yang, Jian and Tu, Jianhong and Zhang, Jianwei and Yang, Jia...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2505.09388
-
[41]
Building and better understanding vision-language models: insights and future directions , author=. 2024 , eprint=
work page 2024
-
[42]
Goyal, Yash and Khot, Tejas and Agrawal, Aishwarya and Summers-Stay, Douglas and Batra, Dhruv and Parikh, Devi , title =. Int. J. Comput. Vision , month = apr, pages =. 2019 , issue_date =. doi:10.1007/s11263-018-1116-0 , abstract =
-
[43]
MMMU: A Massive Multi-discipline Multimodal Understanding and Reasoning Benchmark for Expert AGI , author=. Proceedings of CVPR , year=
-
[44]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Are We on the Right Way for Evaluating Large Vision-Language Models? , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[45]
Lu, Pan and Bansal, Hritik and Xia, Tony and Liu, Jiacheng and Li, Chunyuan and Hajishirzi, Hannaneh and Cheng, Hao and Chang, Kai-Wei and Galley, Michel and Gao, Jianfeng , month = oct, year =
-
[46]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Gqa: A new dataset for real-world visual reasoning and compositional question answering , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[47]
and Kamboj, Abhi and Do, Minh N
Nguyen, Duy A. and Kamboj, Abhi and Do, Minh N. , editor =. Robult:. 2025 , pages =. doi:10.24963/ijcai.2025/666 , booktitle =
-
[48]
The Twelfth International Conference on Learning Representations , year=
Multimodal Learning Without Labeled Multimodal Data: Guarantees and Applications , author=. The Twelfth International Conference on Learning Representations , year=
-
[49]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
Towards VQA Models That Can Read , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , pages=
-
[50]
Bo Li and Yuanhan Zhang and Dong Guo and Renrui Zhang and Feng Li and Hao Zhang and Kaichen Zhang and Peiyuan Zhang and Yanwei Li and Ziwei Liu and Chunyuan Li , journal=. 2025 , url=
work page 2025
-
[51]
InternVL3.5: Advancing Open-Source Multimodal Models in Versatility, Reasoning, and Efficiency , author=. 2025 , eprint=
work page 2025
-
[52]
Visual instruction tuning , volume =
Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae , editor =. Visual instruction tuning , volume =. Advances in neural information processing systems , publisher =. 2023 , pages =
work page 2023
-
[53]
Xie, Yuxi and Li, Guanzhen and Xu, Xiao and Kan, Min-Yen , editor =. V-. Findings of the. 2024 , pages =. doi:10.18653/v1/2024.findings-emnlp.775 , abstract =
-
[54]
arXiv preprint arXiv:2501.09695 , year=
Mitigating Hallucinations in Large Vision-Language Models via DPO: On-Policy Data Hold the Key , author=. arXiv preprint arXiv:2501.09695 , year=
-
[55]
A sober look at the robustness of clips to spurious features , volume =
Wang, Qizhou and Lin, Yong and Chen, Yongqiang and Schmidt, Ludwig and Han, Bo and Zhang, Tong , editor =. A sober look at the robustness of clips to spurious features , volume =. 2024 , pages =. doi:10.52202/079017-3893 , booktitle =
-
[56]
Hasan, Md Kamrul and Rahman, Wasifur and Bagher Zadeh, AmirAli and Zhong, Jianyuan and Tanveer, Md Iftekhar and Morency, Louis-Philippe and Hoque, Mohammed (Ehsan). UR - FUNNY : A Multimodal Language Dataset for Understanding Humor. Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Confe...
-
[57]
Forty-second International Conference on Machine Learning , year=
Look Twice Before You Answer: Memory-Space Visual Retracing for Hallucination Mitigation in Multimodal Large Language Models , author=. Forty-second International Conference on Machine Learning , year=
-
[58]
Forty-second International Conference on Machine Learning , year=
Mitigating Object Hallucination in Large Vision-Language Models via Image-Grounded Guidance , author=. Forty-second International Conference on Machine Learning , year=
- [59]
-
[60]
SigLIP 2: Multilingual Vision-Language Encoders with Improved Semantic Understanding, Localization, and Dense Features , author=. 2025 , eprint=
work page 2025
-
[61]
InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning , url =
Dai, Wenliang and Li, Junnan and LI, DONGXU and Tiong, Anthony and Zhao, Junqi and Wang, Weisheng and Li, Boyang and Fung, Pascale N and Hoi, Steven , booktitle =. InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning , url =
-
[62]
Does Object Grounding Really Reduce Hallucination of Large Vision-Language Models?
Geigle, Gregor and Timofte, Radu and Glava s , Goran. Does Object Grounding Really Reduce Hallucination of Large Vision-Language Models?. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing. 2024. doi:10.18653/v1/2024.emnlp-main.159
-
[63]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =
Favero, Alessandro and Zancato, Luca and Trager, Matthew and Choudhary, Siddharth and Perera, Pramuditha and Achille, Alessandro and Swaminathan, Ashwin and Soatto, Stefano , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) , month =. 2024 , pages =
work page 2024
-
[64]
Proceedings of The 28th International Conference on Artificial Intelligence and Statistics , pages =
Quantifying Knowledge Distillation using Partial Information Decomposition , author =. Proceedings of The 28th International Conference on Artificial Intelligence and Statistics , pages =. 2025 , editor =
work page 2025
-
[65]
The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
Data Selection Matters: Towards Robust Instruction Tuning of Large Multimodal Models , author=. The Thirty-ninth Annual Conference on Neural Information Processing Systems , year=
-
[66]
Thirty-seventh Conference on Neural Information Processing Systems , year=
Visual Instruction Tuning , author=. Thirty-seventh Conference on Neural Information Processing Systems , year=
-
[67]
The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
Enhancing Large Vision Language Models with Self-Training on Image Comprehension , author=. The Thirty-eighth Annual Conference on Neural Information Processing Systems , year=
-
[68]
arXiv preprint arXiv:2301.03829 , year=
From plate to prevention: A dietary nutrient-aided platform for health promotion in singapore , author=. arXiv preprint arXiv:2301.03829 , year=
-
[69]
Proceedings of the AAAI Conference on Artificial Intelligence , author =. 2024 , note =. doi:10.1609/aaai.v38i16.29748 , abstract =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.