Recognition: no theorem link
VT-Bench: A Unified Benchmark for Visual-Tabular Multi-Modal Learning
Pith reviewed 2026-05-12 01:27 UTC · model grok-4.3
The pith
VT-Bench is the first unified benchmark to standardize evaluation of models that combine images with tabular data.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
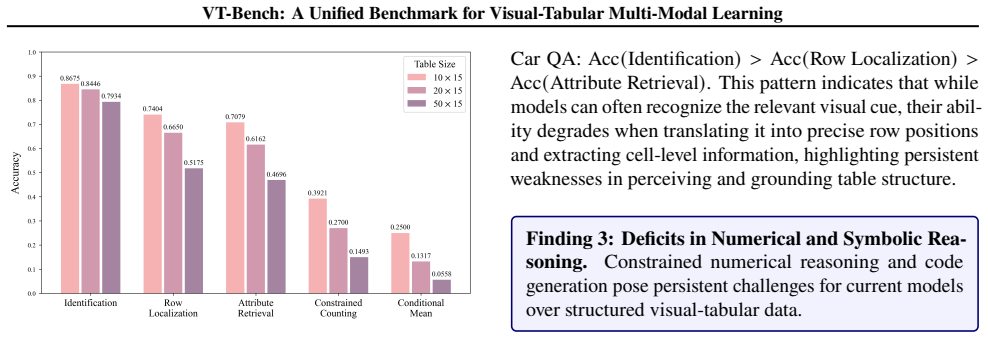
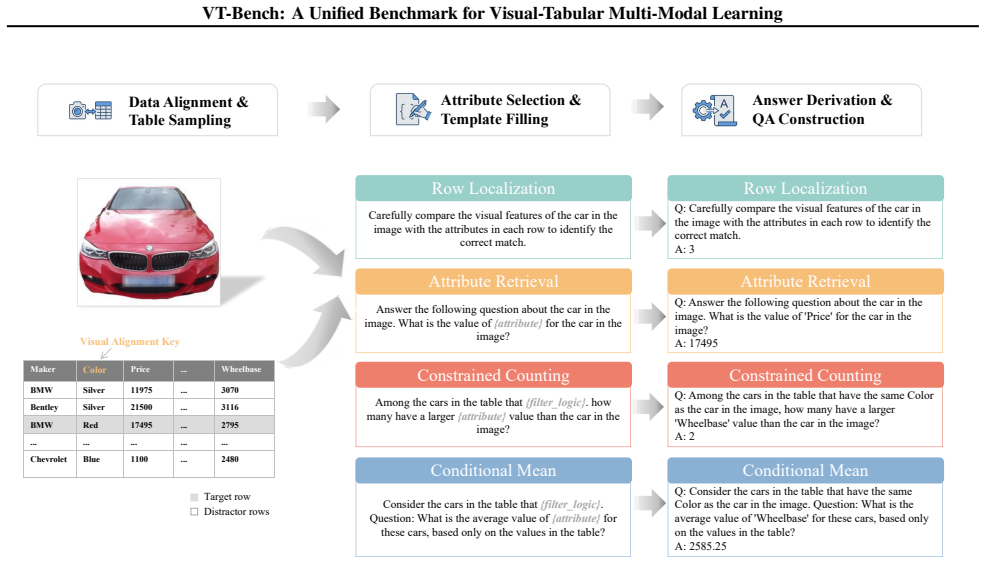
VT-Bench aggregates 14 datasets across 9 domains with over 756K samples to create the first standardized benchmark for vision-tabular discriminative prediction and generative reasoning. Evaluation across 23 models, from unimodal experts to specialized visual-tabular models, general vision-language models, and tool-augmented methods, shows substantial remaining challenges in learning from this data combination.
What carries the argument
VT-Bench, the benchmark that defines protocols and aggregates datasets for consistent testing of visual-tabular tasks.
Load-bearing premise
The 14 chosen datasets and the 23-model evaluation setup capture the main real-world difficulties of visual-tabular learning without major gaps or bias.
What would settle it
A new model that scores high on every VT-Bench task but shows no gains over baselines when tested on independent visual-tabular problems collected from the same domains would show the benchmark missed key difficulties.
Figures







read the original abstract
Multi-model learning has attracted great attention in visual-text tasks. However, visual-tabular data, which plays a pivotal role in high-stakes domains like healthcare and industry, remains underexplored. In this paper, we introduce \textit{VT-Bench}, the first unified benchmark for standardizing vision-tabular discriminative prediction and generative reasoning tasks. VT-Bench aggregates 14 datasets across 9 domains (medical-centric, while covering pets, media, and transportation) with over 756K samples. We evaluate 23 representative models, including unimodal experts, specialized visual-tabular models, general-purpose vision-language models (VLMs), and tool-augmented methods, highlighting substantial challenges of visual-tabular learning. We believe VT-Bench will stimulate the community to build more powerful multi-modal vision-tabular foundation models. Benchmark: https://github.com/Ziyi-Jia990/VT-Bench
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VT-Bench as the first unified benchmark for visual-tabular multi-modal learning. It aggregates 14 existing datasets across 9 domains (primarily medical, with coverage of pets, media, and transportation) totaling over 756K samples, defines discriminative prediction and generative reasoning tasks, and reports baseline results from evaluating 23 models spanning unimodal experts, specialized visual-tabular models, general-purpose VLMs, and tool-augmented methods.
Significance. If the benchmark construction and task definitions hold up under scrutiny, VT-Bench would provide a much-needed standardized evaluation framework for an underexplored but high-stakes area of multi-modal learning. By releasing the benchmark via GitHub and demonstrating substantial performance gaps across model categories, the work could accelerate development of vision-tabular foundation models, analogous to the role of established benchmarks in vision-language research.
major comments (2)
- [§3 and §4] §3 (Dataset Aggregation) and §4 (Task Definitions): the manuscript must explicitly document the selection criteria for the 14 datasets, including any exclusion rules, domain balance metrics, and preprocessing pipelines. Without these, it is impossible to assess whether the benchmark fairly captures core visual-tabular challenges or introduces selection bias toward medical data.
- [§5] §5 (Model Evaluation): the reported results for the 23 models lack statistical controls such as multiple random seeds, confidence intervals, or significance tests for the claimed 'substantial challenges.' This weakens the ability to draw reliable conclusions about relative model performance across discriminative and generative tasks.
minor comments (3)
- [Abstract] Abstract: the phrasing 'medical-centric, while covering pets, media, and transportation' should be accompanied by a breakdown of sample counts or dataset counts per domain to clarify coverage.
- [Introduction / Conclusion] The GitHub link is provided but the manuscript should include a brief description of the repository contents (e.g., data loaders, evaluation scripts, task splits) to facilitate immediate use by the community.
- [§4] Notation for task types (discriminative vs. generative) should be defined consistently in the main text and tables to avoid ambiguity when comparing model categories.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback and positive recommendation for minor revision. We address each major comment point-by-point below, agreeing where the manuscript can be strengthened through added documentation and statistical controls. All changes will be incorporated in the revised version.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Dataset Aggregation) and §4 (Task Definitions): the manuscript must explicitly document the selection criteria for the 14 datasets, including any exclusion rules, domain balance metrics, and preprocessing pipelines. Without these, it is impossible to assess whether the benchmark fairly captures core visual-tabular challenges or introduces selection bias toward medical data.
Authors: We agree that explicit documentation of benchmark construction is essential for transparency and to allow assessment of potential biases. Section 3 of the original manuscript provides an overview of the 14 datasets with Table 1 summarizing domains, sample counts, and sources, while §4 defines the tasks. However, we acknowledge the need for more detail on selection. In the revised manuscript, we will add a new subsection 'Dataset Selection and Preprocessing' in §3 that explicitly states: (1) Selection criteria included public availability of paired visual-tabular data, relevance to discriminative prediction or generative reasoning, minimum sample size (>1,000 for statistical reliability), and coverage of high-stakes domains; (2) Exclusion rules: datasets were excluded if they lacked one modality, contained only synthetic data, had restricted access, or were too small; (3) Domain balance: we will report metrics such as the proportion of samples per domain (medical: ~65%, pets: ~15%, media: ~10%, transportation: ~10%) and note that medical dominance reflects real-world prevalence of visual-tabular data (e.g., imaging + EHR) rather than arbitrary choice, while non-medical domains were deliberately included for diversity; (4) Preprocessing pipelines: uniform steps including image resizing to 224x224, tabular feature standardization, missing value imputation via mean/mode, and consistent train/validation/test splits (70/15/15). These additions will directly address concerns about fairness and selection bias without changing the benchmark composition. revision: yes
-
Referee: [§5] §5 (Model Evaluation): the reported results for the 23 models lack statistical controls such as multiple random seeds, confidence intervals, or significance tests for the claimed 'substantial challenges.' This weakens the ability to draw reliable conclusions about relative model performance across discriminative and generative tasks.
Authors: We appreciate the emphasis on statistical rigor for drawing reliable conclusions about model performance gaps. The original §5 reports single-run results across the 23 models to highlight clear trends (e.g., unimodal models struggling with cross-modal integration and VLMs showing limited tabular reasoning). To strengthen this, the revised manuscript will include: (1) averages and standard deviations over 3 random seeds for all models with stochastic components (e.g., fine-tuning or generation sampling); (2) 95% confidence intervals for primary metrics such as accuracy, F1-score (discriminative tasks), and BLEU/ROUGE (generative tasks); (3) paired statistical tests (e.g., t-tests) between model categories to quantify significance of the observed challenges. Due to substantial computational costs for re-evaluating all 23 models (particularly large VLMs and tool-augmented systems) across 14 datasets, we will apply full multi-seed analysis to representative subsets (baselines, top performers, and one from each category) and note this as a limitation for the remainder. These updates will better substantiate the claims of substantial challenges while remaining feasible for minor revision. revision: partial
Circularity Check
No significant circularity detected
full rationale
The paper constructs VT-Bench by aggregating 14 existing datasets into a unified benchmark and reporting baseline evaluations on 23 models for discriminative and generative tasks. No equations, derivations, fitted parameters, predictions, or load-bearing self-citations appear in the argument structure. The central claim is a constructive contribution (dataset aggregation and standardization) rather than a deductive result that reduces to its own inputs. Domain coverage and task definitions are explicitly stated without circular reduction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Multimodal Machine Learning: A Survey and Taxonomy , journal =
Baltru. Multimodal Machine Learning: A Survey and Taxonomy , journal =. 2018 , volume =
work page 2018
-
[2]
Proceedings of the 32nd International Conference on Machine Learning (ICML 2015) , address =
Xu, Kelvin and Ba, Jimmy and Kiros, Ryan and Cho, Kyunghyun and Courville, Aaron and Salakhudinov, Ruslan and Zemel, Rich and Bengio, Yoshua , title =. Proceedings of the 32nd International Conference on Machine Learning (ICML 2015) , address =. 2015 , pages =
work page 2015
-
[3]
Proceedings of the 15th IEEE International Conference on Computer Vision (ICCV 2015) , address =
Antol, Stanislaw and Agrawal, Aishwarya and Lu, Jiasen and Mitchell, Margaret and Batra, Dhruv and Zitnick, C Lawrence and Parikh, Devi , title =. Proceedings of the 15th IEEE International Conference on Computer Vision (ICCV 2015) , address =. 2015 , pages =
work page 2015
-
[4]
Vinyals, Oriol and Toshev, Alexander and Bengio, Samy and Erhan, Dumitru , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2015) , address =. 2015 , pages =
work page 2015
-
[5]
Yue, Xiang and Ni, Yuansheng and Zhang, Kai and Zheng, Tianyu and Liu, Ruoqi and Zhang, Ge and Stevens, Samuel and Jiang, Dongfu and Ren, Weiming and Sun, Yuxuan and others , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2024) , address =. 2024 , pages =
work page 2024
-
[6]
Proceedings of the 18th European Conference on Computer Vision (ECCV 2024) , address =
Liu, Yuan and Duan, Haodong and Zhang, Yuanhan and Li, Bo and Zhang, Songyang and Zhao, Wangbo and Yuan, Yike and Wang, Jiaqi and He, Conghui and Liu, Ziwei and others , title =. Proceedings of the 18th European Conference on Computer Vision (ECCV 2024) , address =. 2024 , pages =
work page 2024
-
[7]
Proceedings of the 38th International Conference on Machine Learning (ICML 2021) , address =
Radford, Alec and Kim, Jong Wook and Hallacy, Chris and Ramesh, Aditya and Goh, Gabriel and Agarwal, Sandhini and Sastry, Girish and Askell, Amanda and Mishkin, Pamela and Clark, Jack and others , title =. Proceedings of the 38th International Conference on Machine Learning (ICML 2021) , address =. 2021 , pages =
work page 2021
-
[8]
Proceedings of the 40th International Conference on Machine Learning (ICML 2023) , address =
Li, Junnan and Li, Dongxu and Savarese, Silvio and Hoi, Steven , title =. Proceedings of the 40th International Conference on Machine Learning (ICML 2023) , address =. 2023 , pages =
work page 2023
-
[9]
Advances in Neural Information Processing Systems , year =
Liu, Haotian and Li, Chunyuan and Wu, Qingyang and Lee, Yong Jae , title =. Advances in Neural Information Processing Systems , year =
-
[10]
Proceedings of the 39th International Conference on Machine Learning (ICML 2022) , address =
Li, Junnan and Li, Dongxu and Xiong, Caiming and Hoi, Steven , title =. Proceedings of the 39th International Conference on Machine Learning (ICML 2022) , address =. 2022 , pages =
work page 2022
-
[11]
Advances in Neural Information Processing Systems , year =
Lu, Jiasen and Batra, Dhruv and Parikh, Devi and Lee, Stefan , title =. Advances in Neural Information Processing Systems , year =
- [12]
-
[13]
Yang, Jiaxi and Chen, Kui and Ding, Kai and Na, Chongning and Wang, Meng , title =. Data Intelligence , year =
-
[14]
Huang, Shih-Cheng and Pareek, Anuj and Seyyedi, Saeed and Banerjee, Imon and Lungren, Matthew P , title =. NPJ Digital Medicine , year =
-
[15]
Proceedings of the 10th IEEE International Conference on Big Data (Big Data 2022) , address =
Huang, Jingmin and Chen, Bowei and Luo, Lan and Yue, Shigang and Ounis, Iadh , title =. Proceedings of the 10th IEEE International Conference on Big Data (Big Data 2022) , address =. 2022 , pages =
work page 2022
-
[16]
Cui, Can and Yang, Haichun and Wang, Yaohong and Zhao, Shilin and Asad, Zuhayr and Coburn, Lori A. and Wilson, Keith T. and Landman, Bennett A. and Huo, Yuankai , title =. Progress in Biomedical Engineering , year =
-
[17]
Medical Image Analysis , year =
Duenias, Daniel and Nichyporuk, Brennan and Arbel, Tal and Raviv, Tammy Riklin and others , title =. Medical Image Analysis , year =
-
[18]
Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV 2021) , address =
Holste, Gregory and Partridge, Savannah C and Rahbar, Habib and Biswas, Debosmita and Lee, Christoph I and Alessio, Adam M , title =. Proceedings of the 18th IEEE/CVF International Conference on Computer Vision (ICCV 2021) , address =. 2021 , pages =
work page 2021
-
[19]
Long-term Cancer Survival Prediction Using Multimodal Deep Learning , journal =
Vale-Silva, Lu. Long-term Cancer Survival Prediction Using Multimodal Deep Learning , journal =. 2021 , volume =
work page 2021
-
[20]
Zheng, Hanci and Lin, Zongying and Zhou, Qizheng and Peng, Xingchen and Xiao, Jianghong and Zu, Chen and Jiao, Zhengyang and Wang, Yan , title =. Proceedings of the 25th International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2022) , address =. 2022 , pages =
work page 2022
- [21]
-
[22]
Jiang, Jun-Peng and Ye, Han-Jia and Wang, Leye and Yang, Yang and Jiang, Yuan and Zhan, De-Chuan , title =. 2024 , booktitle =
work page 2024
-
[23]
Hager, Paul and Menten, Martin J and Rueckert, Daniel , title =. Proceedings of the 36th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR 2023) , address =. 2023 , pages =
work page 2023
-
[24]
Proceedings of the 18th European Conference on Computer Vision (ECCV 2024) , address =
Du, Siyi and Zheng, Shaoming and Wang, Yinsong and Bai, Wenjia and O’Regan, Declan P and Qin, Chen , title =. Proceedings of the 18th European Conference on Computer Vision (ECCV 2024) , address =. 2024 , pages =
work page 2024
-
[25]
Luo, Haohao and Shen, Ying and Deng, Yang , title =. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing (EMNLP 2023) , address =. 2023 , pages =
work page 2023
-
[26]
Advances in Neural Information Processing Systems , year =
Bae, Seongsu and Kyung, Daeun and Ryu, Jaehee and Cho, Eunbyeol and Lee, Gyubok and Kweon, Sunjun and Oh, Jungwoo and Ji, Lei and Chang, Eric and Kim, Tackeun and others , title =. Advances in Neural Information Processing Systems , year =
-
[27]
Talmor, Alon and Yoran, Ori and Catav, Amnon and Lahav, Dan and Wang, Yizhong and Asai, Akari and Ilharco, Gabriel and Hajishirzi, Hannaneh and Berant, Jonathan , title =. Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL 2021) , address =. 2021 , pages =
work page 2021
-
[28]
Duanmu, Hongyi and Huang, Pauline Boning and Brahmavar, Srinidhi and Lin, Stephanie and Ren, Thomas and Kong, Jun and Wang, Fusheng and Duong, Tim Q , title =. Proceedings of the 23rd International Conference on Medical Image Computing and Computer-Assisted Intervention (MICCAI 2020) , address =. 2020 , pages =
work page 2020
-
[29]
He, Kaiming and Zhang, Xiangyu and Ren, Shaoqing and Sun, Jian , title =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2016) , address =. 2016 , pages =
work page 2016
-
[30]
Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil , title =. 2021 , booktitle =
work page 2021
-
[31]
Proceedings of the 34th International Conference on Machine Learning (ICML 2017) , address =
Sundararajan, Mukund and Taly, Ankur and Yan, Qiqi , title =. Proceedings of the 34th International Conference on Machine Learning (ICML 2017) , address =. 2017 , pages =
work page 2017
-
[32]
and Zhu, Yuke and others , title =
Liang, Paul Pu and Lyu, Yiwei and Fan, Xiang and Wu, Zetian and Cheng, Yun and Wu, Jason and Chen, Leslie and Wu, Peter and Lee, Michelle A. and Zhu, Yuke and others , title =. Advances in Neural Information Processing Systems , year =
-
[33]
arXiv preprint arXiv:2412.16243 , year =
Tang, Zhiqiang and Zhong, Zihan and He, Tong and Friedland, Gerald , title =. arXiv preprint arXiv:2412.16243 , year =
-
[34]
Johnson, Alistair E. W. and Bulgarelli, Lucas and Shen, Lu and Gayles, Alvin and Shammout, Ayad and Horng, Steven and Pollard, Tom J. and Hao, Sicheng and Moody, Benjamin and Gow, Brian and others , title =. Scientific Data , year =
-
[35]
Johnson, Alistair E. W. and Pollard, Tom J. and Berkowitz, Seth J. and Greenbaum, Nathaniel R. and Lungren, Matthew P. and Deng, Chih-ying and Mark, Roger G. and Horng, Steven , title =. Scientific Data , year =
-
[36]
Spasov, Simeon and Passamonti, Luca and Duggento, Andrea and Lio, Pietro and Toschi, Nicola and others , title =. NeuroImage , year =
-
[37]
Advances in Neural Information Processing Systems , year =
Ke, Guolin and Meng, Qi and Finley, Thomas and Wang, Taifeng and Chen, Wei and Ma, Weidong and Ye, Qiwei and Liu, Tie-Yan , title =. Advances in Neural Information Processing Systems , year =
-
[38]
TabTransformer: Tabular data modeling using contextual embeddings.arXiv preprint arXiv:2012.06678,
Huang, Xin and Khetan, Ashish and Cvitkovic, Milan and Karnin, Zohar , title =. arXiv preprint arXiv:2012.06678 , year =
-
[39]
Accurate Predictions on Small Data with a Tabular Foundation Model , journal =
Hollmann, Noah and M. Accurate Predictions on Small Data with a Tabular Foundation Model , journal =. 2025 , volume =
work page 2025
-
[40]
Yang, An and Li, Anfeng and Yang, Baosong and Zhang, Beichen and Hui, Binyuan and Zheng, Bo and Yu, Bowen and Gao, Chang and others , title =. arXiv preprint arXiv:2505.09388 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[41]
arXiv preprint arXiv:2406.08100 , year =
Zheng, Mingyu and Feng, Xinwei and Si, Qingyi and She, Qiaoqiao and Lin, Zheng and Jiang, Wenbin and Wang, Weiping , title =. arXiv preprint arXiv:2406.08100 , year =
-
[42]
The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink , journal =
Patterson, David and Gonzalez, Joseph and H. The Carbon Footprint of Machine Learning Training Will Plateau, Then Shrink , journal =. 2022 , volume =
work page 2022
-
[43]
Hong, Wenyi and Yu, Wenmeng and Gu, Xiaotao and Wang, Guo and Gan, Guobing and Tang, Haomiao and Cheng, Jiale and others , title =. arXiv preprint arXiv:2507.01006 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[44]
InternVL3: Exploring Advanced Training and Test-Time Recipes for Open-Source Multimodal Models
Zhu, Jinguo and Wang, Weiyun and Chen, Zhe and Liu, Zhaoyang and Ye, Shenglong and Gu, Lixin and others , title =. arXiv preprint arXiv:2504.10479 , year =
work page internal anchor Pith review Pith/arXiv arXiv
-
[46]
Informatics in Medicine Unlocked , year =
Mienye, Ibomoiye Domor and Obaido, George and Jere, Nobert and Mienye, Ebikella and Aruleba, Kehinde and Emmanuel, Ikiomoye Douglas and Ogbuokiri, Blessing , title =. Informatics in Medicine Unlocked , year =
-
[47]
Zhu, Fengbin and Lei, Wenqiang and Huang, Youcheng and Wang, Chao and Zhang, Shuo and Lv, Jiancheng and Feng, Fuli and Chua, Tat-Seng , title =. arXiv preprint arXiv:2105.07624 , year =
-
[48]
Proceedings of the 30th ACM International Conference on Multimedia (MM 2022) , address =
Zhu, Fengbin and Lei, Wenqiang and Feng, Fuli and Wang, Chao and Zhang, Haozhou and Chua, Tat-Seng , title =. Proceedings of the 30th ACM International Conference on Multimedia (MM 2022) , address =. 2022 , pages =
work page 2022
-
[49]
Tablevqa-bench: A visual question answering benchmark on multiple table domains, 2024
Tablevqa-bench: A visual question answering benchmark on multiple table domains , author=. arXiv preprint arXiv:2404.19205 , year=
-
[50]
arXiv preprint arXiv:2506.11684 , year=
MTabVQA: Evaluating Multi-Tabular Reasoning of Language Models in Visual Space , author=. arXiv preprint arXiv:2506.11684 , year=
-
[51]
arXiv preprint arXiv:2408.13860 , year=
Knowledge-aware reasoning over multimodal semi-structured tables , author=. arXiv preprint arXiv:2408.13860 , year=
-
[52]
arXiv preprint arXiv:2111.11665 , year=
Radfusion: Benchmarking performance and fairness for multimodal pulmonary embolism detection from ct and ehr , author=. arXiv preprint arXiv:2111.11665 , year=
-
[53]
The UK Biobank resource with deep phenotyping and genomic data , author=. Nature , volume=. 2018 , publisher=
work page 2018
-
[54]
S. Bai and Y. Cai and R. Chen and K. Chen and others. Qwen3-VL Technical Report. arXiv preprint arXiv:2511.21631. 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [55]
-
[56]
Pixtral 12b.arXiv preprint arXiv:2410.07073,
P. Agrawal and others , title =. arXiv preprint arXiv:2410.07073 , year =
- [57]
-
[58]
Gemini 3 Flash: Model Card , year =
-
[59]
arXiv preprint arXiv:2505.21771 , year =
Prasham Yatinkumar Titiya and Jainil Trivedi and Chitta Baral and Vivek Gupta , title =. arXiv preprint arXiv:2505.21771 , year =
-
[60]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Jiang, Jinhao and Zhou, Kun and Dong, Zican and Ye, Keming and Zhao, Xin and Wen, Ji-Rong , title=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
work page 2023
-
[61]
Thyme: Think beyond images.arXiv preprint arXiv:2508.11630, 2025
Thyme: Think beyond images , author=. arXiv preprint arXiv:2508.11630 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.